一、策略梯度核心思想和原理
從時序差分算法Q學習到深度Q網絡,這些算法都側重于學習和優化價值函數,屬于基于價值的強化學習算法(Value-based)。
1. 基于策略方法的主要思想(Policy-based)
基于價值類方法當狀態動作空間較大且連續時面臨挑戰,對基于策略的目標函數使用梯度上升優化參數最大化獎勵。在策略梯度中,參數化的策略π不再是一個概率集合,而是一個概率密度函數
2. 優點:建模效率高、探索性更好、收斂性更優
3. 模型結構
是無環境模型的結構,神經網絡作為策略函數近似器,其參數表示或策略
仍然是一個無環境模型結構,和之前基于價值類的方法有很大的不同。首先,策略不再是隱式的,而是要直接求解。對于深度策略梯度而言就是使用神經網絡作為策略函數的函數逼近器,通過神經網絡的參數來表示策略π。其次,在下邊的PGM圖中,沒有畫出價值結點,多了獎勵累計部分,這是因為經典的策略梯度方法經常使用獎勵和的期望作為優化的目標,而不直接使用狀態價值函數V(s),或者動作價值函數Q(s,a)。與之前的Value-Based方法不同,基于策略的方法不依賴與價值函數的估計,不適用貝爾曼方程或者貝爾曼期望方程,是直接使用神經網絡逼近策略函數,并使用策略梯度來進行更新。
R(t)和G(t)的區別:其中R(t)是累計獎勵,G(t)是回報。回報是隨時間步變化的量,累計獎勵R是整個episode的獎勵的總和。
4. 目標函數
episode可以用很多個,比如打游戲每個回合就是一個episode,希望在多個回合中找到最佳策略或者規律。目標函數的設計原則就是所有的回合總回報的加權平均值最大(用加權平均的原因是因為每條軌跡發生的概率不同,用的經常發生,有的發生的概率極小,顯然不能平均)
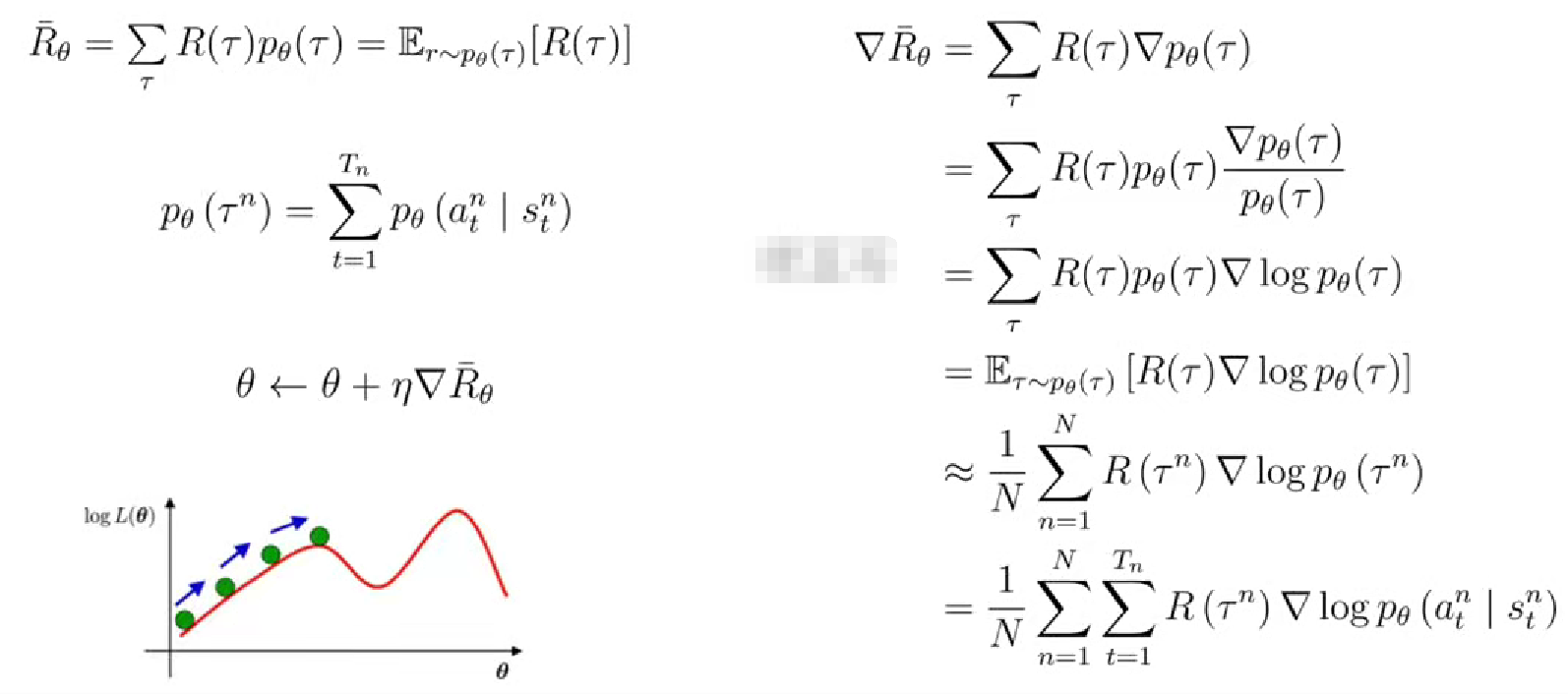
5. 策略梯度的兩種常見改進
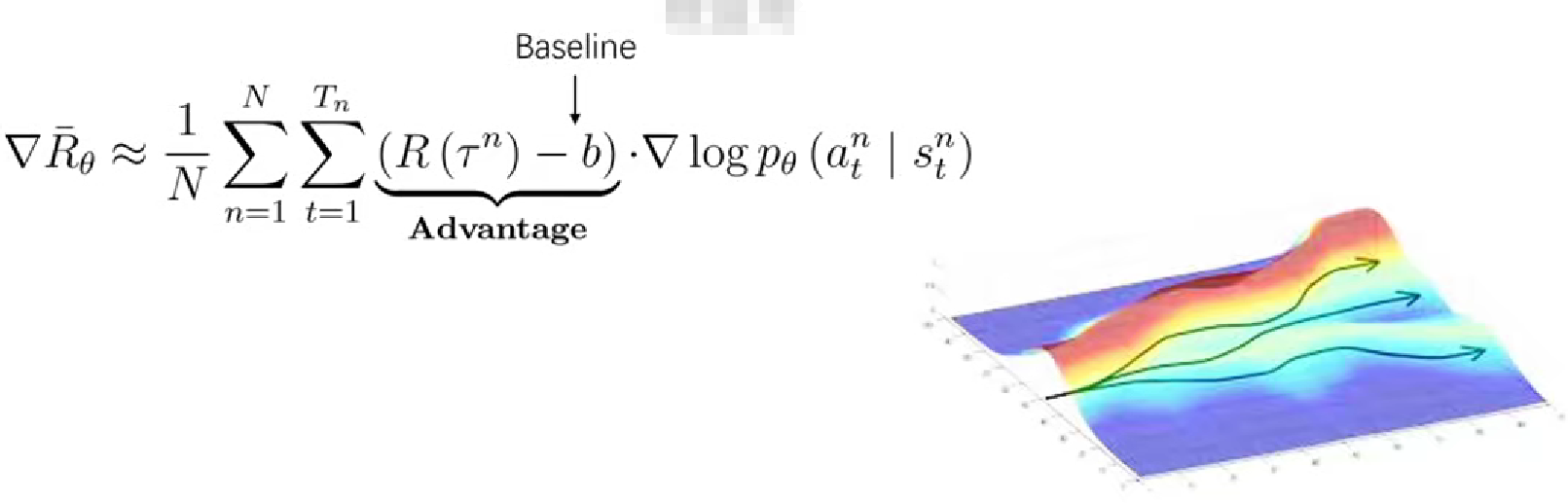
5.1 添加基線:如前所述,策略梯度的計算往往采樣軌跡的方法。通過多條軌跡,也就是多次與環境的交互來收集數據,每條軌跡都會算出來一個梯度用來更新函數的參數,然而單條軌跡梯度可能存在高方差的問題,容易導致訓練過程的不穩定,或者說收斂的速度比較慢。為了解決這個問題,引入所謂基線這一概念,就是在目標函數梯度中減去一個b,其中b代表baseline,b是一個相對獎勵的參考值,因為他的波動范圍相對來說更小,因此可以使訓練過程更加穩定并且加快收斂速度。具體可以通過減去獎勵均值,再除以方差來實現,這樣可以將獎勵調整為正態分布,從而使得梯度更新的尺度更加合適。![]() 這一項叫優勢函數,某種程度上可以將優勢函數視為價值函數在策略梯度算法中的一種變體。在強化學習中,價值函數通常在基于價值的方法,如動態規劃、Q-Learring等中使用,來估計狀態或者動作的價值來指導agent的決策。在策略梯度的方法當中,通常使用優勢函數,不過這都屬于價值評估的范疇。如果我們用便想邊干來比喻強化學習過程的話,想就代表求價值,干就是求策略,優勢函數就是屬于想的這個范疇中。
這一項叫優勢函數,某種程度上可以將優勢函數視為價值函數在策略梯度算法中的一種變體。在強化學習中,價值函數通常在基于價值的方法,如動態規劃、Q-Learring等中使用,來估計狀態或者動作的價值來指導agent的決策。在策略梯度的方法當中,通常使用優勢函數,不過這都屬于價值評估的范疇。如果我們用便想邊干來比喻強化學習過程的話,想就代表求價值,干就是求策略,優勢函數就是屬于想的這個范疇中。
5.2 改進二:Credit-Assignment功勞分配
在前面的目標函數當中,同一個episode中所有時間步的狀態動作對使用同樣的獎勵來進行加權,這顯然是不公平的,因為在同一個episode中有些動作是好的,有些動作是不好的,不應該公平對待。改進如下:在計算總回報的時候,只計算當前時刻之后的獎勵,忽略之前的。還可以再未來獎勵前加個折扣,讓影響力計算更加合理,因為一般情況下,時間拖的越久,未來時刻對當前時刻的影響力就越小。因此γ隨時間呈指數級的減小。
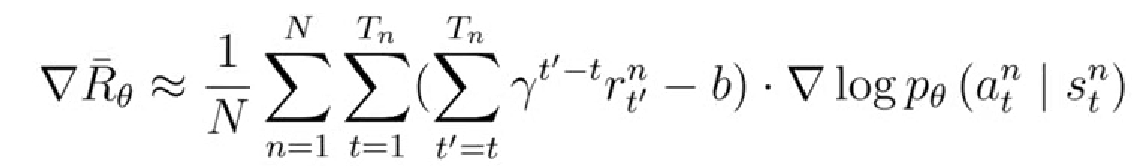
6. 策略梯度的適用條件和常見的應用場景
6.1 策略梯度方法可以處理連續的問題,而不需要對動作空間進行離散化。
6.2 適用于高緯度狀態空間的問題,可以處理包含大量狀態的環境。
6.3 通過參數化的策略函數,使得策略可以靈活調整和優化
在應用場景方面,策略梯度方法適用于各種強化學習任務,比如機器人控制、游戲等等。這些問題中往往都有連續動作空間,此外面對高緯度狀態空間問題,圖像處理任務,自然語言處理任務等,策略梯度表現出良好的適應性,還有就是策略梯度方法可以很好的應用于帶有約束的優化問題。總的來說策略梯度方法相對于基于價值的方法更加靈活,特別是在連續動作空間和高緯度狀態空間的情況下。
面臨的挑戰:梯度估計的方差問題和采樣效率等等,在離散動作空間和低緯狀態空間中基于價值的方法更具有優勢。
二、蒙特卡洛策略梯度
在強化學習中提到蒙特卡洛一般就是指基于經驗的學習方法,使用采樣軌跡進行學習,而且通常是用完整的軌跡進行學習和估計。
1. 主要思想:蒙特卡洛策略梯度就是一種結合了蒙特卡洛學習和策略梯度的方法,通過采樣軌跡,采用梯度上升法,更新參數,最大化累計獎勵。
2. 模型結構
屬于無環境模型,用神經網絡逼近策略函數。選用回報,而非總回報表示價值。
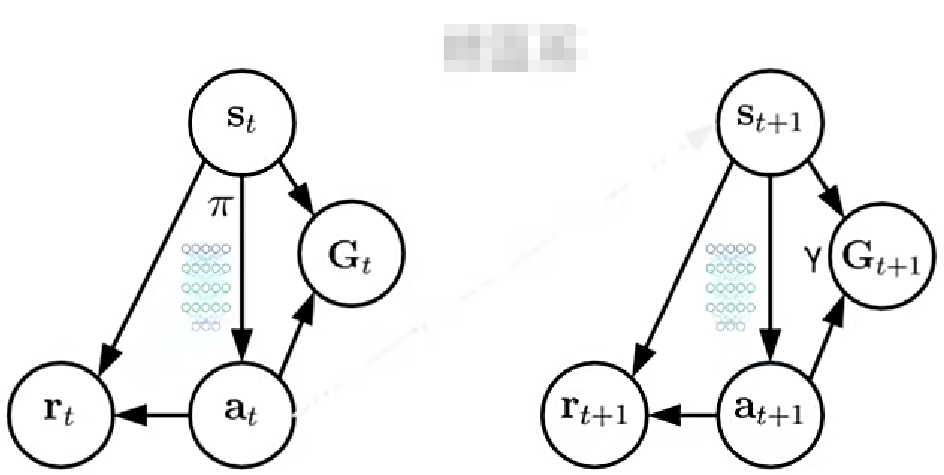
3. 概念對比

4. 目標函數:給定策略之后的累計期望
5. 適用條件
5.1 通常適用于離散空間的強化學習問題,不需要進行連續的動作選擇。
5.2 不依賴環境模型的支持,而是通過環境模型的交互來收集經驗的樣本。
5.3 由于該方法使用完整的軌跡方法進行參數更新,進而可以處理高方差問題,更好地利用軌跡中的獎勵信息
5.4 無需探索策略或探索率,因為可以通過與環境的交互來進行自然地探索,這使得他在探索利用平衡方面更加靈活。
三、近端策略優化算法(PPO)
Proximal Policy Optimization
1. 主要思想:
傳統策略梯度方法是同策略的,有一些列顯著的缺點:
采樣效率低:每個樣本只用于一次更新,用完就廢掉,無法重復利用
方差大、收斂不穩定:受樣本隨機性和噪聲的影響
難以探索新策略空間:只使用當前的采樣數據,容易陷入局部最優
優點:異策略(off-policy)將采樣與學習分離,數據復用,收斂性和穩定性更好
2. 前置知識
2.1 重要性采樣(Importance Sampling)
是一種用于估計概率分布的統一方法,常常用于強化學習,概率推斷和統計推斷等領域,主要目的是用一個概率分布的樣本來估計另一個概率的期望或者是累計的分布函數。比如:兄弟倆,其中有一個很神秘,不知道其連續分布長什么樣。另外一個很熟悉,分布是已知的。兩個人都可以采樣,也就是說可以同時知道他們的一些具體的行為,比如他倆同時參加一次考試得到的分數,這樣以來就能根據一個人的行為,再加上兩個人在某些具體的事上的比值來估計另外一個人。
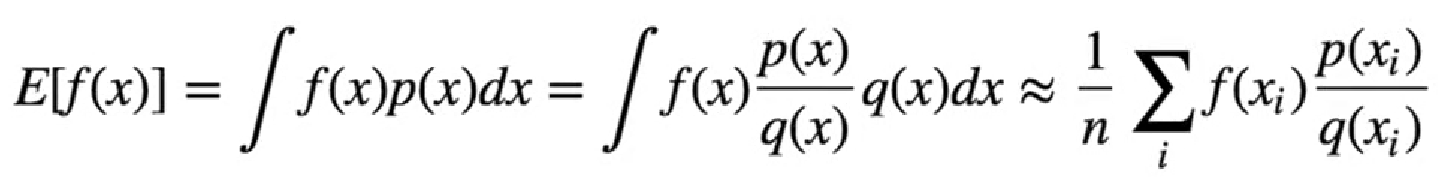
3. 目標函數
近端強調的就是KL項起到的約束作用。重要性采樣+KL散度=PPO算法同策略到異策略的完美轉換。其中KL散度是用來度量兩種分布間相似程度的量,簡單理解就是一個數值,約相似這個數值就約小。
4. 改進
4.1 改進一、自適應懲罰(PPO penalty)
在KL懲罰之前有個參數β,理想情況下是可以自適應調整的,用來實現動態懲罰的目的。具體調整如下:進一步前邊的期望可以簡化為一個求和的運算有兩個原因,一是假定所有樣本的概率相同。二是在求梯度的情況下除以樣本數的意義也不是很大,去掉也不受影響。

4.2 PPO-clip
clip修剪:簡化原有目標函數KL散度部分,提高運算效率。
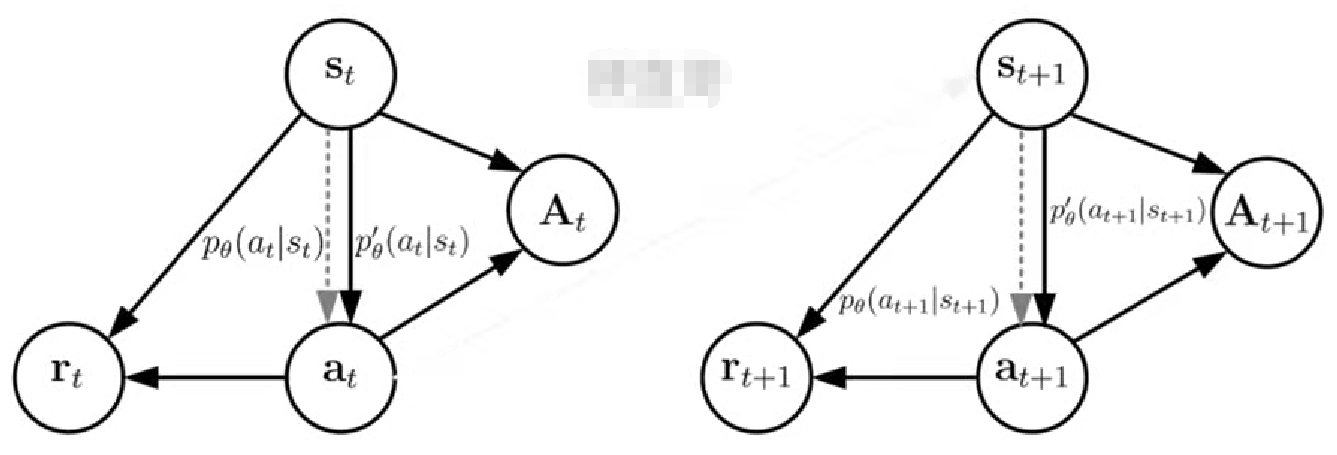
5. 模型結構
重要性采樣PPO和KL散度都是在修正或約束兩個策略分布間相似度
其中虛線表示未知的目標策略,實線表示已知的采樣策略
6. 適用條件:
6.1 在高緯度連續動作空間搜索最優策略的問題:機器人控制、自動駕駛等
6.2 適用于需要穩定收斂的任務:限制每次更新中策略改變幅度
6.3 大規模分布式訓練:可以在多個并行訓練實例上更新和采樣







》)






)
)


:六個默認構造函數(一))
數據結構的基礎概念、線性表)