《深入理解Linux網絡》筆記
- 前言
- 參考
前言
前段時間看了《深入理解Linux網絡》這本書,雖然有些地方有以代碼充篇幅的嫌疑,但總體來說還是值得一看的。在這里簡單記錄一下筆記,記錄下對網絡新的理解。
- 內核是如果接受網絡包的?
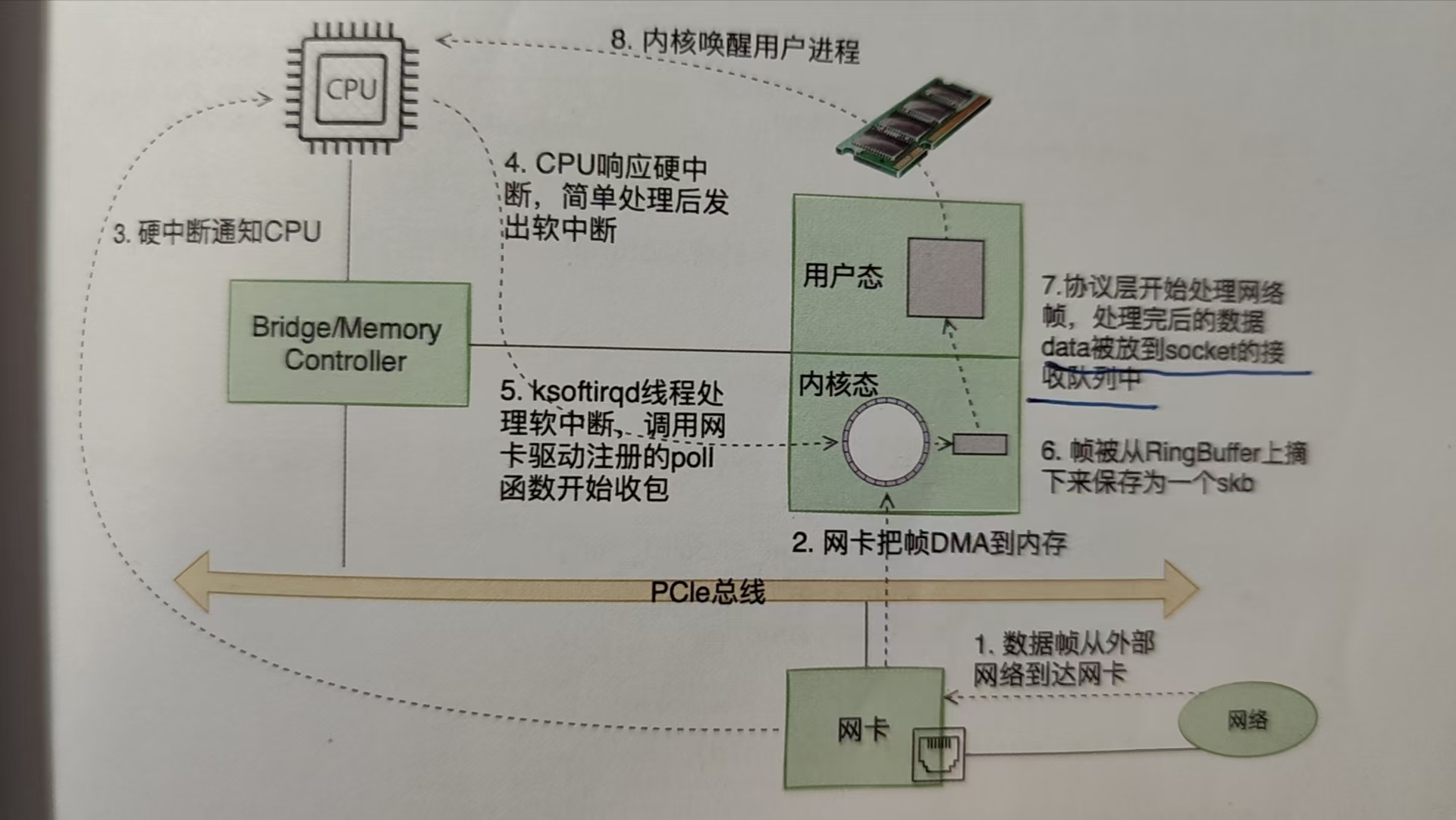
如上圖所示,整個流程基本如下:- 數據包首先從網絡中到達主機中的網卡設備
- 網卡通過DMA把數據幀運到內存中
- 之后網卡通過觸發硬終端(觸發電平變化)來通知CPU有網絡包到達
- CPU收到硬中斷之后,會調用網絡設備注冊的中斷處理函數。在這個函數中響應中斷進行簡單的處理,燃弧發出軟中斷(linux中整個中斷過程分為上半部(硬中斷)和下半部(軟中斷))。
- 內核線程(ksoftirqd線程, 內核啟動的時候會專門創建一些軟中斷內核線程,一般來說,機器上有幾個核心就會有幾個ksoftirqd內核線程)響應軟中斷,調用網卡驅動注冊的poll函數開始收包。從RingBuffer中(就是之前DMA運輸的地方)摘取一個幀,然后交給上層的協議棧進行具體的處理。
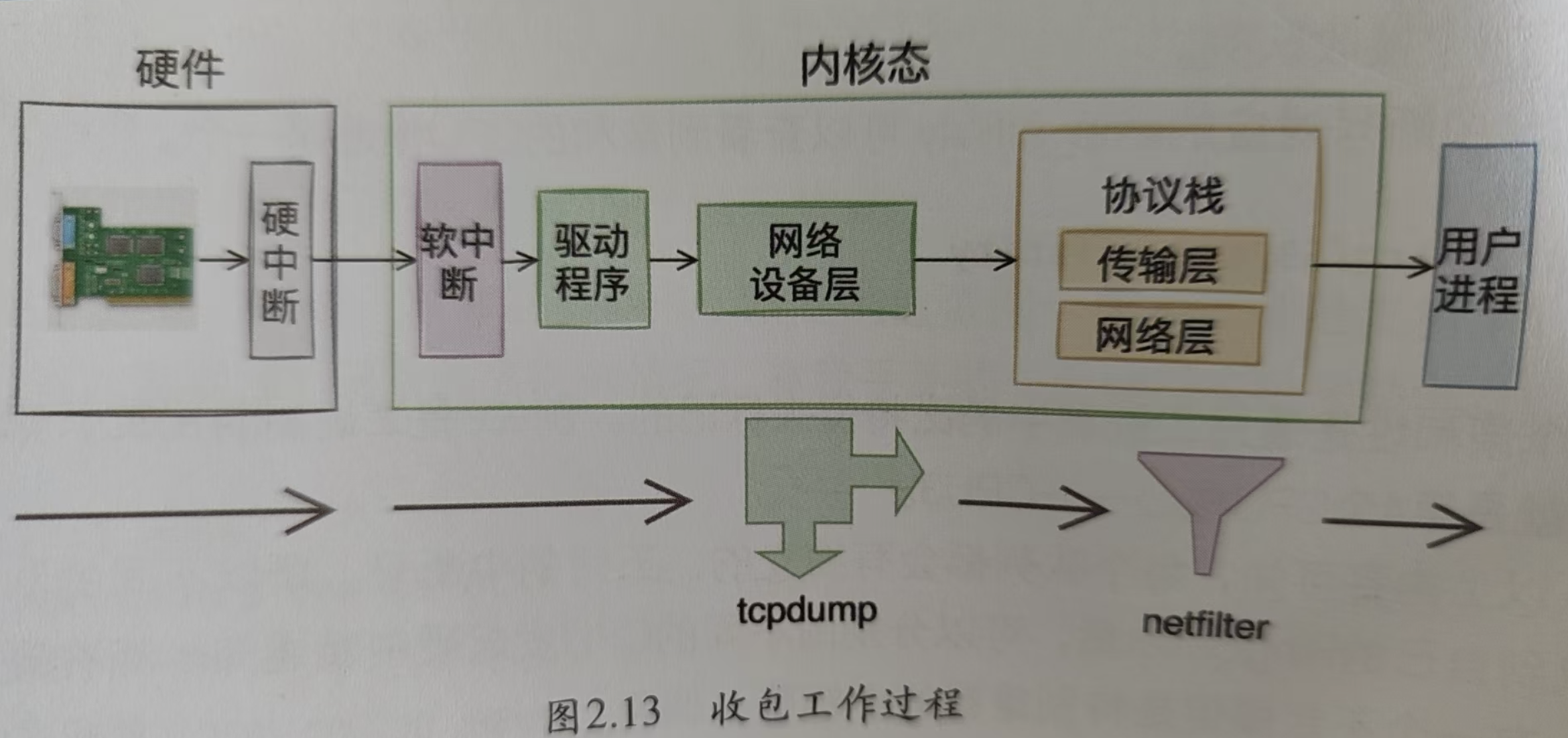
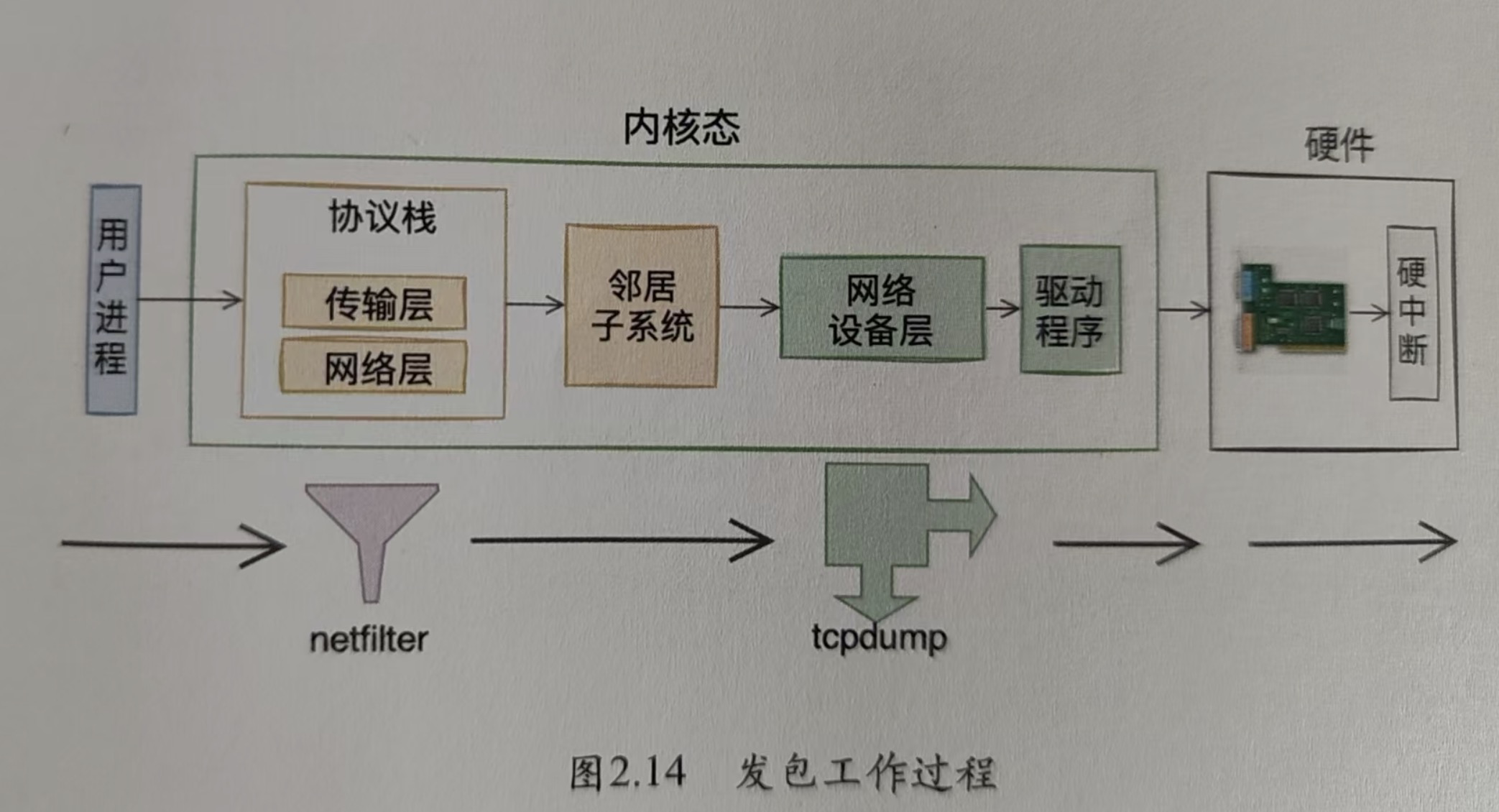
- tcpdump抓包和iptable過濾包的原理大概是什么?
tcpdump是一個常用的抓包工具,其原理概括來說就是通過類似一個回調的機制,將其掛到網絡包傳輸的路徑中。當有網絡包到來(或者發送出去)的時候內核會調用將數據包傳給tcpdump的回調函數,就可以達到抓包的效果。
?
iptable其實本質上也一樣,只不過iptable會對經過的包進行過濾、修改。而tcpdump一般只是查看。
有一點不一樣的是,tcpdump是工作在設備層的(所以tcpdump還可以查看數據鏈路層的一些包信息),而iptable是工作在IP層(ARP層)的。
如下圖所示。
ps: netfilter可以理解就是 iptable。
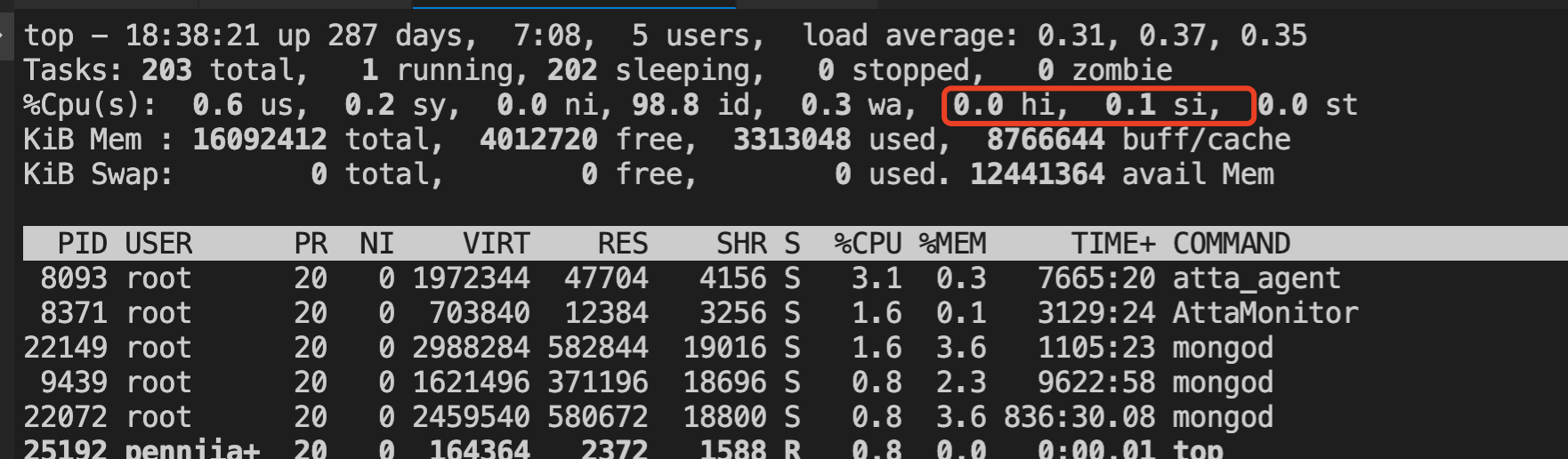
- top命令中hi,si代表啥意思?
如果了解了linux的中斷原理,也就對top命令中hi,si有了更深的理解。hi代表硬中斷的開銷,si代表軟中斷的開銷。
- 關于系統調用陷入內核態的一些理解
對于一個程序來說,通過系統調用(比如說write數據到網絡中)陷入內核態之后,還依舊執行的是這個程序的活 (系統還依舊算著這個進程的cpu運行時間),只不過是陷入到了內核態,算是這個程序的內核態線程(并不是新建了一個內核態線程)在執行。這也就是所謂的進程的內核上下文。
- 如果使用的是普通的同步阻塞網絡讀寫調用,一般來說,會進行至少兩次進程的上下文切換(一個是無數據到達時阻塞、另一個是數據到達時喚醒)。一般來說,每一次進程的上下文切換都需要花費3-5微秒的時間,以CPU視角來說,這其實已經不少了,而且上下文的切換并沒有干什么實質性的活,所以,很多機制都盡量減少不必要的上下文切換(比如說自旋鎖、 epoll等機制。)
- epoll、poll等多路復用機制高效在什么地方?
在我看來,多路復用機制高效的本質在于可以同時監聽多個套接字,這樣就一旦其中有需要讀寫的事件到來,就可以盡量減少進程的上下文切換(不像同步操作read、write那樣進行頻繁的阻塞),讓進程更專注的處理網絡請求。
?
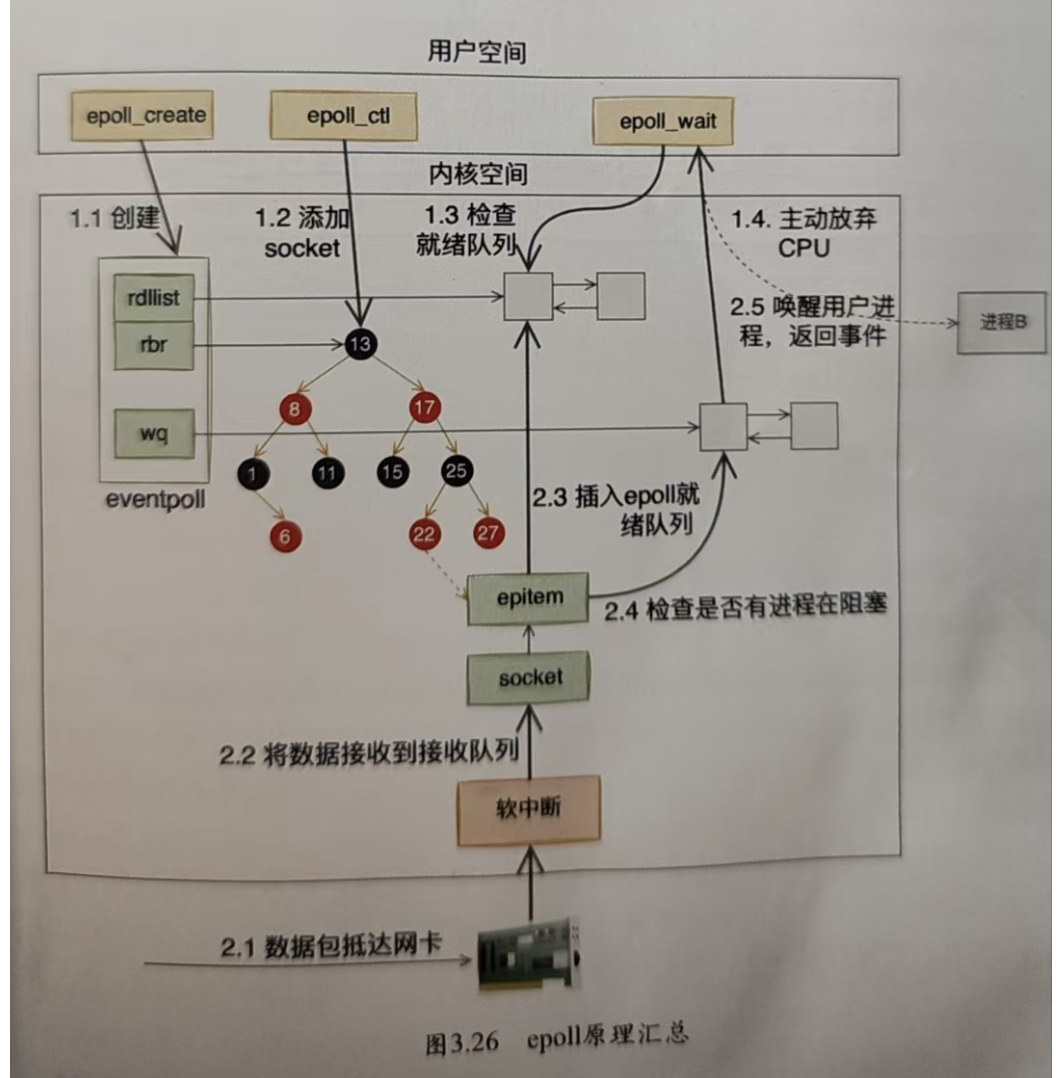
整個epoll機制基本如下圖所示。
通過epoll_ctl加入需要監聽的多個套接字。當某一個套接字對應的網絡包從網卡到來之時,通過內核的軟硬件中斷進行處理,然后將請求放入epoll對象的就緒列表中。
?
而epoll_wait就是從就緒列表中看是否有事件到達,如果有則取出進行處理。 在高并發的場景中,epoll_wait會一直處理,知道沒活的時候才會讓出CPU.
?
而紅黑樹只是epoll中用來快速查找、刪除socket時用的數據結構,并不是epoll支持高并發的根本原因。
- 關于tcp分段和ip分片的一些理解
對于一般的tcp傳輸來說,下層的mac協議限制的幀的大小,MTU一般是1500字節。如果超過了MTU,mac層將無法傳輸(應該會丟棄)。對應MTU,ip層也有響應的長度限制MSS,如果超過了這個限制之后,ip層會執行分片,以避免mac層將數據丟棄。但是ip層的分片會導致一些問題:一個是額外的分片開銷;另一個是如果一個分片丟失了,上層的整個包都需要重傳(對于TCP來說整個包會重傳,對于UDP來說,數據包就是丟失了);
?
所以,tcp層為了減少ip分片,在tcp層就將數據包進行了分段,使裝入ip層數據不大于MSS,這樣,ip層就不會進行分片,也不會有一個分片丟失,整個數據包都得重傳的尷尬。
- 如果想通過網絡發送一個文件,會涉及到哪些內存拷貝呢?
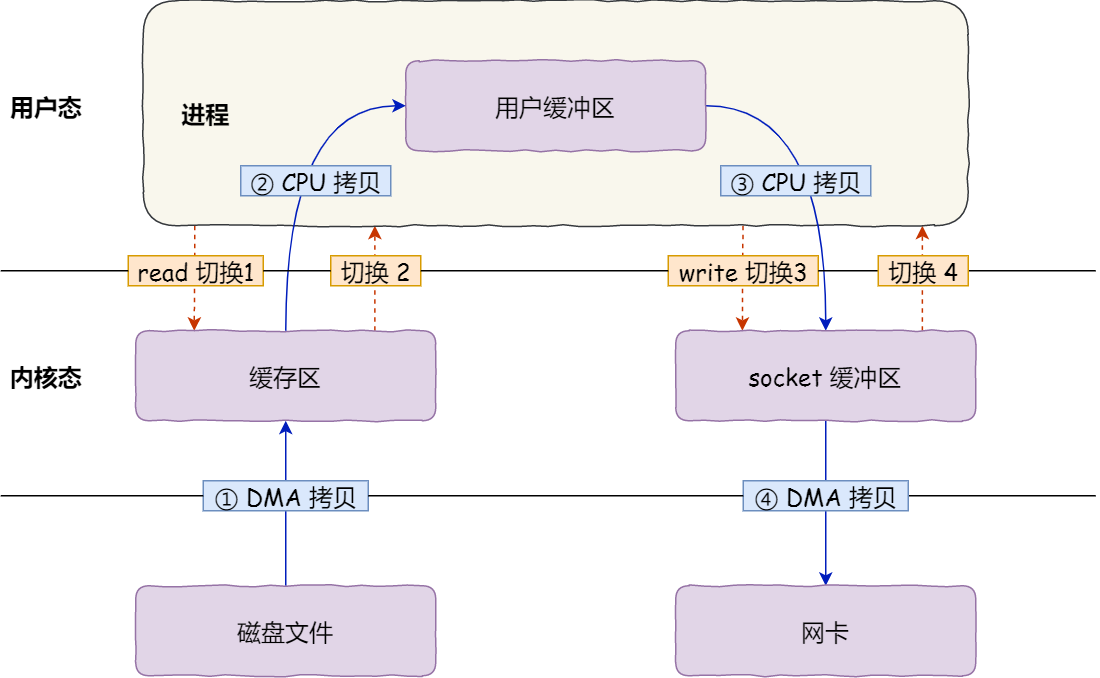
一般來說,我們想通過網絡發送一個本地的文件,會首先通過read()系統調用將文件讀到內存中,然后在write()到遠端。這其中涉及到磁盤-內核空間-用戶空間的內存拷貝過程。
如下圖所示。一共涉及到4次的用戶態和內核態的上下文切換和4次的內存拷貝。
仔細分析一下其實知道,如果不需要再用戶空間修改文件內容的話,完全不需要將數據拷貝到用戶空間。
所以,一般來說有幾種方式可以提高這種場景的內存效率。
- 通過 mmap + write
即通過linux提供的mmap內存映射,將內核緩沖區里的數據映射到用戶空間,這樣,操作系統內核與用戶空間就不需要再進行任何的數據拷貝操作。
這樣需要4次的用戶態和內核態的上下文切換,和3次的內存拷貝。
- 使用sendfile系統調用
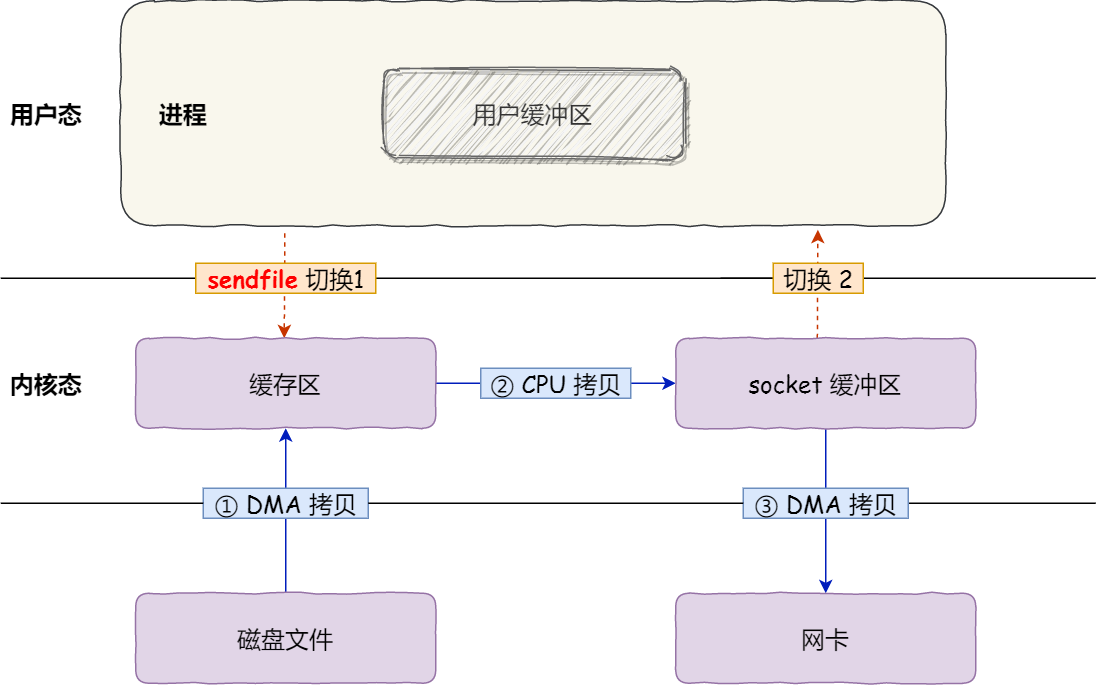
在 Linux 內核版本 2.1 中,提供了一個專門發送文件的系統調用函數 sendfile()。該系統調用,可以直接把內核緩沖區里的數據拷貝到 socket 緩沖區里,不再拷貝到用戶態,這樣就只有 2 次上下文切換,和 3 次數據拷貝。
sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
而且從 Linux 內核 2.4 版本開始起, 對于支持 SG-DMA 技術的網卡,sendfile還可以進一步減少cpu的干預,直接從內存緩存中拷貝到網卡,如下圖所示。
算是真正做到了零拷貝。
kafka之所以性能突出,一個重要的原因就是利用了這種零拷貝技術。
- 關于linux路由表
linux默認情況下會丟掉不屬于本機IP的數據包。將net.ipv4.ip_forward設置為1后,會開啟路由功能,Linux會像路由器一樣對不屬于本機的IP數據包進行路由轉發。
?
linux可以配置多個路由表,默認有三個已有的路由表:
> 1. local: 處理本地IP和廣播地址路由,local路由表只由kernel維護,不能更改和刪除
2. main: 處理所有非策略路由,不指定路由表名時默認使用的路由表
3. default: 所有其他路由表都沒有匹配到的情況下,根據該表中的條目進行處理
- 關于本機網絡
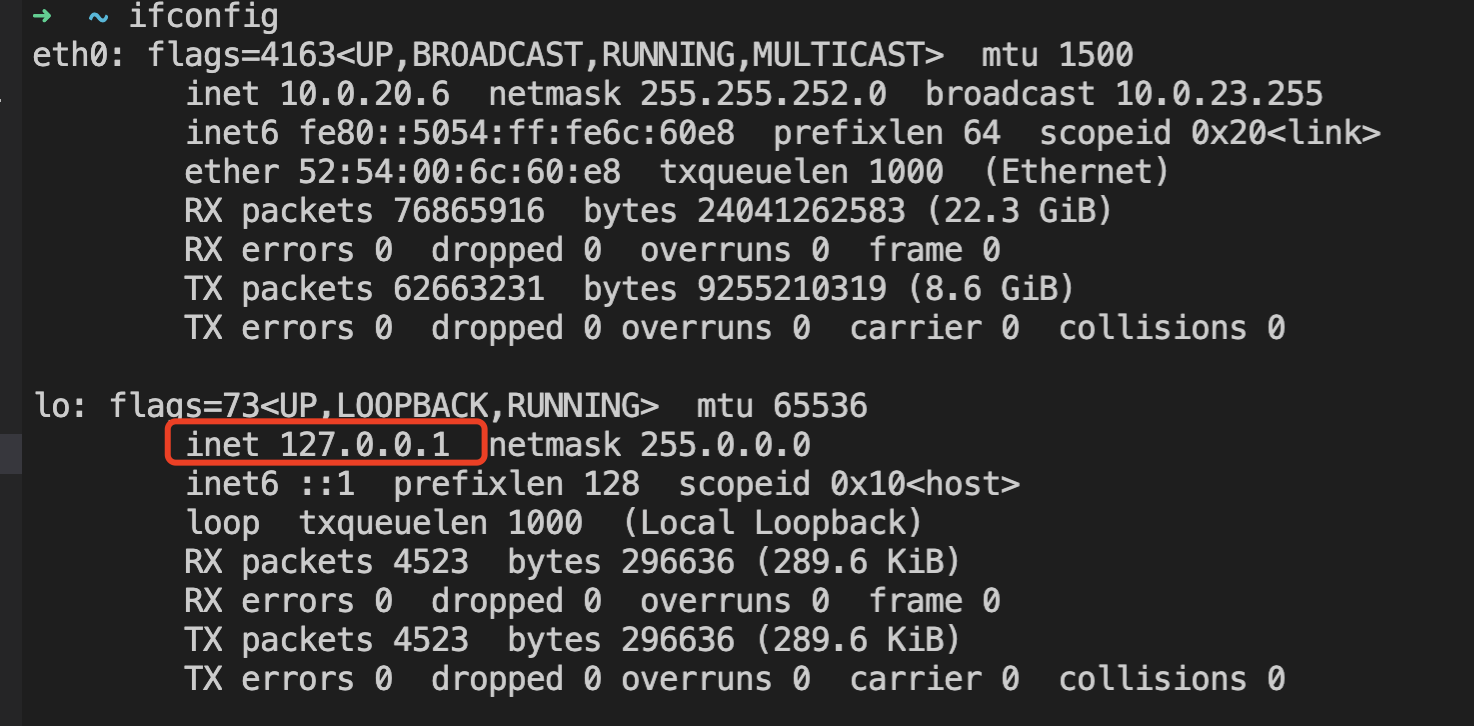
我們使用ifconfig可以看到一個lo的回環設備,這是內核虛擬出來的一個本機網卡設備,所有127.0.0.1的網絡IO都直接通過這個lo進行傳輸,不需要經過實際的網絡設備,所以即使拔了網線,也依然可以對127.0.0.1的網絡IO進行請求。
?
除了127.0.0.1之外,本機ip(如上圖中的10.0.20.6)也是一樣的,使用本機ip也可以訪問本地服務,走的也是lo回環設備。
- listen系統調用本質上是在干啥?
對于我們熟知的網絡系統調用Listen來說,其一個重要的作用就是在內核中建立并初始化好半隊列(用來存儲經過第一次握手的socket)和全隊列(用來存儲已經建立連接的socket, accept 其實就是從這里消費tcp連接的)的數據接口,為接下來TCP的握手連接做好準備。
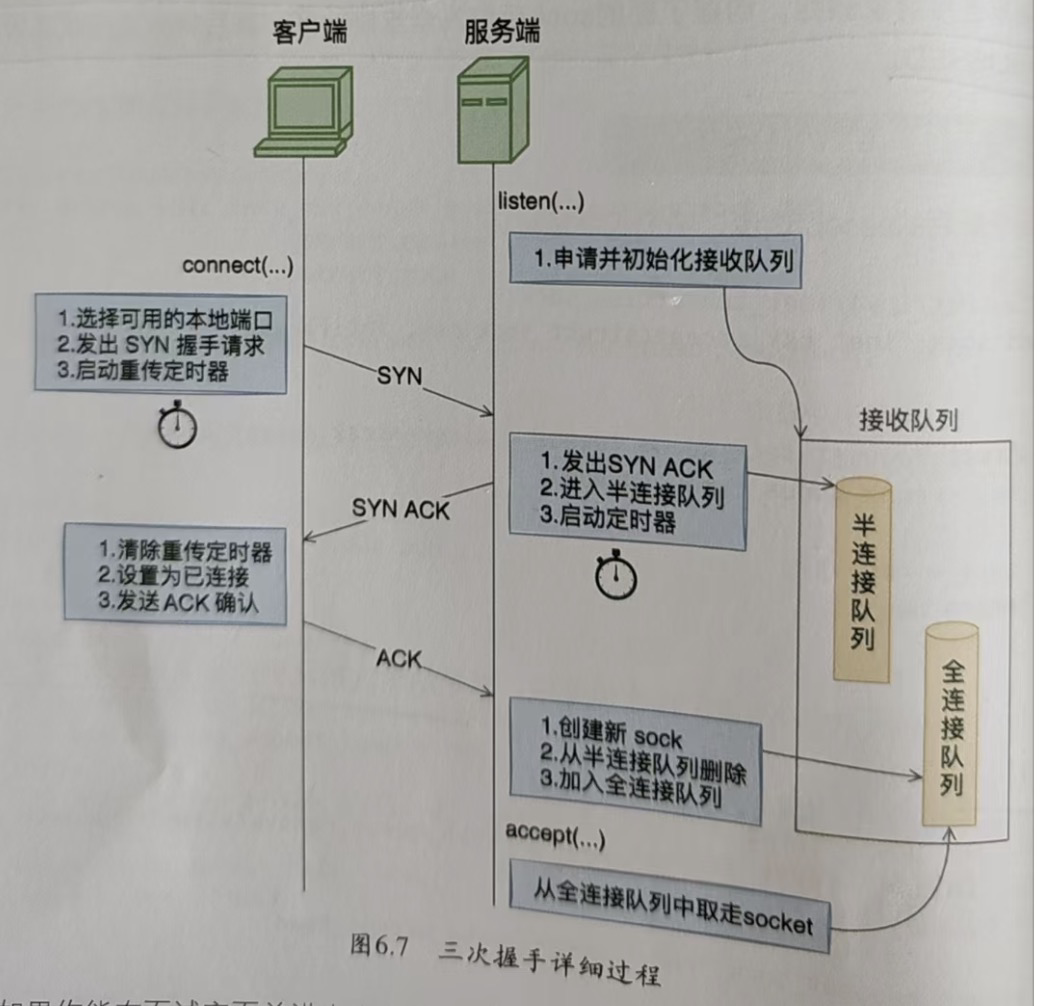
- 關于tcp的建立過程的一些細節
tcp通過三次握手來建立連接。 一般來說,
- 客戶端通過connect來建立連接,客戶端發送SYN 連接握手請求,然后啟動定時器。
- 服務端收到請求之后,內核會發出SYN ACK, 這個時候將請求放入半連接隊列。 同時也會啟動一個重傳定時器(所以如第二次握手發出之后,遲遲收不到第三次握手, 服務端會進行重傳第二次握手)。
- 然后客戶端收到SYN ACK之后,清除重傳定時器,將連接置為已連接,然后發送第三次握手ACK。
- 服務端收到第三次握手之后,將連接沖半連接隊列里刪除,然后加入全連接隊列。等待accept來消費連接。
整個過程如下圖所示。
一般來說,建立一個tcp連接需要1.5個RTT, 根據通信雙方的遠近一般需要幾十到幾百毫秒的樣子。 (一般來說,同地區的不同機房一般大約是幾ms,北京到廣東大概30-40ms)
- 一條空的tcpl連接(只建立連接但是不發送數據)大概需要3-4kb的內存空間。 一條TIME_WAIT狀態的連接需要消耗0.4kb的樣子。所以機器上如果TIME_WAIT過多一般影響的不是內存而是端口號。
- 一個機器可以建立多少個連接?
要理解,一條tcp連接是有(src ip, src port, dst ip, dsp port) 四元組來構成的,所以對于一個客戶端來說,說是根據16bit 的port 只能建立65536個連接,這是不正確的。 限制服務器端和客戶端連接的最主要的是內存和cpu,如果這些是充足的,一臺服務器建立百萬連接完全是可能的。
參考
【1】《深入理解Linux網絡》
【2】為什么 TCP/IP 協議會拆分數據
【3】Linux 內存拷貝

)



)
完全工作流解讀|計育韜)










使用教程第八講)

使用frp配置內網穿透,隨時隨地ssh到機器)