《DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model》
2024年10月發表,來自香港大學、浙江大學、華為和悉尼大學。
????????多模態大型語言模型(MLLM)已成為研究界關注的一個突出領域,因為它們擅長處理和推理非文本數據,包括圖像和視頻。本研究旨在通過引入DriveGPT4,將MLLM的應用擴展到自動駕駛領域,DriveGPT4是一種基于LLM的新型可解釋端到端自動駕駛系統。DriveGPT4能夠處理多幀視頻輸入和文本查詢,便于解釋車輛動作,提供相關推理,并有效解決用戶提出的各種問題。此外,DriveGPT4以端到端的方式預測低級車輛控制信號。這些高級功能是通過利用專門為自動駕駛應用量身定制的定制視覺指令調優數據集,結合混合微調訓練策略來實現的。DriveGPT4代表了利用LLM開發可解釋的端到端自動駕駛解決方案的開創性努力。對BDD-X數據集進行的評估顯示,DriveGPT4具有卓越的定性和定量性能。此外,與GPT4-V相比,對特定領域數據的微調使DriveGPT4在自動駕駛接地方面能夠產生接近甚至改進的結果。
?
1. 研究背景與動機
-
問題提出:傳統自動駕駛系統采用模塊化設計(感知、規劃、控制),但面對未知場景時易失效。端到端學習系統雖能直接預測控制信號,但因其“黑盒”特性缺乏可解釋性,阻礙商業化應用。
-
現有不足:現有可解釋性研究多基于小規模語言模型,回答模式僵化,難以應對多樣化用戶提問。
-
解決方案:利用大語言模型(LLM)的強推理能力和多模態處理能力,提出DriveGPT4,實現可解釋的端到端自動駕駛,同時生成自然語言解釋和低層次控制信號。
2. 核心貢獻
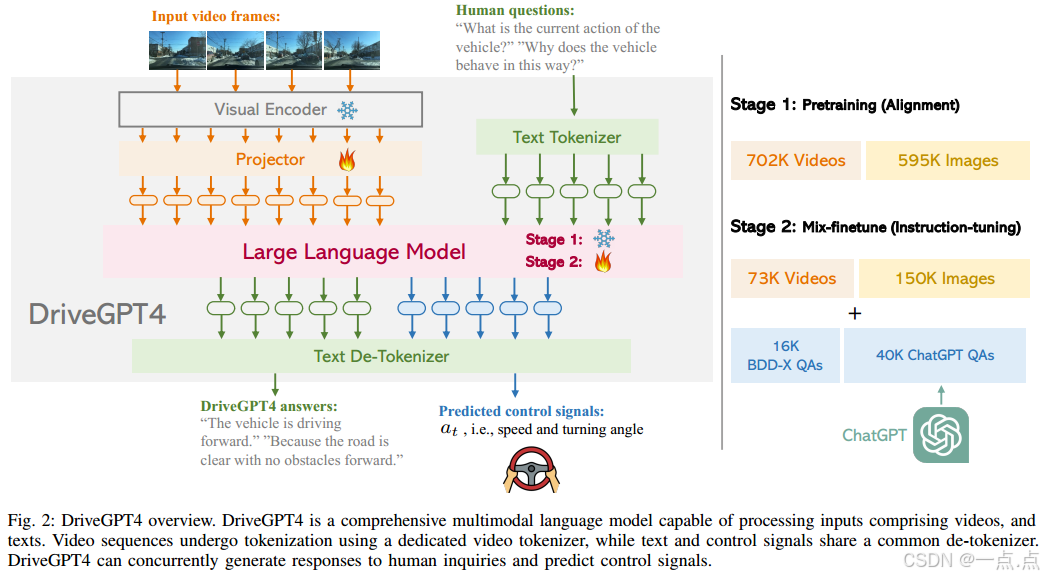
-
DriveGPT4模型:
-
多模態輸入:支持視頻(多幀圖像)和文本輸入,通過專用視頻tokenizer將視頻幀映射為文本域特征。
-
雙輸出能力:生成自然語言回答(動作描述、理由等)和低層次控制信號(速度、轉向角)。
-
架構設計:基于LLaMA2,結合CLIP視覺編碼器提取時空特征,控制信號與文本共享解tokenizer(類似RT-2)。
-
-
數據集構建:

-
基于BDD-X數據集(20K樣本),通過ChatGPT生成多樣化問答對(56K樣本),包括動作描述、理由、控制信號預測及靈活對話。
-
解決傳統數據集固定格式問題,提升模型泛化能力。
-
-
混合微調策略:
-
預訓練:通用圖像和視頻-文本對(CC3M + WebVid-2M),對齊多模態特征。
-
混合微調:結合56K自動駕駛領域數據(BDD-X + ChatGPT生成)和223K通用指令數據(LLaVA、Valley),增強視覺理解和領域適應能力。
-
3. 實驗與結果
-
數據集與評測:
-
BDD-X測試集:劃分為簡單(Easy)、中等(Medium)、復雜(Hard)場景,評估動作描述、理由生成、控制信號預測。
-
指標:自然語言生成采用CIDEr、BLEU4、ROUGE-L;控制信號預測采用RMSE和閾值準確率(AτAτ?)。
-
-
關鍵結果:
-
可解釋性任務:DriveGPT4在動作描述(CIDEr 256.03 vs. ADAPT 227.93)和理由生成(CIDEr 98.71 vs. 80.00)上顯著優于基線。
-
控制信號預測:速度預測RMSE 1.30(優于ADAPT的1.69),轉向角RMSE 8.98(優于9.97)。
-
泛化能力:在NuScenes數據集和視頻游戲中零樣本測試成功,展示跨領域適應性。
-
對比GPT4-V:DriveGPT4在動態行為理解和控制信號預測上更具優勢(GPT4-V無法預測數值控制信號)。
-
4. 技術亮點
-
視頻處理:通過時空特征池化(Temporal & Spatial Pooling)高效編碼多幀視頻信息。
-
控制信號嵌入:將數值控制信號視為“語言”,利用LLM的解碼能力直接生成。
-
混合微調:結合領域數據與通用數據,緩解幻覺問題(如檢測虛假車輛)。
5. 局限與未來方向
-
實時性:未支持長序列輸入(如32幀視頻),受限于計算資源與推理速度。
-
閉環控制:當前為開環預測,未來需結合強化學習實現閉環控制。
-
數據擴展:計劃通過CARLA仿真生成更多指令數據,增強復雜場景下的推理能力。
6. 總結
DriveGPT4首次將大語言模型引入可解釋端到端自動駕駛系統,通過多模態輸入處理、混合微調策略和靈活的輸出設計,實現了自然語言解釋與控制信號預測的雙重目標。實驗表明其在復雜場景下的優越性能,為零樣本泛化和實際應用奠定了基礎。未來研究可進一步優化實時性、閉環控制及數據多樣性。
?如果此文章對您有所幫助,那就請點個贊吧,收藏+關注 那就更棒啦,十分感謝!!!?





)





安裝與部署)




:LangChain Model模型)


