1.select語句的語法格式
select 字段列表 from 表名
where 條件表達式
group by 分組字段 [having 條件表達式]
order by 排序字段 [asc|desc];
說明:
from 子句用于指定檢索的數據源
where子句用于指定記錄的過濾條件
group by 子句用于對檢索的數據進行分組
having 子句通常和group by 子句一起使用,用于過濾分組后的統計信息
order by子句用于對檢索的數據進行排序處理,默認為升序asc
2.select子句指定字段列表
(1)字段列表可以包含字段名,也可以包含表達式,字段名之間使用逗號分隔,并且順序可以任意指定
(2)可以為字段列表中的字段名或者表達式指定別名,中間使用as關鍵字分隔即可
(3)多表查詢時,同名字段前必須添加表名前綴,中間使用"."分隔
(4)結果集中的列名為字段列表中的字段名或者表達式名
例如:select version(), now(), pi(), 1+2, null=null, null!=null, null is null;的查詢如下:
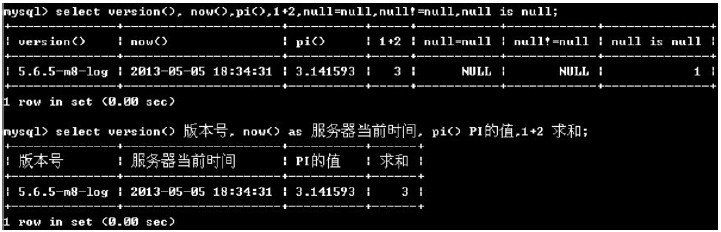
(5)檢索表student全部記錄
select * from student;
3.使用謂詞過濾記錄
MYSQL中的兩個謂詞distinct和limit可以過濾記錄
(1)使用謂詞distinct過濾結果集中的重復記錄
數據庫表中不允許出現重復的記錄,但這不意味著select的查詢結果擊中不會出現記錄重復的現象。如果需要過濾結果集中重復的記錄,可以使用謂詞關鍵字distinct,語法格式如下:
distinct 字段名;
例如:select distinct department_name from classes;
(2)使用謂詞limit查詢某幾行記錄
使用select語句時,經常需要返回前幾條或者中間某幾條記錄,可以使用謂詞關鍵字limit實現。語法格式如下:
select 字段列表
from 數據源
limit [start,] length
例如:前三條記錄
select * from student limit 0,3; 等效于 select * from student limit 3;
從第二條記錄開始的3條記錄
select * from choose limit 1,3;
4.使用from指定數據源
在實際應用中,為了避免數據冗余,需要將一張大表劃分成若干張小表。但檢索數據時,為了更加直觀看到所有數據,往往需要將若干張小表縫補連接成成一張大表。連接的方法有兩種,一種是在from子句使用連接運算,講多個數據源按照某種連接條件“縫補”在一起,一種是在where子句中指定連接條件。
通過from指定連接運算的格式如下:
from 表名1 連接類型 join 表名2 on 連接條件;
SQL標準中,連接類型有inner連接和outer連接,而外連接又分為left左外連接,right右外連接以及full完全外連接。
如果表1和表2存在相同意義的字段,則可以通過該字段連接這兩張表。例如,在student表中,想要直接看到學生和其班級信息,可以通過班級id把班級信息連接上來。
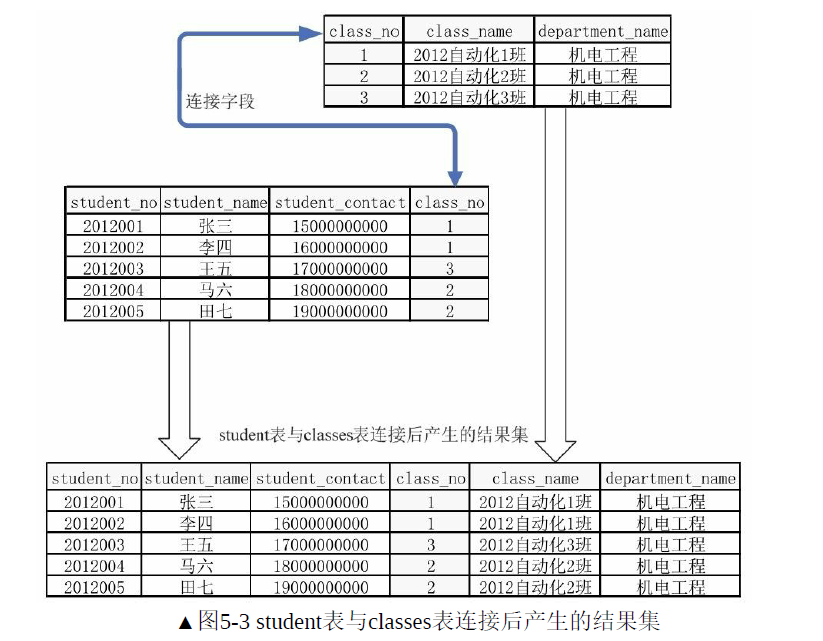
(1)內連接:
from 表1 inner join 表2 on 連接條件
重點:會過濾掉表1和表2的不符合條件的信息
(2)左外連接:
from 表1 left join 表2 on 連接條件
重點:保留表1的全部信息,而表2 不符合的信息則過濾掉,表1如果存在某些匹配不到表2的信息,則該行的表2部分信息都是NULL
(3)右外連接:
from 表1 right join 表2 on 連接條件
重點:保留表2的全部記錄,而表1中不符合的信息則過濾掉,表2中如果存在某些匹配不到表1的信息,則該行的表1部分則都是NULL。
(4)全連接:
MYSQL暫不支持全連接運算,不贅述。
5.多表連接
格式如下:
from 表1 連接類型 join 表2 on 連接條件
連接類型 join 表3 on 連接條件
6.使用where子句過濾結果集
(1)單一條件過濾
where 表達式1 比較運算符 表達式2
select * from classes where class_name=‘2012自動化2班’;
(2)is NULL運算
表達式 is [not] NULL
判斷表達式的值是否為NULL或者不為NULL
(3)邏輯運算符
邏輯非為符號 !, 一般用于"! 布爾表達式"
例如: select * from course where !(up_limit=60);
等效于: select * from course where up_limit != 60;
(4)and邏輯運算 和 or邏輯運算
布爾表達式1 and|or 布爾表達式2
(5)between … and …
用于判斷一個表達式的值是否位于指定的取值范圍內
(6)in運算符
in運算符用于判斷一個表達式的值是否位于一個離散的數學集合內
格式:表達式 [not] in (數學集合)
例如:select * from student where substring(student_name, 1, 1) in ('張’, ‘田’);
(7)like進行模糊查詢
like運算符用于判斷一個字符串是否與給定的模式相匹配。模式是一種特殊的字符串,特殊之處在于它不僅包含普通字符,還包含通配符。
格式:字符串表達式 [not] like 模式
通配符:
%(匹配零個或多個字符組成的任意字符串)
_ (匹配任意一個字符)
例如:
檢索所有姓張但是名字只有兩個字的學生的信息
select * from student where student_name like ‘張_’;
檢索姓名中帶有’三’的所有學生的信息
select * from student where student_name like ‘%三%’;
7.使用order by排序
order by 字段名1 [asc|desc] […, 字段名n [asc|desc]]
(1)單個排序
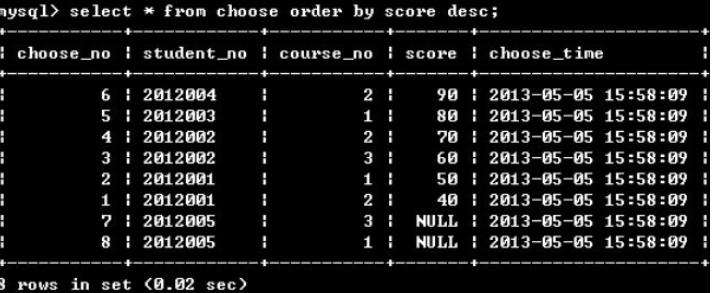
(2)多重排序
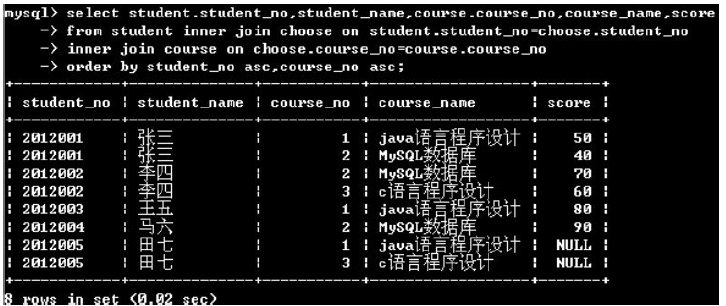
8.使用聚合函數匯總結果集
(1)聚合函數:sum(), avg(), count(), max(),min()
9.使用groupby子句對記錄進行分組
格式:group by 字段列表[having 條件表達式][with rollup]
(1)單獨使用group by沒意義,因為只保留各分組的一條記錄
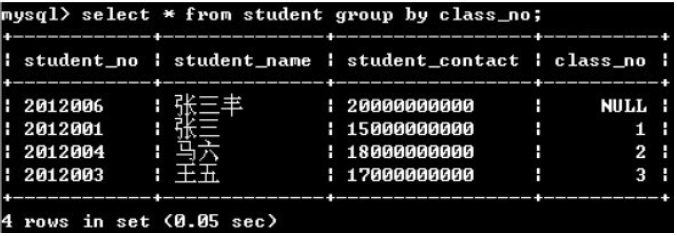
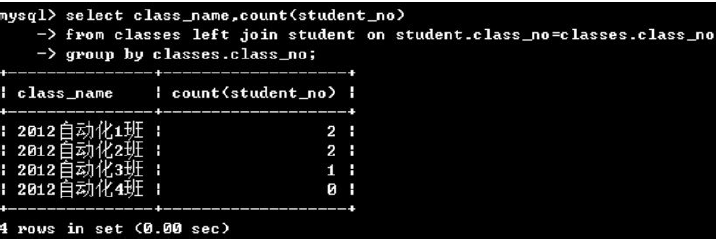
(2)group by + 聚合函數
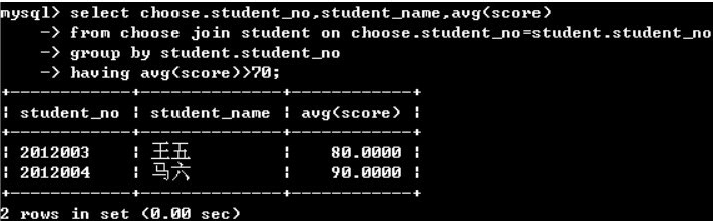
(3)group by +having子句
having子句無法用where代替,因為where和group by和having同時存在的時候,where首先運行,然后group by和having對where運算結果進行過濾篩選。
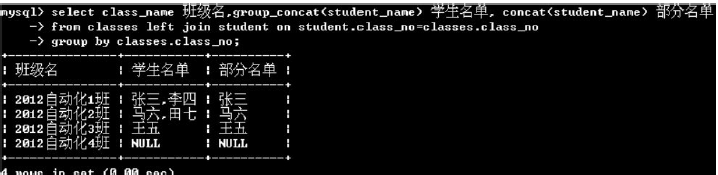
(4)group_concat()
group_concat()函數可以將各個字段的值用逗號連接起來
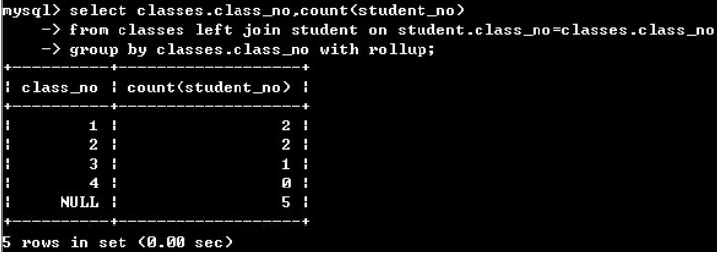
(5)group by + 聚合函數 + with rollup
在原先的group by+聚合函數中,聚合函數處理每個分組,但是沒有處理整個表,with rollup在最后加上一行處理整個表的結果
10.合并結果集
格式:
select 字段列表1 from table1
union [all]
select 字段列表2 from table2
要求:字段列表1和字段列表2的字段個數和對應的數據類型必須一致
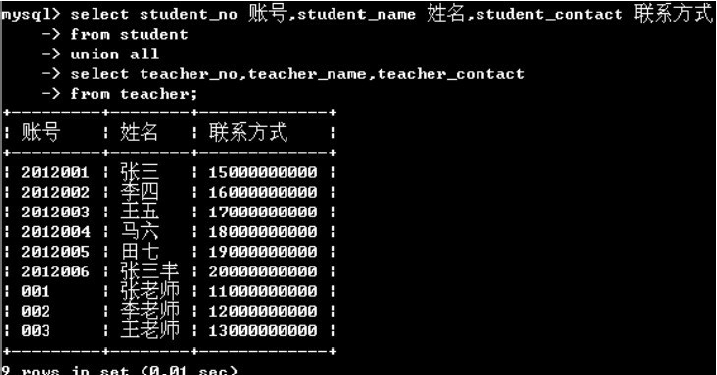
union和union all 的區別:當使用union時,MYSQL會篩選掉select結果中重復的記錄。而是用union all時,MYSQL會直接合并兩個結果集。
例如:查詢所有學生和老師的聯系方式
11.子查詢
(1)如果子查詢返回單個值,則可以將這個子查詢結果和其他表達式的值進行比較
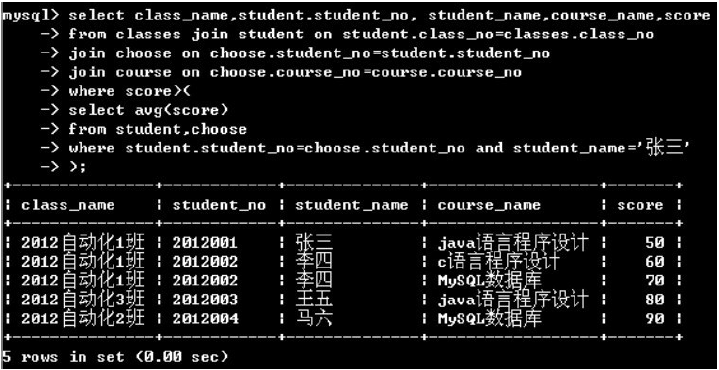
(2)子查詢+in運算符
子查詢經常與in運算符一起使用,用于將一個表達式的值與子查詢返回的一列值進行比較,如果表達式的值是此列中的任何一個值,則條件表達式的結果為true,否則為false
例如:select id, name,sex from human where id in (select human_id from bese_human);
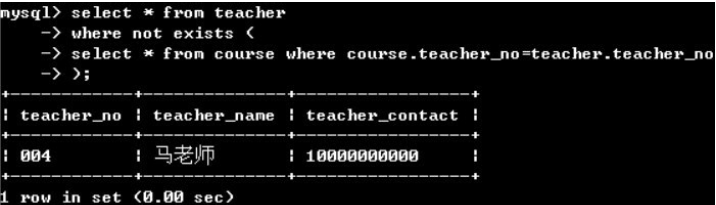
(3)子查詢+exists運算符
exists邏輯運算符用于檢測子查詢結果集中是否包含記錄。如果結果集中至少包含一條記錄,則exists的結果為true,否則為false
例如:檢索沒有申請選修課的教師的信息
select * from teacher
where not exists(
select * from course where course.teacher_no=teacher.teacher_no
);
說明:遍歷到teacher表一行,則執行子查詢,子查詢為true則不顯示,子查詢不是true則展示
(4)子查詢+any運算符
any運算符通常與比較運算符一起使用。使用any運算符時,通過比較運算符將一個表達式的值與子查詢返回的一列值逐一進行比較,若某次比較結果為true,否則為false。
select * from
student join classes on student.class_no=classes.class_no
join choose on choose.student_no=student.student_no
where score > any(
select score from choose where class_no = 1;
);
(5)子查詢+all運算符
all運算符通常與比較運算符一起使用。使用all運算符時,通過比較運算符將一個表達式的值與子查詢返回的一列值逐一進行比較,若所有比較結果為true,則為true,否則為false。
select * from
student join classes on student.class_no=classes.class_no
join choose on choose.student_no=student.student_no
where score > all(
select score from choose where class_no = 1;
);
12.正則表達式模糊查詢
與like運算符相似,正則表達式主要用于判斷一個字符串是否與給定的模式匹配。但正則表達式的模式匹配功能比立刻運算符的模式匹配功能更為強大,且更加靈活。使用正則表達式進行模糊查詢時,需要使用regexp關鍵字,語法格式如下:
字段名 [not] regexp [binary] ‘正則表達式’
說明:正則表達式匹配英文字母時,默認情況下不區分大小寫,除非添加binary選項或者將字符序collation設置為bin或者cs。
正則表達式由一些普通字符和一些元字符構成,普通字符包括大寫字母,小寫字母和數字,甚至是中文簡體字符。而元字符具有特殊的含義。
元字符:
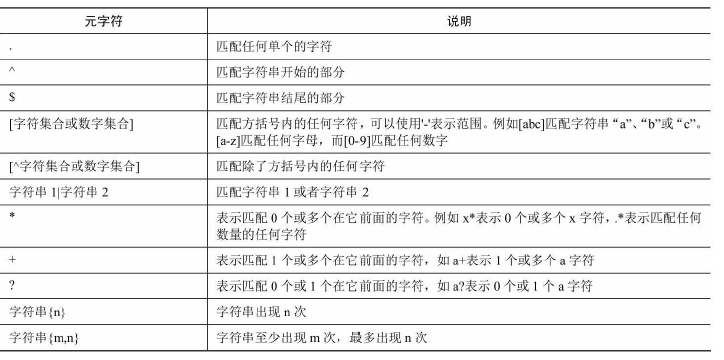
(1)檢索含有‘java’的課程信息
select * from course where course_name regexp ‘java’;
(2)檢索以‘java’結尾的課程信息
select * from course where course_name regexp ‘java$’;
(3)檢索以‘java’開頭的課程信息
select * from course where course_name regexp ‘^java’;
(4)檢索以15或者18開頭的數字,后面跟著9個數字
select * from course where course_number regexp ‘1[58][0-9]{9}’
13.MYISAM存儲引擎的全文檢索
對于海量數據庫而言,使用like關鍵字或者正則表達式對字符串進行模糊查詢,很多時候無法使用索引,因此需要進行全表掃描,檢索效率較低。如果模糊查詢并發操作較多,將會急劇降低數據庫的檢索性能,甚至導致服務器宕機。
使用like或者正則表達式進行模糊查詢,當模式的第一個字符是通配符時,將導致索引無法使用。
針對這一個問題,MYSQL中的全文檢索使用特定的分詞技術,利用查詢的關鍵字和查詢字段內容之間的相關度進行檢索。通過全文索引可以提高文本匹配的速度。
格式:
select 字段列表
from 表名
where match (全文索引字段1,全文索引字段2, …) against (搜索關鍵字[全文檢索方式])
注意:使用全文檢索前,需要在某些字段創建全文索引,使之成為全文索引字段。
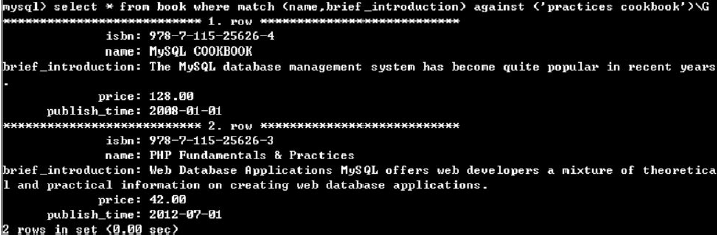
(1)檢索書名或者簡介中設計"practices"單詞的所有圖書信息
select * from book where match (name, brief_introduction) against (‘practices’)\G

(2)檢索書名或者簡介中設計"practices"或者“cookbook”單詞的所有圖書信息
select * from book where match (name, brief_introduction) against (‘practices cookbook’)\G
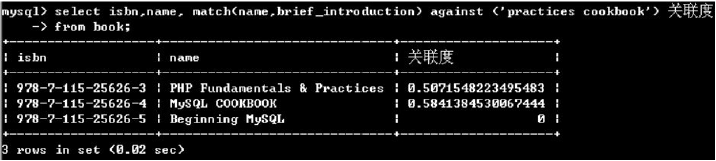
(3)MYSQL對于全文檢索的結果集是按照關聯度進行排序的(大致,實際上比較繁雜)。而關聯度信息正是全文檢索的子句得出的結果
select isbn,name match(name, brief_introduction) against (‘practices cookbook’) 關聯度 from book;
(4)MYSQL在執行全文檢索時,會計算檢索詞在表中記錄的頻率,如果頻率高達100%,意味著所有記錄都含有該檢索詞,那么該全文檢索實際上沒有太多意義。
MYSQL在進行全文檢索時,默認情況下忽略權重超過50%的記錄,這個50%稱為閾值。
(5)MYSQL對搜索關鍵字規定了最小長度和最大長度
show variables like ‘ft_min_word_len’;
show variables like ‘ft_max_word_len’;
這兩個變量是靜態變量,不能使用set命令設置,可以在my.cnf配置文件的[mysqld]選項組中加上想要的設置。
(6)MYSQL在MYISAM引擎的全文搜索中,內置了545個停用詞,其中包括has,all,be,been,that等單詞。MYISAM忽略搜索中的停用詞,可以使用show variables like 'ft_stopword_file’查看停用詞。
‘ft_stopword_file’變量也是靜態變量,無法使用set命令進行設置,管理員可以自行創建停用詞文件,然后在my.cnf配置文件的[mysqld]選項組中加上“ft_stopword_file=‘文件路徑’”的方法設置全文檢索停用詞。
14.全文檢索方式
常用全文檢索方式有3種:自然語言檢索,布爾檢索和查詢擴展檢索
(1).自然語言檢索
MYSQL全文檢索中的默認類型,單表查詢,存在閾值限制
(2).布爾檢索
沒有閾值限制,且可以進行多表查詢,還可以包含特定意義的操作符,如+,-,<,>等。
(3).查詢擴展檢索
查詢擴展檢索是對自然語言檢索的一種改動,當查詢短語很短時游泳。先進行自然語言檢索,然后把關聯度較高的記錄中的詞添加到搜索關鍵字中進行二次自然語言檢索,然后返回查詢結果集。
15.innodb表的全文檢索
(1)innodb存儲引擎忽略了全文檢索中閾值的概念
(2)innodb_ft_min_token_size(默認值3)和innodb_ft_max_token_size(默認值84)定義了搜索關鍵字的最小長度以及最大長度
(3)innodb_ft_enable_stopword(默認值ON)定義了是否開啟停用詞
(4)innodb的停用詞在information_schema數據庫的INNODB_FT_DEFAULT_STOPWORD表中定義









![[c語言日寄]數據結構:棧](http://pic.xiahunao.cn/[c語言日寄]數據結構:棧)









基本概念)