StreamRL:彈性、可擴展、異構的RLHF架構
大語言模型(LLMs)的強化學習(RL)訓練正處于快速發展階段,但現有架構存在諸多問題。本文介紹的StreamRL框架為解決這些難題而來,它通過獨特設計提升了訓練效率和資源利用率,在相關實驗中表現優異,想知道它是如何做到的嗎?快來一探究竟!
文章核心
論文標題:StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
來源:arXiv:2504.15930v1 [cs.LG] + https://arxiv.org/abs/2504.15930
PS: 整理了LLM、量化投資、機器學習方向的學習資料,關注同名公眾號 「 亞里隨筆」 即刻免費解鎖
研究背景
在大語言模型(LLMs)的發展進程中,強化學習(RL)已成為關鍵的訓練后技術,它有效提升了模型的推理能力,不少前沿模型如 OpenAI 的 o1、o3,Claude 3.7 Sonnet 以及 DeepSeek - R1 等均借助 RL 在多種任務中取得領先表現。
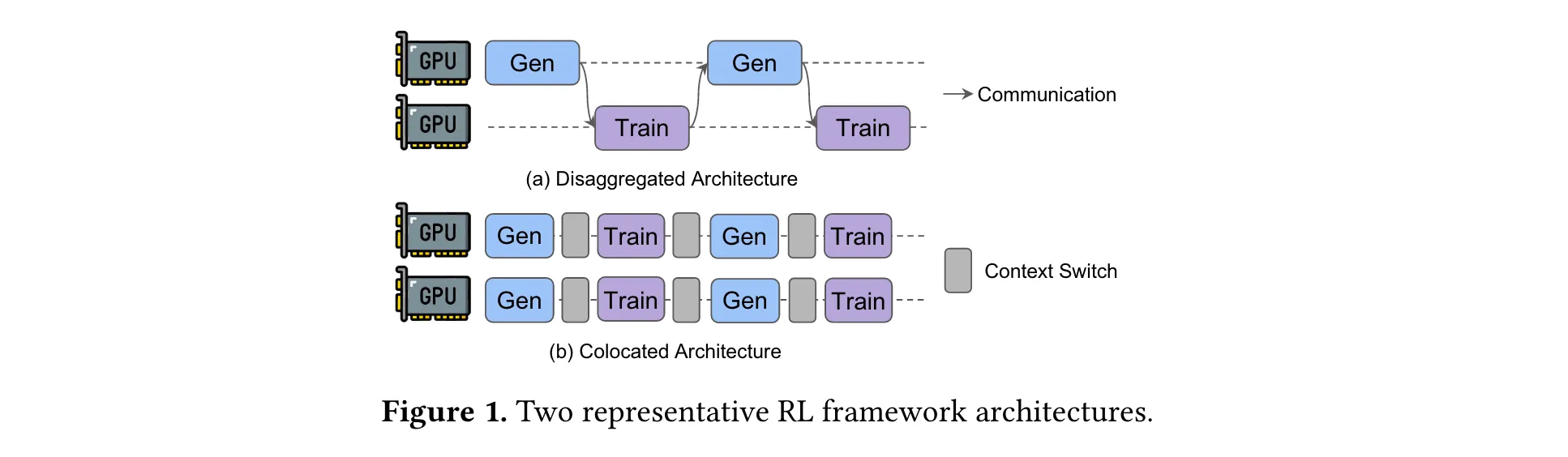
早期,RL 訓練框架多采用分離式架構,雖能復用現有基礎設施,但存在資源閑置問題。為解決此問題,共置架構應運而生,它通過時間復用 GPU 資源,提升了訓練效率,一度成為主流選擇。然而在實際大規模部署時,共置架構暴露出資源耦合的弊端。與此同時,分離式架構的優勢重新受到關注,但其在現有框架下存在流水線氣泡和偏態氣泡等挑戰,StreamRL 正是在這樣的背景下被提出,旨在解決上述問題,充分釋放分離式架構的潛力。
研究問題
-
傳統共置(colocated)架構存在資源耦合問題,生成階段和訓練階段因共享相同資源,無法根據各自特性靈活分配資源,導致資源利用率低,影響大規模訓練的可擴展性和成本效益。
-
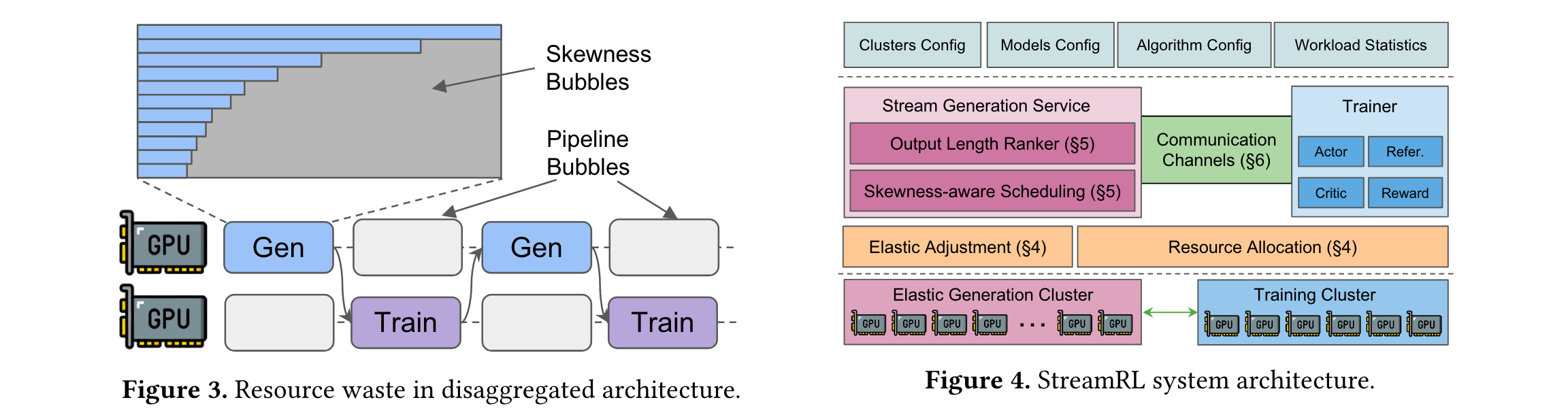
分離式(disaggregated)架構雖理論上有優勢,但存在流水線氣泡(pipeline bubbles)和偏態氣泡(skewness bubbles)問題。流水線氣泡源于兩階段串行執行,偏態氣泡則因LLM推理工作負載中長尾輸出長度分布,這兩種氣泡都會造成GPU資源閑置。
-
現有框架難以有效應對LLM推理工作負載固有的長尾輸出長度分布問題,處理不當會影響模型質量和訓練效率。
主要貢獻
1. 重新審視架構優勢:分析現有共置RL框架的關鍵問題,提出重新采用分離式架構進行RL訓練。該架構可實現靈活資源分配、支持異構硬件選擇以及跨數據中心訓練,克服了共置架構的局限性。
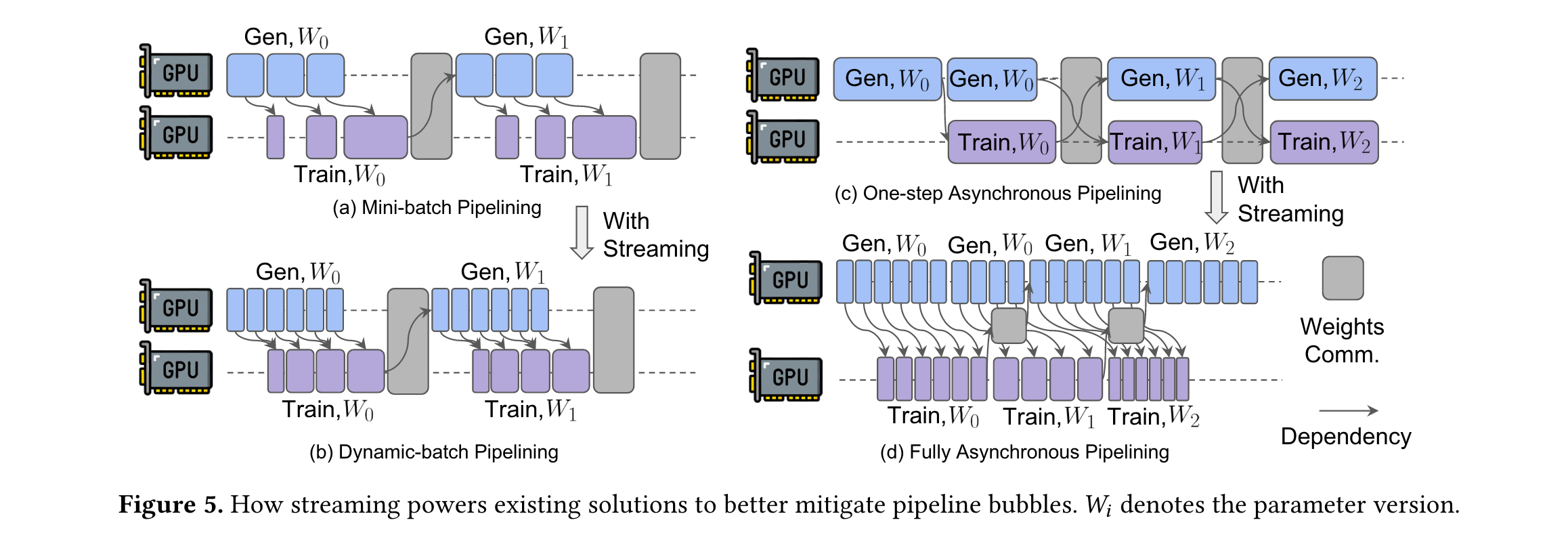
2. 提出StreamRL框架:設計StreamRL框架,通過解決流水線氣泡和長尾問題,充分釋放分離式架構的潛力。如采用動態批處理流水線(Dynamic-batch pipelining)和完全異步流水線(Fully asynchronous pipelining)解決流水線氣泡;利用輸出長度排序器模型(Output Length Ranker)和偏態感知調度(Skewness-aware scheduling)處理長尾問題。
3. 實驗驗證性能優越:通過在多種LLMs和真實數據集上實驗,證明StreamRL相比現有最先進系統,吞吐量最高提升2.66倍,在異構、跨數據中心設置下成本效益最高提升1.33倍,展現出良好的性能和可擴展性。
方法論精要
StreamRL是專為分離式架構設計的高效強化學習框架,其技術路線圍繞解決分離式架構存在的問題展開,主要包含以下關鍵步驟:
1. 核心框架設計:StreamRL將生成和訓練階段分別抽象為流生成服務(SGS)和訓練器(Trainer),二者部署在物理上分離的資源上,甚至可位于不同數據中心,通過點到點鏈路連接。這種設計能實現靈活的資源分配、異構硬件選擇和跨數據中心訓練。
2. 解決流水線氣泡問題:針對流水線氣泡,StreamRL在不同RL算法場景下采用不同策略。在同步RL中,提出動態批處理流水線,摒棄傳統的批量生成方式,樣本一完成就立即發送給訓練階段,訓練階段根據生成速度進行動態批處理,減少訓練階段空閑時間,消除大部分流水線氣泡。在異步RL中,采用完全異步流水線,使權重傳輸與訓練、生成過程并行,去除權重傳輸對關鍵路徑的影響,即便迭代間生成和訓練時間有波動,只要平均速度匹配且波動有限,就不會產生新的氣泡。
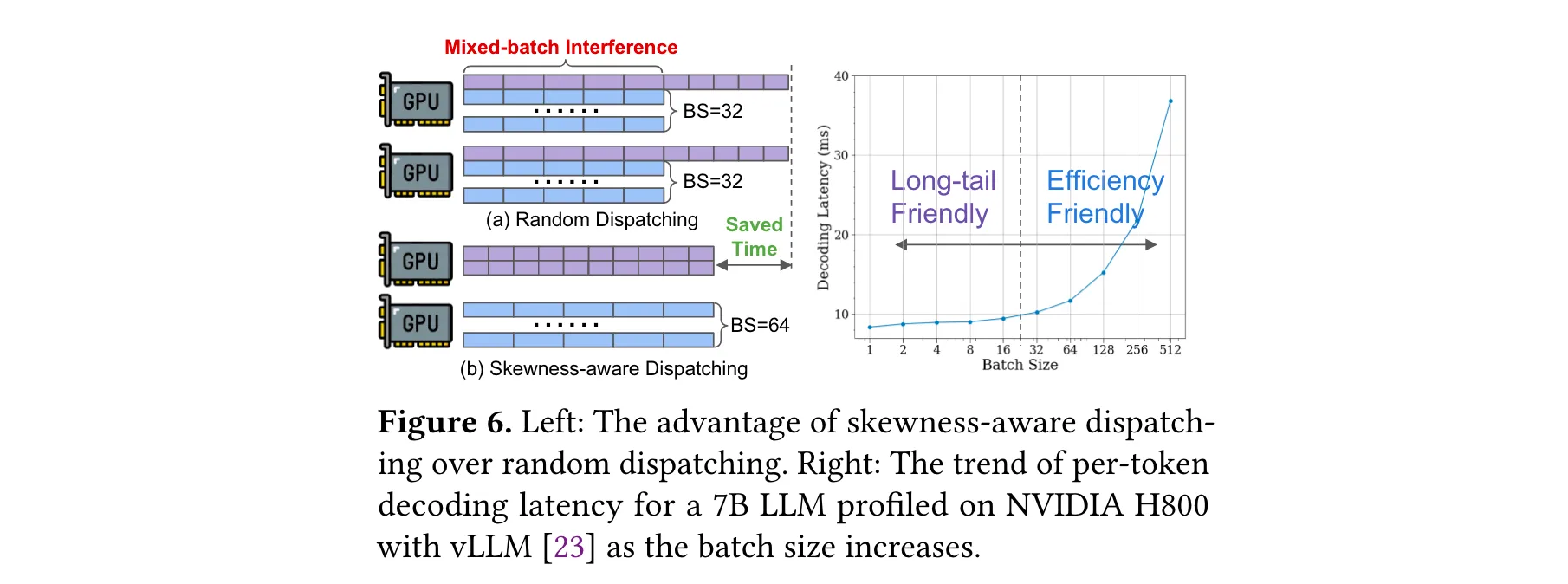
3. 處理偏態氣泡問題:為解決偏態氣泡,StreamRL利用輸出長度排序器模型來識別長尾樣本。該模型通過對收集的(prompt, length)對進行監督微調訓練得到,可對輸入提示的輸出長度進行估計和排序。基于此,SGS采用偏態感知調度機制,將提示按估計輸出長度排序,標記出長尾樣本,為其分配專門的計算資源和較小的批量大小,同時將常規樣本組成大批次,充分利用GPU資源。在調度順序上,采用最長處理時間優先(LPT)的貪心算法,優先處理長樣本,以減少整體生成延遲。
4. 系統實現優化:SGS使用內部優化的C++推理引擎和CUDA內核,支持連續批處理和前綴共享技術,提高生成效率;Trainer實現3D并行,通過開發動態CPU卸載技術解決GPU內存限制問題。此外,專門開發的RL - RPC通信框架用于SGS和Trainer間的數據傳輸,利用GPU - Direct RDMA實現零拷貝張量傳輸,減少通信開銷,并具備TCP fallback機制確保兼容性。在權重傳輸方面,根據不同部署場景采用不同策略,單數據中心通過多樹負載均衡,跨數據中心則由特定節點發送權重并結合本地廣播,以優化傳輸效率。
實驗洞察
為全面評估StreamRL的性能,研究人員進行了一系列實驗,從多個維度深入探究其特性,具體實驗結果如下:
1. 性能優勢顯著:研究人員在包含16個節點、128個GPU的H800集群上,選用Qwen2.5系列模型(7B - 72B),以內部CodeMath prompts數據集開展實驗,并以verl和ColocationRL為基線對比。結果顯示,StreamRL - Sync相較于verl,吞吐量提升1.12 - 2.12倍;相較于ColocationRL,提升1.06 - 1.41倍。而StreamRL - Async借助一步異步訓練,充分重疊流水線氣泡,吞吐量提升幅度更大,達1.30 - 2.66倍。在異構、跨數據中心場景下,將SGS部署于H20集群,Trainer部署于H800集群,StreamRL經硬件成本歸一化后的吞吐量,相比單數據中心場景提高了1.23 - 1.31倍,展現出強大的性能優勢。
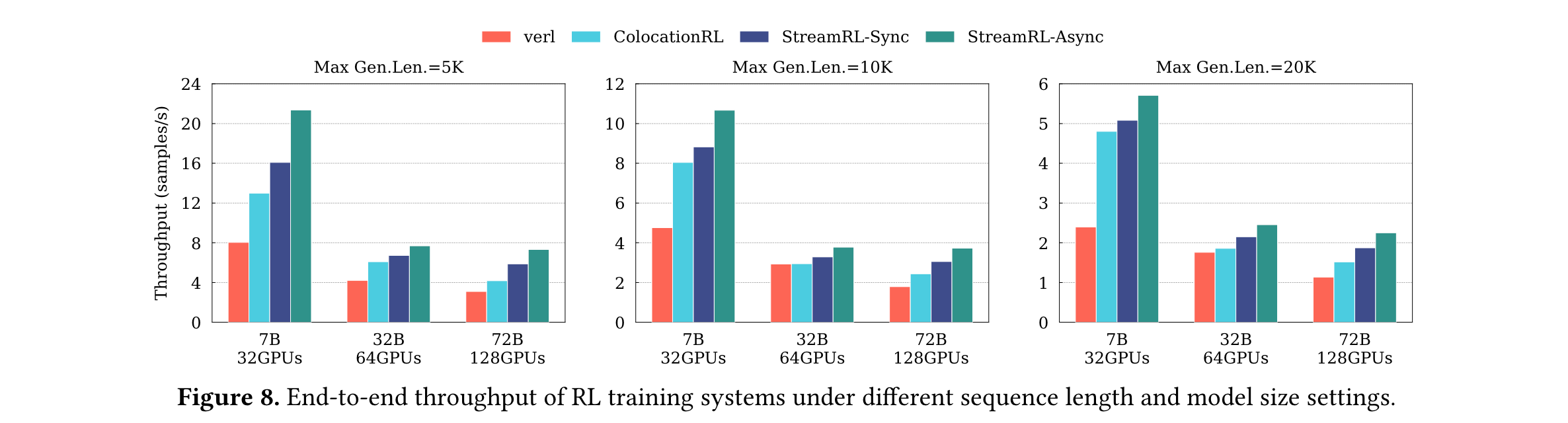
2. 效率大幅提升:在訓練效率方面,StreamRL成果斐然。通過異步訓練和優化資源分配,實現了階段延遲的有效平衡,在異步訓練中迭代時間由較慢階段決定,平衡的階段延遲直接帶來1.25倍的加速。并且,動態調整算法能實時監測生成和訓練時間差,當生成時間超訓練時間一定閾值時,自動為SGS增加數據并行單元,恢復階段平衡。如在訓練7B模型時,隨著數據集輸出長度增加,StreamRL能及時檢測到不平衡并自動調整資源,確保訓練高效進行。
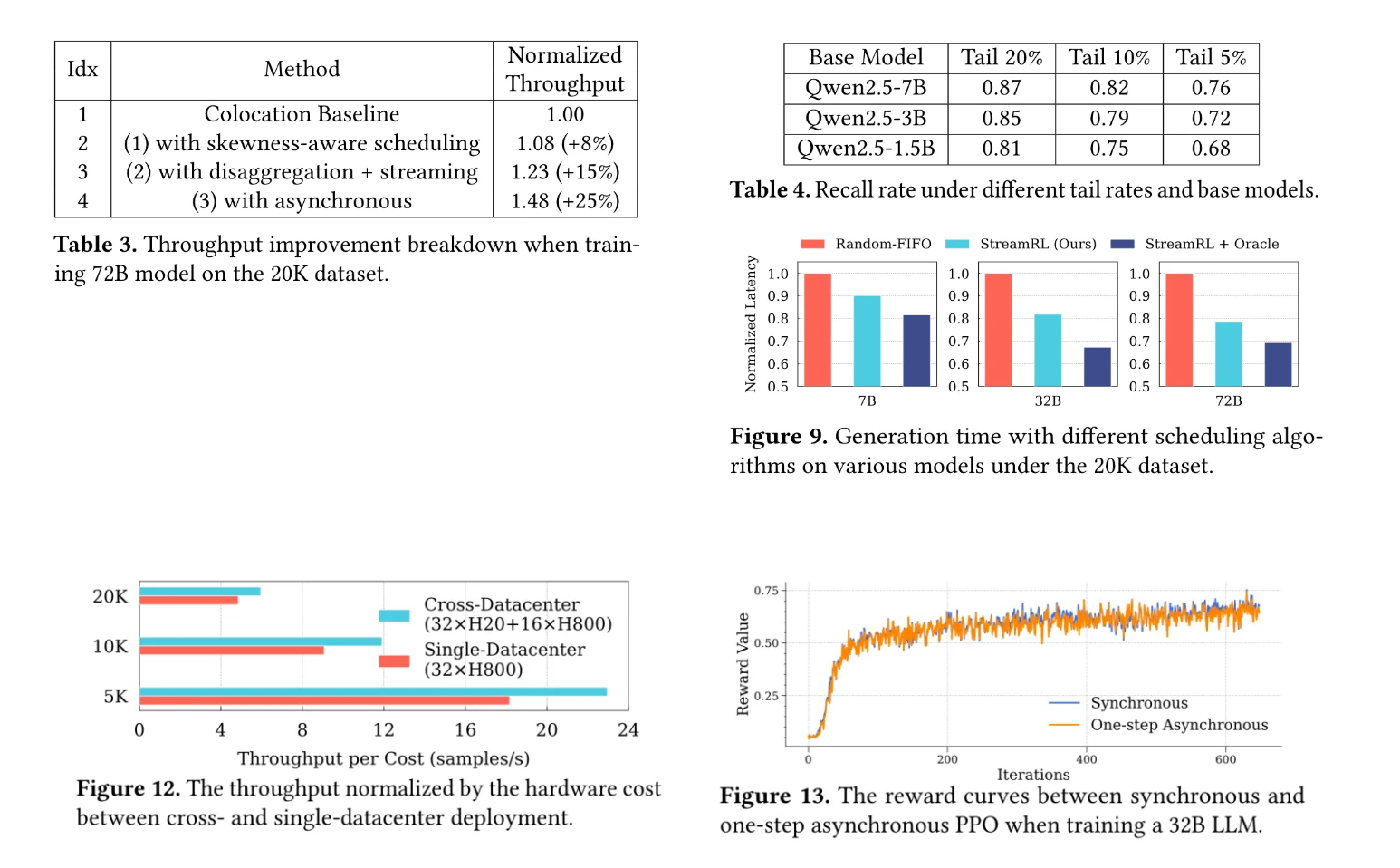
3. 核心模塊效果顯著:通過消融研究,驗證了StreamRL核心模塊的有效性。以72B模型在20K最大長度數據集上的實驗為例,偏態感知調度技術可使吞吐量提升8%,主要是因為其利用輸出長度排序器模型精準識別長尾樣本,為其分配專屬資源和合適批量,加速了長尾樣本生成。在此基礎上,分離式流生成技術進一步將吞吐量提升15%,異步訓練則額外提升25%。輸出長度排序器模型對最長20%樣本的召回率高達87%,能有效識別長尾樣本,大幅提升生成效率,為整體性能提升奠定堅實基礎。








)



P86+P87+P88)






