在使用神經網絡處理自然語言處理任務時,我們首先需要對數據進行預處理,將數據從字符串轉換為神經網絡可以接受的格式,一般會分為如下幾步:
| - Step1 分詞:使用分詞器對文本數據進行分詞(字、字詞); - Step2 構建詞典:根據數據集分詞的結果,構建詞典映射(這一步并不絕對,如果采用預訓練詞向量,詞典映 射要根據詞向量文件進行處理); - Step3 數據轉換:根據構建好的詞典,將分詞處理后的數據做映射,將文本序列轉換為數字序列; - Step4 數據填充與截斷:在以batch輸入到模型的方式中,需要對過短的數據進行填充,過長的數據進行截斷, 保證數據長度符合模型能接受的范圍,同時batch內的數據維度大小一致。 |
在transformers工具包中,只需要借助Tokenizer模塊便可以快速的實現上述全部工作,它的功能就是將文本轉換為神經網絡可以處理的數據。Tokenizer工具包無需額外安裝,會隨著transformers一起安裝。
1 Tokenizer 基本使用(對單條數據進行處理)
Tokenizer 基本使用:
(1) 加載保存(from_pretrained / save_pretrained)
(2) 句子分詞(tokenize)
(3) 查看詞典 (vocab)
(4) 索引轉換(convert_tokens_to_ids / convert_ids_to_tokens)
(5) 填充截斷(padding / truncation)
(6) 其他輸入(attention_mask / token_type_ids)
不同的模型會對應不同的tokenizer。transformers中需要導入AutoTokenizer,AutoTokenizer會根據不同的模型導入對應的tokenizer
1.1. Tokenizer的加載與保存
from transformers import AutoTokenizer
# 從HuggingFace加載,輸入模型名稱,即可加載對于的分詞器
tokenizer = AutoTokenizer.from_pretrained("../models/roberta-base-finetuned-dianping-chinese")
tokenizer打印結果如下:
BertTokenizerFast(name_or_path='/root/autodl-fs/models/roberta-base-finetuned-dianping-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right',
special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
將tokenizer 保存到本地后可以直接從本地加載
# tokenizer 保存到本地
tokenizer.save_pretrained("./roberta_tokenizer")
# 從本地加載tokenizer
tokenizer = AutoTokenizer.from_pretrained("./roberta_tokenizer/")
1.2. 句子分詞
sen = "弱小的我也有大夢想!"
tokens = tokenizer.tokenize(sen)
#['弱', '小', '的', '我', '也', '有', '大', '夢', '想', '!']
1.3. 查看字典
tokenizer.vocab
tokenizer.vocab_size #21128
{'##椪': 16551,'##瀅': 17157,'##蝕': 19128,'##魅': 20848,'##隱': 20460,'儆': 1024,'嫣': 2073,'簧': 5082,'鎂': 7250,'maggie': 12423,'768': 12472,'1921': 10033,'焜': 4191,'瀆': 3932,'鎂': 7110,'謚': 6471,'app': 8172,'噱': 1694,'goo': 9271,'345': 11434,'##rin': 13250,'?': 324,'redis': 12599,'/': 8027,'蒞': 5797,
...'##轟': 19821,'387': 12716,'##齣': 21031,'##ント': 10002,...}
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
1.4. 索引轉換
# 將詞序列轉換為id序列
ids = tokenizer.convert_tokens_to_ids(tokens)
#[2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106]# 將id序列轉換為token序列
tokens = tokenizer.convert_ids_to_tokens(ids)
#['弱', '小', '的', '我', '也', '有', '大', '夢', '想', '!']# 將token序列轉換為string
str_sen = tokenizer.convert_tokens_to_string(tokens)
#'弱 小 的 我 也 有 大 夢 想!'
上面的把各個步驟都分開了,簡潔的方法:
# 將字符串轉換為id序列,又稱之為編碼
ids = tokenizer.encode(sen, add_special_tokens=True)
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102]# 將id序列轉換為字符串,又稱之為解碼
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
# '[CLS] 弱 小 的 我 也 有 大 夢 想! [SEP]'
下面的方法比上面多了兩個special_tokens:[CLS]和[SEP],這是特定tokenizer給定的,句子開頭和句子結尾
1.5. 填充與截斷
以上是針對單條數據,如果是針對多條數據會涉及到填充和截斷。把短的數據補齊,長的數據截斷。
# 填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
# [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0]
# 截斷
ids = tokenizer.encode(sen, max_length=5, truncation=True)
# [101, 2483, 2207, 4638, 102]
填充和階段的長度包含了兩個special_tokens:[CLS]和[SEP]
1.6. 其他輸入部分
數據處理里面還有一個地方要特別注意:既然數據中存在著填充,就要告訴模型,哪些是填充,哪些是有效的數據。這個時候需要attention_mask。也就是說,對于上面的例子,ids為0的元素對應的attention_mask的元素應為0,不為0的元素位置attention_mask的元素應為0。
另外香BERT這樣的模型需要token_type_ids標定是第幾個句子。
1.6.1 手動生成方式(體現定義)
如果是手動設定attention_mask和token_type_ids如下:
attention_mask = [1 if idx != 0 else 0 for idx in ids]
token_type_ids = [0] * len(ids)
#ids: ([101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
#attention_mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
#token_type_ids: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
1.6.2 快速調用方式
transformers肯定不會讓手動生成,有自動的方法。就是encode_plus
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=15)
使用encode_plus生成的是一個字典如下:
{
'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
}‘input_ids’:分此后轉換的id
‘token_type_ids’:屬于第幾個句子
‘attention_mask’:1對應的’input_ids’元素是非填充元素,是真實有效的
調用encode_plus方法名字太長了,不好記,等效的方法就是可以直接用 tokenizer而不使用任何方法。
inputs = tokenizer(sen, padding="max_length", max_length=15)
得到和上面一樣的結果:
{
'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]
}
2 處理batch數據
上面是處理單條數據,現在看看怎么處理batch數據
sens = ["弱小的我也有大夢想","有夢想誰都了不起","追逐夢想的心,比夢想本身,更可貴"]
res = tokenizer(sens)
#{'input_ids': [[101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 102], [101, 3300, 3457, 2682, 6443, 6963, 749, 679, 6629, 102], [101, 6841, 6852, 3457, 2682, 4638, 2552, 8024, 3683, 3457, 2682, 3315, 6716, 8024, 3291, 1377, 6586, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
sens是個列表有3個句子,得到的res是一個字典,包含:‘input_ids’;‘token_type_ids’;‘attention_mask’,每個都是一個列表,列表的每個元素對應每個句子’input_ids’;‘token_type_ids’;‘attention_mask’
以batch的方式去處理比一個一個的處理速度更快。
3 Fast/Slow Tokenizer
Tokenizer有快的版本和慢的版本
3.1 FastTokenizer
- 基于Rust實現,速度快
- offsets_mapping、 word_ids SlowTokenizer
sen = "弱小的我也有大Dreaming!"
fast_tokenizer = AutoTokenizer.from_pretrained(model_path)

FastTokenizer會有一些特殊的返回。比如return_offsets_mapping,用來指示每個token對應到原文的起始位置。
inputs = fast_tokenizer(sen, return_offsets_mapping=True)
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 10252, 8221, 106, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], # "弱小的我也有大Dreaming!"
# Dreaming被分為兩個詞(7, 12), (12, 15)
# 該字段中保存著每個token對應到原文中的起始與結束位置
'offset_mapping': [(0, 0), (0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 6), (6, 7), (7, 12), (12, 15), (15, 16), (0, 0)]
}
# word_ids方法,該方法會返回分詞后token序列對應原始實際詞的索引,特殊標記的值為None。
# Dreaming被分為兩個詞【7, 7】
inputs.word_ids()
# [None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
3.2 SlowTokenizer
- 基于Python實現,速度慢
slow_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
 兩種方式的時間對比如下:
兩種方式的時間對比如下:
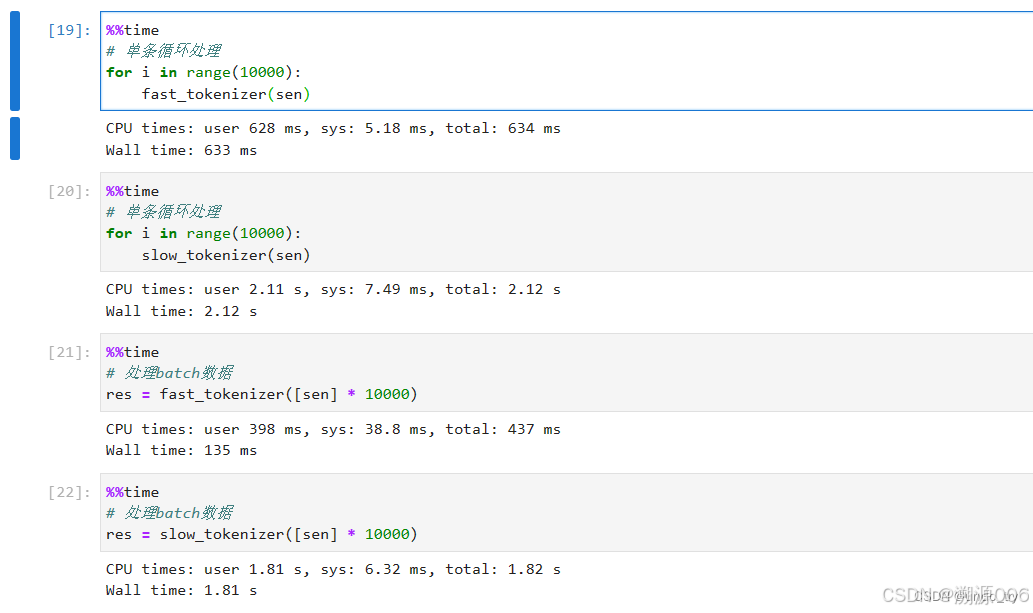
4 特殊Tokenizer的加載
一些非官方實現的模型,自己實現了tokenizer,如果想用他們自己實現的tokenizer,需要指定trust_remote_code=True。
from transformers import AutoTokenizer# 需要設置trust_remote_code=True
# 表示信任遠程代碼
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
tokenizer
即使保存到本地,然后從本地加載也要設置trust_remote_code=True
tokenizer.save_pretrained("chatglm_tokenizer")# 需要設置trust_remote_code=True
tokenizer = AutoTokenizer.from_pretrained("chatglm_tokenizer", trust_remote_code=True)
參考鏈接:【手把手帶你實戰HuggingFace Transformers-入門篇】基礎組件之Tokenizer_嗶哩嗶哩_bilibili
Transformers基本組件(一)快速入門Pipeline、Tokenizer、Model_transformers.pipeline-CSDN博客

橋梁模式)




:類型限定符)



—指針3)




)



