RNN神經網絡
1-核心知識
- 1-解釋RNN神經網絡
- 2-RNN和傳統的神經網絡有什么區別?
- 3-RNN和LSTM有什么區別?
- 4-transformer的歸一化有哪幾種實現方式
2-知識問答
1-解釋RNN神經網絡
Why:與我何干?
在我們的生活中,很多事情是有先后順序的,比如聽一首歌,歌詞是一句接一句的;看一部電影,情節是一幕接一幕的。如果能讓計算機像我們一樣理解這種順序,就能更好地處理語言、音樂、視頻等很多問題。RNN神經網絡就是一種能讓計算機處理這種順序信息的工具,它可以用來做語音識別、翻譯、寫作助手等等,讓機器更好地理解我們。
What:定義、概念解釋,可以做什么
**RNN神經網絡(Recurrent Neural Network)**是一種神經網絡,它和普通的神經網絡不一樣,普通的神經網絡是把輸入直接變成輸出,而RNN神經網絡可以記住之前的信息,就像我們人類一樣,會把之前看到的東西記在心里,然后用這些記憶來理解現在看到的東西。比如,你看到一個故事的前半部分,就會根據這些內容來理解后半部分。RNN神經網絡也可以做到這一點,它能夠處理像句子、時間序列數據(比如股票價格的變化)這樣有先后順序的信息。
How:步驟流程方法,以及解釋所需的任何主題內容
RNN神經網絡的工作方式有點像一個接力賽。想象一下,你和朋友們在接力賽中,每個人手里都拿著一個接力棒,這個接力棒就像RNN神經網絡中的“記憶”。當一個新的信息(比如一個單詞)進來的時候,RNN神經網絡會把之前的記憶(也就是之前的接力棒)和這個新的信息結合起來,然后更新一下記憶,再把更新后的記憶傳遞給下一個時刻。這個過程會一直重復下去,就像接力賽一樣,每一個時刻的輸出都和之前的信息有關。
舉個例子,假設你正在讀一個故事,RNN神經網絡就像是你在讀這個故事的時候,每讀到一個新的句子,就會把之前讀到的內容(記憶)和這個新的句子結合起來,然后更新一下你對整個故事的理解。這樣,當你讀到后面的內容時,就能更好地理解整個故事的情節。
How good:可以給聽眾帶來什么好處,什么改變
RNN神經網絡的好處在于它能夠處理有先后順序的信息,這在很多實際應用中都非常有用。比如在語音識別中,它可以更好地理解語音中的單詞順序;在翻譯中,它可以更好地理解句子的結構,從而翻譯得更準確;在預測股票價格時,它可以利用之前的價格變化來預測未來的價格。通過這種方式,RNN神經網絡讓計算機能夠更好地處理和理解我們生活中的各種順序信息,讓機器變得更加智能。
2-RNN和傳統的神經網絡有什么區別?
Why:與我何干?
了解RNN神經網絡和傳統神經網絡的區別,可以幫助你更好地選擇適合的工具來解決不同的問題。比如,如果你要處理像句子、視頻、音樂這樣有先后順序的信息,RNN神經網絡可能更適合;而如果你要處理像圖片這樣沒有順序關系的信息,傳統神經網絡可能就足夠了。
What:定義、概念解釋,可以做什么
- 傳統神經網絡(Feedforward Neural Network):這種神經網絡就像一個工廠的流水線,信息從輸入端進去,經過一層層的處理,最后從輸出端出來。每一層的處理都是獨立的,不會受到之前輸入的影響。它主要用于處理沒有先后順序的信息,比如圖片識別,因為圖片的像素點之間沒有先后順序。
- RNN神經網絡(Recurrent Neural Network):這種神經網絡就像一個有記憶的人,它不僅能處理當前的信息,還能記住之前的信息,并用這些記憶來影響當前的處理結果。它主要用于處理有先后順序的信息,比如句子、時間序列數據(股票價格變化)等。
How:步驟流程方法,以及解釋所需的任何主題內容
我們用一個簡單的例子來說明它們的區別:
- 傳統神經網絡:假設你在做一個水果分類的任務,輸入是一張水果的圖片,輸出是這個水果的種類(比如蘋果、香蕉)。傳統神經網絡會把這張圖片的像素點輸入進去,經過幾層處理,最后輸出這個水果的種類。它不會考慮之前輸入的圖片,每次都是獨立處理。
- RNN神經網絡:假設你在做一個語言翻譯的任務,輸入是一個句子,輸出是這個句子的翻譯。RNN神經網絡會一個詞一個詞地處理這個句子,每處理一個詞,它都會把之前處理的詞的信息(記憶)用上。比如,它看到“我”這個詞的時候,會記住這個信息;當它看到“喜歡”這個詞的時候,它會結合之前“我”的信息來理解;當它看到“吃蘋果”這個詞的時候,它會結合前面“我”和“喜歡”的信息,最后輸出翻譯結果。這個過程中,RNN神經網絡就像一個有記憶的人,能夠利用之前的信息來更好地理解當前的信息。
How good:可以給聽眾帶來什么好處,什么改變
了解這兩種神經網絡的區別,可以幫助你更好地選擇適合的工具來解決問題。如果你的任務是處理像圖片、表格這樣沒有先后順序的信息,傳統神經網絡就足夠了;而如果你的任務是處理像語言、視頻、股票價格這樣有先后順序的信息,RNN神經網絡會更有優勢。這樣,你就能更高效地解決問題,讓機器更好地幫助你。
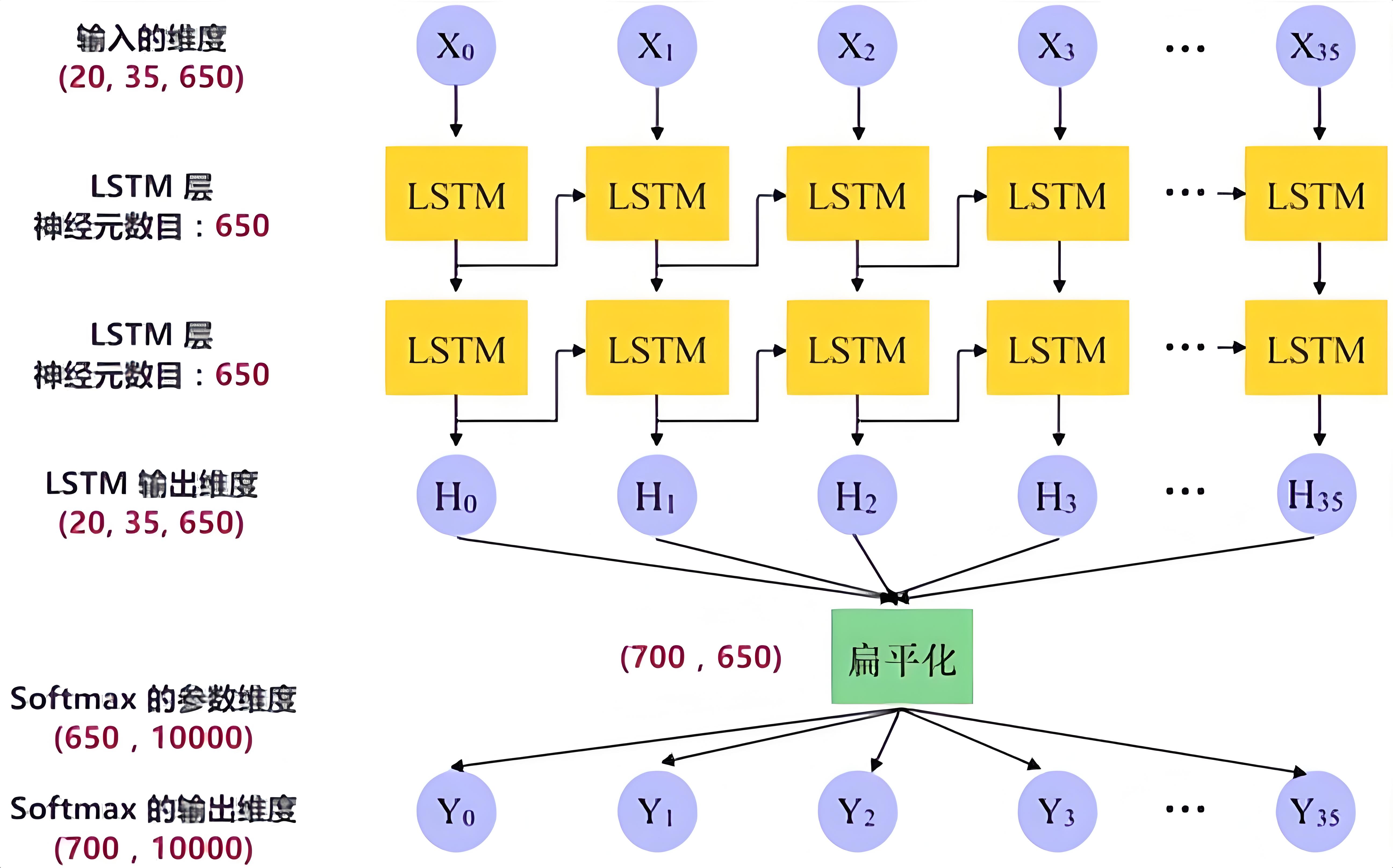
3-RNN和LSTM有什么區別?
好的,我來幫你理解RNN和LSTM的區別。
Why:與我何干?
RNN和LSTM都是用來處理有先后順序信息的神經網絡,比如語言、時間序列等。但它們在處理長距離依賴關系(比如句子中前面的單詞對后面的單詞的影響)時表現不同。了解它們的區別,可以幫助你選擇更適合的工具來解決具體問題,比如在翻譯、語音識別或者股票價格預測等任務中。
What:定義、概念解釋,可以做什么
- RNN(Recurrent Neural Network):RNN是一種神經網絡,它能夠記住之前的信息,并用這些信息來處理當前的信息。比如,它可以把一個句子一個詞一個詞地處理,每處理一個詞,就會結合之前詞的信息來理解當前的詞。
- LSTM(Long Short-Term Memory):LSTM是一種改進版的RNN。它專門用來解決RNN在處理長距離依賴關系時遇到的問題。比如,在一個很長的句子中,RNN可能會忘記句子開頭的信息,而LSTM可以更好地記住這些信息,從而更好地理解整個句子。
How:步驟流程方法,以及解釋所需的任何主題內容
我們用一個簡單的例子來說明它們的區別:
- RNN:想象你在讀一個很長的故事,RNN就像是一個記憶力有限的人。它一邊讀一邊記,但讀到后面的時候,可能會忘記前面的內容。比如,故事開頭提到一個人物的名字,但讀到后面的時候,RNN可能就忘了這個名字,導致理解后面的情節時出現困難。
- LSTM:LSTM就像是一個有超強記憶力的人。它也有記憶,但它有一個特殊的機制,可以決定哪些信息是重要的,需要長期記住;哪些信息是暫時的,可以忘記。比如,故事開頭提到一個人物的名字,LSTM會記住這個名字,并在后面的情節中用到它。即使故事很長,LSTM也能很好地記住重要的信息,從而更好地理解整個故事。
具體來說,LSTM有一個復雜的結構,它有三個“門”(輸入門、遺忘門、輸出門):
- 輸入門:決定哪些新信息需要加入到記憶中。
- 遺忘門:決定哪些舊信息需要忘記。
- 輸出門:決定哪些信息需要輸出。
通過這些“門”,LSTM可以更好地控制信息的流動,從而避免像RNN那樣容易忘記重要信息的問題。
How good:可以給聽眾帶來什么好處,什么改變
- RNN:優點是簡單,計算速度快,適合處理比較短的序列信息。比如,處理一個很短的句子或者一小段時間序列數據。但它的缺點是容易忘記長距離的信息,這在處理長句子或者長序列數據時會成為一個問題。
- LSTM:優點是可以很好地處理長距離依賴關系,適合處理長句子、長序列數據。比如,在翻譯、語音識別或者股票價格預測等任務中,LSTM可以更好地記住前面的信息,從而提高處理的準確性。但它的缺點是結構復雜,計算速度比RNN慢。
了解它們的區別后,你可以根據具體任務的需求來選擇合適的工具。如果你的任務序列比較短,RNN可能就足夠了;如果你的任務序列比較長,LSTM會是一個更好的選擇。
4-transformer的歸一化有哪幾種實現方式
好的,我們來用費曼技巧來解釋“Transformer 的歸一化實現方式”,難度等級是 D=2。
Why(與我何干?)
在 Transformer 模型中,歸一化是一種非常重要的操作。它可以幫助模型更好地學習和訓練,避免數值不穩定的問題,就像給模型的輸入數據“穿上了合適的鞋子”,讓模型能夠更平穩地“走路”。
What(定義、概念解釋,可以做什么)
歸一化(Normalization)是一種對數據進行處理的方法,它的目的是讓數據的分布更加均勻,通常會把數據縮放到一個固定的范圍內,比如 0 到 1 或者 -1 到 1。在 Transformer 模型中,歸一化可以防止某些數值過大或過小,從而影響模型的訓練效果。
How(步驟流程方法,以及解釋所需的任何主題內容)
Transformer 中主要有以下幾種歸一化實現方式:
-
Layer Normalization(層歸一化)
📐 解釋:這是最常用的一種歸一化方式。它對每一層的輸入數據進行歸一化處理。具體來說,它會計算每一層中每個樣本的均值和標準差,然后用這些值對數據進行調整。
📝 步驟:- 計算每一層中每個樣本的均值 (\mu) 和標準差 (\sigma)。
- 對每個樣本的數據 (x) 進行歸一化:(\hat{x} = \frac{x - \mu}{\sigma})。
- 通常還會引入兩個可學習的參數 (\gamma) 和 (\beta),對歸一化后的數據進行縮放和偏移:(y = \gamma \hat{x} + \beta)。
📚 例子:想象你有一堆不同大小的蘋果,你希望它們的大小都差不多,所以你先算出這些蘋果的平均大小和大小的波動范圍,然后根據這些值調整每個蘋果的大小,最后還可以根據需要把蘋果放大或縮小一點。
-
Post-Normalization(后歸一化)
📝 解釋:這種歸一化方式是在每一層的計算完成后再進行歸一化。也就是說,先進行自注意力計算和前饋網絡的計算,然后再對結果進行歸一化。
📚 例子:就好像你先做完了所有的作業,然后最后再檢查一遍,確保作業的質量。 -
Pre-Normalization(前歸一化)
📝 解釋:這種歸一化方式是在每一層的計算之前先進行歸一化。也就是說,先對輸入數據進行歸一化,然后再進行自注意力計算和前饋網絡的計算。
📚 例子:就好像你先檢查一下作業的格式和內容,確保沒有問題后再開始寫作業。 -
RMS Normalization(均方根歸一化)
📐 解釋:這是一種改進的歸一化方法,它只使用數據的均方根值來進行歸一化,而不是同時使用均值和標準差。這樣可以避免某些情況下均值為零的情況,讓歸一化更加穩定。
📝 步驟:- 計算每一層中每個樣本的均方根值 (\text{RMS}(x) = \sqrt{\frac{1}{n}\sum_{i=1}{n}x_i2})。
- 對每個樣本的數據 (x) 進行歸一化:(\hat{x} = \frac{x}{\text{RMS}(x)})。
📚 例子:想象你有一堆不同高度的積木,你希望它們的高度都差不多,所以你先算出這些積木高度的平方和的平均值,然后根據這個值調整每個積木的高度。
How Good(可以給聽眾帶來什么好處,什么改變)
- 穩定訓練:歸一化可以防止數值不穩定,讓模型訓練更加平穩。
- 加速收斂:通過歸一化,模型可以更快地找到最優解,就像給模型“加油”一樣。
- 提高性能:合適的歸一化方法可以讓模型的性能更好,比如在翻譯、分類等任務中表現得更準確。

)






![[密碼學實戰]使用C語言實現TCP服務端(二十九)](http://pic.xiahunao.cn/[密碼學實戰]使用C語言實現TCP服務端(二十九))

在邊緣設備的算力分配策略:MoE架構實戰分析)
)
-后端 請求頭校驗,jwt退出登錄,mybaits實現數據庫用戶校驗)
APC注入)



)
openjdk17 c++源碼垃圾回收安全點信號函數處理線程阻塞)
