目錄
前言
一、 本文目標
二、環境準備
2.1 安裝依賴
2.2 配置 ChromeDriver
三、小米商城頁面結構分析
3.1 商品列表結構
3.2 分頁結構
四、Selenium 自動化爬蟲實現
4.1 腳本整體結構
4.2 代碼實現
五、關鍵技術詳解
5.1 Selenium 啟動與配置
5.2 頁面等待與異步加載
5.3 商品數據解析
5.4 分頁處理
5.5 異常處理
5.6 可選:保存到 MongoDB
六、Headless 模式與瀏覽器兼容
七、常見問題與優化建議
7.1 反爬機制
7.2 頁面結構變動
7.3 數據完整性
7.4 性能優化
八、總結

?🎬 攻城獅7號:個人主頁
🔥 個人專欄:?《python爬蟲教程》
?? 君子慎獨!
?🌈 大家好,歡迎來訪我的博客!
?? 此篇文章主要介紹 Selenium 的實戰
📚 本期文章收錄在《python爬蟲教程》,大家有興趣可以自行查看!
?? 歡迎各位 ?? 點贊 👍 收藏 ?留言 📝!
前言
????????在實際數據采集和電商分析中,很多網站采用了前端渲染和復雜的 Ajax 請求,直接分析接口變得困難。小米商城就是這樣一個典型案例。與淘寶類似,小米商城的商品列表和分頁都依賴于前端 JavaScript 動態渲染,Ajax 接口參數復雜且可能包含加密校驗。對于這種頁面,最直接、最穩定的抓取方式就是使用 Selenium 模擬真實用戶操作。
????????本篇文章將以"空調"為例,詳細講解如何用 Selenium 自動化爬取小米商城的空調商品信息,包括商品名稱、價格、圖片鏈接、商品詳情鏈接等,并實現自動翻頁抓取。文章內容涵蓋環境準備、頁面結構分析、Selenium 腳本編寫、數據解析、翻頁處理、異常處理、可選的 MongoDB 存儲、Headless 模式、常見問題與優化建議等,幫助你系統掌握電商前端動態頁面的爬取方法。
一、 本文目標
- 利用 Selenium 自動化爬取小米商城空調商品信息
- 用 PyQuery 解析商品名稱、價格、圖片、鏈接等數據
- 實現自動翻頁抓取多頁商品
- 可選:將數據保存到 MongoDB
- 兼容 Headless(無界面)模式
- 具備異常處理和反爬優化思路
二、環境準備
2.1 安裝依賴
- Chrome 瀏覽器(建議最新版)
- ChromeDriver(版本需與 Chrome 主版本一致)
- Python 3.7+
- Selenium
- PyQuery
- (可選)MongoDB
安裝 Python 依賴:
pip install selenium pyquery# 可選:pip install pymongoChromeDriver 下載地址:( https://googlechromelabs.github.io/chrome-for-testing/ )
注意: ChromeDriver 版本必須和 Chrome 瀏覽器主版本號一致,否則 Selenium 啟動會報錯。
2.2 配置 ChromeDriver
- 將 chromedriver.exe 放到 PATH 路徑下,或在代碼中指定其絕對路徑。
- 建議用 ChromeDriver 的"可分離"模式,便于調試。
三、小米商城頁面結構分析
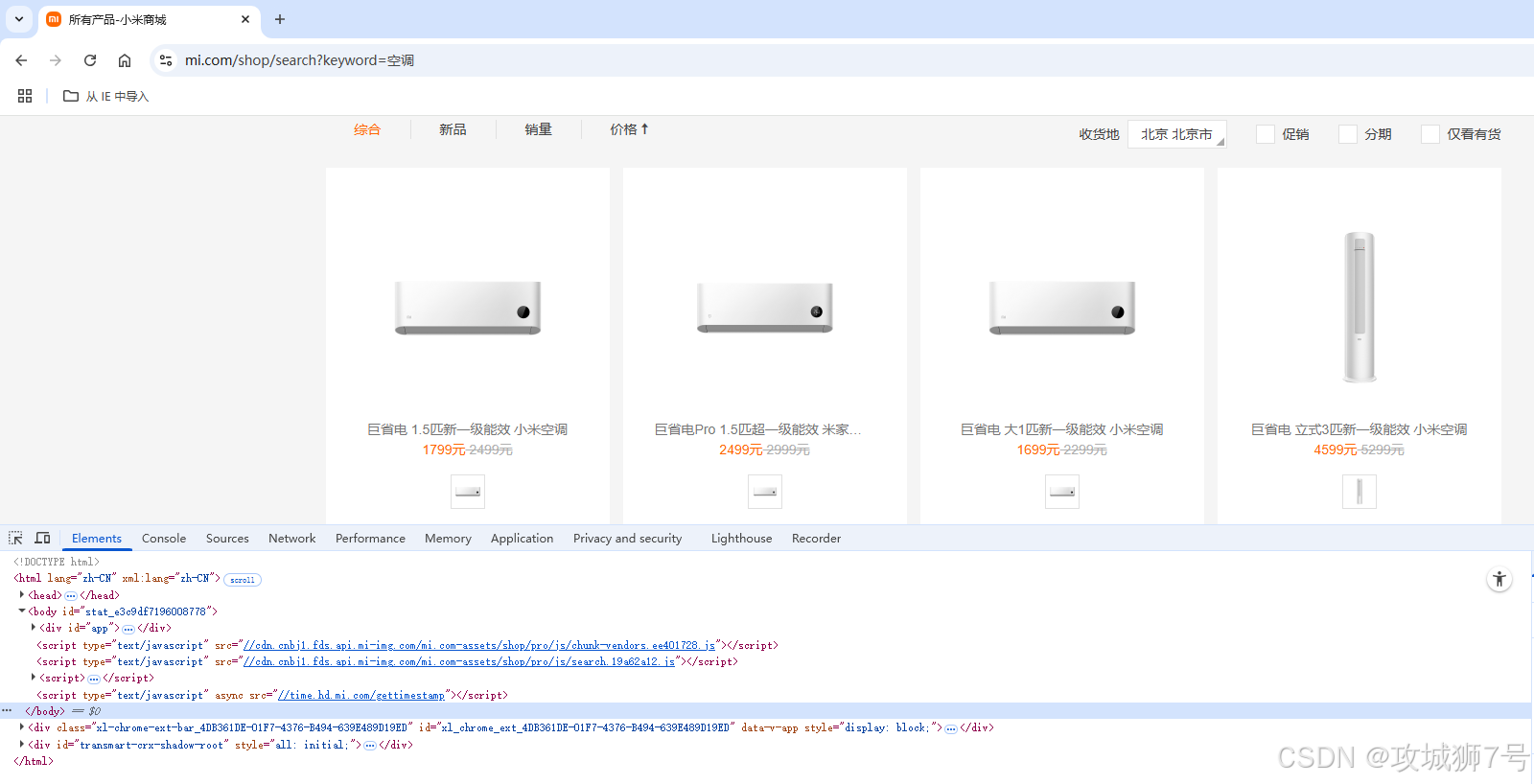
以( https://www.mi.com/shop/search?keyword=空調 ) 為例,打開開發者工具,分析商品列表和分頁結構。
 ?
?
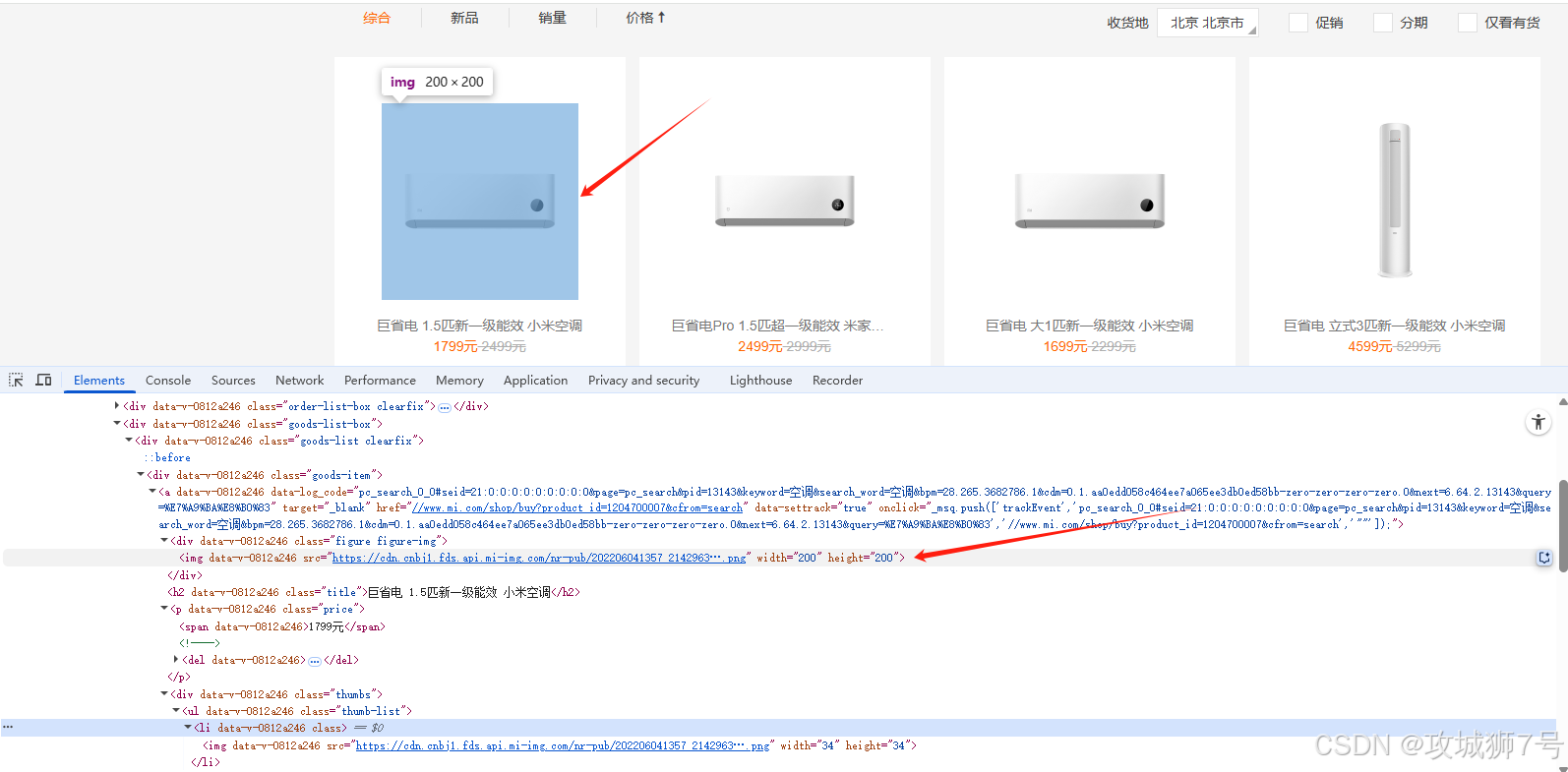
3.1 商品列表結構
????????點擊網頁元素,按鼠標右鍵的檢查項,快速定位
 ?
?
商品列表在如下結構下:
<ul class="goods-list"><li><a href="商品詳情鏈接"><img src="圖片鏈接" ...><div class="title">商品名稱</div><div class="price">價格</div>...</a></li>...</ul>??????? 實際頁面可能有多種 class,如 `.goods-list li`、`.product-list li`、`.goods-item` 等。需根據實際頁面調整選擇器。
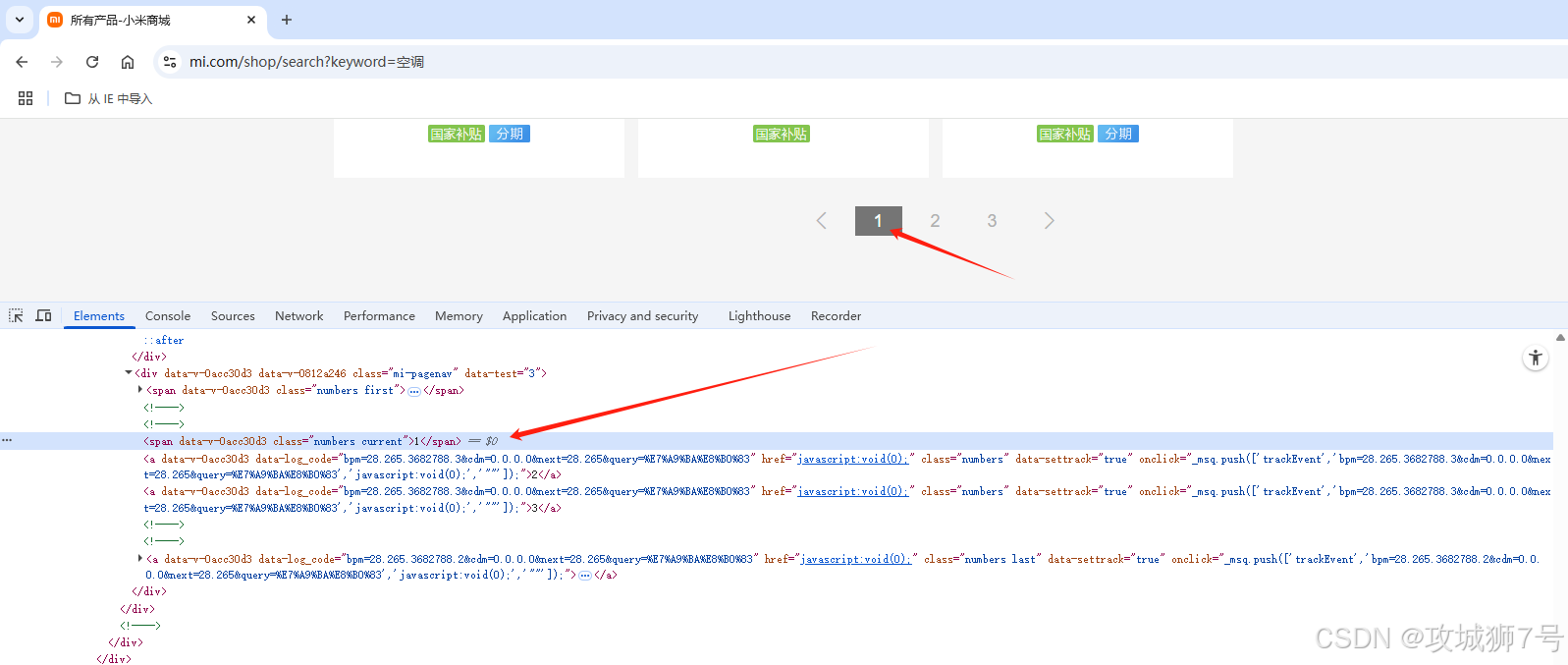
3.2 分頁結構
????????同樣點擊網頁分頁標簽元素,按鼠標右鍵的檢查項,快速定位分析
 ?
?
分頁欄如下:
<div class="mi-pagenav"><span class="numbers current">1</span><a class="numbers">2</a><a class="numbers">3</a>...</div>- 當前頁為 `<span class="numbers current">1</span>`
- 其它頁為 `<a class="numbers">2</a>`
- 需用 Selenium 模擬點擊 `<a class="numbers">2</a>` 實現翻頁
四、Selenium 自動化爬蟲實現
4.1 腳本整體結構
核心流程:
1. 啟動 Selenium,打開小米商城空調搜索頁
2. 解析當前頁商品數據
3. 模擬點擊分頁按鈕,依次抓取多頁
4. 解析每頁數據并輸出
5. 關閉瀏覽器
4.2 代碼實現
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.chrome.options import Optionsfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom pyquery import PyQuery as pqimport timeKEYWORD = '空調'MAX_PAGE = 3chrome_options = Options()# chrome_options.add_argument('--headless') # 如需無頭模式可取消注釋chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_experimental_option("detach", True)service = Service()browser = webdriver.Chrome(service=service, options=chrome_options)wait = WebDriverWait(browser, 20)def get_products(page):html = browser.page_sourcedoc = pq(html)products = []for item in doc('.goods-list li, .product-list li, .list li, .goods-item, .product-item').items():title = item.find('.title, .name, .pro-title, .text').text()price = item.find('.price, .pro-price, .num').text()img = item.find('img').attr('src') or item.find('img').attr('data-src')link = item.find('a').attr('href')if title and ('空調' in title or '空調' in item.text()):products.append({'title': title,'price': price,'img': img,'link': link})if not products:for a in doc('a').items():text = a.text()if '空調' in text:img = a.find('img').attr('src') or a.find('img').attr('data-src')price = ''parent = a.parent()for p in parent.parents():price = p.find('.price, .pro-price, .num').text()if price:breakproducts.append({'title': text,'price': price,'img': img,'link': a.attr('href')})print(f'第{page}頁空調商品:')for p in products:print(p)return productsdef main():browser.get(f'https://www.mi.com/shop/search?keyword={KEYWORD}')for page in range(1, MAX_PAGE + 1):wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'body')))time.sleep(2)get_products(page)if page < MAX_PAGE:try:page_btn = browser.find_element(By.XPATH, f'//div[contains(@class,"mi-pagenav")]//a[@class="numbers" and text()="{page+1}"]')browser.execute_script("arguments[0].click();", page_btn)time.sleep(2)except Exception as e:print(f'點擊第{page+1}頁失敗:', e)breakbrowser.quit()if __name__ == '__main__':main()運行爬取截圖:
 ?
?
五、關鍵技術詳解
5.1 Selenium 啟動與配置
- 推薦用 Chrome 瀏覽器,需保證 ChromeDriver 版本匹配
- 可選用 Headless 模式,適合服務器環境
- `detach` 選項可讓瀏覽器調試時不自動關閉
5.2 頁面等待與異步加載
- 小米商城商品列表為異步渲染,需用 WebDriverWait 等待元素加載
- `time.sleep()` 可適當延遲,確保頁面渲染完成
5.3 商品數據解析
- 用 PyQuery 解析 HTML,支持 jQuery 風格選擇器
- 兼容多種商品卡片結構,適應頁面變動
- 兜底方案:遍歷所有 a 標簽,抓取帶"空調"字樣的商品
5.4 分頁處理
- 不能直接拼接 URL 翻頁,需模擬點擊分頁按鈕
- 用 XPath 精確定位 `<a class="numbers">`,并用 JS 執行點擊,兼容前端事件綁定
- 每次翻頁后需等待頁面刷新再抓取數據
5.5 異常處理
- 分頁點擊失敗時自動中斷,避免死循環
- 可根據實際需求增加重試機制
5.6 可選:保存到 MongoDB
如需將數據保存到 MongoDB,可參考如下代碼:
import pymongoMONGO_URL = 'localhost'MONGO_DB = 'xiaomi'MONGO_COLLECTION = 'ac_products'client = pymongo.MongoClient(MONGO_URL)db = client[MONGO_DB]def save_to_mongo(result):try:if db[MONGO_COLLECTION].insert_one(result):print('存儲到 MongoDB 成功')except Exception:print('存儲到 MongoDB 失敗')在 `get_products` 中調用 `save_to_mongo(product)` 即可。
六、Headless 模式與瀏覽器兼容
- Headless 模式適合服務器、云主機等無桌面環境
- 啟用方式:
chrome_options.add_argument('--headless')- 也可用 Firefox、Edge 等瀏覽器,Selenium 語法基本一致
七、常見問題與優化建議
7.1 反爬機制
- 有些網站如頻繁訪問可能彈出驗證碼
- 有些網站需要登錄才能進行下一步數據獲取,如果有登錄步驟,就需要自己通過Selenium自行實現
- 建議適當延遲、降低抓取頻率
- 可用代理池、賬號池等方式進一步優化
7.2 頁面結構變動
- 商品卡片 class 可能變動,需定期檢查并調整選擇器
- 建議用多種選擇器兜底,提升健壯性
7.3 數據完整性
- 某些商品可能缺少價格、圖片等字段,需容錯處理
- 可用 try/except 或默認值兜底
7.4 性能優化
- Headless 模式+禁用圖片加載可提升速度
- 可用多進程/多線程并發抓取不同關鍵詞
八、總結
????????本文系統講解了如何用 Selenium 自動化爬取小米商城空調商品信息,涵蓋了環境準備、頁面結構分析、自動化腳本實現、數據解析、翻頁處理、異常處理、可選的 MongoDB 存儲、Headless 模式、常見問題與優化建議等內容。通過這種"可見即可爬"的方式,可以高效應對前端動態渲染和復雜 Ajax 的電商頁面,極大提升數據采集的靈活性和穩定性。
????????你可以根據實際需求,擴展腳本支持更多商品類型、更多字段、并發抓取、數據存儲等功能,打造屬于自己的電商數據采集工具。
看到這里了還不給博主點一個:
?? 點贊??收藏 ?? 關注!
💛 💙 💜 ?? 💚💓 💗 💕 💞 💘 💖
再次感謝大家的支持!
你們的點贊就是博主更新最大的動力!




)
)


:六個默認構造函數(一))
數據結構的基礎概念、線性表)








)
