1. 如何設計數據庫

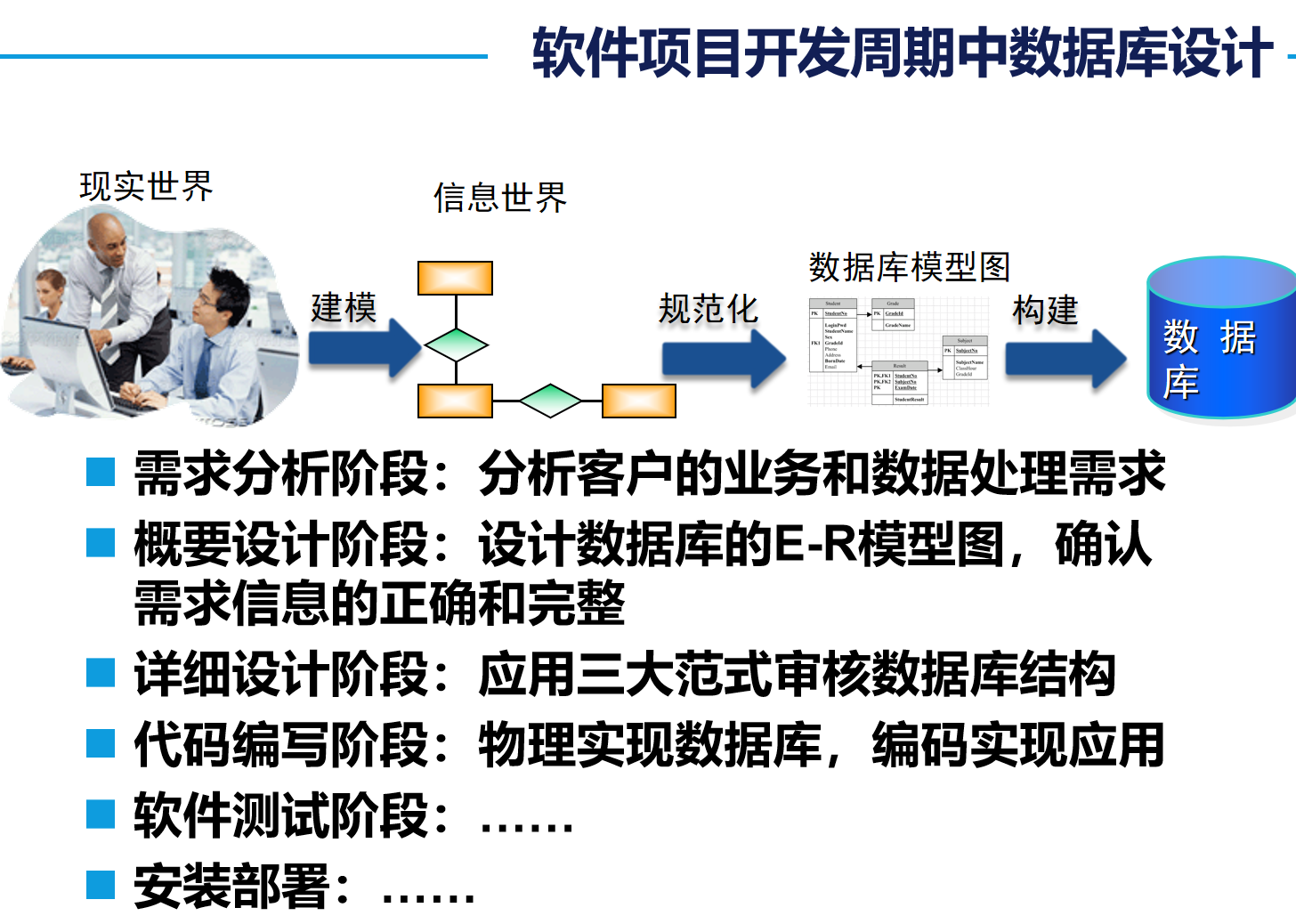
? ? ? ? 設計數據庫步驟




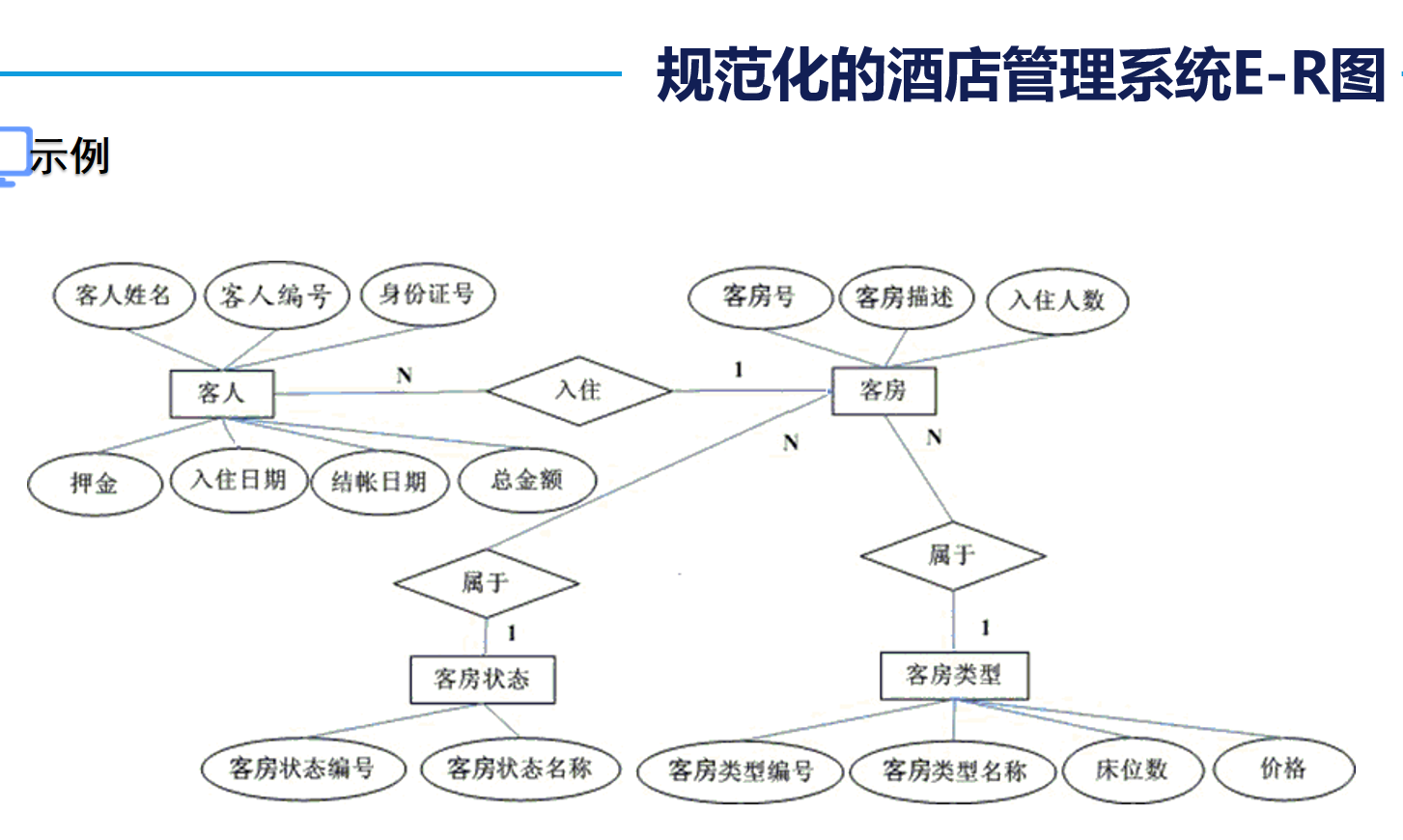
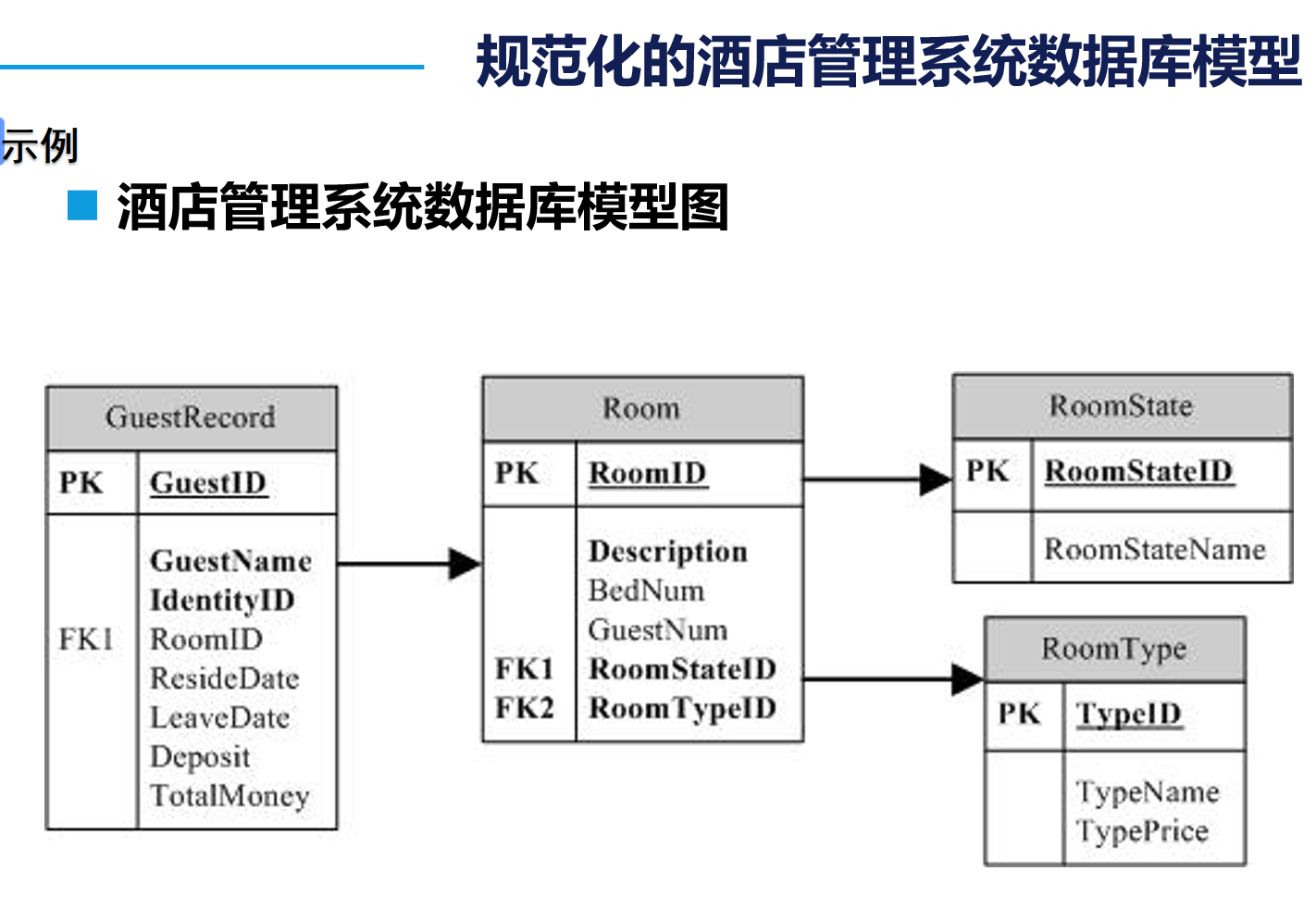
2. E-R圖的使用
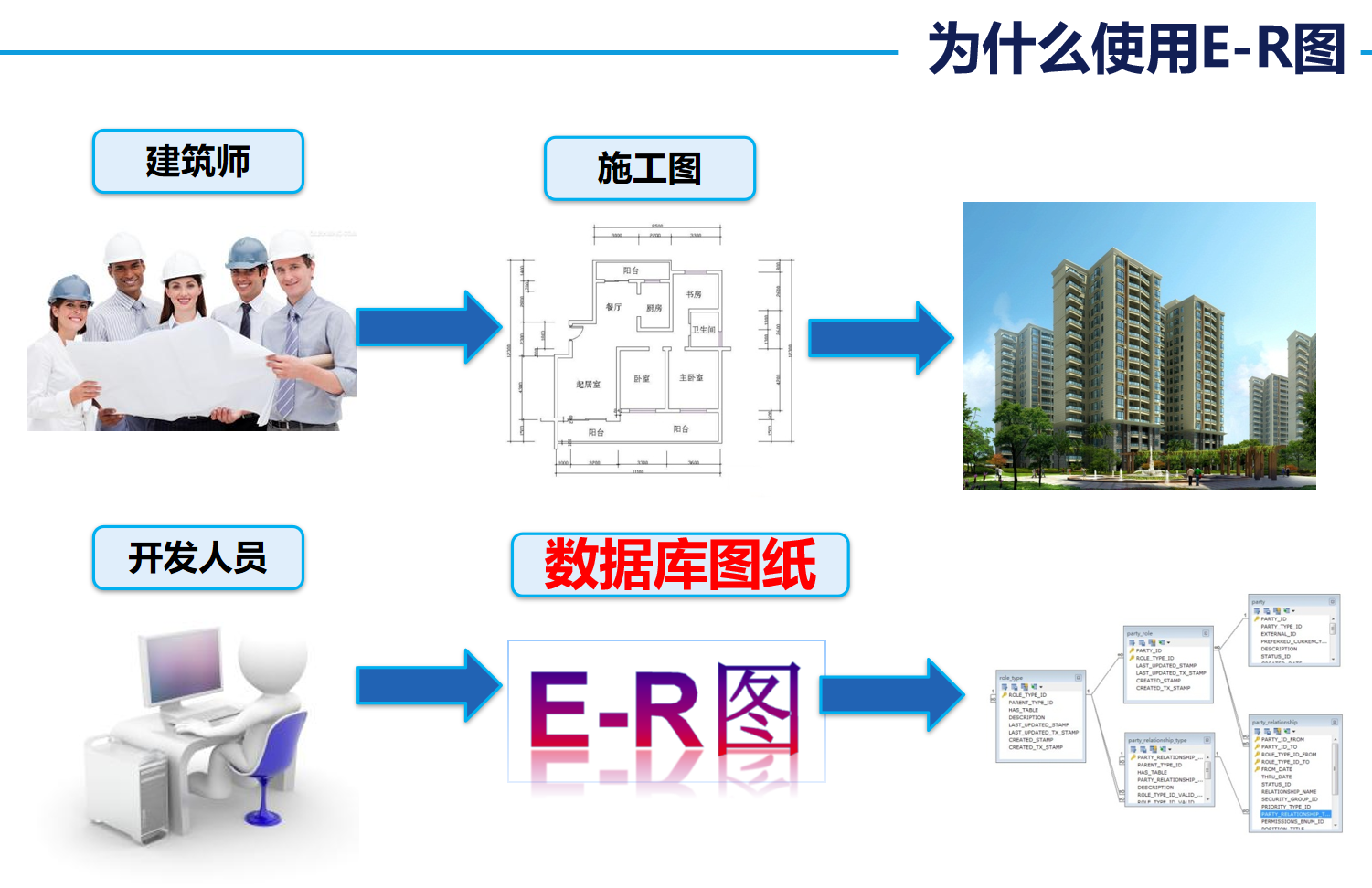
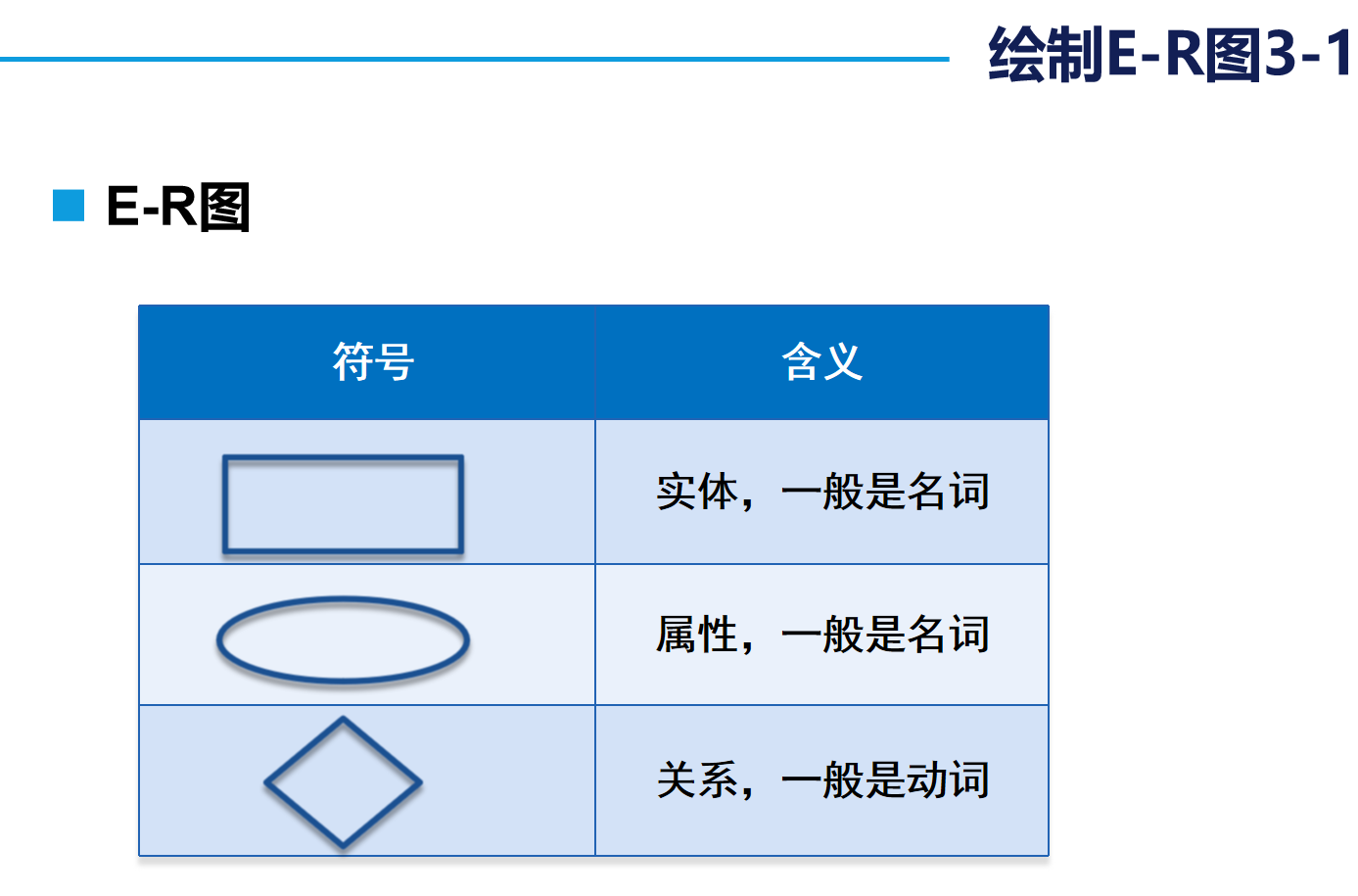
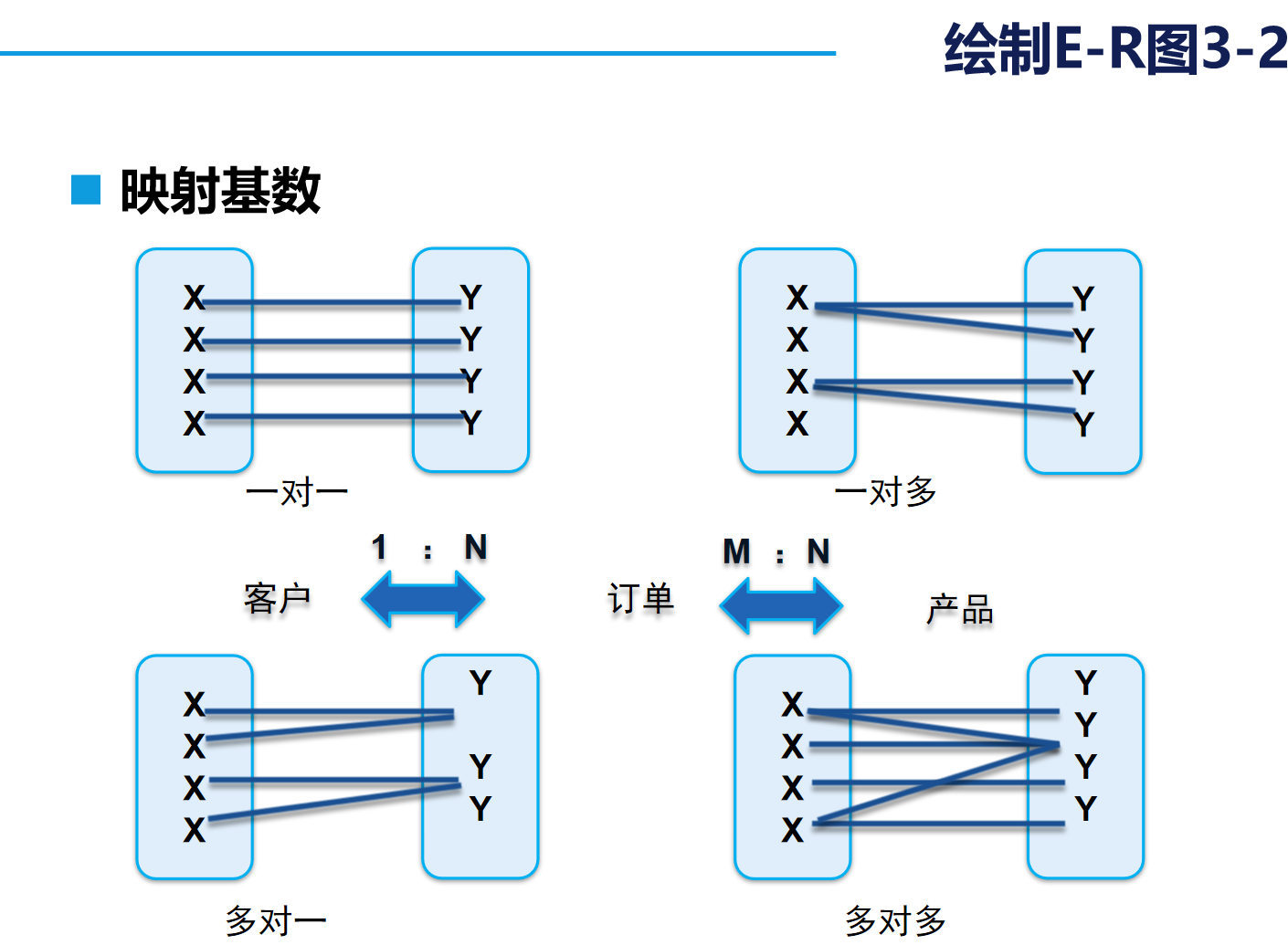
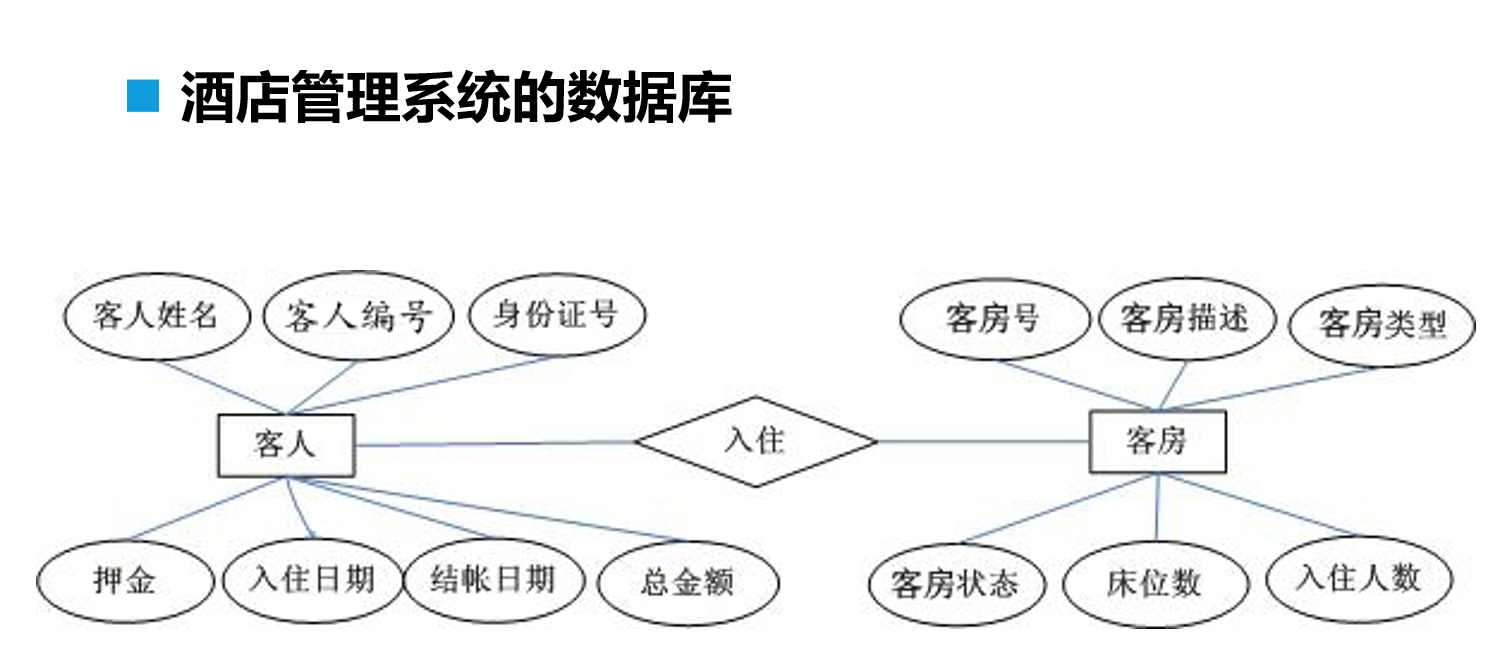
我們在日常設計的數據庫多為“一對多”和“多對一”

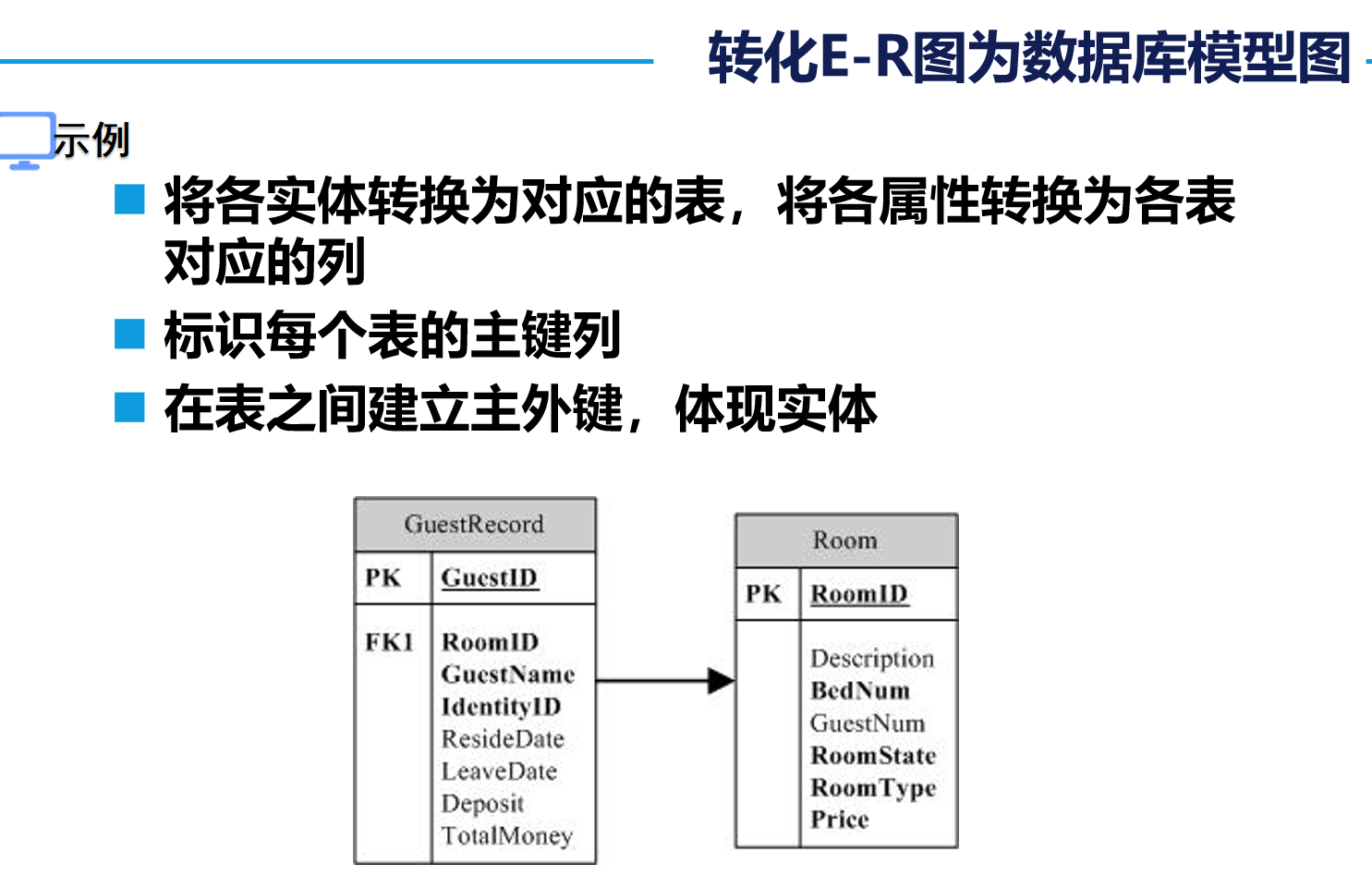
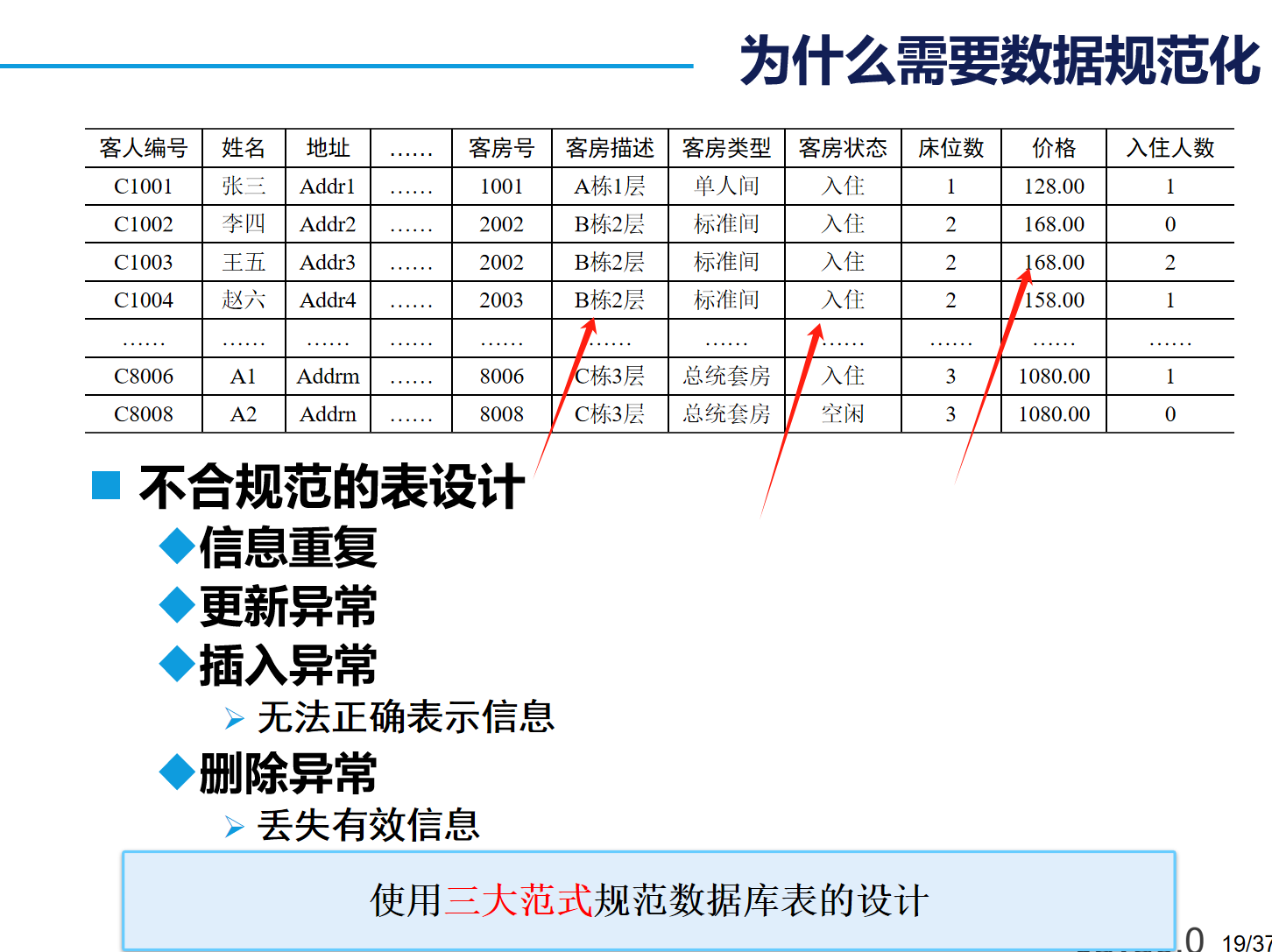
3. 設計數據庫三大范式?
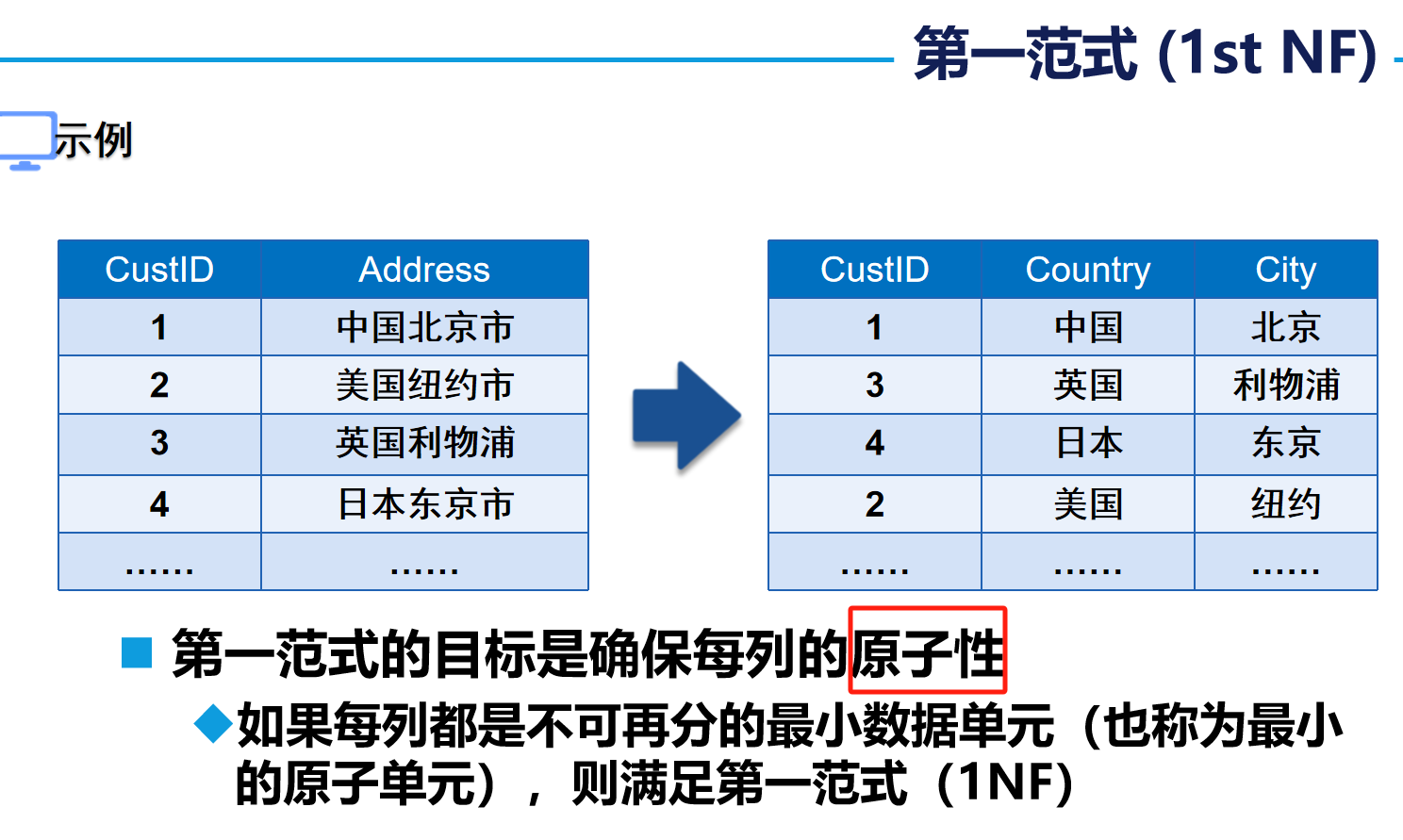
????????第一范式(1st NF):確保每列的原子性
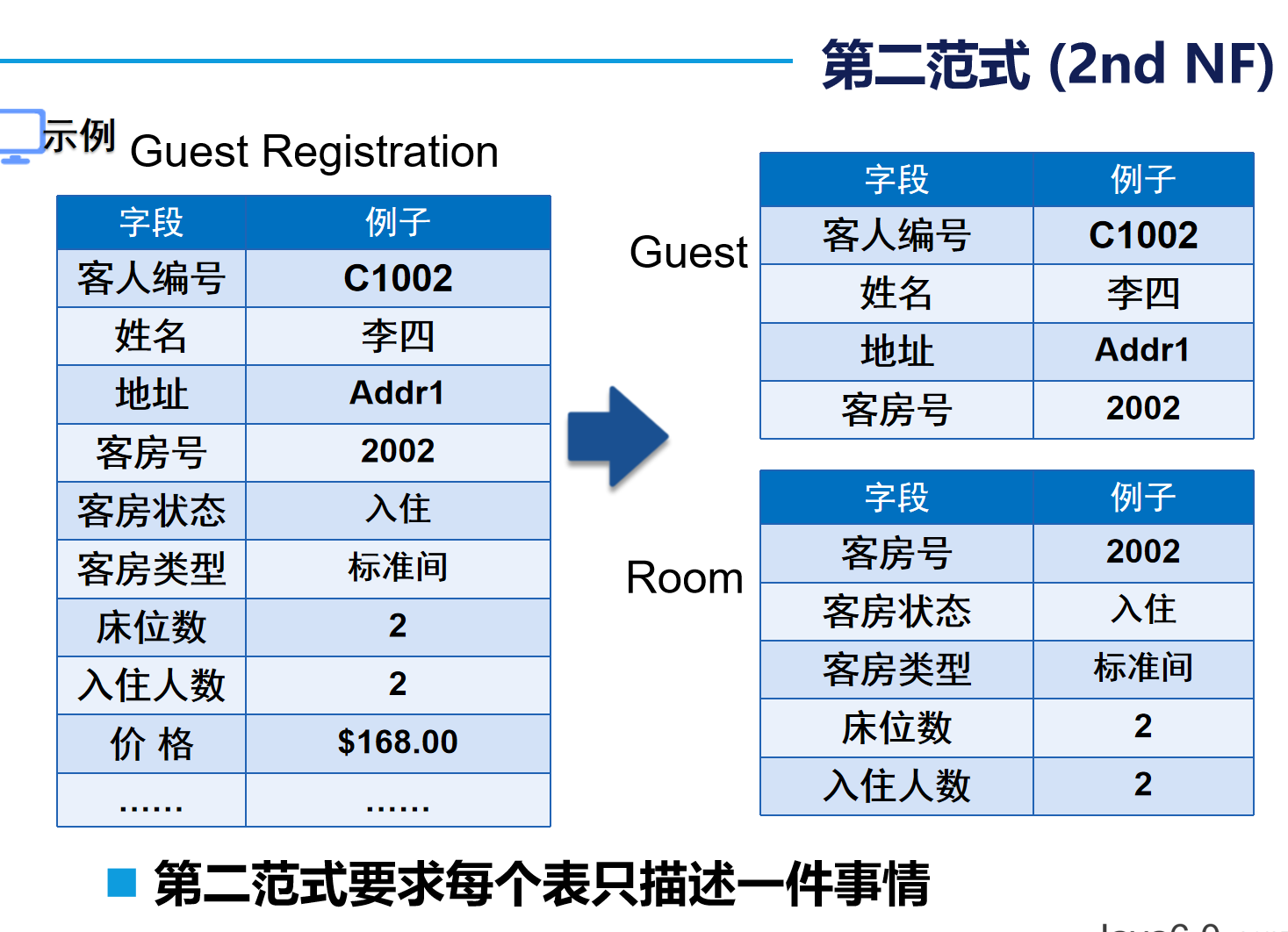
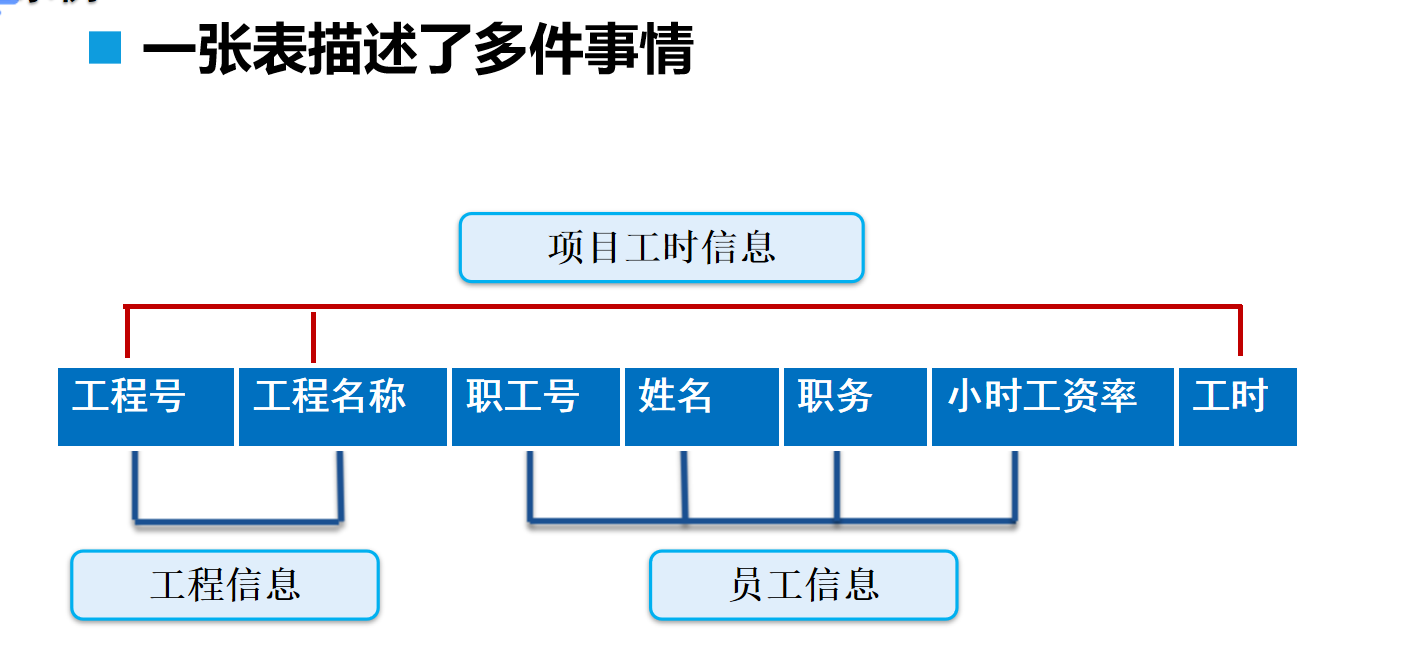
? ? ? ? 第二范式(2st NF):每個表只描述一件事情
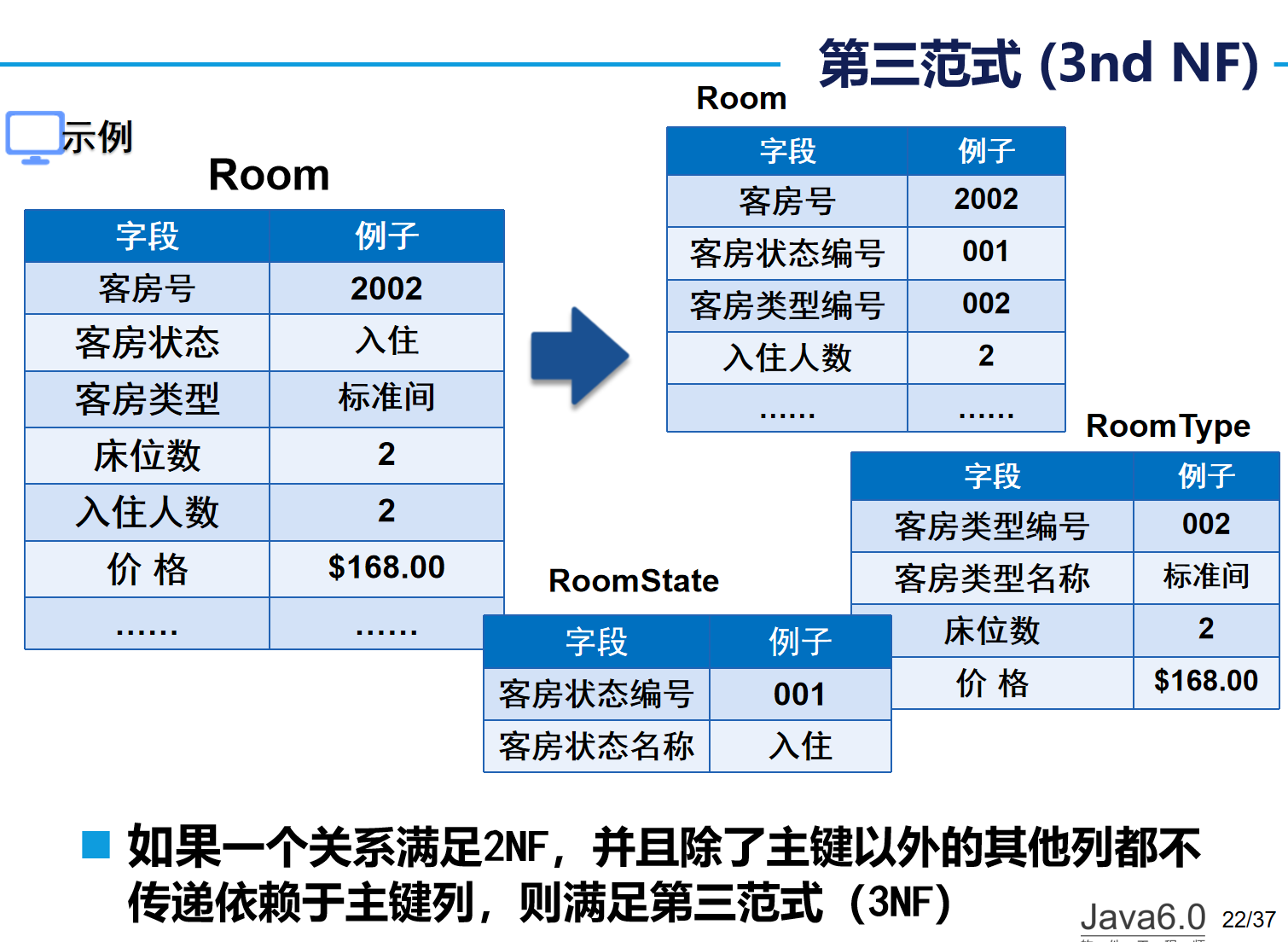
????????第三范式 (3nd NF):表中各列必須和主鍵直接相關,不能間接相關
4. 三大范式補充
1. 第一范式(1NF)
?核心要求?:確保每列具有原子性,即不可再分。
- ?通俗理解?:表中的每個字段必須是不可分割的最小數據單元,不能包含集合、數組或復合結構。例如,“地址”字段若包含省份、城市、街道等信息,需拆分為多個獨立字段。
- ?示例?:若“家庭信息”列包含“地址+成員”,需拆分為“地址”和“家庭成員”兩列以滿足1NF。
2. 第二范式(2NF)
?核心要求?:在1NF基礎上,非主鍵屬性必須完全依賴于主鍵(而非部分依賴)。
- ?聯合主鍵場景?:若主鍵由多列組成(如訂單號+產品號),非主鍵字段(如產品價格)必須依賴整個主鍵,而非僅依賴產品號。
- ?違反示例?:訂單表中“訂單日期”僅依賴訂單號(主鍵的一部分),需拆分表以消除部分依賴。
3. 第三范式(3NF)
?核心要求?:在2NF基礎上,消除非主鍵屬性間的傳遞依賴。
- ?傳遞依賴問題?:若字段A依賴字段B,而B依賴主鍵,則A應直接依賴主鍵。例如,訂單表中不應直接存儲客戶姓名(依賴客戶編號),應通過外鍵關聯客戶表。
- ?優點?:減少數據冗余(如避免重復存儲客戶信息)并避免更新異常。
注意事項
- ?實際應用?:三大范式雖規范,但可能影響查詢性能。阿里巴巴建議關聯表不超過3張,需平衡規范性與性能。
- ?更高范式?:存在BCNF、4NF等,但1NF~3NF最常用。
- ?反范式設計?:為提高查詢效率,允許適度冗余(如統計字段),但需權衡數據一致性風險
5. 實際案例演示

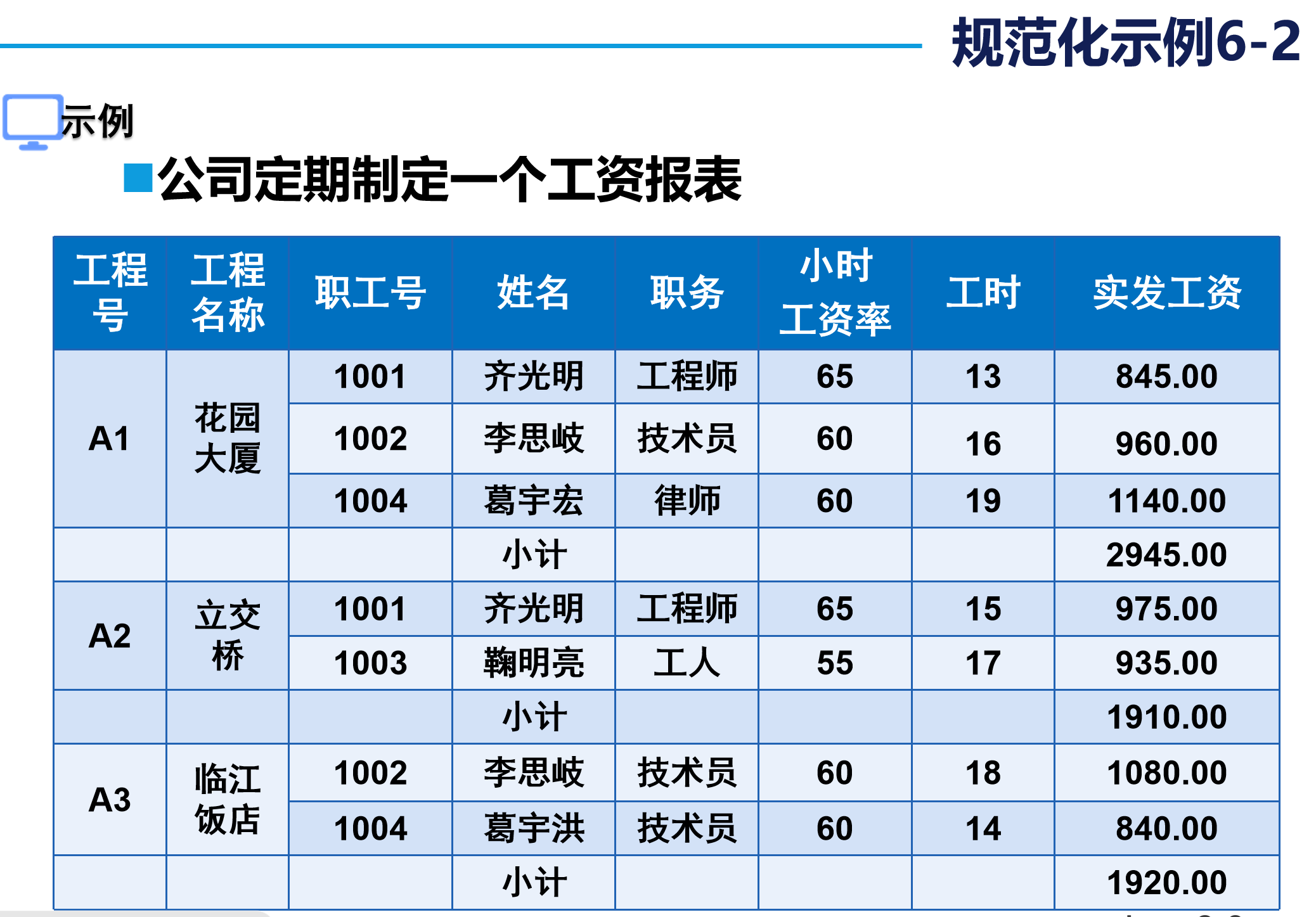

????????應用第一范式規范化
無可繼續拆分的信息,無需應用
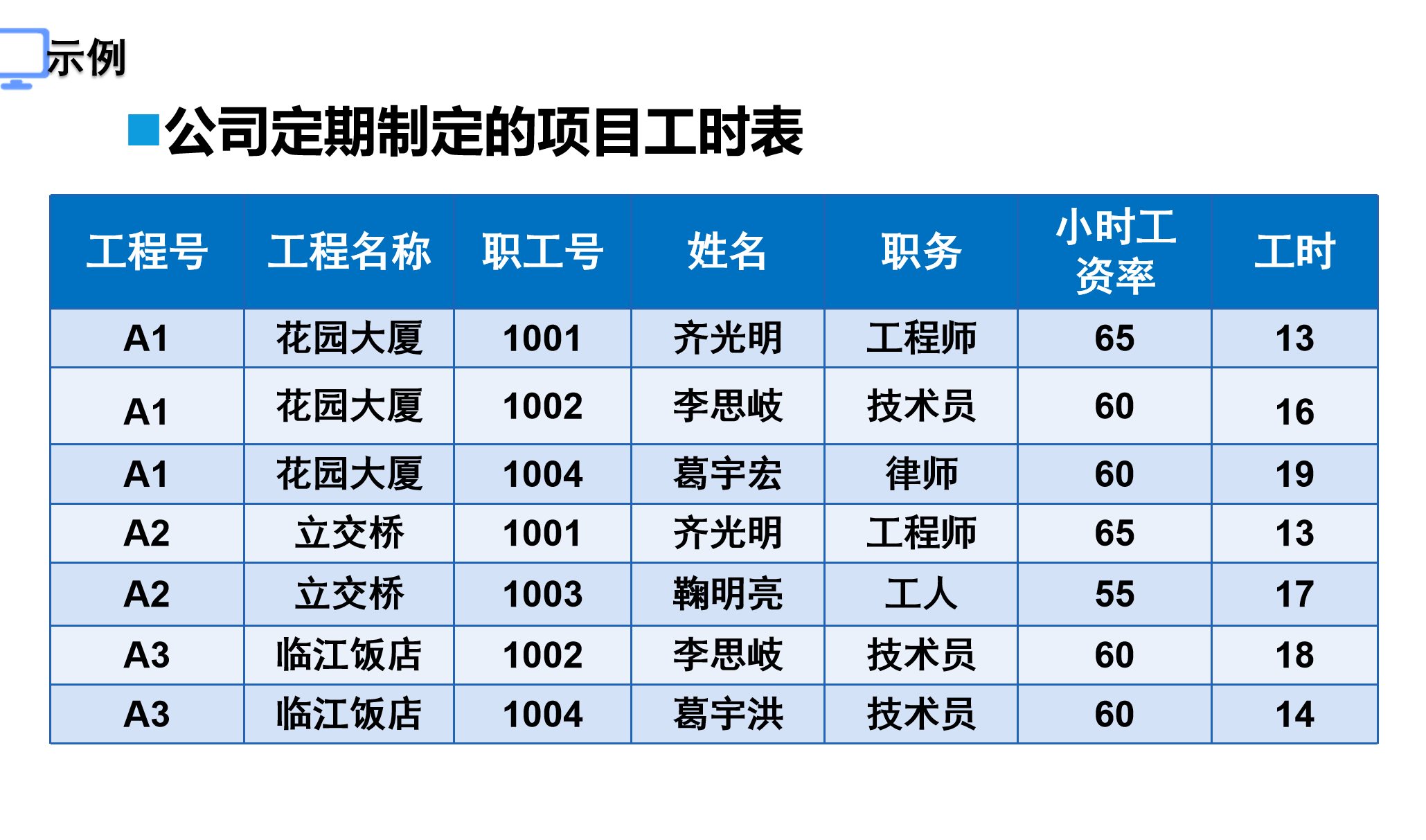
????????應用第二范式規范化
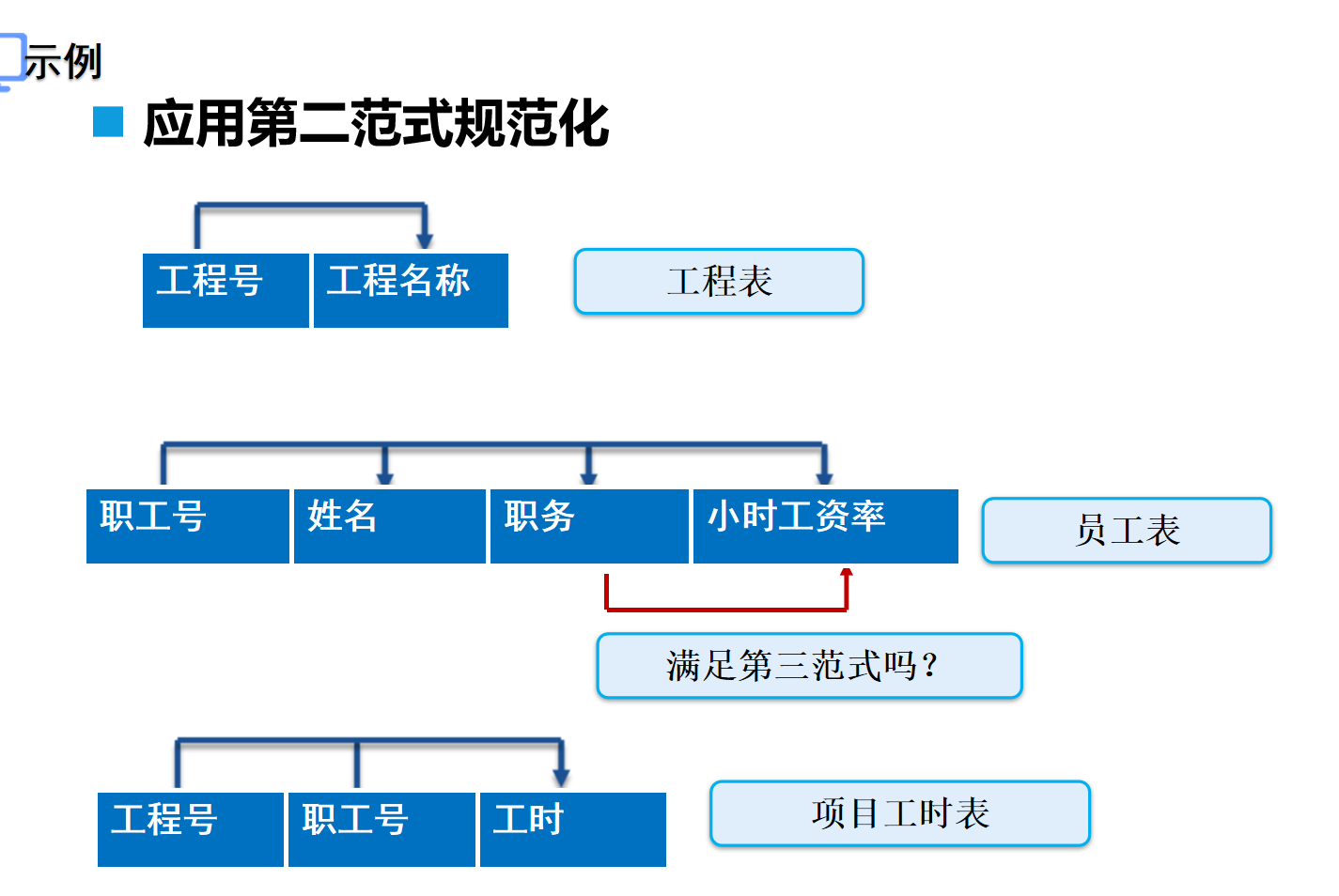
????????應用第三范式規范化
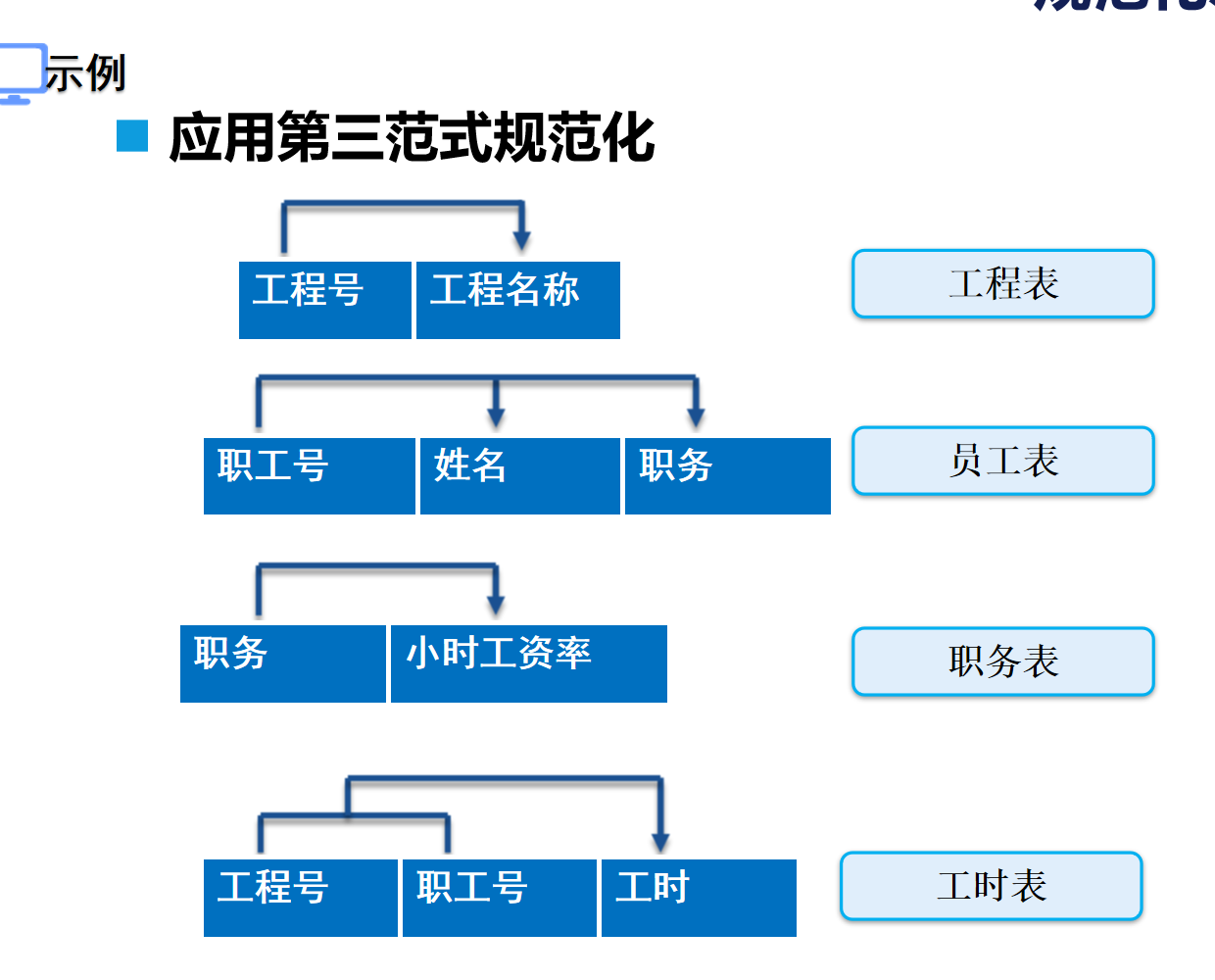 ?
?
6. 反范式設計(補充說明)

一、基本概念
反范式設計是數據庫設計中的一種優化手段,指在數據庫建模過程中,通過適當違反范式規則(如增加冗余數據、合并表等),來提高數據庫的讀取性能。它是對范式設計(追求數據一致性和減少冗余)的一種權衡,適用于讀取操作頻繁、寫入操作較少的場景。
二、核心思想
- 犧牲部分一致性,換取查詢效率:通過引入冗余數據或合并表,減少查詢時的表連接(JOIN)操作,從而提升查詢速度。
- 平衡性能與維護成本:在數據冗余帶來的查詢優化和數據更新、維護成本之間尋找平衡點。
三、常見方法
以下是反范式設計的常用手段,可根據具體場景組合使用:
1.?增加冗余字段
- 做法:在多個表中保留相同的字段,避免跨表查詢。
例:訂單表(Order)中包含用戶姓名(User.Name),避免每次查詢訂單時 JOIN 用戶表(User)。 - 適用場景:冗余字段更新頻率低,且查詢時頻繁需要關聯的場景。
2.?合并表
- 做法:將經常一起查詢的多個表合并為一個表,減少 JOIN 操作。
例:將用戶表(User)和用戶詳情表(UserDetail)合并為一個表。 - 適用場景:表之間存在強關聯,且合并后不會導致大量空字段的場景。
3.?拆分表
- 垂直拆分:將表中不常用的字段拆分到單獨的擴展表中,減少主表數據量,提升查詢速度。
例:將用戶表中的 “頭像 URL”“簡介” 等低頻字段拆分到擴展表。 - 水平拆分:按條件(如時間、ID 范圍)將表數據拆分到多個子表中,降低單表數據量。
例:按年份將訂單表拆分為Order_2023、Order_2024等表。
4.?增加派生字段
- 做法:通過計算或聚合生成新字段,直接存儲結果,避免查詢時實時計算。
例:在用戶表中存儲 “總訂單數” 字段,通過定時任務更新,避免每次查詢時統計。
四、適用場景
反范式設計適用于以下場景:
- 讀多寫少:如報表系統、日志系統、歷史數據查詢等。
- 實時性要求高:如電商商品詳情頁(需快速展示商品、分類、商家等信息)。
- 單表數據量龐大:當范式設計導致 JOIN 操作性能低下時,可通過冗余減少關聯。
- 允許一定數據延遲:如允許冗余字段定期同步,而非實時更新。
五、優缺點分析
| 優點 | 缺點 |
|---|---|
| 減少 JOIN 操作,提升查詢性能 | 數據冗余可能導致不一致(如更新延遲) |
| 簡化查詢邏輯,降低開發復雜度 | 增加數據維護成本(如更新、刪除) |
| 單表查詢效率更高 | 占用更多存儲空間 |
| 對 OLAP(聯機分析處理)場景友好 | 設計不當可能導致后續擴展困難 |
六、實施注意事項
- 評估場景必要性:優先使用索引、緩存(如 Redis)等優化手段,避免過度反范式。
- 控制冗余程度:僅對高頻查詢且低更新的數據進行冗余,避免全表冗余。
- 數據一致性方案:
- 定期同步:通過定時任務(如 CRON)更新冗余數據。
- 觸發器:在寫入主表時,通過數據庫觸發器同步更新冗余字段(需注意性能影響)。
- 應用層控制:在業務代碼中手動維護主表與冗余數據的一致性。
- 文檔記錄:明確標注反范式設計的字段和邏輯,方便后續維護。
- 監控與優化:定期分析查詢性能和數據一致性,必要時調整設計。
七、與范式設計的對比
| 維度 | 范式設計 | 反范式設計 |
|---|---|---|
| 核心目標 | 數據一致性、減少冗余 | 讀取性能優化 |
| 適用場景 | OLTP(聯機事務處理)系統 | OLAP 系統、讀多寫少場景 |
| 典型場景 | 銀行交易系統、電商訂單系統 | 報表系統、商品詳情頁 |
| 設計復雜度 | 高(需遵循范式規則) | 中(需平衡冗余與維護) |
八、案例說明
場景:設計一個電商平臺的 “商品詳情頁”,需展示商品信息、分類名稱、商家名稱。
- 范式設計:
- 表結構:
商品表(Goods)、分類表(Category)、商家表(Seller)。 - 查詢:需 JOIN 三張表,性能可能較低(尤其在高并發場景)。
- 表結構:
- 反范式設計:
- 在
商品表中增加冗余字段category_name(分類名稱)、seller_name(商家名稱)。 - 查詢:直接單表查詢,性能顯著提升;通過定時任務或商品 / 分類 / 商家更新時同步冗余字段。
- 在
九、總結
反范式設計是數據庫優化的重要手段,但需謹慎使用。關鍵在于明確業務需求,在性能提升與數據維護成本之間找到平衡點。實際應用中,常采用 “混合設計”—— 核心業務遵循范式設計,高頻查詢場景輔以反范式優化,以兼顧一致性和性能。
7. 總結


)







:三層架構)








如何通過“思考時間”(即推理時的計算資源)提升推理能力)
