目錄
一.配置Redis
1.配置application.properties
2. 配置Config
3.測試連接redis
二、Redis持久化
持久化方案
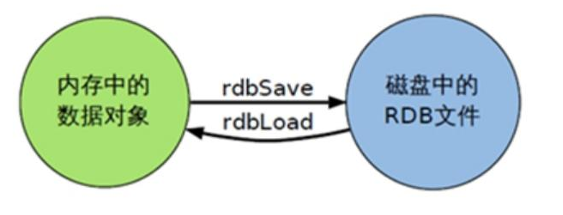
RDB:
1、RDB基礎認識
1、具體流程如下:
3、小結:
3、Fork&Copy-On-Write
4、RDB的配置
5、默認快照的配置
6、save VS bgsave
7、flushall
8、save
9、stop-writes-on-bgsave-error
10、rdbcompression
11、rdbchecksum
12、動態停止RDB
2、RDB備份和恢復:
3、RDB小結
2、AOF
1、開啟AOF
2、修復和恢復
3、同步頻率設置
4、rewrite壓縮
5、AOF小結
3、選擇RDB還是AOF?
一.配置Redis
1.配置application.properties
# Redis 服務器地址
spring.redis.host=127.0.0.1
# Redis 服務器連接端口
spring.redis.port=6379
# Redis 密碼(如果沒有密碼,直接刪除這一行)
spring.redis.password=
# Redis 數據庫索引(默認 0)
spring.redis.database=2
# 連接超時時間(毫秒)
spring.redis.timeout=1800000
# 連接池最大連接數(使用負數表示無限制)
spring.redis.lettuce.pool.max-active=20
# 最大阻塞等待時間(負數表示無限制)
spring.redis.lettuce.pool.max-wait=-1
# 連接池中的最大空閑連接
spring.redis.lettuce.pool.max-idle=5
# 連接池中的最小空閑連接
spring.redis.lettuce.pool.min-idle=02. 配置Config
里面包含兩個方法
1.redisTemplate
2.CacheManager
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Object> template =new RedisTemplate<>();System.out.println("template=>" + template);//這里可以驗證..RedisSerializer<String> redisSerializer =new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer =new Jackson2JsonRedisSerializer(Object.class);ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL,JsonTypeInfo.As.WRAPPER_ARRAY);jackson2JsonRedisSerializer.setObjectMapper(om);template.setConnectionFactory(factory);//key序列化方式template.setKeySerializer(redisSerializer);//value序列化template.setValueSerializer(jackson2JsonRedisSerializer);//value hashmap序列化template.setHashValueSerializer(jackson2JsonRedisSerializer);return template;}@Beanpublic CacheManager cacheManager(RedisConnectionFactory factory) {RedisSerializer<String> redisSerializer =new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);//解決查詢緩存轉換異常的問題ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL,JsonTypeInfo.As.WRAPPER_ARRAY);jackson2JsonRedisSerializer.setObjectMapper(om);// 配置序列化(解決亂碼的問題),過期時間600秒RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(600)).serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)).disableCachingNullValues();RedisCacheManager cacheManager = RedisCacheManager.builder(factory).cacheDefaults(config).build();return cacheManager;}
}
3.測試連接redis
@RestController
@RequestMapping("/redisTest")
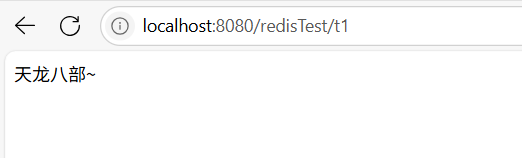
public class RedisTestController {//裝配RedisTemplate@Resourceprivate RedisTemplate redisTemplate;//編寫第一個測試方法//演示設置數據和獲取數據@GetMapping("/t1")public String t1() {//設置值到redisredisTemplate.opsForValue().set("book", "天龍八部~");//從redis獲取值String book = (String) redisTemplate.opsForValue().get("book");return book;}通過上面的api來訪問,就會得到:
以及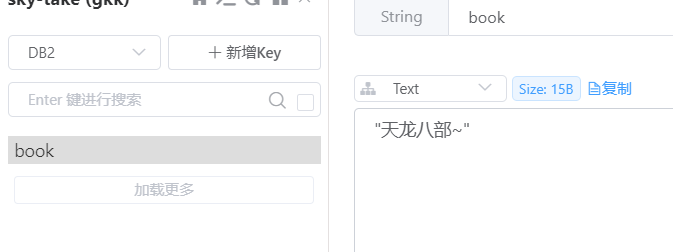
?這樣我們就測試成功了
注意:
如果是通過客戶端添加的數據,我們用redisTemplate的時候也會做反序列化,但是客戶端set是不會做序列化的,所以會報錯
解決方案就是用服務端的程序重新set一下就好了?
二、Redis持久化
Redis 持久化是指 ??將內存中的數據保存到磁盤??,確保即使 Redis 服務重啟或崩潰,數據也不會丟失。由于 Redis 是 ??內存數據庫??(數據默認存儲在內存中),持久化機制可以防止數據因斷電、宕機等情況而丟失。
在線文檔 :https://redis.io/topics/persistence
持久化方案
RDB和AOP
RDB:
1、RDB基礎認識
在指定時間內將內存的數據集快照寫入磁盤中,也就是Snapshot快照,恢復時將快照文件讀到內存
??RDB 持久化是通過生成數據快照來實現的
流程圖:
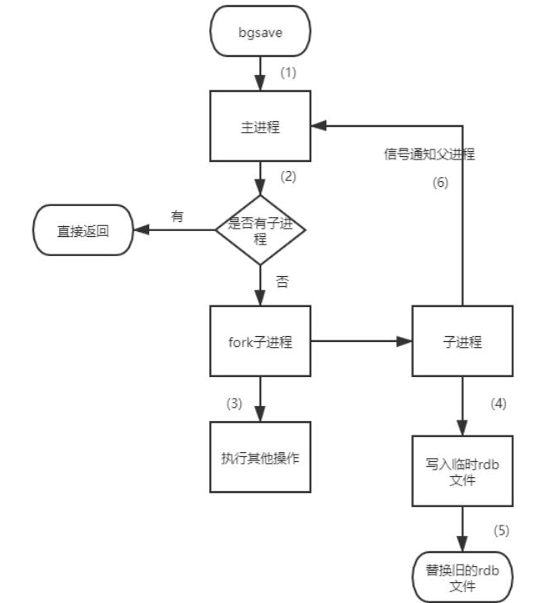
1、具體流程如下:
1、redis 客戶端執行bgsave命令或者自動觸發bgsave命令;
2、主進程判斷當前是否已經存在正在執行的子進程,如果存在,那么主進程直接返回;
3、如果不存在正在執行的子進程,那么就fork一個新的子進程進行持久化數據,fork過程是阻塞的,fork操作完成后主進程即可執行其他操作; ?
4、子進程先將數據寫入到臨時的rdb文件中,待快照數據寫入完成后再原子替換舊的rdb文件;
5、同時發送信號給主進程,通知主進程rdb持久化完成,主進程更新相關的統計信息
3、小結:
1.整個過程中,主進程是不進行任何IO操作的,這就確保了極高的性能 。
2.如果需要進行大規模數據的恢復, 且對于數據恢復的完整性不是非常敏感,那RDB方式 要比AOF方式更加的高效 。?
3.RDB 的缺點是最后一次持久化后的數據可能丟失:如果你是正常關閉Redis,也就是正常shutdown時仍然會進行持久化, 不會造成數據丟失。如果是Redis 異常終止/宕機, 就可能造成數據丟失,具體流程如下:
- 收到?
SHUTDOWN?命令。 - Redis 立即執行一次 ??阻塞式?
SAVE??(確保數據完整)。 - 將最新數據寫入?
dump.rdb。 - 關閉進程。
![]()
默認是SAVE
3、Fork&Copy-On-Write
1、Fork 的作用是復制一個與當前進程一樣的進程。新進程的所有數據(變量、環境變量、 程序計數器等) 數值都和原進程一致,但是是一個全新的進程,并作為原進程的子進程
2、在Linux 程序中,fork()會產生一個和父進程完全相同的子進程,但子進程在此后多會 exec 系統調用,出于效率考慮,Linux中引入了"寫時復制技術 即:copy-on-write", 有興 韓順平Java 工程師 趣的參考:https://blog.csdn.net/Code_beeps/article/details/92838520
3、一般情況父進程和子進程會共用同一段物理內存,只有進程空間的各段的內容要發生變化時,才會將父進程的內容復制一份給子進程,也就是說:
當我用父進程操作一塊物理內存,fork了一個子進程,此時父進程和子進程都在同一塊物理內存,因為數據是一致的,當父進程對物理內存進行操作了,就會創建一個新的物理內存,此時父線程就到新的內存區域了,子線程在舊的內存區域。
4、RDB的配置
在redis.conf中配置文件名稱,默認為dump.rdb,可以自定義
![]()
如何配置:
1、默認為Redis啟動時命令行所在的目錄下
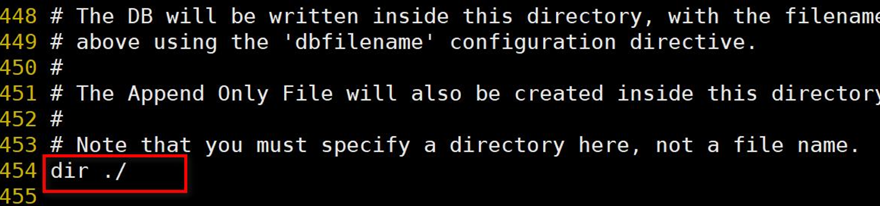
進入到/usr/local/bin 目錄下, 啟動 Redis, 這個 ./ 就是 /usr/local/bin , 如果你在 /root/ 目錄下啟動 Redis, 那么 ./ 就是 /root/ 下了。如果之前在root目錄下啟動的redis,數據自動保存在這個目錄下的dump.rdb,當年第二天打開,數據也從這個目錄下的dump.rdb里恢復回來,也就是說,如果你從其他目錄打開是沒有數據的,因為沒有對應的dump.rdb
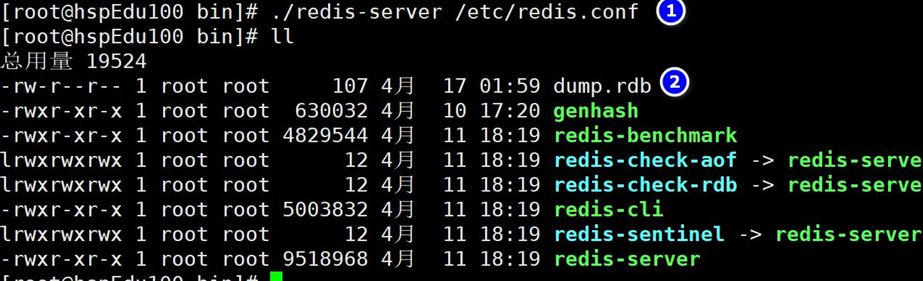
2、rdb 文件的保存路徑, 也可以修改, 比如: dir"/root/"??
![]()
把dit ./改成dir /root/? ,這樣一來無論從哪打開redis都會統一走同一個持久化文件
5、默認快照的配置
這是后臺機制
1.
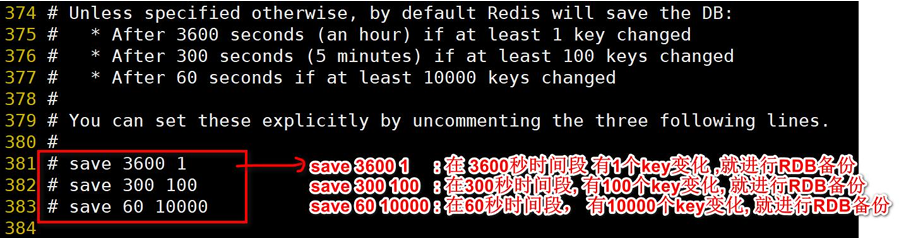
2.注意理解這個時間段的概念:
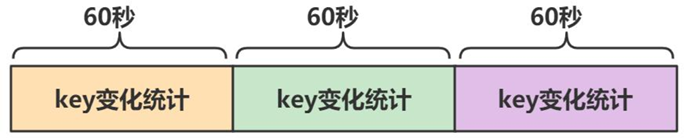
時間是獨立的一段一段時間,下一個60秒會刷新統計
3.如果我們沒有開啟save注釋,那么在退出Redis的時候也會再進行備份,更新dump.rdb(執行一次 ??阻塞式?SAVE??)
4.如果再規定時間內沒有達到指定的key值變化,那么30秒后不做持久化
例子:save 30 10:
如果再規定時間內沒有達到指定的key值變化,那么30秒后不做持久化,但是時間是獨立的一段一段時間,下一個30秒會刷新統計,那我上一個30秒修改的key不做保存,就丟失了。除非shutdown
6、save VS bgsave
1、save :save時只管保存,其它不管,全部阻塞。手動保存, 不建議。
2、bgsave:Redis 會在后臺異步進行快照操作, 快照同時還可以響應客戶端請求。
3、可以通過lastsave 命令獲取最后一次成功執行快照的時間(unix時間戳), 可以使用工具轉換時間戳(Unix timestamp)轉換工具 - 在線工具
7、flushall
1、執行flushall 命令,會把內存的數據全部拿掉,同時把數據再次持久化,所以dump.rdb文件數據為空.
2、Redis Flushall 命令用于清空整個 Redis 服務器的數據(刪除所有數據庫的所有 key)
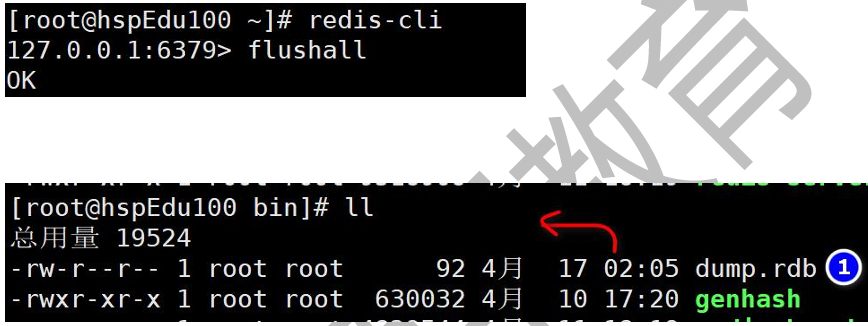
內存92相當于是初始化的內存大小
8、save
save 秒鐘 寫操作次數
禁用: 給save傳入空字符串
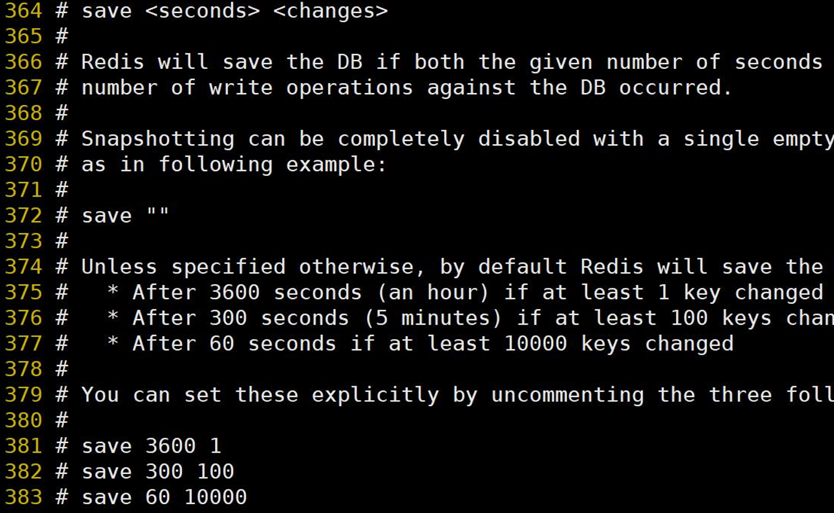
RDB是整個內存的壓縮過的Snapshot,RDB的數據結構,可以配置復合的快照觸發條
9、stop-writes-on-bgsave-error
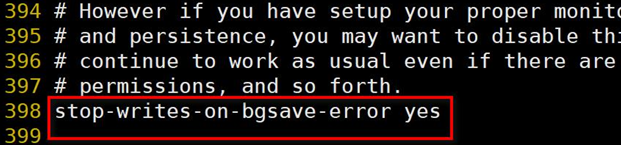
當Redis無法寫入磁盤的話(比如磁盤滿了), 直接關掉Redis的寫操作。推薦yes
10、rdbcompression

1、對于存儲到磁盤中的快照,可以設置是否進行壓縮存儲。如果是的話,redis會采用 LZF 算法進行壓縮。
2、如果你不想消耗CPU來進行壓縮的話,可以設置為關閉此功能, 默認yes
11、rdbchecksum

1、在存儲快照后, 還可以讓redis使用CRC64算法來進行數據校驗,保證文件是完整的
2、但是這樣做會增加大約10%的性能消耗,如果希望獲取到最大的性能提升,可以關閉 此功能, 推薦yes
12、動態停止RDB
1、動態停止RDB:redis-cli config set save"",不需要重啟redis
2、說明:save后給空值,表示禁用保存策略
2、RDB備份和恢復:
1、Redis可以充當緩存, 對項目進行優化, 因此重要/敏感的數據建議在Mysql 要保存一份
2、從設計層面來說,Redis的內存數據, 都是可以重新獲取的(可能來自程序, 也可能來自 Mysql)
3、因此我們這里說的備份&恢復主要是給大家說明一下 Redis啟動時, 初始化數據是從 dump.rdb 來的, 這個機制.
config get dir 查詢 rdb 文件的目錄
將dump.rdb 進行備份, 如果有必要可以寫shell腳本來定時備份 網課:?https://www.bilibili.com/video/BV1Sv411r7vd?p=105
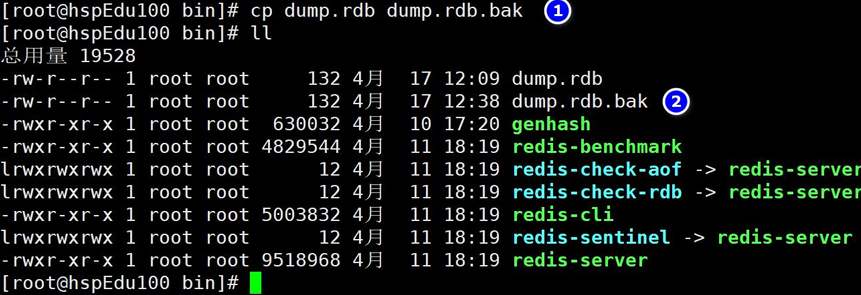
參考韓順平老師的演示:
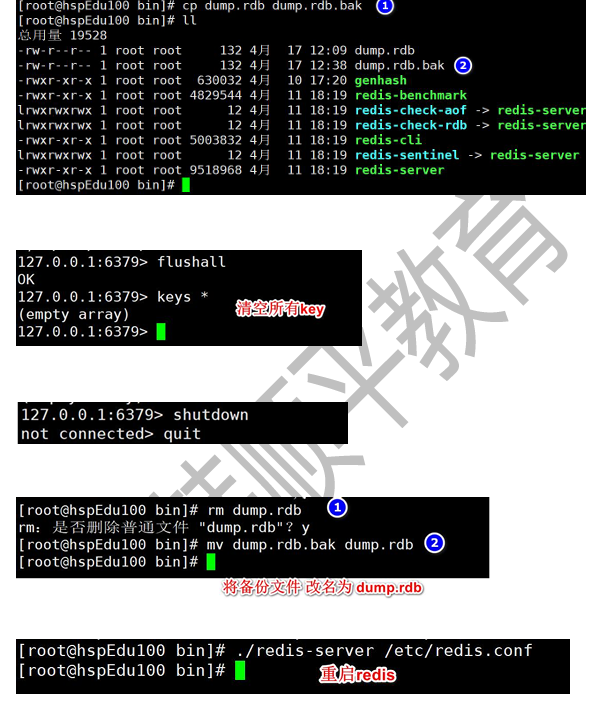
最終結果:
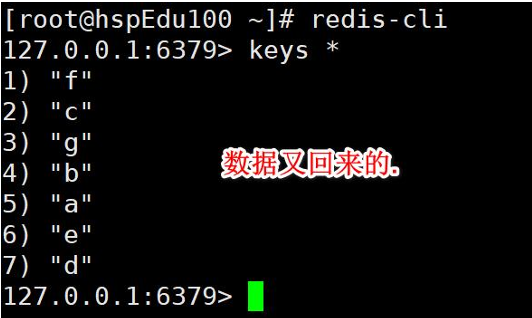
3、RDB小結
優勢:
1、適合大規模的數據恢復
2、對數據完整性和一致性要求不高更適合使用
3、節省磁盤空間
4、恢復速度快
劣勢:
1、雖然Redis在fork時使用了寫時拷貝技術(Copy-On-Write), 但是如果數據龐大時還是比較消耗性能。
2、在備份周期在一定間隔時間做一次備份,所以如果Redis意外down掉的話(如果正常 關閉Redis, 仍然會進行RDB備份, 不會丟失數據), 就會丟失最后一次快照后的所有修改
2、AOF
官方資料 在線文檔 :https://redis.io/topics/persistence
1、AOF(Append Only File)
2、以日志的形式來記錄每個寫操作(增量保存),將Redis執行過的所有寫指令記錄下來(比 如 set/del 操作會記錄, 讀操作get不記錄)
3、只許追加文件但不可以改寫文件
4、redis 啟動之初會讀取該文件重新構建數據
5、redis 重啟的話就根據日志文件的內容將寫指令從前到后執行一次以完成數據的恢復工作
持久化流程圖
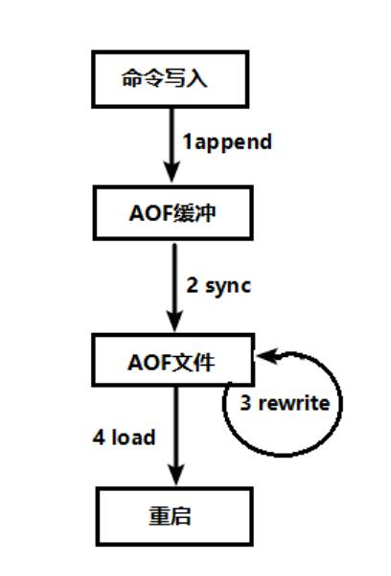
1) 客戶端的請求寫命令會被append追加到AOF緩沖區內
2) AOF 緩沖區根據AOF持久化策略[always,everysec,no]將操作sync同步到磁盤的AOF文件中
3) AOF 文件大小超過重寫策略或手動重寫時,會對AOF文件rewrite重寫,壓縮AOF文件容量
4) Redis 服務重啟時,會重新load加載AOF文件中的寫操作達到數據恢復的目的
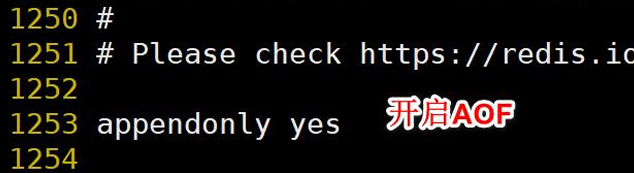
1、開啟AOF
1、在redis.conf 中配置文件名稱,默認為 appendonly.aof
2、AOF文件的保存路徑,同RDB的路徑一致。
3、AOF和RDB同時開啟,系統默認取AOF的數據
4、老韓實驗, 當開啟AOF后,Redis從AOF文件取數據.
后續:
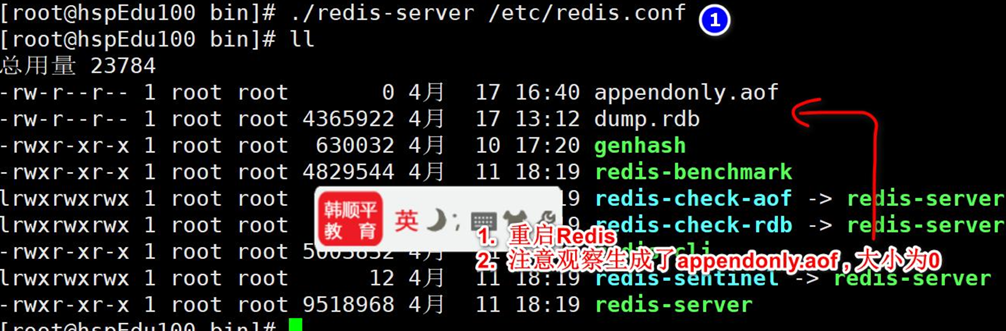
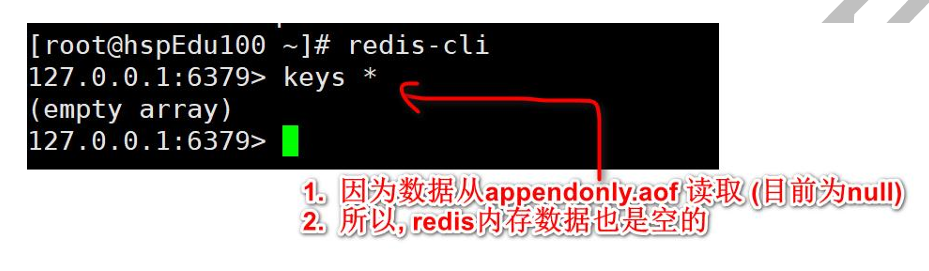
當我們開啟AOF之后再去寫操作,這時候appendonly.aof就有數據了
2、修復和恢復
AOF的備份機制和性能雖然和RDB不同, 但是備份和恢復的操作同RDB一樣, 都是拷貝備份文件, 需要恢復時再拷貝到Redis工作目錄下,啟動系統即加載
一、正常恢復
1、修改默認的appendonlyno,改為yes
2、將有數據的aof文件定時備份, 需要恢復時, 復制一份保存到對應目錄(查看目錄:config get dir)
3、恢復:重啟redis然后重新加載
4、和前面RDB備份/恢復機制類似? .bak
二、異常恢復
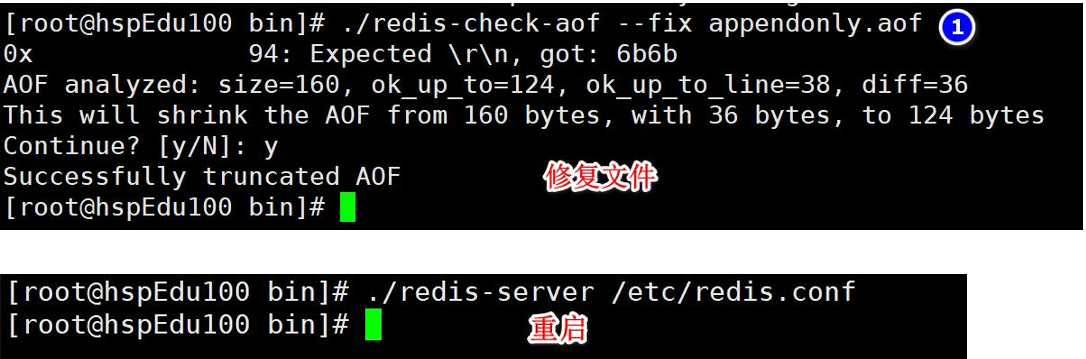
1、如遇到AOF文件損壞,通過/usr/local/bin/redis-check-aof --fix appendonly.aof 進行恢復
2、建議先: 備份被寫壞的AOF文件
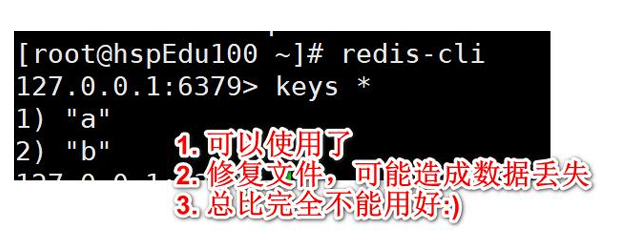
3、恢復:重啟redis,然后重新加載
可能會造成數據丟失,但是總比沒有好,而且當文件損壞之后是連接不上了,根本就沒有redis服務

開始修復文件:
成功了
3、同步頻率設置
AOF 緩沖區根據AOF持久化策略[always,everysec,no]將操作sync同步到磁盤的AOF文件中,其中[always,everysec,no]就是同步頻率設置
1.配置位置
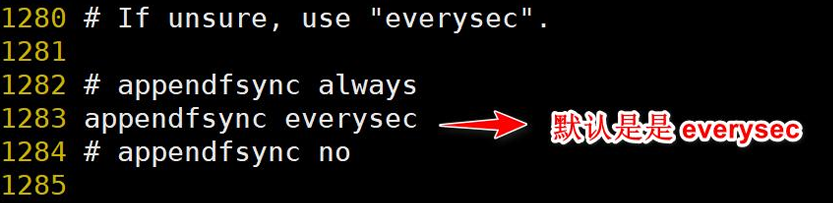
1) appendfsync always 始終同步,每次Redis的寫入都會立刻記入日志;性能較差但數據完整性比較好
2) appendfsync everysec 每秒同步,每秒記入日志一次,如果宕機,本秒的數據可能丟失。
3) appendfsync no redis不主動進行同步,把同步時機交給操作系統?https://baijiahao.baidu.com/s?id=1740774723808931509&wfr=spider&for=pc
4、rewrite壓縮
一、rewrite 重寫介紹
1) AOF 文件越來越大,需要定期對AOF文件進行重寫達到壓縮
2) 舊的AOF文件含有無效命令會被忽略,保留最新的數據命令 , 比如 :set a a1 ; set a b1; set a c1; 保留最后一條指令就可以了
3) 多條寫命令可以合并為一個 , 比如把上面的指令改成: set a c1 b b1 c c1
4) AOF 重寫降低了文件占用空間
5) 更小的AOF文件可以更快的被redis加載
二、重寫觸發配置
1) 手動觸發 直接調用bgrewriteaof 命令

2) 自動觸發
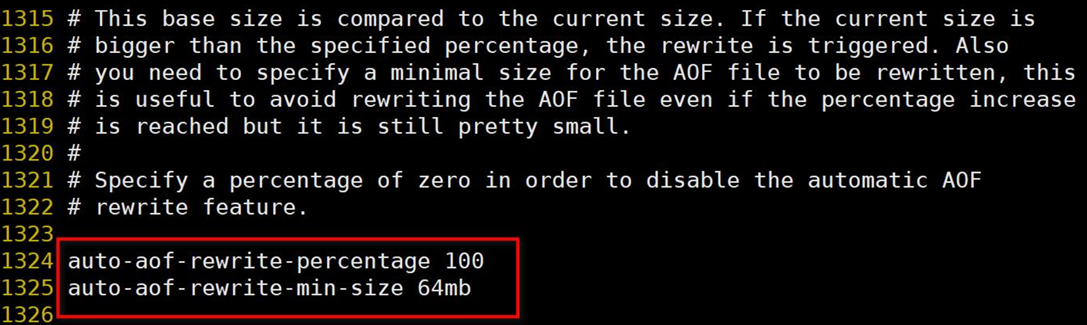 ?auto-aof-rewrite-min-size: AOF 文件最小重寫大小, 只有當 AOF 文件大小大于該值時候才能 auto-aof-rewrite-percentage,?默認配置64MB
?auto-aof-rewrite-min-size: AOF 文件最小重寫大小, 只有當 AOF 文件大小大于該值時候才能 auto-aof-rewrite-percentage,?默認配置64MB
auto-aof-rewrite-percentage: 當前 AOF 文件大小和最后一次重寫后的大小之間的比率等于或者大于指定的增長百分比,如100代表當前AOF文件是上次重寫的兩倍時候才重寫
系統載入時或者上次重寫完畢時,Redis會記錄此時AOF大小,設為 base_size。
如果Redis的AOF當前大小>=base_size+base_size*100%(默認) 且 當前 大小>=64mb(默認)的情況下,Redis會對AOF進行重寫。比如base_size是64m,那么下一次就是128m,沒有到達128就不會重寫。
5、AOF小結
優勢:
1、備份機制更穩健,丟失數據概率更低,數據一致性比RDB好。
2、可讀的日志文本,通過操作AOF穩健,可以處理誤操作

劣勢:
1、比起RDB占用更多的磁盤空間
? ? ? ? 只記錄有哪些key
2、恢復備份速度要慢
? ? ? ? 因為記錄的全是一些寫指令,要重新執行一遍
3、每次讀寫都同步的話,有一定的性能壓力?
3、選擇RDB還是AOF?
官方文檔地址:https://redis.io/topics/persistence

? ? ? ?官方推薦兩個都啟用
如果只做緩存:如果你只希望你的數據在服務器運行的時候存在, 你也可以不使用任何持久化方式
![[ctfshow web入門] web77](http://pic.xiahunao.cn/[ctfshow web入門] web77)


 詳解)


![WeakAuras Lua Script [TOC BOSS 5 - Anub‘arak ]](http://pic.xiahunao.cn/WeakAuras Lua Script [TOC BOSS 5 - Anub‘arak ])






OpenJDK 17 中線程啟動的完整流程用C++ 源碼詳解之主-子線程通信機制)




)
