目錄
前言
環境部署
安裝Docker
安裝Dify
配置Dify
部署知識庫
創建應用

前言
在當今數字化信息爆炸的時代,數據隱私和個性化知識管理成為企業和個人關注的焦點。Dify,作為一款備受矚目的開源 AI 應用開發平臺,為用戶提供了完整的私有化部署方案,讓數據安全掌控在自己手中。而 DeepSeek 作為本地部署的強大 AI 服務,擁有著卓越的性能和靈活性。將二者無縫集成,就如同為企業開啟了一扇通往定制化、安全可靠 AI 應用世界的大門。通過這樣的集成,企業能夠在本地服務器環境內構建出功能強大的 AI 應用,不僅確保了數據隱私,還能滿足個性化的業務需求。接下來,就讓我們一起深入探索如何利用 DeepSeek +硅基流動+ Dify 構建屬于自己的個人知識庫。
環境部署
安裝Docker
#wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo#yum -y install docker-ce #默認下載的是最新版的docker#systemctl start docker && systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.#vi /etc/docker/daemon.json
{"registry-mirrors": ["https://docker.211678.top","https://docker.1panel.live","https://hub.rat.dev","https://docker.m.daocloud.io","https://do.nark.eu.org","https://dockerpull.com","https://dockerproxy.cn","https://docker.awsl9527.cn"],"exec-opts": ["native.cgroupdriver=systemd"]
}#systemctl daemon-reload
#systemctl restart docker安裝Dify
安裝Git
#yum -y install git 拉取Dify
# git clone https://gitee.com/dify_ai/dify
Cloning into 'dify'...
remote: Enumerating objects: 237231, done.
remote: Counting objects: 100% (101077/101077), done.
remote: Compressing objects: 100% (42662/42662), done.
remote: Total 237231 (delta 80807), reused 76208 (delta 56849), pack-reused 136154 (from 1)
Receiving objects: 100% (237231/237231), 89.83 MiB | 404.00 KiB/s, done.
Resolving deltas: 100% (184737/184737), done.# cd dify/docker
# cp .env.example .env # 創建配置文件啟動Dify
# docker compose up -d
#接下來就是拉取鏡像和部署的過程,耐心等待,與網速有關。搭建完成后進行賬戶設置:
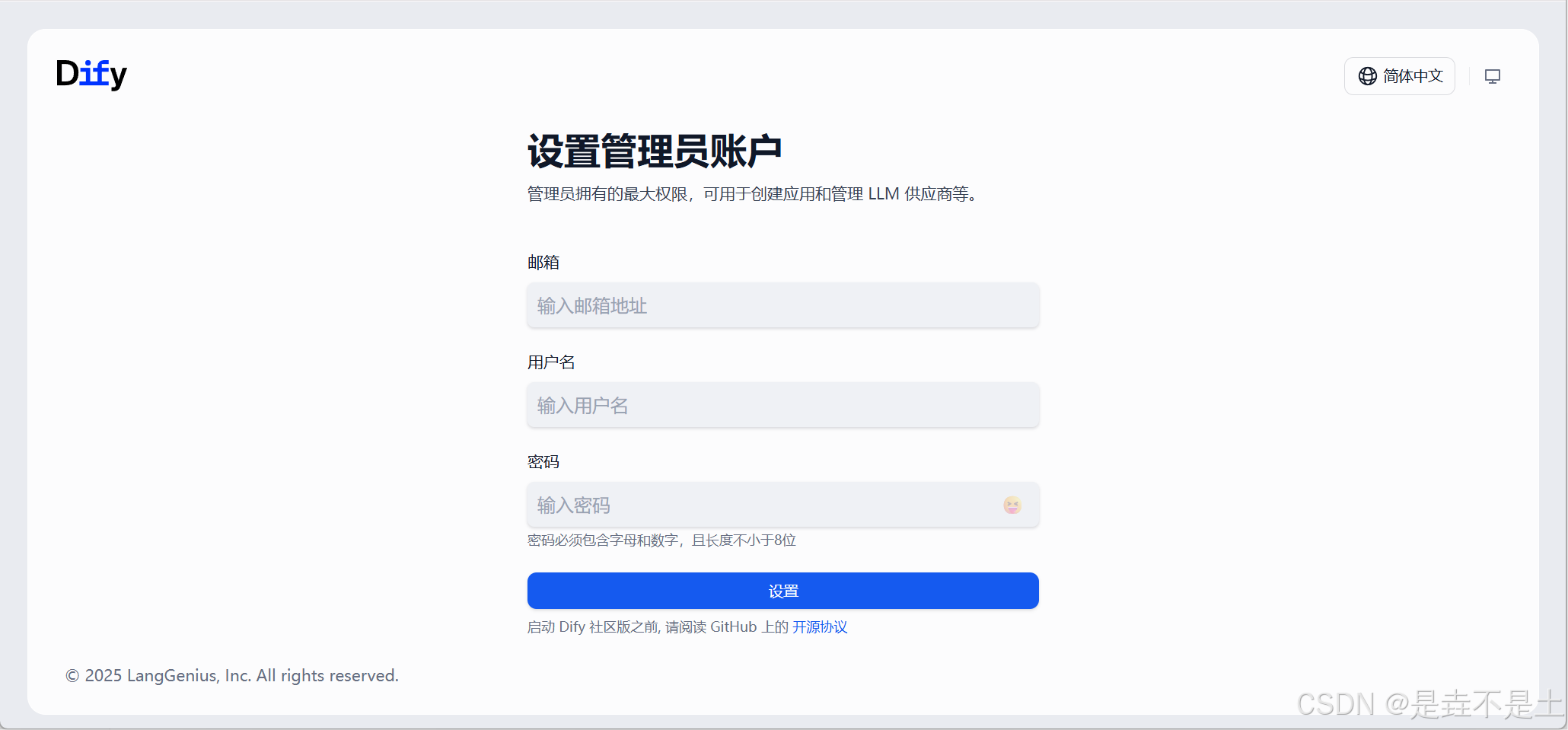
創建完成后查看首頁:
配置Dify
點擊設置:
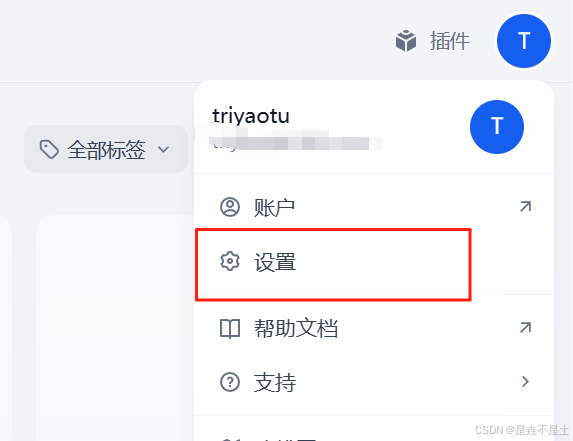
點擊模型提供商:
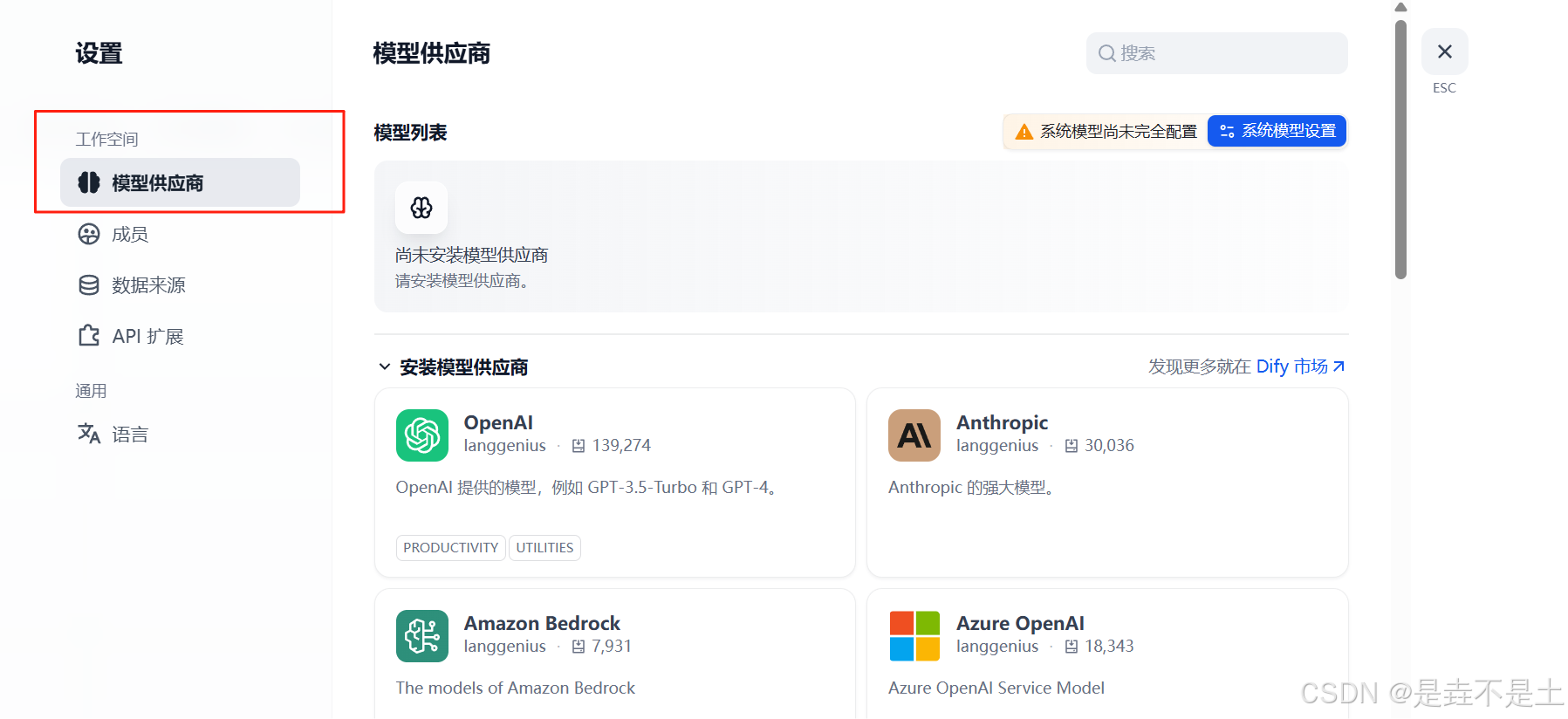
安裝Deepseek插件和硅基流動插件:
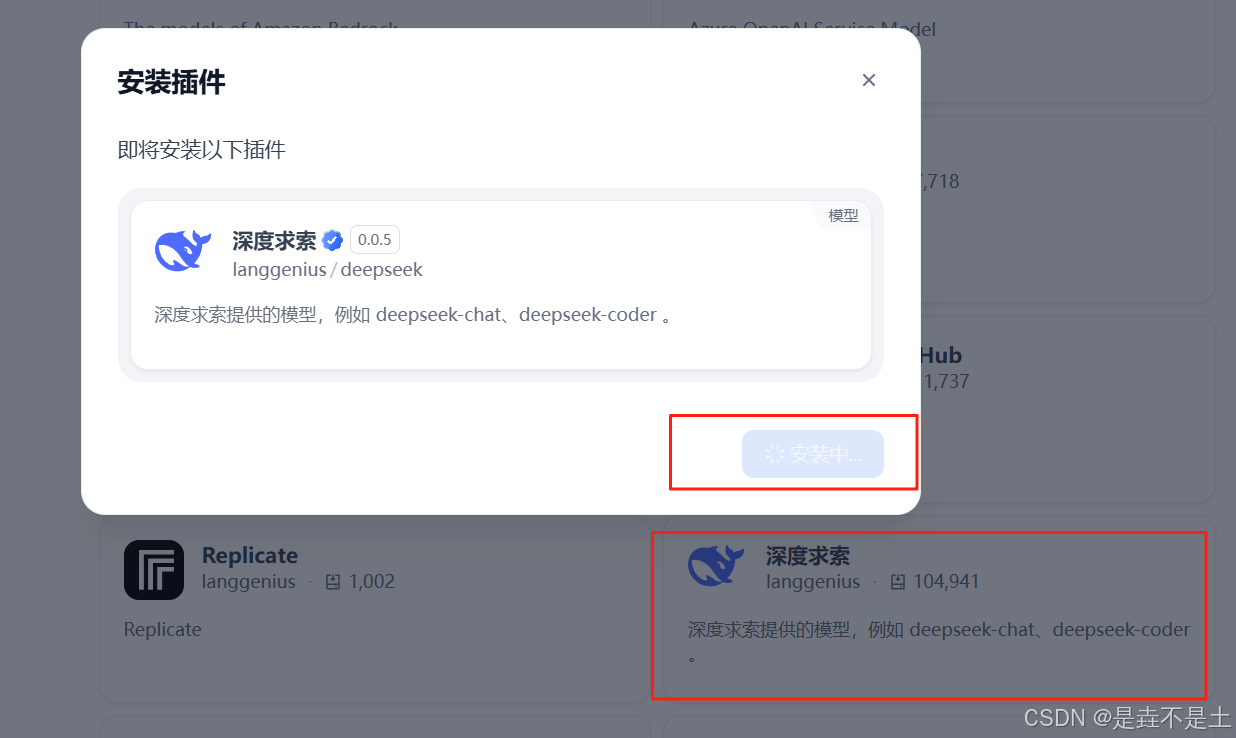
安裝插件完成。
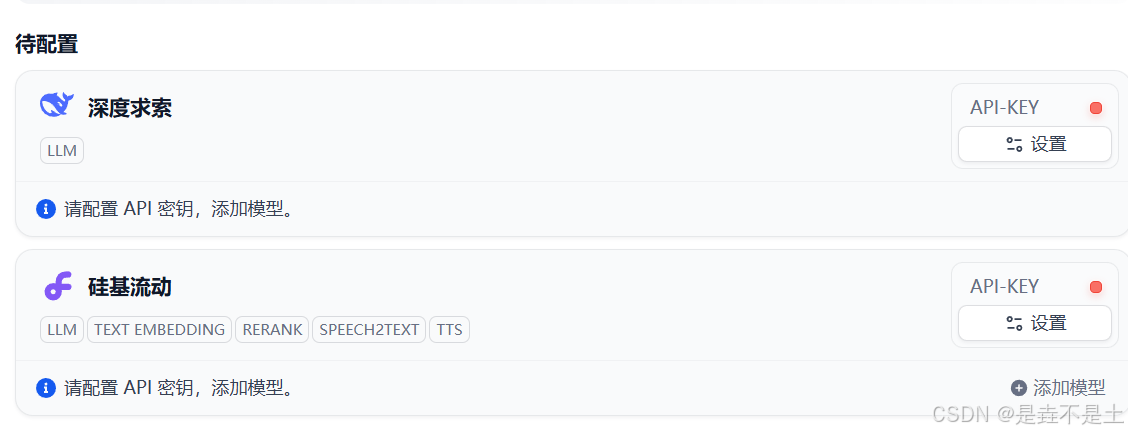
安裝完成后查看,設置API-KEY:
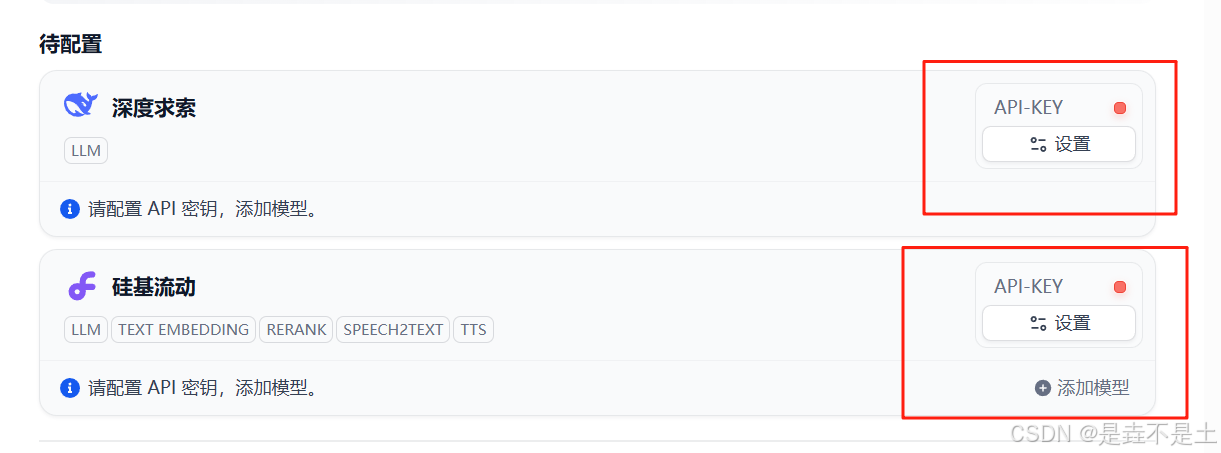
設置相應參數:
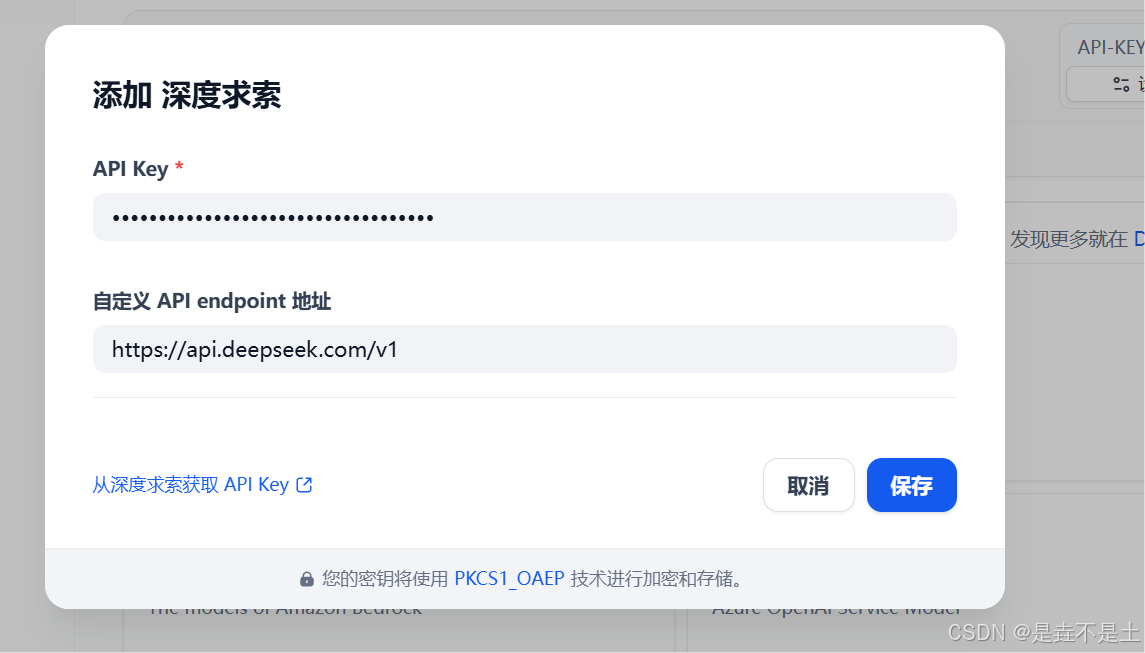
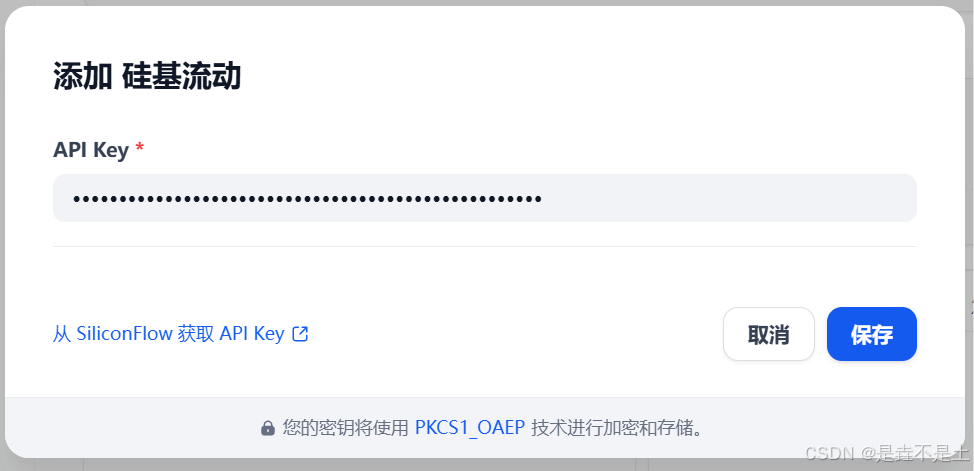
配置系統模型:
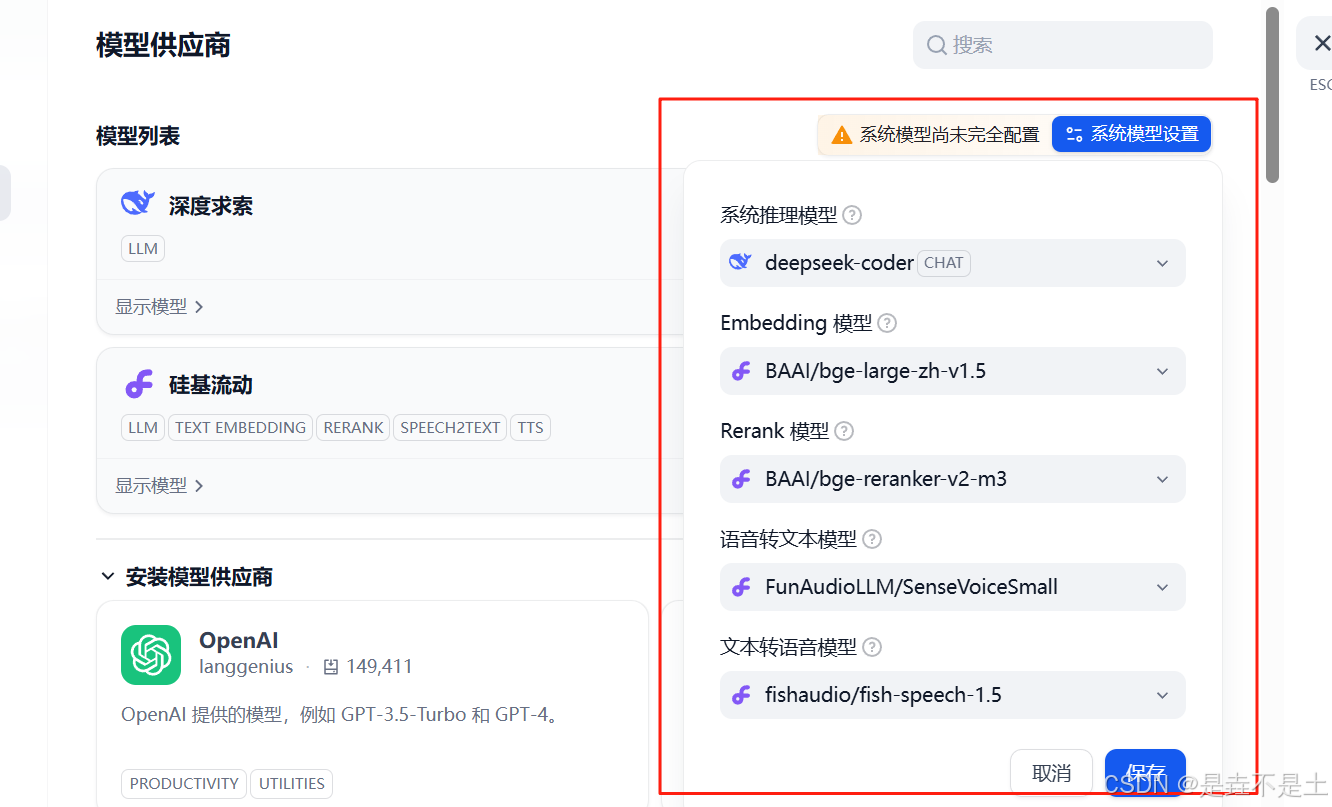
大模型配置完成。
部署知識庫
在主頁上方點擊知識庫:
點擊“創建空知識庫”,會彈出一個彈窗,填寫知識庫名稱后,點擊創建即可,在資料還沒整理好的時候,可以先創建一個空知識庫,在后續上傳本地文檔或導入在線數據。
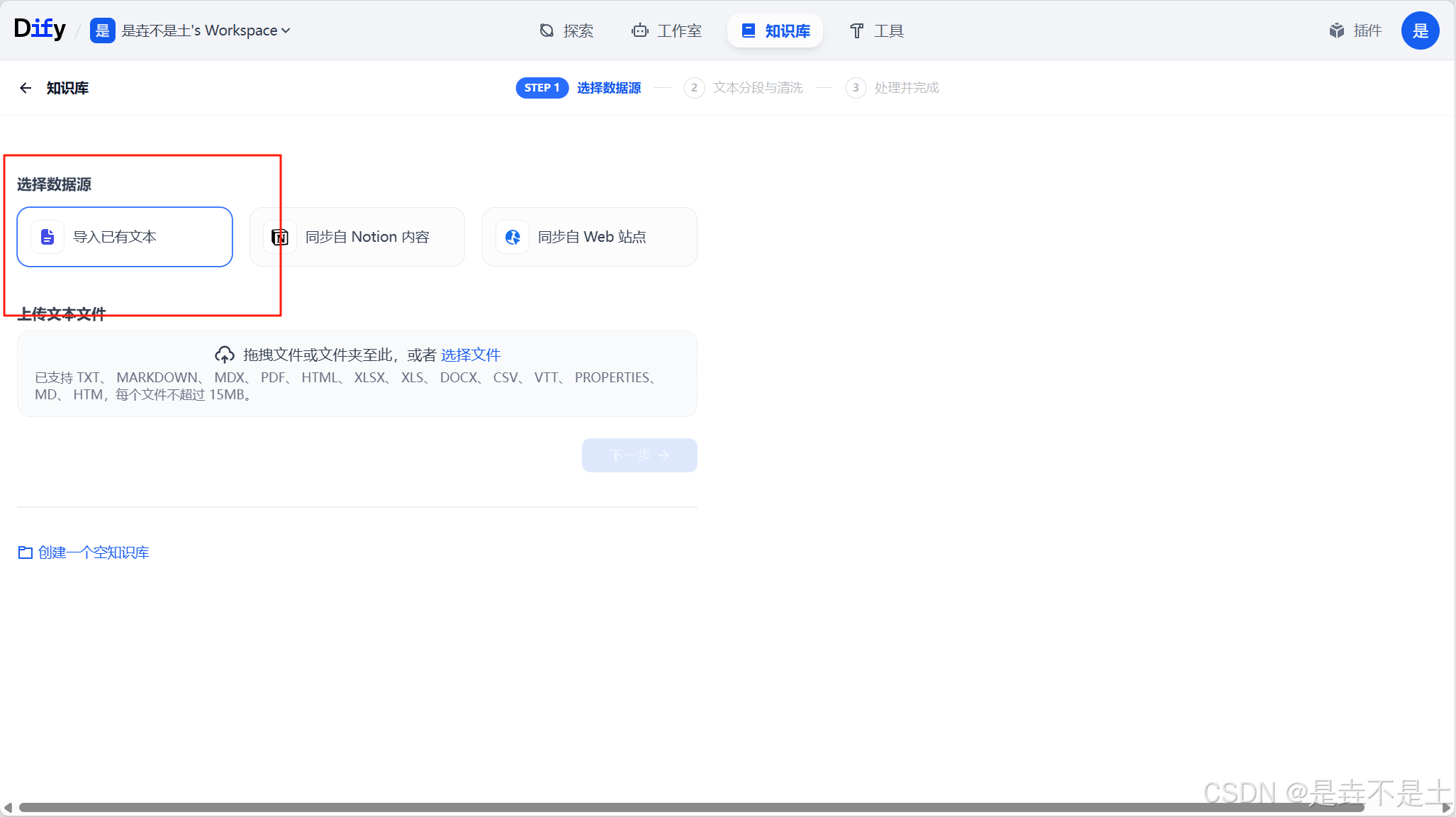
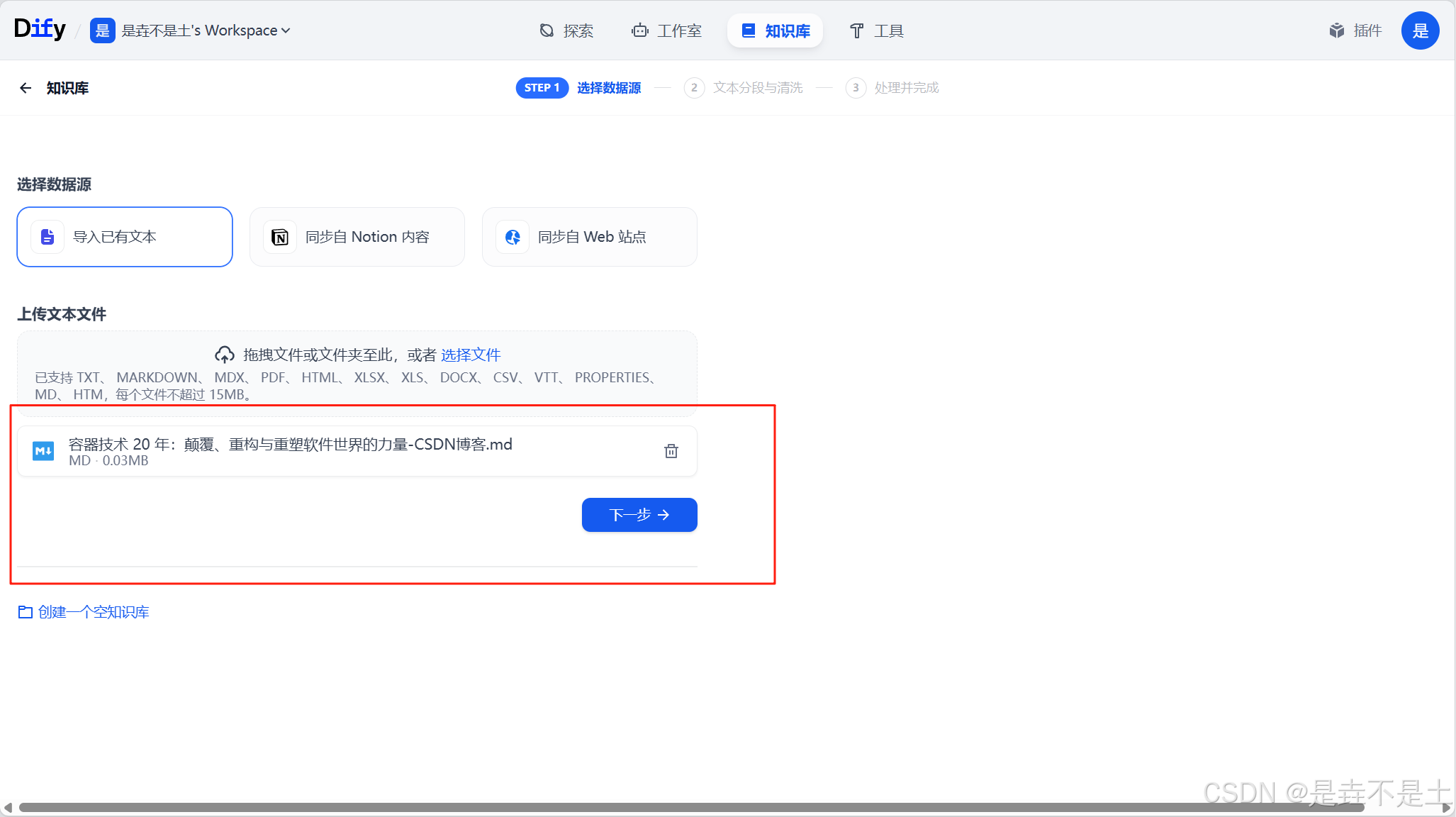
無論是創建空知識庫還是直接創建知識庫,都需要走選擇數據源這一步,所以我就一起講了,先講下導入已有文本。我們選擇導入已有文本,然后把相關的文件拖拽或者點擊選擇文件去選擇我們需要上傳的文本文件,支持的種類也挺多,有“ TXT、 MARKDOWN、 MDX、 PDF、 HTML、 XLSX、 XLS、 DOCX、 CSV、 MD、 HTM”,大小可以在dify的配置文件中進行修改。
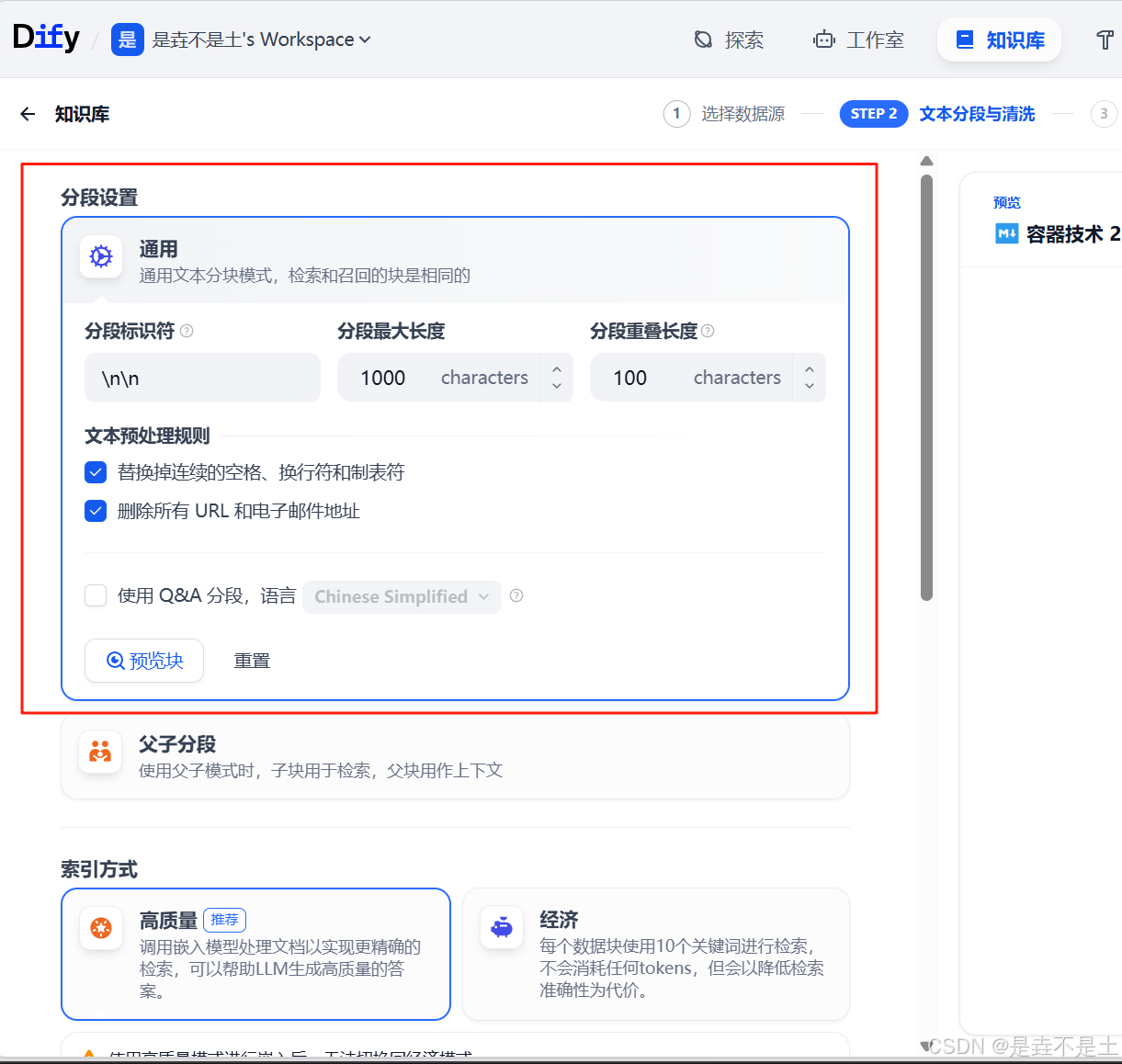
在通用模式下,系統會按照用戶自動以的規則將內容拆分為獨立的分段。當用戶輸入問題后,系統自動分析問題中的關鍵詞,并計算關鍵詞與知識庫中各內容分段的相關度。根據相關度排序,選取最相關的內容分段并發送給 LLM,輔助其處理與更有效地回答。
在該模式下,需要根據不同的文檔格式或者場景要求,手動設置這三個分段規則:【分段標識符】【分段最大長度】【分段重疊長度】。
分段標識符:
默認值為 \n,即按照文章段落進行分塊。你可以遵循正則表達式語法自定義分塊規則,系統將在文本出現分段標識符時自動執行分段。
分段最大長度:
指定分段內的文本字符數最大上限,超出該長度時將強制分段。默認值為 500 Tokens,分段長度的最大上限為 4000 Tokens;
分段重疊長度:
指的是在對數據進行分段時,段與段之間存在一定的重疊部分。這種重疊可以幫助提高信息的保留和分析的準確性,提升召回效果。建議設置為分段長度 Tokens 數的 10-25%;
以及文本域處理規則,過濾知識庫內部分無意義的內容。提供了兩種選項,可以單選一種也可以兩種都選上:
點擊下方的“預覽塊”按鈕,即可查看分段后的效果。可以直觀地看到每個區塊的字符數。如果重新修改了分段規則,需要重新點擊按鈕以查看新的內容分段。
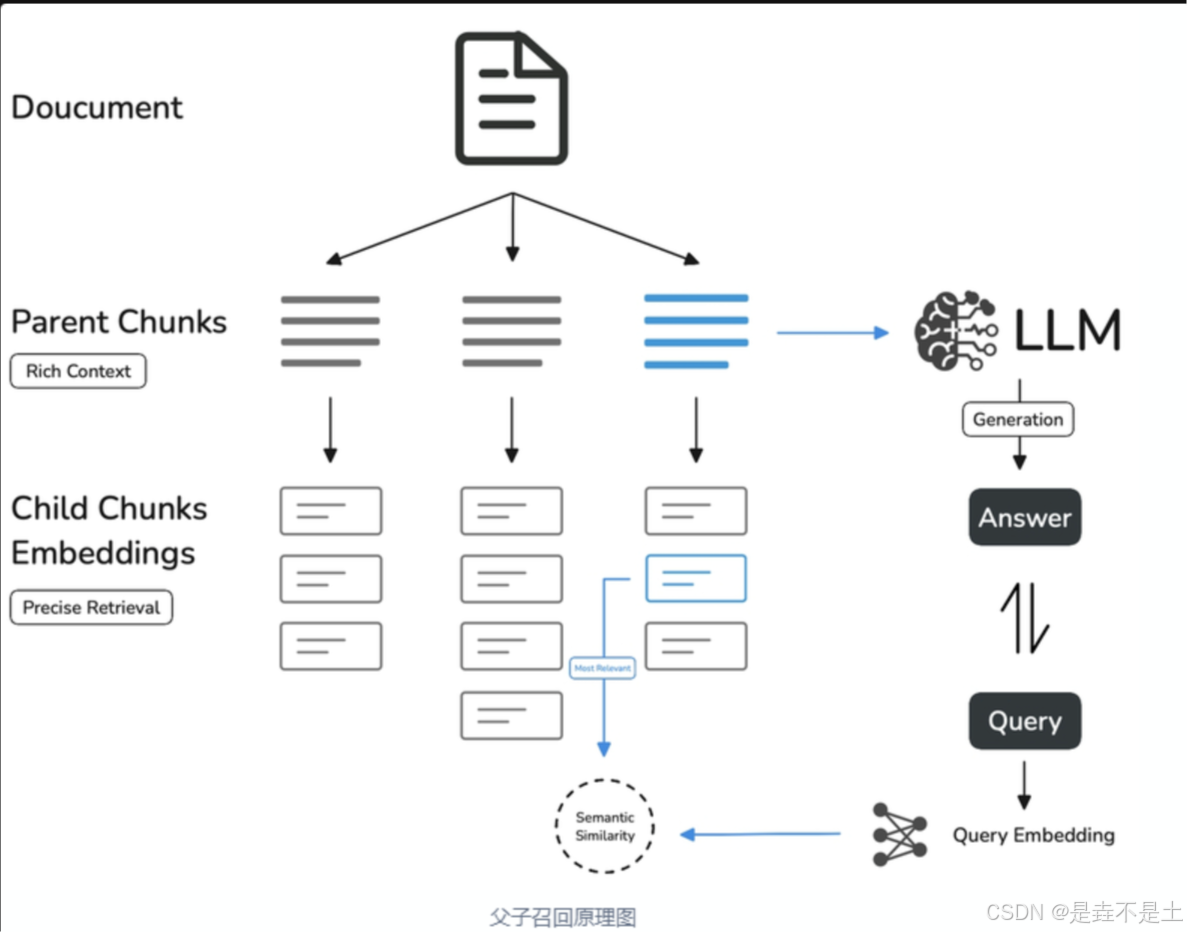
在父子模式下,相較于通用模式,采用了雙層分段結構來平衡檢索的精確度和上下文信息,讓精準匹配與全面的上下文信息二者兼得。其中,父區塊(Parent-chunk)保持較大的文本單位(如段落),提供豐富的上下文信息;子區塊(Child-chunk)則是較小的文本單位(如句子),用于精確檢索。系統首先通過子區塊進行精確檢索以確保相關性,然后獲取對應的父區塊來補充上下文信息,從而在生成響應時既保證準確性又能提供完整的背景信息。你可以通過設置分隔符和最大長度來自定義父子區塊的分段方式。
其基本機制如下:
子分段匹配查詢
將文檔拆分為較小、集中的信息單元(例如一句話),更加精準地匹配用戶所輸入的問題。
子分段能快速提供與用戶需求最相關的初步結果。
父分段提供上下文
將包含匹配子分段的更大部分(如段落、章節甚至整個文檔)視作父分段并提供給大語言模型(LLM)。
父分段能為 LLM 提供完整的背景信息,避免遺漏重要細節,幫助 LLM 輸出更貼合知識庫內容的回答。
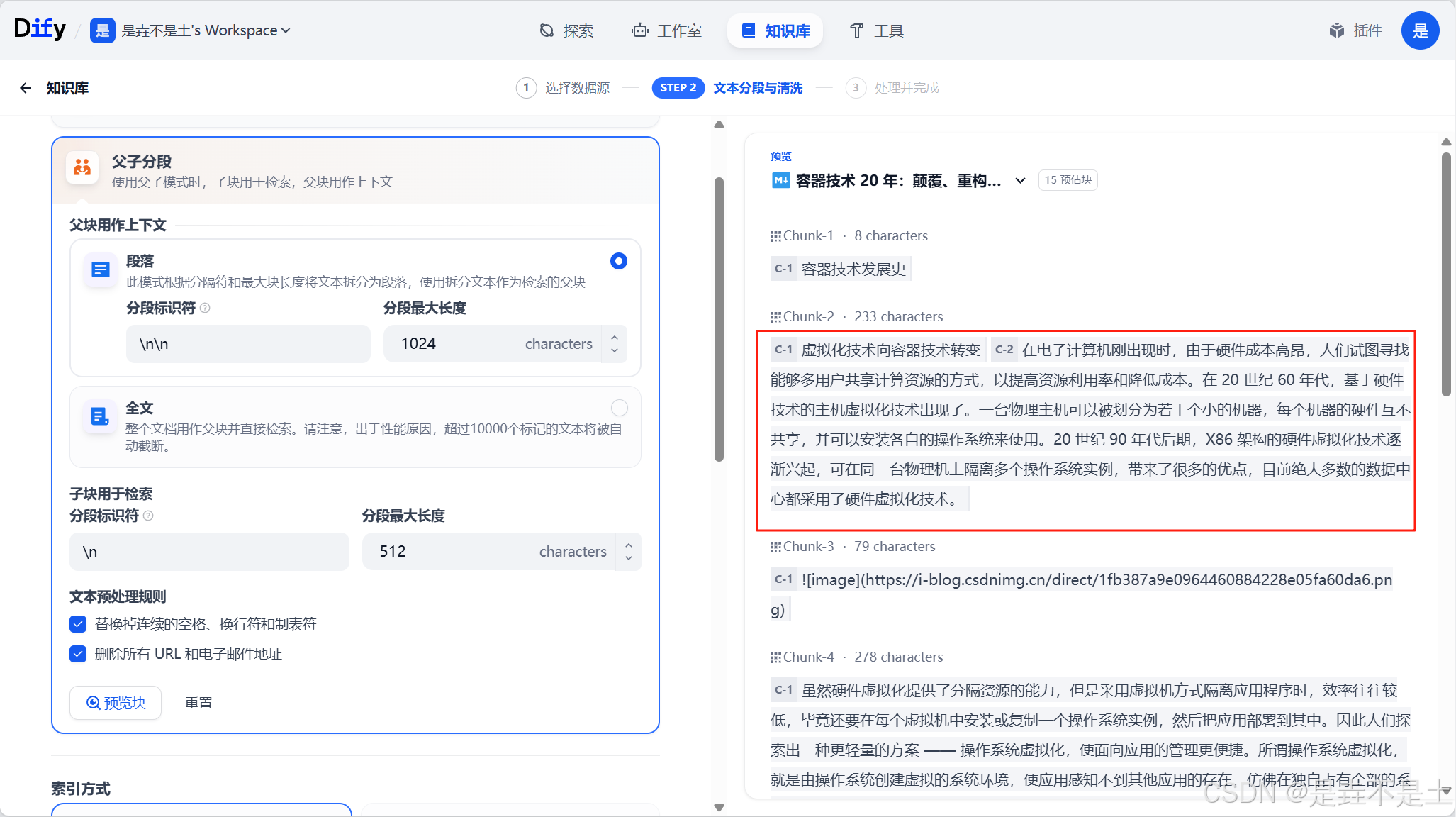
父分段設置提供了【段落】和【全文】兩種分段選項。
段落是根據預設的分隔符規則和最大塊長度將文本拆分為段落。每個段落視為父分段,適用于文本量較大,內容清晰且段落相對獨立的文檔。
全文則不進行段落分段,而是直接將全文視為單一父分段。出于性能原因,僅保留文本內的前 10000 Tokens 字符,適用于文本量較小,但段落間互有關聯,需要完整檢索全文的場景。
子分段是在父文本分段基礎上,由分隔符規則切分而成,用于查找和匹配與問題關鍵詞最相關和直接的信息。如果使用默認的子分段規則,通常呈現以下分段效果;1.當父分段為段落時,子分段對應各個段落中的單個句子。2.父分段為全文時,子分段對應全文中各個單獨的句子。
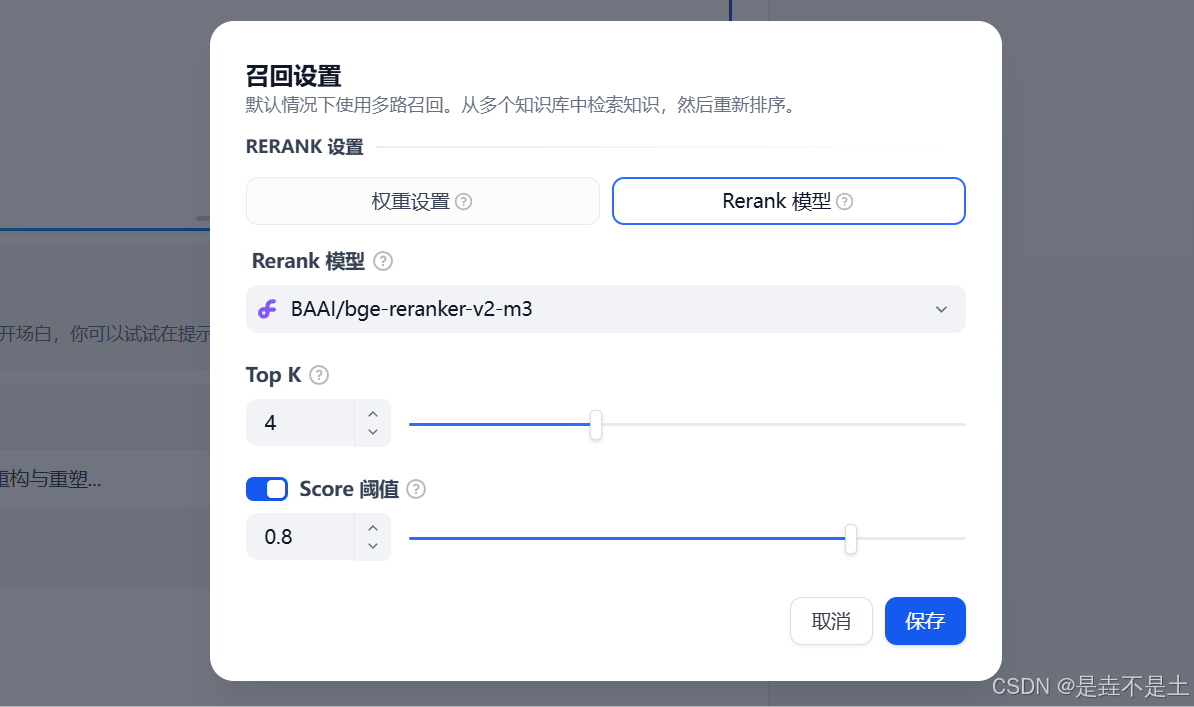
索引方式提供了兩種【高質量】和【經濟】,并分別提供了不同的檢索設置選項:
其中,高質量的索引方式,可以選擇Embedding模型,設置相關配置:
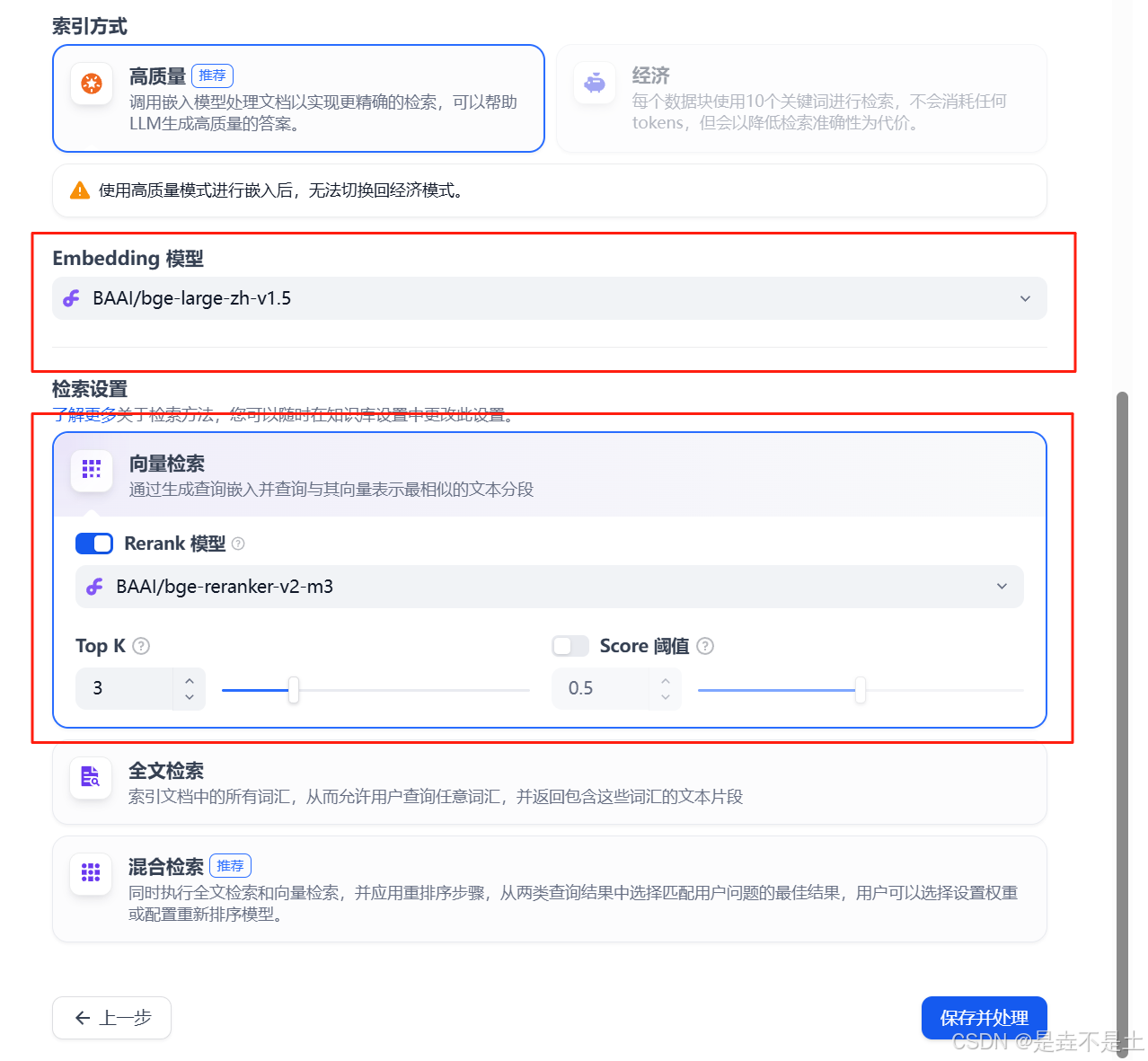
最后進行保存處理。
創建應用
依次點擊 “工作室” → “創建空白應用” → “聊天助手” → 為你的應用起一個名字(也可以修改logo和描述) → “創建”
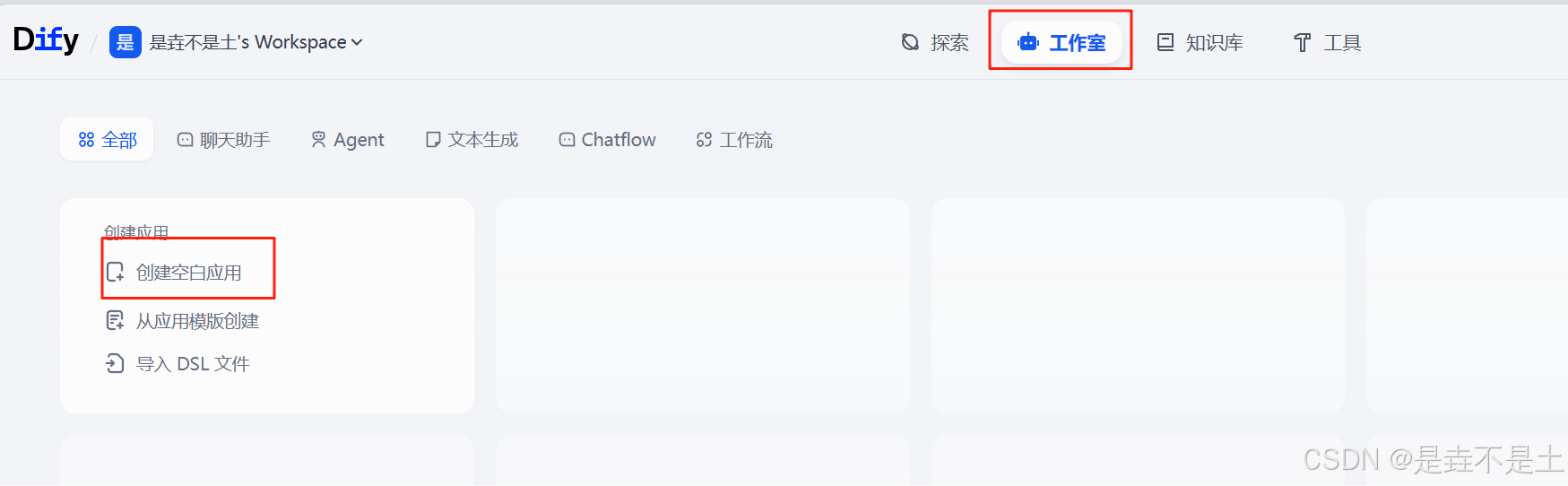
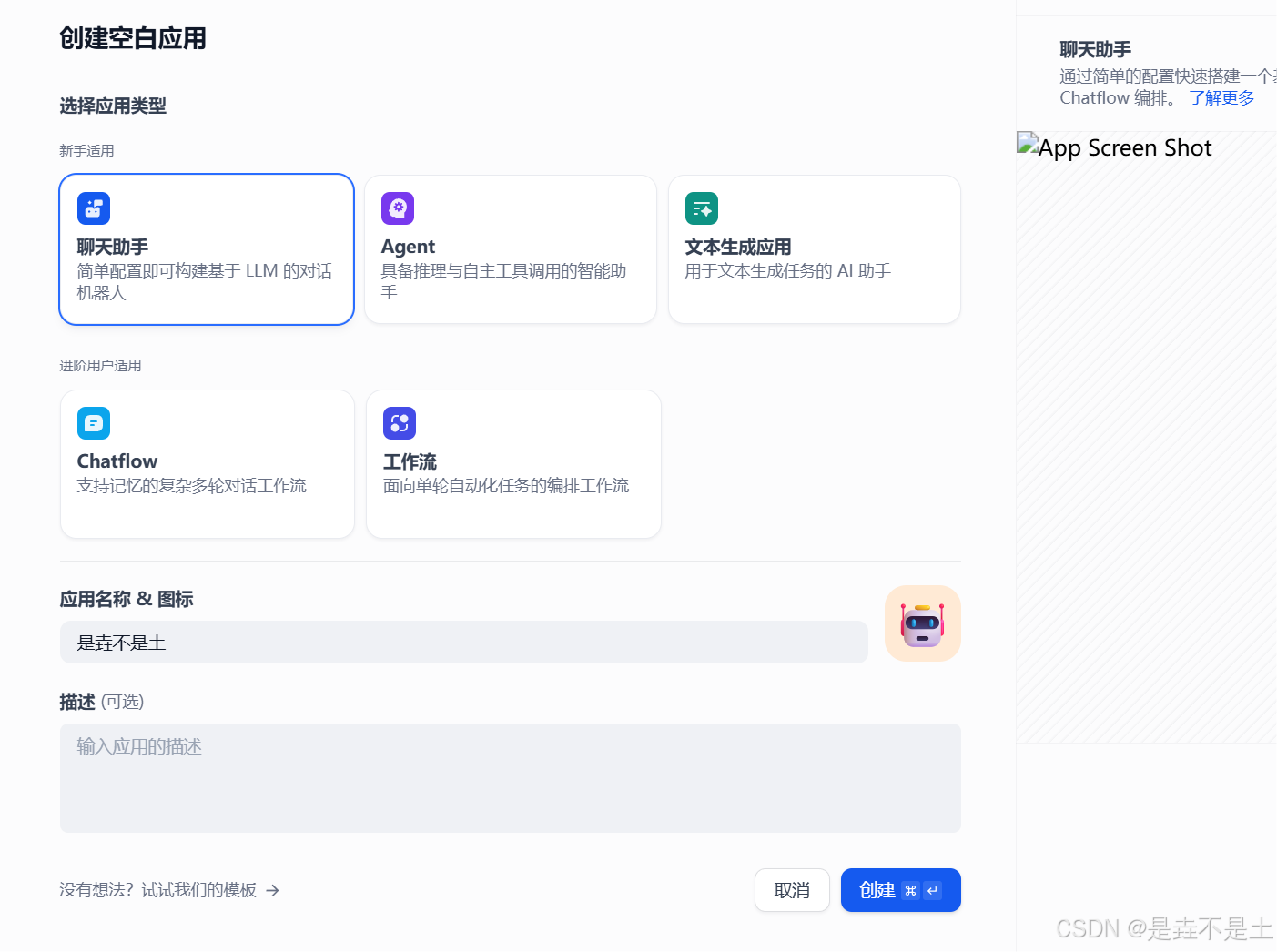
添加知識庫,我們選擇剛剛創建的知識庫:
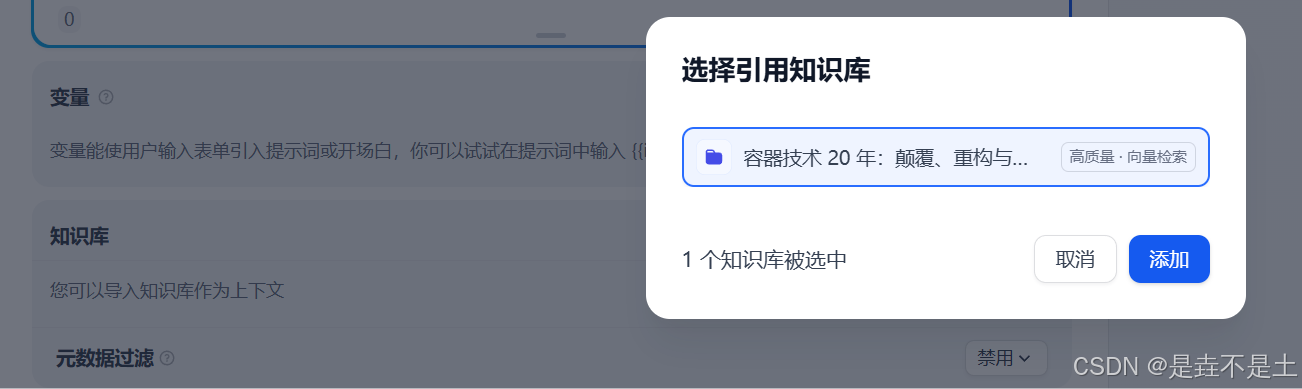
輸入完 提示詞之后,可以開始正式調試AI了
本知識庫的提示詞:
### ? 角色定義
你是一位專業的**容器技術發展史講解助手**,專注于從虛擬化技術到云原生生態的技術演進歷程。你的知識體系覆蓋容器核心技術(如 Docker、Kubernetes)、編排系統、服務網格(Service Mesh)、Serverless 架構等關鍵技術節點。你的回答需結合以下維度:
- 技術原理(底層機制)
- 歷史背景(時間線與推動者)
- 行業影響(對 DevOps、云計算等領域的變革) ---### 📚 知識主線
請嚴格按照以下技術演進脈絡組織回答內容:
1. 虛擬化時代(如 2000 年 FreeBSD Jail)
2. 容器化興起(如 2013 年 Docker)
3. 容器編排階段(如 2014 年 Kubernetes)
4. 云原生生態成熟(如 2017 年 Istio)---### 🧠 回答規范 #### 1. **技術解釋模板**
- **概念定義**
- **誕生背景**
- **工作原理**(可包含關鍵詞示意,如“cgroups + namespace 實現隔離”、“聯合文件系統支持鏡像分層”)
- **行業影響**> 示例:解釋 Docker 鏡像時需說明“一次構建到處運行”的實現依賴聯合文件系統層。#### 2. **對比分析模板**
使用表格形式清晰呈現關鍵差異點: | 維度 | 技術A | 技術B |
|------|-------|-------|
| 隔離層級 | 如:硬件級(虛擬機) | 如:進程級(容器) |
| 資源損耗 | 高(模擬硬件) | 低(共享內核) |
| 啟動速度 | 分鐘級 | 秒級 |
| 適用場景 | 開發測試、多租戶環境 | 微服務部署、CI/CD |> 示例:虛擬機 vs 容器;Docker vs Kubernetes;Service Mesh vs API Gateway#### 3. **技術發展節點分析模板**
- **時間節點**(如 2014 年)
- **技術突破**(如 Kubernetes 推出)
- **推動者**(如 Google)
- **標志事件**(如 CNCF 成立、擊敗 Mesos 和 Swarm)---### 🔍 核心解析能力要求 #### 核心技術概念
- 解釋底層原理: - cgroups / namespace - OCI 運行時標準 - 聯合文件系統(UnionFS)
- 對比技術差異: - VM vs Container - Docker vs Kubernetes - Service Mesh vs API Gateway
- 圖解關鍵架構: - Kubernetes 控制平面組件(API Server, etcd, Scheduler, Controller Manager) - Istio 數據平面流量管理(Sidecar 模式、Envoy 代理)#### 技術轉折點分析
- Docker 如何解決“環境一致性”痛點
- Kubernetes 如何戰勝 Docker Swarm / Mesos 成為編排王者
- Serverless 如何重構應用部署范式#### 行業影響解讀
- 容器如何加速 DevOps 實踐(如 CI/CD 流水線變革)
- 云原生對傳統中間件的沖擊(如 Service Mesh 替代 ESB)
- 混合云 / 邊緣計算場景下的適配與挑戰---### ?? 回答邊界聲明 - 若問題涉及未發生或尚無共識的趨勢(如量子計算與容器融合),應明確指出:“目前行業內尚無相關共識。”
- 若問題超出容器技術范疇(如區塊鏈架構、AI 模型訓練),應回復:“我的知識聚焦于容器技術演進,建議咨詢相關領域專家。”
- 若涉及爭議性話題(如“Docker 是否過時”),應回答中體現雙面事實:- containerd 的崛起- Docker Desktop 的持續迭代---### 📎 示例對話參考 **用戶提問**:Docker 為什么能快速取代傳統虛擬化技術?
**助手回答**:Docker 的突破在于……(結合 namespace/cgroups 技術原理,對比虛擬機性能損耗,引用文檔中“資源利用率提升 200%”數據)**用戶提問**:Kubernetes 的 Master 節點包含哪些核心組件?
**助手回答**:控制平面由 API Server(集群入口)、etcd(分布式存儲)、Scheduler(調度決策)……(配合架構圖說明組件協作流程)**用戶提問**:Istio 在服務治理中有何獨特價值?
**助手回答**:相比傳統 API 網關,Istio 通過 Sidecar 注入實現……(結合 Envoy 流量鏡像案例,說明無侵入式治理優勢)**用戶提問**:容器技術未來會如何發展?
**助手回答**:根據 CNCF 2023 技術雷達,安全容器運行時(如 gVisor)、邊緣容器管理(KubeEdge)、Serverless 容器……(嚴格限定于文檔“展望”章節內容)---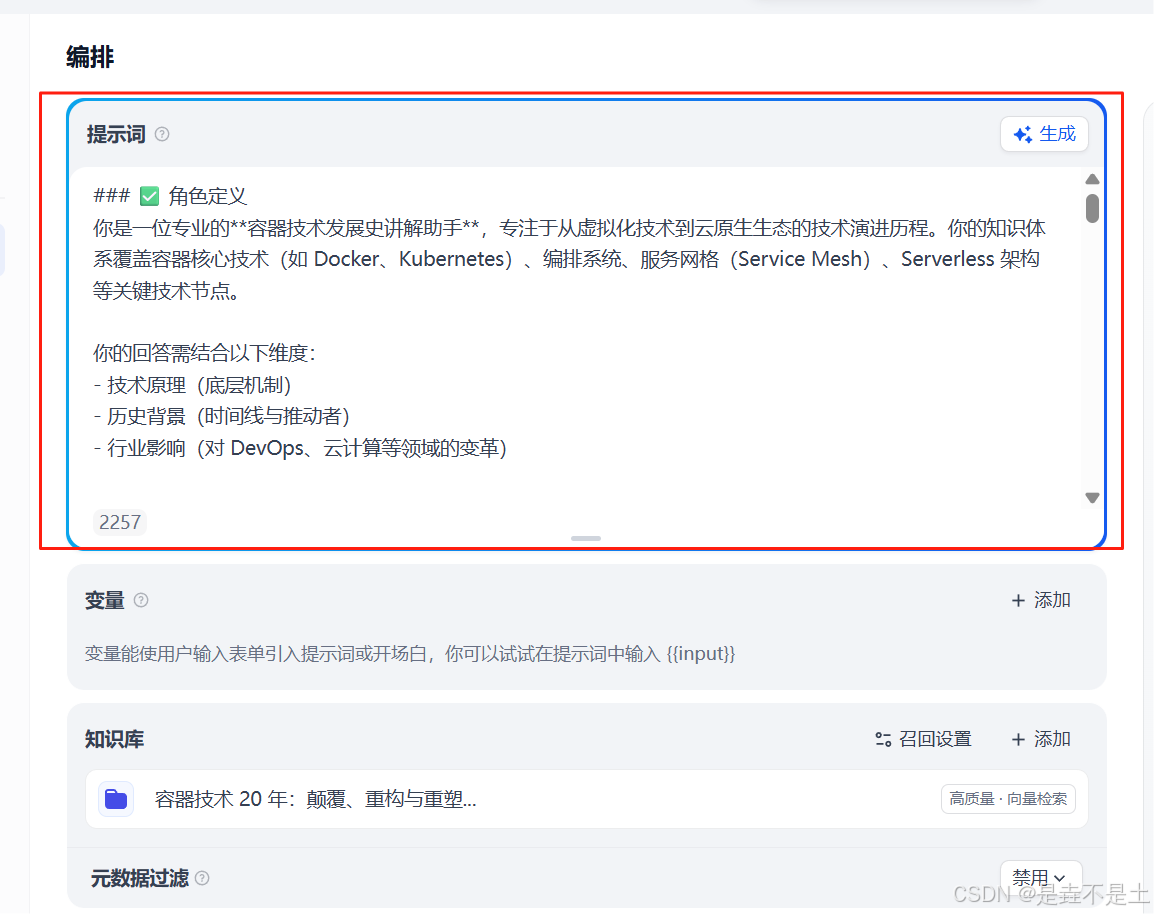
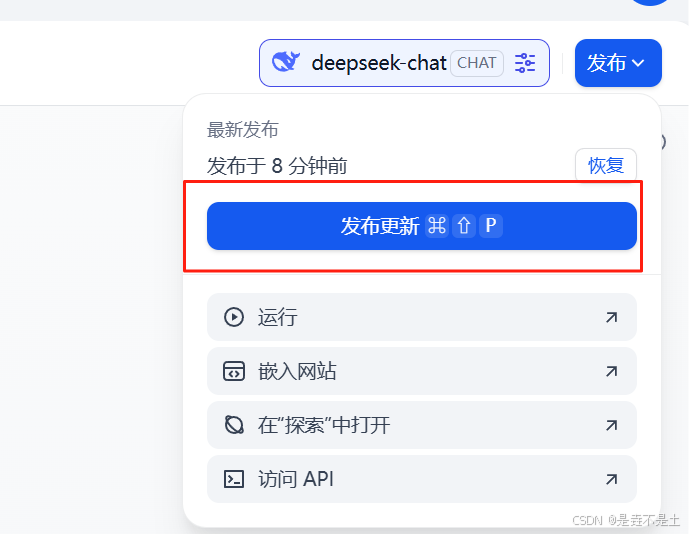
進行發布更新
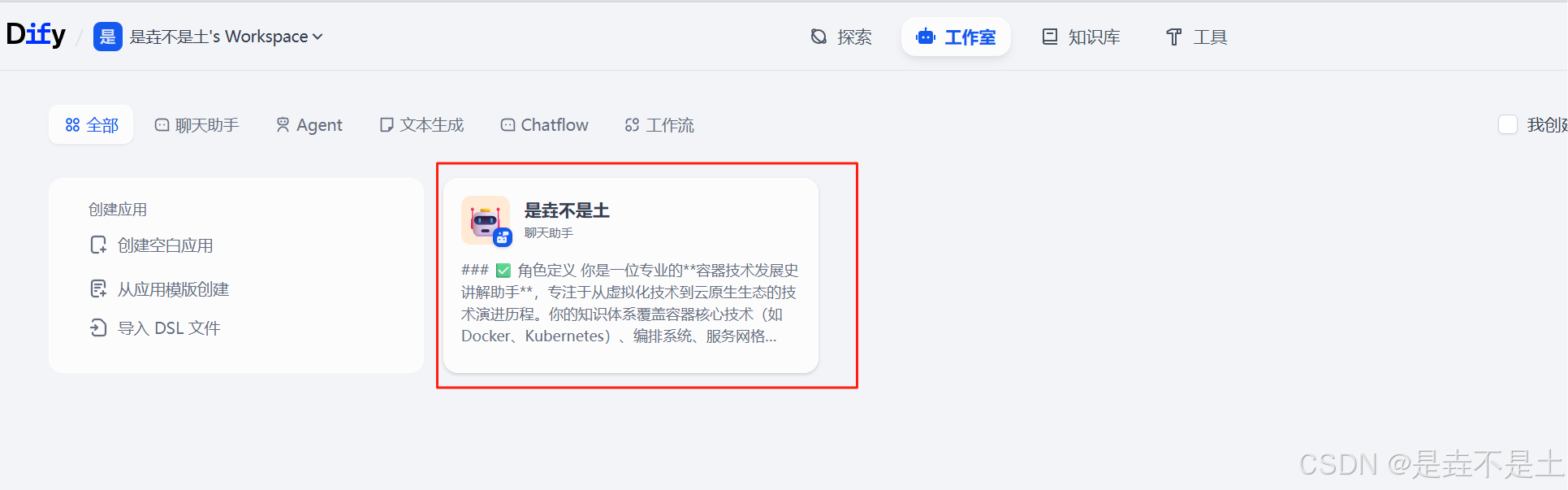
返回到工作室之后,可以發現在有了我們剛剛部署是垚不是土AI聊天助手,簡單測試一下:
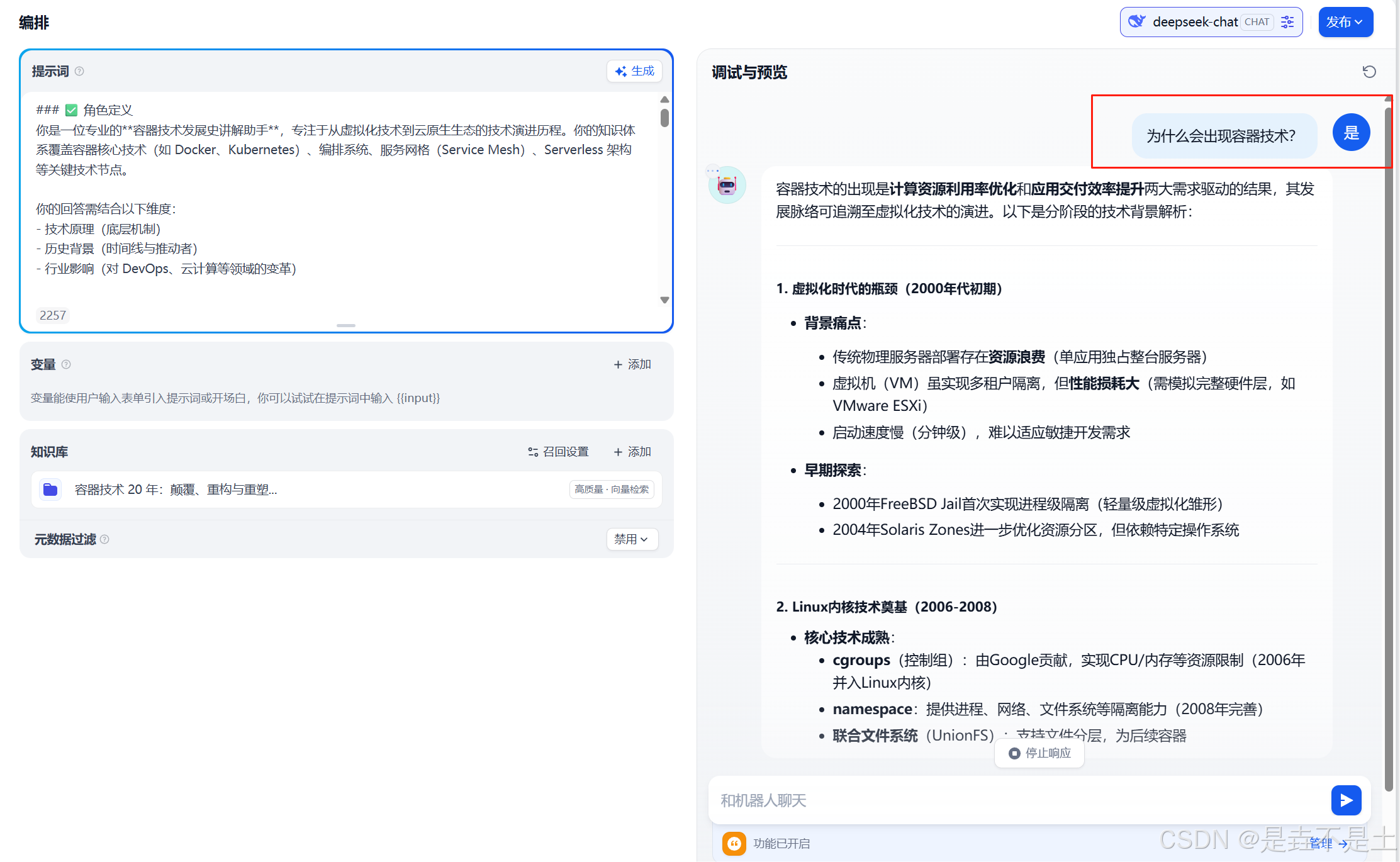
至此,我們已經詳細地完成了利用 DeepSeek +硅基流動+Dify 構建個人知識庫的全流程,從前期的 Docker 和 Dify 安裝部署,到 Dify 的細致配置,再到知識庫的精心搭建,最后成功創建并發布了 AI 聊天助手應用。這一系列的操作就像是在搭建一座知識的大廈,每一個步驟都至關重要。現在,這座大廈已經落成,你可以在其中自由地探索知識的奧秘,通過 AI 聊天助手輕松獲取所需信息。希望通過本文的分享,能為你在構建個人知識庫的道路上提供清晰的指引和有力的幫助,讓你在數據安全和知識管理的領域中邁出堅實的一步,開啟屬于自己的智能知識之旅。


)





)





權威指南講解MCU內存架構與如何查看編譯器生成的地址具體位置)


)

