1、鎖的可重入
一個不可重入的鎖,搶占該鎖的方法遞歸調用自己,或者兩個持有該鎖的方法之間發生調用,都會發生死鎖。以之前實現的顯式獨占鎖為例,在遞歸調用時會發生死鎖:
public class MyLock implements Lock {/* 僅需要將操作代理到Sync上即可*/private final Sync sync = new Sync();private final static class Sync extends AbstractQueuedSynchronizer {// 判斷處于獨占狀態@Overrideprotected boolean isHeldExclusively() {return getState() == 1;}// 獲得鎖@Overrideprotected boolean tryAcquire(int i) {if (compareAndSetState(0, 1)) {// 設置占有獨占鎖的線程setExclusiveOwnerThread(Thread.currentThread());return true;}return false;}// 釋放鎖@Overrideprotected boolean tryRelease(int i) {if (getState() == 0) {throw new IllegalMonitorStateException();}setExclusiveOwnerThread(null);setState(0);return true;}// 返回一個Condition,每個condition都包含了一個condition隊列public Condition newCondition() {return new ConditionObject();}}@Overridepublic void lock() {System.out.println(Thread.currentThread().getName() + " ready get lock");sync.acquire(1);System.out.println(Thread.currentThread().getName() + " already got lock");}@Overridepublic void lockInterruptibly() throws InterruptedException {sync.acquireInterruptibly(1);}@Overridepublic boolean tryLock() {return sync.tryAcquire(1);}@Overridepublic boolean tryLock(long timeout, TimeUnit timeUnit) throws InterruptedException {return sync.tryAcquireNanos(1, timeUnit.toNanos(timeout));}@Overridepublic void unlock() {System.out.println(Thread.currentThread().getName() + " ready release lock");sync.release(1);System.out.println(Thread.currentThread().getName() + " already released lock");}@Overridepublic Condition newCondition() {return sync.newCondition();}
}
測試代碼:
public class Test {private static MyLock lock = new MyLock();private static class TestThread implements Runnable {public TestThread() {}@Overridepublic void run() {System.out.println(Thread.currentThread().getName());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}reenter(3);}public void reenter(int level) {lock.lock();try {System.out.println(Thread.currentThread().getName() + ":遞歸層級:" + level);if (level == 0) return;reenter(level - 1);} finally {lock.unlock();}}}public static void main(String[] args) {for (int i = 0; i < 3; i++) {Thread thread = new Thread(new TestThread(new JavaBean(0)));thread.start();}}
}
輸出結果:
Thread-2 ready get lock
Thread-0 ready get lock
Thread-2 already got lock
Thread-1 ready get lock
Thread-2:遞歸層級:3
Thread-2 ready get lock
代碼停在這里發生死鎖,原因是 Thread-2 已經拿到了鎖,在遞歸到下一層時,還要獲取 lock,但是 MyLock 沒實現可重入,使得它在執行 tryAcquire() 的原子操作 compareAndSetState(0,1) 時一直不成功,因為期望值此時已經由 0 變成了 1。所以這里需要實現可重入鎖。
想要實現可重入的鎖,需要讓 state 作為鎖的計數器:
// 獲得鎖@Overrideprotected boolean tryAcquire(int i) {if (compareAndSetState(0, 1)) {setExclusiveOwnerThread(Thread.currentThread());return true;} else if (getExclusiveOwnerThread() == Thread.currentThread()) {setState(getState() + 1);return true;}return false;}// 釋放鎖@Overrideprotected boolean tryRelease(int i) {if (getExclusiveOwnerThread() != Thread.currentThread()) {throw new IllegalMonitorStateException();}if (getState() == 0) {throw new IllegalMonitorStateException();}setState(getState() - 1);if (getState() == 0) {setExclusiveOwnerThread(null);}return true;}
state 作為持有這個鎖的線程的數量,鎖被持有了幾次,就要相應的釋放幾次。
2、Java 內存模型(JMM)
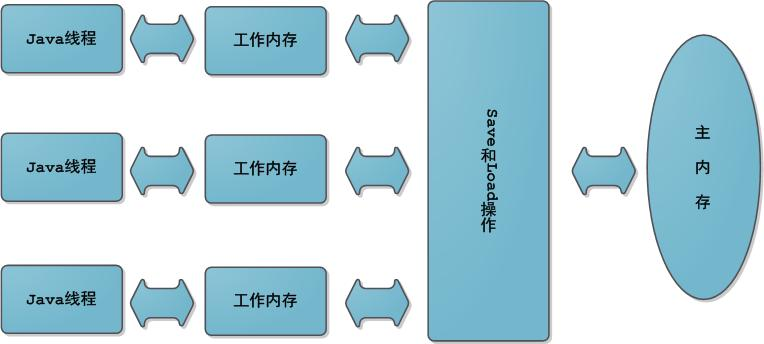
上圖中工作內存和主內存是兩個抽象的概念,不是真實存在的實體,它們可以是 CPU 寄存器、CPU 中的高速緩存,甚至是主內存 RAM 的一部分。
線程在執行計算工作時,會把需要用到的變量從主內存拷貝到自己的工作內存中。線程不能直接操作主內存中的數據,也不能訪問其它線程工作內存。這樣的內存模型使得線程執行過程中面臨兩個問題:可見性與原子性。
2.1 可見性與原子性
可見性是指當多個線程訪問同一個變量時,一個線程修改了這個變量的值,其他線程能夠立即看得到修改的值。
線程對變量的所有操作都必須在工作內存中進行,不能直接讀寫主內存中的變量。對于共享變量 V,多個線程先是在自己的工作內存,之后再同步到主內存。但同步動作并不會及時的刷到主存中,而是會有一定時間差。這個時候線程 A 對變量 V 的操作對于線程 B 而言就不具備可見性了。
要解決共享對象可見性這個問題,可以使 用volatile 關鍵字或者是加鎖。
原子性即一個操作或者多個操作要么全部執行并且執行的過程不會被任何因素打斷,要么就都不執行。
CPU 資源的分配都是以線程為單位的。任務切換大多數是在時間片段結束以后,當然也可以在任何一條 CPU 指令執行完之后(是 CPU 指令而不是某種高級語言的一個語句,如 Java 中的 count++ 至少需要三條 CPU 指令才能完成),這也可能導致線程安全問題。
舉個例子,假如兩個線程都執行語句 count = count + 1,如圖所示:
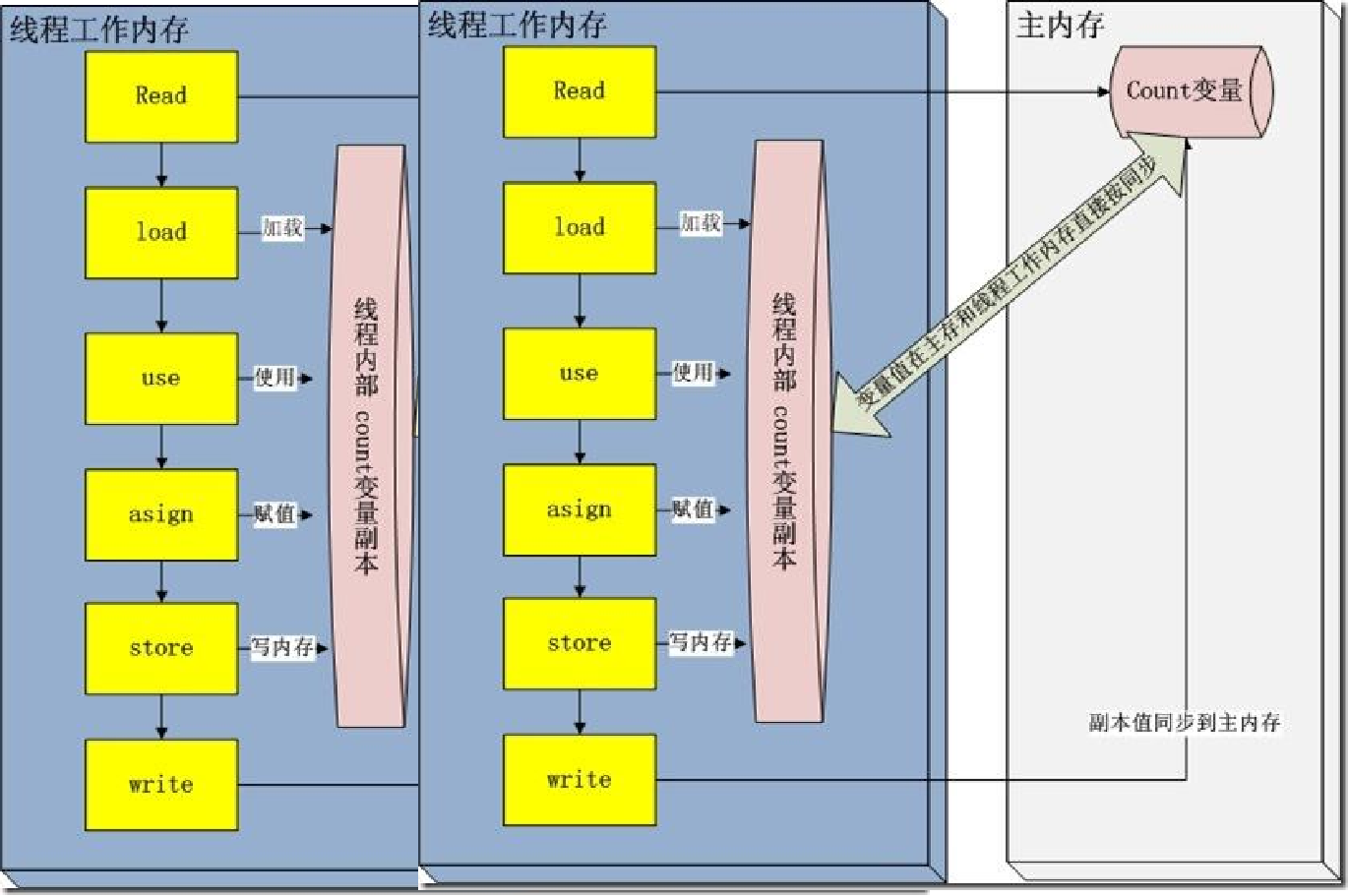
線程 A、B 都把 count 的初值 0 從主內存拷貝到自己的工作內存中開始執行 count + 1 的操作,都得到結果 1 再把副本值同步到主內存中。明明進行了兩次計算,但是得到的卻是計算了一次的結果,這是因為兩個線程對于 count 的操作是互不可見的,彼此不知道對 count 的操作。
上述問題發生的原因是未能保證線程操作的可見性,可以使用 volatile 關鍵字或者是加鎖解決可見性問題。
但是使用 volatile 修飾 count 后問題仍沒有解決,原因就是 count = count + 1 并不是一個原子操作,完全有可能在執行完 count + 1 之后,賦值給 count 之前,CPU 進行上下文切換到其它線程執行完整個 count = count + 1 并將結果同步回內存,最后切換會原線程繼續執行的情況,這就是原子性問題。
2.2 volatile 關鍵字
volatile 是 Java 并發編程包中最輕量級的一個同步工具。
使用 volatile 關鍵字修飾一個變量,會強迫線程每次在計算該變量之前從主內存中拿最新的變量值,并且要求計算完成后立即將新的變量值同步到主內存中。
可以把對 volatile 變量的單個讀/寫,看成是使用同一個鎖對這些單個讀/寫操作做了同步。如:
public class Volatile {volatile int i;// 單個 volatile 變量的讀public int getI() {return i;}// 單個 volatile 變量的寫public void setI(int i) {this.i = i;}private void inc() {// Non-atomic operation on volatile field 'i'i++; // 復合(多個)volatile 變量的讀/寫}
}
等價于:
public class Volatile {int i;// 單個 volatile 變量的讀public synchronized int getI() {return i;}// 單個 volatile 變量的寫public synchronized void setI(int i) {this.i = i;}private void inc() {// 調用同步讀int temp = getI(); // 普通寫,可能在執行這一步之前發生線程切換導致 volatile 修飾的變量發生線程安全問題temp = temp + 1;// 調用同步寫setI(temp);}
}
可見 volatile 只能保證對變量的單個操作的線程安全,但像 i++ 這種復合操作,volatile 則不能保證其線程安全。
因此 volatile 變量自身具有以下特性:
- 可見性:對一個 volatile 變量的讀,總是能看到任意線程對這個 volatile 變量最后的寫入。
- 原子性:對任意單個 volatile 變量的讀/寫具有原子性,但類似于 i++ 這種復合操作不具有原子性。
volatile 適用的場景有:
- 一個線程寫,多個線程讀。(寫線程能立即將結果寫回內存,而讀線程能拿到變量在內存中最新的值。否則寫線程的結果可能并不是立即寫回內存的,導致讀線程拿到的變量不是最新)
- 多個線程寫,但是各個線程寫的值沒有關聯(count = 5 這種直接賦值是沒有關聯的,但是像 count = count +1 這種基于 count 原始值的認為是有關聯)。
volatile 還有一個功能就是抑制重排序。
重排序是指在現代 CPU 中同一時刻可以執行多條指令,可能會造成實際執行的代碼順序與編寫的順序不同的情況。例如:
do(...) {int a = 5; // 1int b = 10; // 2int t;if (b == 5) {t = b;}}
指令重排后可能后編寫的語句會先被執行,即便 b == 5 的條件還未滿足,也先執行 t = b,只不過對于這種條件語句可能會先存入重排序緩沖區中,等到 b == 5 滿足時再從緩沖中取出執行。重排序在單線程中是不會出現亂序問題的,但是多線程則可能會出現。如果用 volatile 修飾某個變量,就不會對其進行重排序。
Intel CPU 可以有十級流水線(即 CPU 可以在同一時刻執行十條指令),Android 芯片的 ARM 架構也可達到三級流水線。
volatile 的實現原理是被 volatile 修飾的共享變量進行讀寫操作的時候會使用 CPU 提供的 Lock 前綴指令。該指令的作用是:
- 將當前處理器緩存行的數據寫回到系統內存。
- 寫回內存的操作會使其它 CPU 里緩存了該內存地址的數據無效。
以上是對 volatile 關鍵字的介紹。最后我們再回頭看下 count = count + 1 的問題的解決方案:
- 使用 volatile 關鍵字搭配 CAS 操作,前者保證可見性,后者保證原子性。實際上 JDK 中很多同步操作都是使用 volatile + CAS 來代替 synchronized。
- 直接用鎖,synchronized、Lock…
3、synchronized 實現原理
3.1 monitorenter 和 monitorexit 指令
底層是使用 monitorenter 和 monitorexit 指令實現的。對于使用了 synchronized 同步代碼塊的代碼:
public class IncTest {private int count;// public 才能被 javap 反編譯出來public int inc() {synchronized (this) {return count++;}}
}
編譯后使用 javap -v IncTest.class 命令反編譯,會看到 inc 方法的匯編指令:
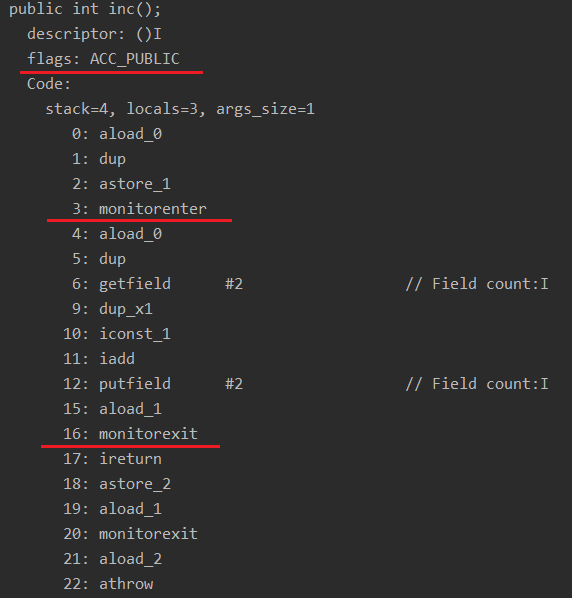
真正執行 count++ 操作的指令是在第4行~第15行,而第3行的 monitorenter 與第16行的 monitorexit 則分別是獲取鎖和釋放鎖的指令。這兩條指令是由編譯器插入的。而使用同步方法時:
public class IncTest {private int count;// public 才能被 javap 反編譯出來public synchronized int inc() {return count++;}
}
其匯編指令為:
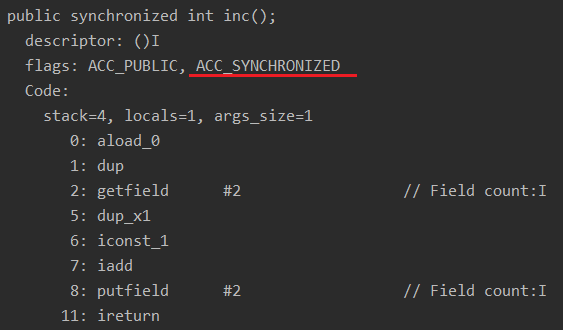
同步方法的匯編指令沒有顯式的 monitorenter 和 monitorexit 指令,但是在方法的 flags 上能看到多出了一個 ACC_SYNCHRONIZED,在運行時還是用到了 monitorenter 和 monitorexit 指令,只不過無法在字節碼指令上體現出來。
總結一下:
- monitorenter 指令是在編譯后插入到同步代碼塊的開始位置,而 monitorexit 是插入到方法結束處和異常處。
- 每個 monitorenter 必須有對應的 monitorexit 與之配對。
- 任何對象都有一個 monitor 與之關聯。
3.2 鎖的存放位置與鎖升級
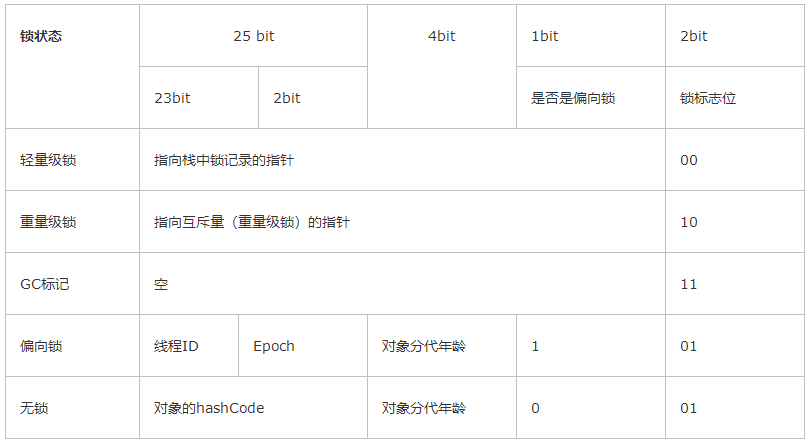
Java 對象在內存中由三部分組成:對象頭、實例數據和對齊填充字節。synchronized 鎖就存放在對象頭中,它由三部分組成:Mark Word、指向類的指針(也稱 KlassPoint)和數組長度(只有數組對象才有):

它們的長度與虛擬機位數保持一致,以 32 位為例,Mark Word 的存儲內容是這樣的:

分代年齡是指對象經歷過 GC 的次數。堆內存至少會被劃分成兩部分,一部分存放新生代對象,一部分存放老年代對象。JVM 默認一個新生代對象經歷過15次 GC 還沒有被回收,就認為該對象是一個需要長期儲存的對象,于是就把它移入堆內存的老年代存放區。
我們都知道 synchronized 同步鎖是一個重量級的鎖,拿鎖失敗的線程會發生上下文切換被阻塞,直到拿到鎖后又發生上下文切換由阻塞狀態變成運行狀態。因為上下文切換的耗時相對于 CPU 執行指令的時間是非常耗時的,一次上下文切換需要大概5000~20000個單位時間,在3~5毫秒左右,而一個1.6G的 CPU 執行一條指令耗時0.6納秒,對于一個100條指令的任務,CPU 的執行時間也就僅僅在0.6毫秒左右。因此,如果使用 synchronized 執行一個較輕量級的任務,被阻塞等待的時間遠遠超過了執行任務本身所需的時間。
為了對上述情況做出優化,從 JDK 1.6 開始出現了鎖升級的概念,意思是說,一個 synchronized 鎖在 Mark Word 中的狀態不是一成不變的,會根據任務的量級對鎖的量級逐步提升,即無鎖狀態->偏向鎖狀態->輕量級鎖狀態->重量級鎖狀態(鎖的四種狀態):
3.2.1 偏向鎖
大多數情況下,鎖不僅不存在多線程競爭,而且總是由同一線程多次獲得(統計發現),為了讓線程獲得鎖的代價更低而引入了偏向鎖(鎖總是會傾向于分配給第一次拿到這個鎖的線程)。無競爭時不需要進行 CAS 操作來加鎖和解鎖,而是直接把鎖給到當前線程。但是一旦發生多個線程間的資源競爭,就要把偏向鎖升級為輕量級鎖,在升級之前,要先撤銷偏向鎖。
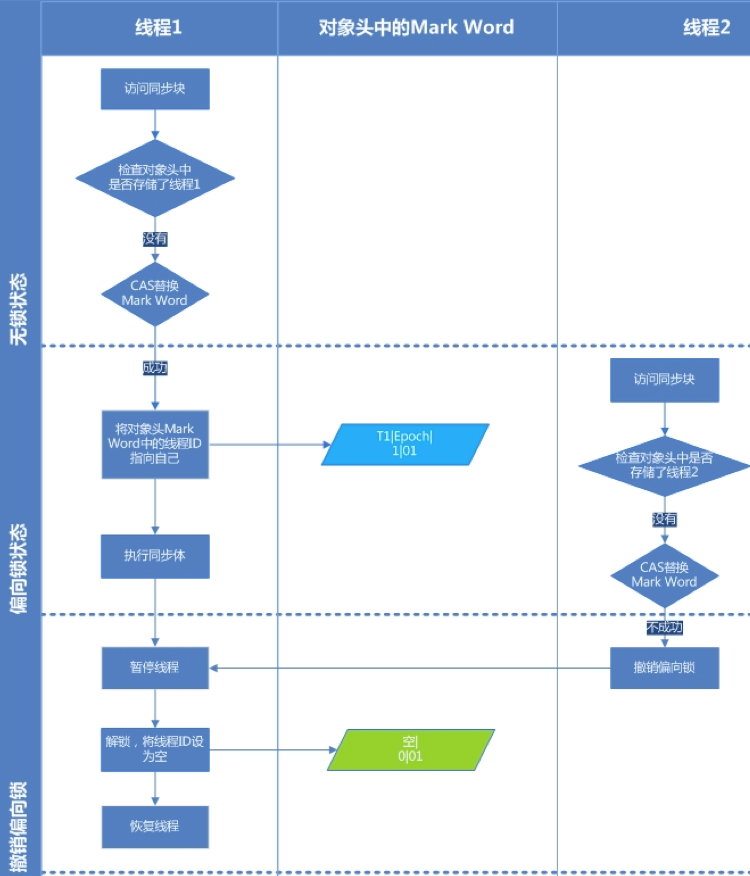
偏向鎖撤銷時中有一個 Stop the World 現象。Stop the World 是指:
在新生代進行的GC叫做minor GC,在老年代進行的GC都叫major GC,Full GC同時作用于新生代和老年代。在垃圾回收過程中經常涉及到對對象的挪動(比如上文提到的對象在Survivor 0和Survivor 1之間的復制),進而導致需要對對象引用進行更新。為了保證引用更新的正確性,Java將暫停所有其他的線程,這種情況被稱為“Stop-The-World”,導致系統全局停頓。Stop-The-World對系統性能存在影響,因此垃圾回收的一個原則是盡量減少“Stop-The-World”的時間。
引用自 JVM學習(7)Stop-The-World
看上圖,線程2在撤銷線程1的偏向鎖時,需要修改線程1工作內存中的相關數據,在修改之前要停止線程1的執行,否則線程2無法修改。因此這里也是發生了 Stop the World 現象,由于它會停止其它線程,因此在有多個線程競爭資源時,是不推薦使用偏向鎖的。
3.2.2 輕量級鎖
輕量級鎖通過 CAS 操作來加鎖和解鎖。其中的自旋鎖借鑒了 CAS 的思想,不會阻塞沒有拿到鎖的線程,而是讓其自旋。假如獲取到鎖的那個線程執行速度很快,那么自旋中的線程也可能很快就拿到了鎖,這樣能節省出兩次上下文切換的時間。
但是自旋是占用 CPU 在不停的循環執行檢測的,倘若線程任務中有訪問服務器之類的重量級操作,如果還是一直不停的自旋,就使得 CPU 不能充分的利用。因此又產生了適應性自旋鎖,它會根據算法決定自旋的時間/次數,一般這個時間就是一次上下文切換的時間。因為引入輕量級鎖的目的就是通過自旋節省掉使用重量級鎖時產生的上下文切換的時間,如果自旋時間已經超過上下文切換時間,那么自旋也就沒有意義了,此時就要把輕量級鎖膨脹為重量級鎖。
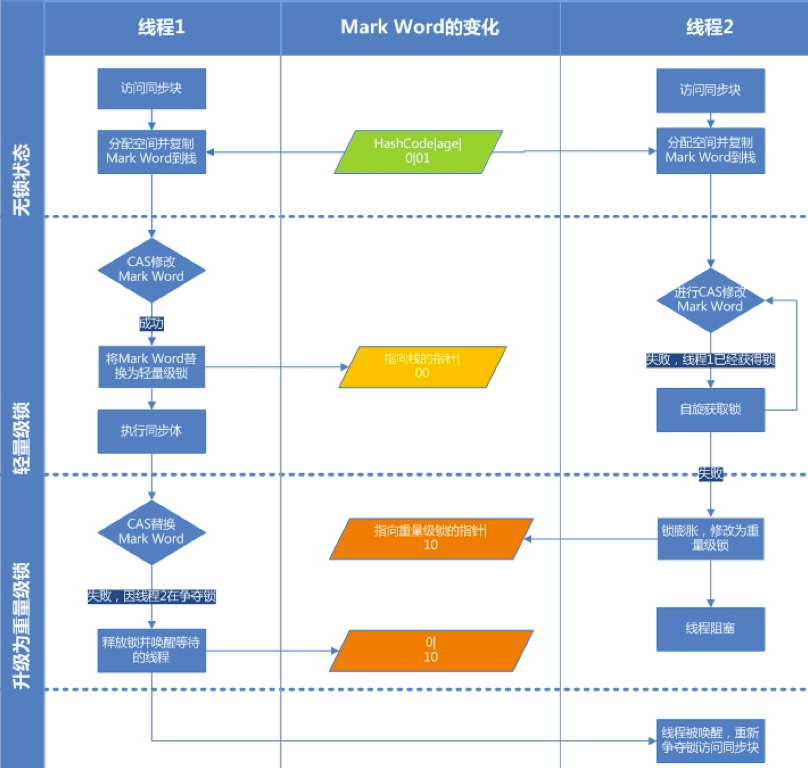
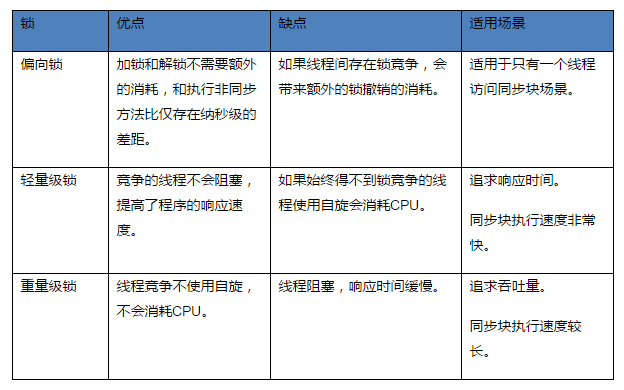
鎖只能升級,不能降級。









使用篇二:docker 鏡像)




)

ScrollList滾動數據列表)


