導讀
目前將自動駕駛與視覺語言模型(VLMs)結合的研究越來越火熱,VLMs已經證明了其對自動駕駛的重要作用。本文引入了一種用于自動駕駛的輕量級端到端多模態模型LightEMMA,它能夠集成和評估當前的商業和開源模型,以研究VLMs在駕駛任務中的作用和局限性,從而推進VLMs在自動駕駛中的進一步發展。
??【深藍AI】編譯
本文由paper一作——Zhijie Qiao授權【深藍AI】編譯發布!
論文題目:LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
論文作者:Zhijie Qiao, Haowei Li, Zhong Cao, Henry X. Liu
論文地址:https://arxiv.org/pdf/2505.00284
代碼地址:https://github.com/michigan-traffic-lab/LightEMMA
1.摘要
視覺語言模型(VLMs)已經證明了其對于端到端自動駕駛的巨大潛力。然而,充分利用VLMs安全且可靠的車輛控制能力仍然是一項開放的研究挑戰。為了系統性地研究VLMs在駕駛任務中的作用和局限性,本文引入了LightEMMA,這是一種用于自動駕駛的輕量級端到端多模態模型。LightEMMA提供了一種統一的、基于VLM的自動駕駛框架,可以輕松集成和評估不斷發展的最先進商業和開源模型。本文使用各種VLMs來構建12個自動駕駛智能體,并且評估其在nuScenes預測任務上的性能,綜合地評估了推理時間、計算成本和預測準確性等指標。實驗示例表明,盡管VLMs具有強大的場景解釋能力,但是其在自動駕駛任務中的實際表現仍然不容樂觀,突出了進一步改進的必要性。
2.介紹
近年來,自動駕駛汽車(AV)取得了巨大的進步,其提高了安全性、舒適性和可靠性。傳統方法依賴于模塊化設計、基于規則的系統和預定義的啟發式方法。盡管這種結構化方法確保了可解釋且可預測的行為,但是它限制了解釋復雜場景和做出靈活、類人決策的能力。
最近的一種方法是基于學習的端到端自動駕駛方法,它將原始傳感器輸入以及高精地圖和環境上下文直接映射到駕駛軌跡。與模塊化流程不同,端到端模型旨在從數據中學習統一的表示,從而實現更全面、更高效的駕駛決策。然而,它們通常是可解釋性有限的黑盒,在關鍵場景中會引發安全問題,并且它們需要大量、多樣化的數據,使其容易受到數據不平衡和稀有性問題的影響。
一種有望解決這些挑戰的新興方法是視覺語言模型(VLMs)的發展。VLMs在包含文本、圖像和視頻的數據集上進行訓練,它展現出強大的推理能力。最近的研究著重于基于VLMs的端到端自動駕駛系統。然而,現有的研究主要突出了VLMs在駕駛環境中的場景理解能力,而沒有充分評估其優勢和局限性。此外,許多應用涉及商用車部署,而沒有可獲取的源代碼或者詳細的實現,這限制了它們在更廣泛的研究和協作中的可用性。
受到EMMA和開源實現工作OpenEMMA中最新進展的啟發,本文引入了LightEMMA,這是一種輕量級的端到端多模態框架,用于自動駕駛。LightEMMA采用零樣本方法,并且充分利用現有VLMs的能力。本文的主要貢獻如下:
1)本文為端到端自動駕駛規劃任務提供了一個開源的基線流程,旨在與最新的VLMs無縫集成,從而實現快速原型開發,同時最大限度地減少計算開銷和傳輸開銷;
2)本文使用nuScenes預測任務的150個測試場景對12個最先進的商業和開源VLMs進行全面評估。本文分析強調了當前基于VLM的駕駛策略的實際優勢和局限性,并且詳細討論了其能力和未來改進的潛在方向。
3.方法
LightEMMA架構的概覽如圖1所示。下面概述了其簡要的工作流程,并且在后續章節中提供詳細說明。
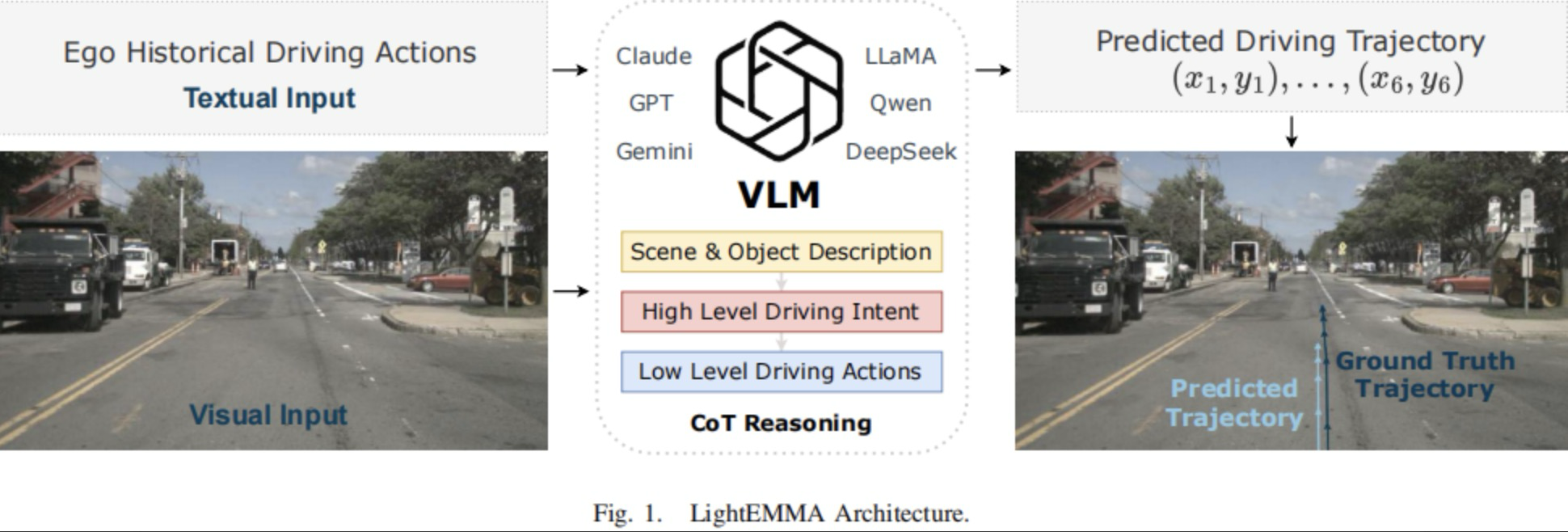
圖1|LightEMMA架構
對于每個推理周期,當前的前視相機圖像和歷史車輛駕駛數據被輸入到VLM中。為了提高可解釋性并且促進結構化推理,本文采用了一種思維鏈(CoT)提示策略,其最后階段顯式地輸出一系列預測的控制行為。這些行為被數值積分以生成預測的軌跡,隨后將其與真值進行比較。所有的VLMs均采用一致的提示和評估過程進行統一評估,無需針對特定模型進行調整。
3.1?VLM選擇
本文從開源和商業模型中選擇最先進的VLMs,涵蓋6種模型類型,總共12種模型。對于每種模型類型,本文評估兩個變體:基礎版本和高級版本。所有使用的模型都是支持文本和圖像輸入的最新開源版本。該設置允許在不同模型之間以及同一模型類內的變體之間進行全面的性能比較。所選擇的模型為:GPT-4o、GPT-4.1、Gemini-2.0-Flash、Gemini-2.5-Pro、Claude-3.5-Sonnet、Claude-3.7-Sonnet、DeepSeek-VL2-16B、DeepSeek-VL2-28B、LLaMA-3.2-11B-Vision-Instruct、LLaMA-3.2-90B-Vision-Instruct、Qwen2.5-VL-7B-Instruct和Qwen2.5-VL-72B-Instruct。
對于商業模型,本文通過付費API訪問它們。該方法通過消除管理本地硬件、軟件更新和可擴展性的需求來簡化部署,因為這些任務是由供應商直接處理的。
對于開源模型,本文從HuggingFace下載,并且使用H100 GPU在本地部署。大多數模型僅需要一個H100 GPU,盡管更大的模型可能需要更多GPU。本文在表格1中給出了所需的最少GPU數量。為了促進多GPU部署,本文利用PyTorch的自動設備映射來實現高效的GPU利用率。
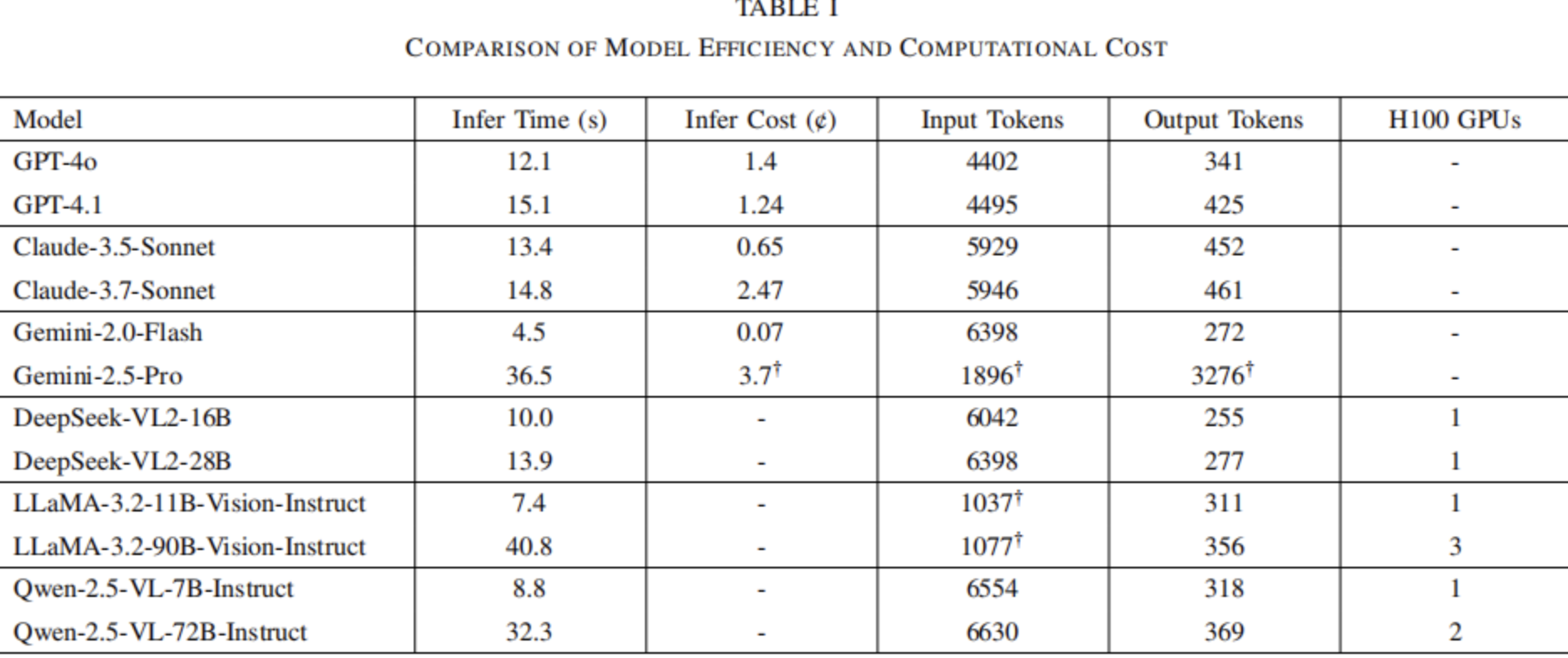
表格1|模型效率和計算成本的比較
3.2?相機輸入
當將前視相機圖像輸入VLM時,本文不使用任何視覺編碼器(例如CLIP),也不應用預處理技術來修改圖像。本文研究結果表明,VLM能夠有效地描述場景,并且直接從原始視覺輸入中準確識別目標,這證明了其在處理視覺數據方面的魯棒性。
根據該設計方法,本文還選擇僅使用當前駕駛場景圖像作為輸入,而不是像先前研究那樣連接多個過去的圖像幀。初步實驗表明,加入額外的幀不會獲得明顯的性能提升。相反,該模型傾向于在多個圖像幀中冗余地提取相同的特征,而沒有捕獲有意義的時空動態。此外,加入更多的圖像幀會導致處理時間和計算成本大致呈線性增加,而沒有明顯的性能優勢。
VideoBERT和Video-MAE等模型通過專門的時間編碼來支持視頻輸入,而不是簡單地將視頻作為圖像幀序列。此類模型固有地采用不同的架構,并且可能捕獲更豐富的時間信息。然而,探索這些專門面向視頻的模型超出了本文目前的研究范圍。
3.3?駕駛歷史輸入
本項工作使用速度和曲率來表示車輛行為,這是一種可解釋的格式,其中速度捕獲縱向運動,曲率描述橫向運動。本文采用這種表示來代替顯式的軌跡點,因為VLMs往往難以有效地推理涉及隱式物理約束的坐標。
3.4?VLM提示 ? ? ??
本文采用簡單的CoT方法來引導VLM的場景理解和行為生成,其中每個階段的輸出都與額外的提示一起集成到后續階段:
1)場景描述:VLM接收一幀圖像作為輸入,并且提示其解釋整個場景,包括車道標記、交通信號燈、車輛、行人活動和其他相關目標;
2)高級駕駛意圖:生成的場景描述與自車的歷史駕駛行為相結合,使VLM能夠在當前場景上下文中解釋過去的行為,并且預測下一高級駕駛行為;
3)低級駕駛命令:場景描述和生成的高級命令用于提示VLM,以指定格式輸出低級駕駛行為的結構化列表,例如[(v1,c1),(v2,c2),(v3,c3),(v4,c4),(v5,c5),(v6,c6)],而無需額外的文本或者解釋。
3.5?工作流程示例 ? ? ??
本節使用圖1所示的圖像,演示了工作流程示例和來自CoT過程的結果。響應和軌跡由Claude-3.7-Sonnet生成。
場景描述:圖像展示了一個城市街道場景,該場景中正在進行道路建設或者維護工作;一名警察站在道路中間指揮交通;可以看到幾輛施工車輛,包括一輛黑色卡車和其它工作車輛停在道路左側;在有警察在場和車道限制的情況下,這個施工區域的交通似乎得到了控制。
高級意圖:給定當前正在施工和一名警察在道路中間指揮交通的場景,自車應該大幅度減速,為可能的停車做準備,在接下來的3秒內將速度降至3-4m/s左右。車輛應繼續沿著車道行駛,同時準備在警察的指揮下完全停車。
低級命令:[(6.0,-0.001),(5.0,-0.001),(4.0,0.0),(3.5,0.0)]。
4.實驗
本文使用所提出的方法和模型,評估了在nuScenes預測任務中的性能,該任務包含150個測試場景的總共3908幀。評估著重于兩個方面:模型的計算效率及其軌跡預測的準確性。
4.1?推理時間
表格1匯總了推理時間,顯示了每個圖像幀的平均處理時間。Gemini-2.0-Flash以每幀4.5秒的速度實現了最快推理,而LLaMA-3.2-90b的推理速度最慢,每幀為40.8秒。Qwen-2.5-72B和Gemini-2.5-Pro也表現出相對較慢的性能,每幀需要30秒以上。其余模型通常以每幀10秒的速度運行,基礎版本通常比高級版本運行更快。
值得注意的是,即使是最快的模型Gemini-2.0-Flash,其處理時間也明顯低于實時更新的頻率。為了真正有效地進行實際部署,這些模型需要以一到兩個數量級更快的速度運行。此外,基于API的商業模型依賴于穩定的網絡連接,這在行駛車輛上可能是不可靠的。相反,本地部署面臨著計算能力有限和能耗的限制,這進一步限制了它們的實用性。
4.2?輸入和輸出Tokens
本文使用每個模型提供的官方指令來計算每幀輸入和輸出tokens的平均數量。如表格1所示,輸入tokens的數量明顯高于輸出tokens,通常約為6000個輸入tokens,而輸出tokens約為300個。這符合預期,因為輸入包括圖像數據,而輸出僅是文本。
然而,也存在一些例外。LLaMA模型給出每幀只有大約1000個輸入tokens。經過進一步研究,發現官方的LLaMA token計數方法不包括圖像tokens,只計算文本。
此外,Gemini-2.5-Pro的token計數在輸入和輸出token計算中明顯包含錯誤,因為它們與可比較模型的結果之間存在顯著偏差。值得注意的是,使用相同的token計數方式計算的Gemini-2.0-Flash生成了一致且合理的結果,這表明Gemini-2.5-Pro存在需要解決的問題。
4.3價格
本節僅適用于商業APIs。為了確保準確的衡量,根據輸入和輸出token的使用,將計費歷史與官方定價表進行交叉引用。為清楚起見,表格1中顯示的所有結果均以美分/幀為單位。
Gemini-2.0-Flash是最便宜的,價格僅為0.07,因此其價格可以忽略不計。GPT-4o和GPT-4.1的價格接近,約為1.3。Claude-3.7-Sonnet比Claude-3.5-Sonnet價格貴得多,尤其比GPT模型也貴很多。由于Gemini-2.5-Pro 的token計算不準確,因此很難做出準確估計。
4.4響應錯誤
在最終的模型輸出階段,本文觀察到各種響應格式錯誤。盡管提示VLM嚴格返回格式為[(v1,c1),(v2,c2),(v3,c3),(v4,c4),(v5,c5),(v6,c6)]的輸出,而沒有額外的文本,但是偶爾會遇到偏差,例如缺少括號或者逗號、額外的解釋或者標點符號以及不正確的列表長度。
如表格2所示,Qwen-2.5-72B的錯誤率最高,其錯誤率為62.9%,而其基礎版本Qwen-2-5-7B沒有產生錯誤。GPT-4.1的錯誤率為28.9%,而GPT-4o的錯誤率較低,為7.8%。其余模型均運行可靠,它們的錯誤率為零或者低于1%。
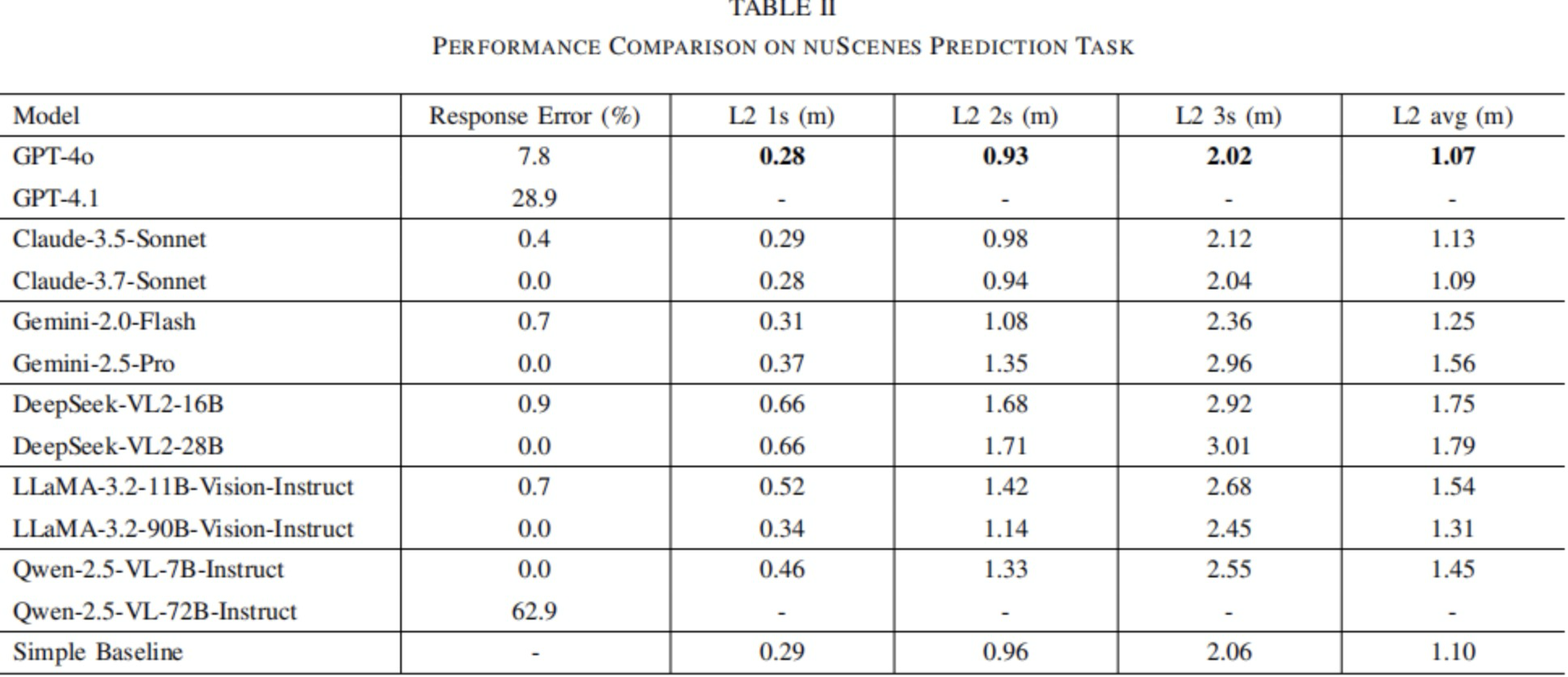
表格2|在nuScenes預測任務中的性能比較
本文認為,在所有模型的提示和工作流程相同的情況下,這些隨機失效反映了固有的模型局限性,而不是框架中存在系統缺陷。雖然許多格式錯誤可以通過后處理、額外的提示或者其它增強技術來減少,但是本文的目標是評估而不是優化單個模型的性能。因此,本文保持一致的實驗設計,并且在不進行修改的情況下給出觀測到的錯誤率。
4.5預測準確性
預測準確性遵循nuScenes預測任務中采用的標準評估方法,以1s、2s和3s的間隔給出L2損失及其平均值。由于存在響應錯誤,每個模型都會對原始幀的不同子集進行預測。為了確保公平比較,如果任何一個模型無法為某幀生成有效的預測,就將該幀排除在所有模型的評估之外。由于Qwen-2.5-72B和GPT-4.1表現出特別高的失敗率,本文將這兩個模型完全排除在分析之外,以保留足夠大的幀集合。
表格2匯總了L2損失結果。為了簡化并且便于比較,本文的分析主要著重于平均L2損失(單位為米);總體而言,GPT-4o實現了最佳的性能,其L2損失為1.07米,緊隨其后的是Claude-3.5-Sonnet和Claude-3.7-Sonnet,其結果略遜一籌。Gemini模型的表現相對較差;值得注意的是,Gemini-2.5-Pro的性能明顯不如Gemini-2.0-Flash。總體而言,開源模型的表現不如商業模型,其中兩個DeepSeek模型的性能最差。
4.6?L2損失基線
盡管L2損失提供了一種評估模型預測性能的簡單方法,但是它可能無法完全捕獲駕駛場景的復雜性。為了緩解這個問題,本文引入了一個簡單而有效的基線:保持最新的AV行為在接下來的三秒內不變。然后,通過計算相對于真值的L2損失來評估這些恒定行為生成的軌跡。
本文的結果表明,該基線實現了1.10米的平均L2損失,與GPT-4o(1.07米)和Claude 3.7-Sonnet(1.09米)的最佳VLM結果非常接近,并且明顯優于許多其它模型。這一比較突出了零樣本VLM方法在軌跡規劃任務中的當前局限性,這表明現有模型可能難以充分應對駕駛特定的復雜性。因此,這強調了需要有針對性的進行增強,例如專門為駕駛上下文來設計VLM架構或者使用領域特定的駕駛數據集對模型進行微調。
5.案例
本節討論了圖2所示的六個具有代表性的場景。由于可用幀的數量較多,因此從中精心挑選了一些示例來說明典型行為。每幅圖都將VLMs預測的軌跡與真值軌跡進行比較。
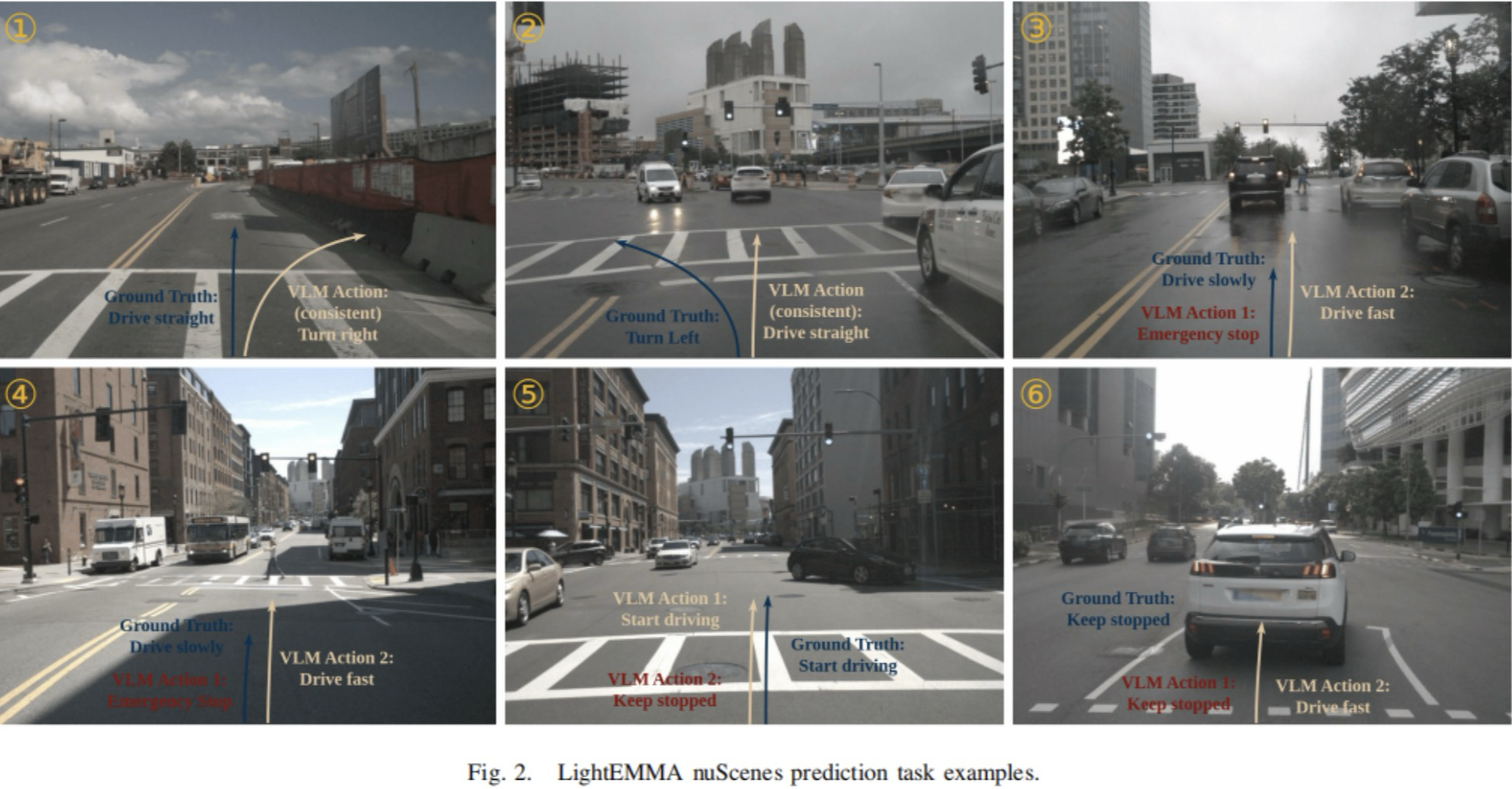
圖2|LightEMMA nuScenes預測任務示例
5.1案例1:歷史行為的軌跡偏差
圖2.1展示了一個場景,其中真值軌跡為直線行駛,但是預測的軌跡為右轉,它未能識別出右側的障礙物。發生這種情況是因為自動駕駛汽車剛剛在該幀之前的交叉路口完成右轉。因此,歷史行為反映了右轉的傾向。然而,VLMs很難僅根據當前的前視圖像識別更新的道路狀況。
5.2案例2:視覺線索的上下文不足
圖2.2展示了另一種所有模型都一直失敗的情況。在這種案例中,真值軌跡為左轉,但是所有模型都錯誤地預測為繼續直行。盡管這種場景本身就具有挑戰性(人行道上沒有顯式的左轉標志或者專用的交通信號燈),但是仍然存在隱式的指示。例如,自動駕駛汽車占據最左側的車道,而右側相鄰車道上的車輛則繼續直行。為了可靠地克服這個問題,模型可以結合額外的上下文信息,例如顯式的導航指示來清楚地指明交叉路口處左轉。
5.3案例3&4:對停車信號的不同響應
圖2.3顯示了一個突出VLM響應差異顯著的場景。在這種案例中,自動駕駛汽車在紅色交通信號燈控制的交叉路口處逐漸接近前方停止的車輛。真值軌跡顯示,自動駕駛汽車平穩地逐漸減速,直到完全停在前方車輛后面。然而,VLM預測結果分為兩類(緊急停車和快速通行),其中沒有一類結果符合真值行為。
圖2.4中觀測到類似的情況。在該場景中,自動駕駛汽車接近有紅色交通信號燈的交叉路口,行人正在穿越人行道。VLM預測要么預測突然緊急剎停(盡管前方有足夠的距離),要么完全忽略行人和交通信號燈,預測自動駕駛汽車將保持速度通過路口。
5.4案例5:對啟動信號的不同響應?
圖2.5描繪了一個場景,其中自動駕駛汽車最初是靜止的,在交通信號燈控制的交叉路口等待。當交通信號燈從紅色變為綠色時,真值行為為自動駕駛汽車迅速啟動加速并且平穩地通過交叉路口。具有較低L2損失的模型復現了這種行為,準確地將綠色信號燈識別為繼續前進的指示,從而預測出適當的加速軌跡。相反,具有較高L2損失的模型保持車輛靜止,未能建立綠色信號燈與相應加速行為之間的重要聯系。
5.5案例6:沖突的視覺線索和模型響應?
最后一個示例如圖2.6所示,其展示了一個有趣的場景,其中即使是具有較低L2損失的模型也表現出不同的行為。與圖2.5中的情況類似,交通信號燈剛剛從紅色轉變為綠色。一組模型觀察到綠燈并且預測立即加速,而忽略了前方車輛。相反,另一組模型準確地識別出沖突的線索(盡管有綠色信號,但是前方存在車輛),因此自動駕駛汽車必須保持靜止。
此外,VLM的這種不同響應揭示了其在應用于自動駕駛任務時決策過程中固有的不穩定性。這種不一致性可能直接導致危險情況的發生,例如意外加速或者碰撞風險,這突出了建立魯棒安全機制或者防護的必要性。
6.總結
本項工作引入了LightEMMA,這是一種輕量級的端到端自動駕駛框架,專門為與最先進的視覺語言模型集成而設計。本文使用了思維鏈提示策略,表明VLMs有時能夠準確地解釋復雜的駕駛場景并且生成智能的響應。值得注意的是,LightEMMA主要用作可訪問的基線,而不是優化特定VLMs的性能。
nuScenes預測任務的系統性評估考慮了計算效率、硬件要求和API成本等多個維度。使用L2損失作為指標的定量分析強調了當前VLM預測的局限性,并且突出了僅依賴這一指標的不足。定性分析進一步確定了常見的缺點,包括過度依賴歷史軌跡數據、有限的空間感知和被動的決策。因此,未來研究應該著重于開發駕駛特定的模型或者利用領域特定的數據集來微調現有的VLMs。


)

)
基礎知識④)
)







)


![掌握Multi-Agent實踐(七):基于AgentScope分布式模式實現多智能體高效協作[并行加速大模型輔助搜索、分布式多用戶協同辯論賽]](http://pic.xiahunao.cn/掌握Multi-Agent實踐(七):基于AgentScope分布式模式實現多智能體高效協作[并行加速大模型輔助搜索、分布式多用戶協同辯論賽])
以及基礎環境(mysql、redis等)ruoyi-ry)
