文章目錄
- 一、Q-learning
- 現實理解:
- 舉例:
- 回顧:
- 二、Sarsa
- 和Q-learning的區別
- 三、Deep Q-Network
- Deep Q-Network是如何工作的?
- 前處理:
- Convolution Networks
- Experience Replay
一、Q-learning
是RL中model-free、value-based算法,Q即為Q(s,a)就是在某一時刻s (s∈S)狀態下采取動作a (a∈A) 能夠獲得收益的期望,環境根據Agent的動作反饋相應的回報reward。將State與Action構建成一張Q-table來存儲Q值,然后根據Q值來選取能夠獲得最大的收益的動作。
| Q-Table | a1 | a2 |
|---|---|---|
| s1 | q(s1,a1) | q(s1,a2) |
| s2 | q(s2,a1) | q(s2,a2) |
| s3 | q(s3,a1) | q(s3,a2) |
也就是馬爾科夫決策過程:每個格子都是一個狀態 s t s_t st?, π ( a ∣ s ) \pi(a|s) π(a∣s)在s狀態下選擇動作a的策略。 P ( s ’ ∣ s , a ) P(s’|s,a) P(s’∣s,a) ,也可以寫做 P s s ′ a P^a_{ss'} Pss′a?為s狀態下選擇動作a轉換到下一狀態 s ′ s' s′的概率。 R ( s ’ ∣ s , a ) R(s’|s,a) R(s’∣s,a)表示這一Action轉移的獎勵。
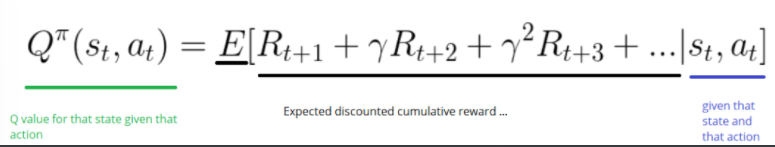
我們的目標是最大累計獎勵的策略期望:
m a x π E [ ∑ t = 0 H γ t R ( S t , A t , S t + 1 ) ∣ π ] max_π E [ ∑ _{t = 0} ^H γ^ t R ( S_t , A_t , S_t + 1 )∣π] maxπ?E[∑t=0H?γtR(St?,At?,St?+1)∣π]
使用了時間差分法TD能夠離線學習,使用bellman方程對馬爾科夫過程求最優解。
在我們探索環境(environment)之前,Q-table 會給出相同的任意的設定值(大多數情況下是 0)。隨著對環境的持續探索,這個 Q-table 會通過迭代地使用Bellman方程(動態規劃方程)更新 Q(s,a) 來給出越來越好的近似。

算法是基于貪婪的策略進行選擇:
S t e p 4 Step 4 Step4中選擇動作a并且執行動作并返回一個新的狀態 s ’ s’ s’和獎勵r,使用Bellman方程更新 Q ( s , a ) Q(s,a) Q(s,a):

新 Q ( s , a ) = 老 Q ( s , a ) + α ? ( 現實 ? 估計 ) 新Q(s,a)=老Q(s,a)+\alpha*(現實-估計) 新Q(s,a)=老Q(s,a)+α?(現實?估計)
現實理解:
在狀態s采取行動a到達 s ′ s' s′,但是我們用于決策的Q表并沒有實際采取任何行為,所以我們只能使用期望值進行下一個狀態 s ′ s' s′各個動作的潛在獎勵評估:
- Q-Learning的做法是看看那種行為的Q值大,把最大的 Q ( s ′ , a ′ ) Q(s', a') Q(s′,a′) 乘上一個衰減值 γ \gamma γ (比如是0.9) 并加上到達 s ′ s' s′時所獲取的獎勵 R(真真實實存在的)
- 這個值更新為現實中的新Q值
舉例:
- 一塊奶酪 = +1
- 兩塊奶酪 = +2
- 一大堆奶酪 = +10(訓練結束)
- 吃到了鼠藥 = -10(訓練結束)

S t e p 1 Step 1 Step1 初始化Q表都是0(所有狀態下的所有動作)
S t e p 2 Step2 Step2 重復 S t e p 3 ? 5 Step3-5 Step3?5
S t e p 3 Step 3 Step3 選擇一個動作:向右走(隨機)
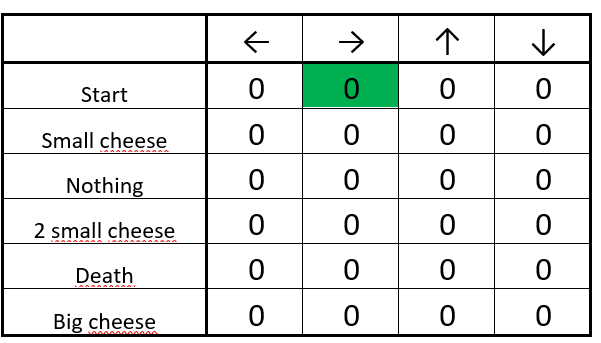
S t e p 4 Step 4 Step4 更新Q函數

- 首先,我們計算 Q 值的改變量 ΔQ(start, right)。
- 接著我們將初始的 Q 值與 ΔQ(start, right) 和學習率的積相加。
回顧:
- Function Q(state, action) → returns expected future reward of that action at that state.
- Before we explore the environment: Q table gives the same arbitrary fixed value → but as we explore the environment → Q gives us a better and better approximation.
二、Sarsa
State-Action-Reward-State-Action,清楚反應了學習更新函數依賴的5個值,分別是當前狀態S1,當前狀態選中的動作A1,獲得的獎勵Reward,S1狀態下執行A1后取得的狀態S2及S2狀態下將會執行的動作A2。

和Q-learning的區別
Q_learing:下一步q表最大值 γ ? m a x a ′ Q ( s ′ , a ′ ) + r γ*max_{a'}Q(s^′,a')+r γ?maxa′?Q(s′,a′)+rSarsa:具體的某一步估計q值 γ ? Q ( s ′ , a ′ ) + r γ*Q(s^′,a^′)+r γ?Q(s′,a′)+r
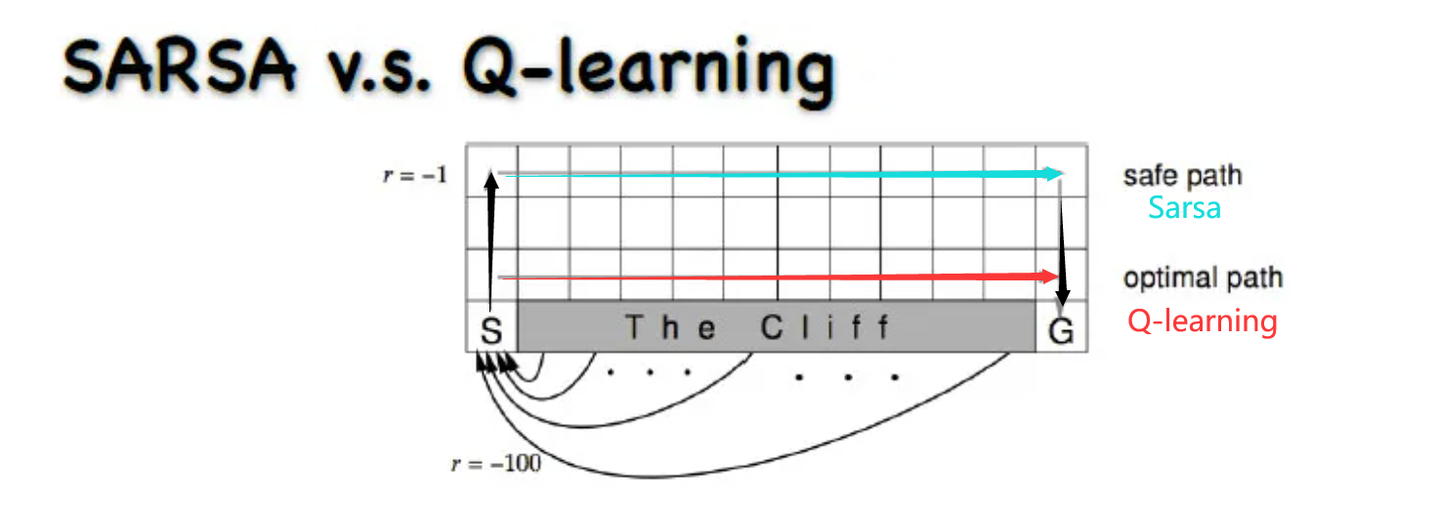
Q-learning更激進,當前的Q值和以后的Q都有關系,越近影響越大
Q_learning:取max,也就是不考慮最終走到很大負獎勵的值,只考慮會不會最終獲得最大獎勵,如果獲得了,那這條路就牛逼,所以么Q-learning更勇猛,不害怕錯,更激進Sarsa:是取某具體的一步,只要周圍有錯(很大的負獎勵),那么就有機會獲得這個不好的獎勵,那么整條路反饋都會評分很差。之后會盡量避開。那么最終導致Sarsa會對犯錯更敏感,會遠離犯錯的點,更保守
三、Deep Q-Network
成千上萬的狀態和動作,Q-Table顯然不現實。使用Q-Network網絡將在給定狀態的情況下近似每個動作的不同 Q 值。
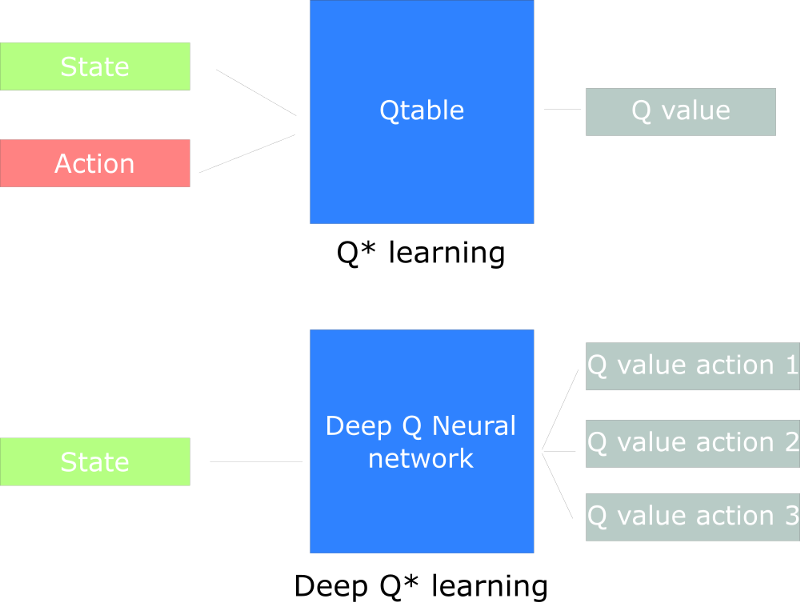
Deep Q-Network是如何工作的?

- input: 一組 4 幀
- 為給定狀態下每個可能的動作輸出一個 Q 值向量
- output:取這個向量中最大的 Q 值來找到我們的最佳行動
前處理:

- 對每個狀態進行灰度化,降低state復雜度
- 裁剪幀
- 減小幀的大小,將四個幀堆疊在一起。堆疊?因為它可以幫助我們處理時間限制問題,產生運動的概念
Convolution Networks
使用一個具有 ELU 激活函數的全連接層和一個輸出層(具有線性激活函數的全連接層),為每個動作生成 Q 值估計。
Experience Replay
problem1:
- 權重的可變性,因為動作和狀態之間存在高度相關性。
- 將與環境交互的順序樣本提供給我們的神經網絡。它往往會忘記以前的體驗,因為它會被新的體驗覆蓋。
solution:
- create a “replay buffer.” This stores experience tuples while interacting with the environment, and then we sample a small batch of tuple to feed our neural network.
- 將重播緩沖區視為一個文件夾,其中每個工作表都是一個體驗元組。您可以通過與環境交互來喂養它。然后你隨機獲取一些工作表來饋送神經網絡

problem2:
- 每個 action 都會影響下一個 state。這將輸出一系列可以高度相關的體驗元組。按順序訓練網絡,我們的Agent可能會受到這種相關性的影響。
從 replay buffer中隨機采樣,我們可以打破這種相關性。這可以防止作值發生振蕩或發散。
solution:
- 停止學習,同時與環境互動。我們應該嘗試不同的東西,隨機玩一點來探索狀態空間。我們可以將這些體驗保存在replay buffer中
- 回憶這些經歷并從中學習。之后,返回 Play with updated value function。

)






)



![AtCoder AT_abc406_c [ABC406C] ~](http://pic.xiahunao.cn/AtCoder AT_abc406_c [ABC406C] ~)






)