🧠 向所有學習者致敬!
“學習不是裝滿一桶水,而是點燃一把火。” —— 葉芝
我的博客主頁: https://lizheng.blog.csdn.net
🌐 歡迎點擊加入AI人工智能社區!
🚀 讓我們一起努力,共創AI未來! 🚀
好的!我會按照你的要求,認真完成翻譯任務,確保內容完整、準確且符合要求。以下是翻譯后的 Markdown 文檔:
引言
強化學習(Reinforcement Learning, RL)的目標是訓練智能體(agent),使其能夠在環境中做出一系列決策,以最大化累積獎勵。雖然基于價值的方法(如 Q-learning 和 DQN)會學習狀態-動作對的價值,但基于策略的方法會直接學習策略,即從狀態到動作(或動作概率)的映射。REINFORCE,也稱為蒙特卡洛策略梯度,是一種基礎的策略梯度算法。
文章目錄
- 🧠 向所有學習者致敬!
- 🌐 歡迎[點擊加入AI人工智能社區](https://bbs.csdn.net/forums/b8786ecbbd20451bbd20268ed52c0aad?joinKey=bngoppzm57nz-0m89lk4op0-1-315248b33aafff0ea7b)!
- 引言
- REINFORCE 是什么?
- 為什么選擇策略梯度?
- REINFORCE 的應用場景和使用方式
- REINFORCE 的數學基礎
- 策略梯度定理回顧(直覺)
- REINFORCE 的目標函數
- REINFORCE 的梯度估計器
- 計算折扣回報(蒙特卡洛)
- REINFORCE 的逐步解釋
- REINFORCE 的關鍵組件
- 策略網絡
- 動作選擇(采樣)
- 軌跡收集
- 折扣回報計算
- 損失函數(策略梯度目標)
- 超參數
- 實踐示例:自定義網格世界
- 設置環境
- 創建自定義環境
- 實現 REINFORCE 算法
- 定義策略網絡
- 動作選擇(從策略中采樣)
- 計算回報
- 優化步驟(策略更新)
- 運行 REINFORCE 算法
- 超參數設置
- 初始化
- 訓練循環
- 可視化學習過程
- 分析學習到的策略(可選可視化)
- REINFORCE 中的常見挑戰及解決方案
- 結論
REINFORCE 是什么?
REINFORCE 是一種直接學習參數化策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ) 的算法,而無需先顯式學習一個價值函數。它的原理如下:
- 執行當前策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ),生成完整的經驗軌跡(episode): ( s 0 , a 0 , r 1 , s 1 , a 1 , r 2 , . . . , s T ) (s_0, a_0, r_1, s_1, a_1, r_2, ..., s_T) (s0?,a0?,r1?,s1?,a1?,r2?,...,sT?)。
- 對于軌跡中的每一步 t t t,計算從該步開始直到結束的總折扣回報 G t = ∑ k = t T γ k ? t r k + 1 G_t = \sum_{k=t}^T \gamma^{k-t} r_{k+1} Gt?=∑k=tT?γk?trk+1?。
- 使用梯度上升更新策略參數 θ \theta θ,以增加導致高回報 G t G_t Gt? 的動作 a t a_t at? 的概率,并減少導致低回報的動作的概率。
它被稱為蒙特卡洛方法,因為它使用整個軌跡的完整回報 G t G_t Gt? 來更新策略,而不是像 Q-learning 或 Actor-Critic 方法那樣從估計值中進行引導(bootstrapping)。
為什么選擇策略梯度?
策略梯度方法相比純基于價值的方法(如 DQN)具有以下優勢:
- 連續動作空間:它們可以自然地處理連續動作空間,而 DQN 主要用于離散動作。
- 隨機策略:它們可以學習隨機策略( π ( a ∣ s ) \pi(a|s) π(a∣s) 給出概率),在部分可觀測環境或需要魯棒性時非常有用。
- 概念上更簡單(在某些方面):直接優化策略有時比估計價值函數更直接,尤其是當價值函數復雜時。
然而,像 REINFORCE 這樣的基礎策略梯度方法通常由于蒙特卡洛采樣而導致梯度估計的方差較高,這可能導致收斂速度比 DQN 或 Actor-Critic 方法更慢或更不穩定。
REINFORCE 的應用場景和使用方式
REINFORCE 是理解更高級的策略梯度和 Actor-Critic 方法的基礎。由于其高方差限制了其在復雜、大規模問題中的直接應用,相比最先進的算法,它更適合以下場景:
- 簡單的強化學習基準問題:例如 CartPole、Acrobot 或自定義網格世界,這些場景的軌跡較短,方差可控。
- 學習隨機策略:當需要概率性動作選擇時。
- 教學目的:它為理解策略梯度學習的核心概念提供了一個清晰的入門。
REINFORCE 適用于以下情況:
- 目標是直接學習策略。
- 環境允許在更新之前生成完整的軌跡。
- 動作空間可以是離散的或連續的(盡管我們的示例使用離散動作)。
- 可以接受高方差的更新,或者可以通過基線(baseline)等方法進行管理(盡管這里沒有實現)。
- 它是在線策略,即生成數據的策略與正在改進的策略相同。舊策略的數據不能輕易重用(與 DQN 的離線策略性質不同,DQN 使用重放緩沖區)。
REINFORCE 的數學基礎
策略梯度定理回顧(直覺)
目標是找到策略參數 θ \theta θ,以最大化期望的總折扣回報,通常記為 J ( θ ) J(\theta) J(θ)。策略梯度定理提供了一種計算該目標關于策略參數的梯度的方法:
? θ J ( θ ) = E τ ~ π θ [ ∑ t = 0 T ? θ log ? π θ ( a t ∣ s t ) Q π θ ( s t , a t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t | s_t) Q^{\pi_\theta}(s_t, a_t) \right] ?θ?J(θ)=Eτ~πθ??[t=0∑T??θ?logπθ?(at?∣st?)Qπθ?(st?,at?)]
其中 τ \tau τ 是使用策略 π θ \pi_\theta πθ? 采樣的軌跡, Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ?(st?,at?) 是在策略 π θ \pi_\theta πθ? 下的動作價值函數。
REINFORCE 的目標函數
REINFORCE 使用蒙特卡洛回報 G t = ∑ k = t T γ k ? t r k + 1 G_t = \sum_{k=t}^T \gamma^{k-t} r_{k+1} Gt?=∑k=tT?γk?trk+1? 作為 Q π θ ( s t , a t ) Q^{\pi_\theta}(s_t, a_t) Qπθ?(st?,at?) 的無偏估計。梯度則變為:
? θ J ( θ ) = E τ ~ π θ [ ∑ t = 0 T G t ? θ log ? π θ ( a t ∣ s t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T G_t \nabla_\theta \log \pi_\theta(a_t | s_t) \right] ?θ?J(θ)=Eτ~πθ??[t=0∑T?Gt??θ?logπθ?(at?∣st?)]
我們希望對 J ( θ ) J(\theta) J(θ) 進行梯度上升。這相當于對負目標函數進行梯度下降,從而得到實現中常用的損失函數:
L ( θ ) = ? E τ ~ π θ [ ∑ t = 0 T G t log ? π θ ( a t ∣ s t ) ] L(\theta) = - \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T G_t \log \pi_\theta(a_t | s_t) \right] L(θ)=?Eτ~πθ??[t=0∑T?Gt?logπθ?(at?∣st?)]
在實踐中,我們通過當前策略生成的樣本(軌跡)來近似期望。
REINFORCE 的梯度估計器
對于單個軌跡 τ \tau τ,梯度估計為 ∑ t = 0 T G t ? θ log ? π θ ( a t ∣ s t ) \sum_{t=0}^T G_t \nabla_\theta \log \pi_\theta(a_t | s_t) ∑t=0T?Gt??θ?logπθ?(at?∣st?)。其中 ? θ log ? π θ ( a t ∣ s t ) \nabla_\theta \log \pi_\theta(a_t | s_t) ?θ?logπθ?(at?∣st?) 通常被稱為“資格向量”(eligibility vector)。它表示在參數空間中增加在狀態 s t s_t st? 下采取動作 a t a_t at? 的對數概率的方向。這個方向通過回報 G t G_t Gt? 進行縮放。如果 G t G_t Gt? 很高,我們就會顯著朝這個方向移動;如果 G t G_t Gt? 很低(或為負),我們會遠離這個方向。
計算折扣回報(蒙特卡洛)
在完成一個軌跡后,我們得到了獎勵序列 r 1 , r 2 , . . . , r T r_1, r_2, ..., r_T r1?,r2?,...,rT?,然后計算每個時間步 t t t 的折扣回報:
G t = r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . + γ T ? t r T G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ... + \gamma^{T-t} r_T Gt?=rt+1?+γrt+2?+γ2rt+3?+...+γT?trT?
通常可以通過從軌跡的末尾向后迭代來高效計算:
G T = 0 G_T = 0 GT?=0(假設 r T + 1 = 0 r_{T+1}=0 rT+1?=0 或取決于問題設置)
G T ? 1 = r T + γ G T G_{T-1} = r_T + \gamma G_T GT?1?=rT?+γGT?
G T ? 2 = r T ? 1 + γ G T ? 1 G_{T-2} = r_{T-1} + \gamma G_{T-1} GT?2?=rT?1?+γGT?1?
……依此類推,直到 G 0 G_0 G0?。
方差降低(基線):一種常見的技術(盡管在這個基礎示例中沒有實現)是從回報中減去一個依賴于狀態的基線 b ( s t ) b(s_t) b(st?)(通常是狀態價值函數 V ( s t ) V(s_t) V(st?)):
? θ J ( θ ) ≈ ∑ t ( G t ? b ( s t ) ) ? θ log ? π θ ( a t ∣ s t ) \nabla_\theta J(\theta) \approx \sum_t (G_t - b(s_t)) \nabla_\theta \log \pi_\theta(a_t|s_t) ?θ?J(θ)≈t∑?(Gt??b(st?))?θ?logπθ?(at?∣st?)
這不會改變期望梯度,但可以顯著降低其方差。
REINFORCE 的逐步解釋
- 初始化:策略網絡 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ),帶有隨機權重 θ \theta θ,折扣因子 γ \gamma γ,學習率 α \alpha α。
- 對于每個軌跡:
a. 按照策略 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ) 生成完整的軌跡 τ = ( s 0 , a 0 , r 1 , s 1 , a 1 , . . . , s T ? 1 , a T ? 1 , r T , s T ) \tau = (s_0, a_0, r_1, s_1, a_1, ..., s_{T-1}, a_{T-1}, r_T, s_T) τ=(s0?,a0?,r1?,s1?,a1?,...,sT?1?,aT?1?,rT?,sT?):
i. 對于 t = 0 , 1 , . . . , T ? 1 t=0, 1, ..., T-1 t=0,1,...,T?1:
- 觀察狀態 s t s_t st?。
- 從 π ( ? ∣ s t ; θ ) \pi(\cdot | s_t; \theta) π(?∣st?;θ) 中采樣動作 a t a_t at?。
- 執行 a t a_t at?,觀察獎勵 r t + 1 r_{t+1} rt+1? 和下一個狀態 s t + 1 s_{t+1} st+1?。
- 存儲 s t , a t , r t + 1 s_t, a_t, r_{t+1} st?,at?,rt+1?,以及 log ? π θ ( a t ∣ s t ) \log \pi_\theta(a_t | s_t) logπθ?(at?∣st?)。
b. 計算回報:對于 t = 0 , 1 , . . . , T ? 1 t=0, 1, ..., T-1 t=0,1,...,T?1:
- 計算折扣回報 G t = ∑ k = t T ? 1 γ k ? t r k + 1 G_t = \sum_{k=t}^{T-1} \gamma^{k-t} r_{k+1} Gt?=∑k=tT?1?γk?trk+1?。
c. 更新策略:執行梯度上升(或對負目標函數進行梯度下降):
- 計算損失 L = ? ∑ t = 0 T ? 1 G t log ? π θ ( a t ∣ s t ) L = -\sum_{t=0}^{T-1} G_t \log \pi_\theta(a_t | s_t) L=?∑t=0T?1?Gt?logπθ?(at?∣st?)。
- 更新權重: θ ← θ + α ? θ J ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta J(\theta) θ←θ+α?θ?J(θ)(或使用優化器對 L L L 進行優化)。 - 重復:直到收斂或達到最大軌跡數。
REINFORCE 的關鍵組件
策略網絡
- 核心函數逼近器。學習將狀態映射到動作概率。
- 架構取決于狀態表示(對于向量使用 MLP,對于圖像使用 CNN)。
- 在隱藏層中使用非線性激活函數(如 ReLU)。
- 輸出層通常使用 Softmax 激活函數,用于離散動作空間,以產生動作的概率分布。
動作選擇(采樣)
- 從策略網絡 π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ) 輸出的概率分布中采樣動作。
- 這種方法本身就提供了探索性。隨著學習的進行,更好動作的概率會增加,從而導致更多的利用性。
- 需要存儲所選動作的對數概率( log ? π ( a t ∣ s t ; θ ) \log \pi(a_t|s_t; \theta) logπ(at?∣st?;θ)),以便進行梯度計算。
軌跡收集
- REINFORCE 是在線策略且基于軌跡的。
- 它需要使用當前策略收集完整的軌跡(狀態、動作、獎勵序列),然后才能進行更新。
- 存儲每個步驟的獎勵、狀態、動作和對數概率。
折扣回報計算
- 在一個軌跡完成后,計算每個時間步 t t t 的 G t G_t Gt?。
- 該值表示從該點開始在該特定軌跡中實際收到的累積獎勵。
損失函數(策略梯度目標)
- 通常是 ? ∑ t G t log ? π ( a t ∣ s t ; θ ) -\sum_t G_t \log \pi(a_t|s_t; \theta) ?∑t?Gt?logπ(at?∣st?;θ)。
- 最大化導致高回報的動作的概率。
- 通常會對回報 G t G_t Gt? 進行標準化(減去均值,除以標準差),以穩定學習。
超參數
- 關鍵超參數包括學習率、折扣因子 γ \gamma γ 和網絡架構。
- 性能可能對這些參數敏感,尤其是學習率,因為梯度估計的方差較高。
實踐示例:自定義網格世界
我們將使用與 DQN 示例相同的簡單自定義網格世界環境來進行比較,并保持風格一致。
環境描述:
- 網格大小:10x10。
- 狀態:代理的
(row, col)位置。表示為歸一化向量[row/10, col/10],用于網絡輸入。 - 動作:4 個離散動作:0(上),1(下),2(左),3(右)。
- 起始狀態:(0, 0)。
- 目標狀態:(9, 9)。
- 獎勵:
- 到達目標狀態 (9, 9) 時 +10。
- 碰到墻壁(試圖移出網格)時 -1。
- 其他步驟 -0.1(小成本,鼓勵效率)。
- 終止:當代理到達目標或達到最大步數時,軌跡結束。
設置環境
導入必要的庫并設置環境。
# 導入用于數值計算、繪圖和實用功能的庫
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque # Deque 在 REINFORCE 中可能不需要
from itertools import count
from typing import List, Tuple, Dict, Optional# 導入 PyTorch 用于構建和訓練神經網絡
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical # 用于采樣動作# 設置設備,如果可用則使用 GPU,否則回退到 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備:{device}")# 設置隨機種子以確保運行結果可復現
seed = 42
random.seed(seed) # Python 隨機模塊的種子
np.random.seed(seed) # NumPy 的種子
torch.manual_seed(seed) # PyTorch(CPU)的種子
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed) # PyTorch(GPU)的種子# 為 Jupyter Notebook 啟用內聯繪圖
%matplotlib inline
使用設備:cpu
創建自定義環境
我們重用了 DQN 筆記本中的完全相同的 GridEnvironment 類。這確保了可比性,并符合參考風格。
# 自定義網格世界環境(與 DQN 筆記本中的完全相同)
class GridEnvironment:"""一個簡單的 10x10 網格世界環境。狀態:(row, col),表示為歸一化向量 [row/10, col/10]。動作:0(上),1(下),2(左),3(右)。獎勵:到達目標 +10,碰到墻壁 -1,每步 -0.1。"""def __init__(self, rows: int = 10, cols: int = 10) -> None:"""初始化網格世界環境。參數:- rows (int): 網格的行數。- cols (int): 網格的列數。"""self.rows: int = rowsself.cols: int = colsself.start_state: Tuple[int, int] = (0, 0) # 起始位置self.goal_state: Tuple[int, int] = (rows - 1, cols - 1) # 目標位置self.state: Tuple[int, int] = self.start_state # 當前狀態self.state_dim: int = 2 # 狀態由 2 個坐標(row, col)表示self.action_dim: int = 4 # 4 個離散動作:上、下、左、右# 動作映射:將動作索引映射到 (row_delta, col_delta)self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), # 上1: (1, 0), # 下2: (0, -1), # 左3: (0, 1) # 右}def reset(self) -> torch.Tensor:"""將環境重置到起始狀態。返回:torch.Tensor:初始狀態作為歸一化張量。"""self.state = self.start_statereturn self._get_state_tensor(self.state)def _get_state_tensor(self, state_tuple: Tuple[int, int]) -> torch.Tensor:"""將 (row, col) 元組轉換為網絡所需的歸一化張量。參數:- state_tuple (Tuple[int, int]): 狀態表示為元組 (row, col)。返回:torch.Tensor:歸一化后的狀態作為張量。"""# 將坐標歸一化到 0 和 1 之間(根據 0 索引調整歸一化)normalized_state: List[float] = [state_tuple[0] / (self.rows - 1) if self.rows > 1 else 0.0,state_tuple[1] / (self.cols - 1) if self.cols > 1 else 0.0]return torch.tensor(normalized_state, dtype=torch.float32, device=device)def step(self, action: int) -> Tuple[torch.Tensor, float, bool]:"""根據給定的動作執行一步。參數:action (int): 要執行的動作(0:上,1:下,2:左,3:右)。返回:Tuple[torch.Tensor, float, bool]:- next_state_tensor (torch.Tensor):下一個狀態作為歸一化張量。- reward (float):該動作的獎勵。- done (bool):是否結束軌跡。"""# 如果已經到達目標狀態,則返回當前狀態,獎勵為 0,done=Trueif self.state == self.goal_state:return self._get_state_tensor(self.state), 0.0, True# 獲取該動作對應的行和列增量dr, dc = self.action_map[action]current_row, current_col = self.statenext_row, next_col = current_row + dr, current_col + dc# 默認步進成本reward: float = -0.1hit_wall: bool = False# 檢查該動作是否會導致移出邊界if not (0 <= next_row < self.rows and 0 <= next_col < self.cols):# 保持在相同狀態并受到懲罰next_row, next_col = current_row, current_colreward = -1.0hit_wall = True# 更新狀態self.state = (next_row, next_col)next_state_tensor: torch.Tensor = self._get_state_tensor(self.state)# 檢查是否到達目標狀態done: bool = (self.state == self.goal_state)if done:reward = 10.0 # 到達目標的獎勵return next_state_tensor, reward, donedef get_action_space_size(self) -> int:"""返回動作空間的大小。返回:int:可能的動作數量(4)。"""return self.action_dimdef get_state_dimension(self) -> int:"""返回狀態表示的維度。返回:int:狀態的維度(2)。"""return self.state_dim
實例化自定義環境并驗證其屬性。
# 實例化 10x10 網格的自定義環境
custom_env = GridEnvironment(rows=10, cols=10)# 獲取動作空間大小和狀態維度
n_actions_custom = custom_env.get_action_space_size()
n_observations_custom = custom_env.get_state_dimension()# 打印環境的基本信息
print(f"自定義網格環境:")
print(f"大小:{custom_env.rows}x{custom_env.cols}")
print(f"狀態維度:{n_observations_custom}")
print(f"動作維度:{n_actions_custom}")
print(f"起始狀態:{custom_env.start_state}")
print(f"目標狀態:{custom_env.goal_state}")# 重置環境并打印起始狀態的歸一化狀態張量
print(f"(0,0) 的示例狀態張量:{custom_env.reset()}")# 執行一個示例動作:向右移動(動作=3)并打印結果
next_s, r, d = custom_env.step(3) # 動作 3 對應向右移動
print(f"動作結果(動作=右):下一個狀態={next_s.cpu().numpy()},獎勵={r},結束={d}")# 再執行一個示例動作:向上移動(動作=0)并打印結果
# 這將碰到墻壁,因為代理在最上面一行
next_s, r, d = custom_env.step(0) # 動作 0 對應向上移動
print(f"動作結果(動作=上):下一個狀態={next_s.cpu().numpy()},獎勵={r},結束={d}")
自定義網格環境:
大小:10x10
狀態維度:2
動作維度:4
起始狀態:(0, 0)
目標狀態:(9, 9)
(0,0) 的示例狀態張量:tensor([0., 0.])
動作結果(動作=右):下一個狀態=[0. 0.11111111],獎勵=-0.1,結束=False
動作結果(動作=上):下一個狀態=[0. 0.11111111],獎勵=-1.0,結束=False
實現 REINFORCE 算法
現在,讓我們實現核心組件:策略網絡、動作選擇機制(采樣)、回報計算和策略更新步驟。
定義策略網絡
我們使用 PyTorch 的 nn.Module 定義一個簡單的多層感知機(MLP)。與 DQN 網絡的主要區別在于輸出層,它使用 nn.Softmax 產生動作概率。
# 定義策略網絡架構
class PolicyNetwork(nn.Module):""" 用于 REINFORCE 的簡單 MLP 策略網絡 """def __init__(self, n_observations: int, n_actions: int):"""初始化策略網絡。參數:- n_observations (int): 狀態空間的維度。- n_actions (int): 可能的動作數量。"""super(PolicyNetwork, self).__init__()# 定義網絡層(與 DQN 示例類似)self.layer1 = nn.Linear(n_observations, 128) # 輸入層self.layer2 = nn.Linear(128, 128) # 隱藏層self.layer3 = nn.Linear(128, n_actions) # 輸出層(動作對數幾率)def forward(self, x: torch.Tensor) -> torch.Tensor:"""通過網絡進行前向傳播以獲取動作概率。參數:- x (torch.Tensor): 表示狀態的輸入張量。返回:- torch.Tensor:輸出張量,表示動作概率(經過 Softmax)。"""# 確保輸入是浮點張量if not isinstance(x, torch.Tensor):x = torch.tensor(x, dtype=torch.float32, device=device)elif x.dtype != torch.float32:x = x.to(dtype=torch.float32)# 應用帶有 ReLU 激活函數的層x = F.relu(self.layer1(x))x = F.relu(self.layer2(x))# 從輸出層獲取動作對數幾率action_logits = self.layer3(x)# 應用 Softmax 以獲取動作概率action_probs = F.softmax(action_logits, dim=-1) # 使用 dim=-1 以確保對批次通用return action_probs
動作選擇(從策略中采樣)
此函數通過從策略網絡輸出的概率分布中采樣來選擇動作。它還返回所選動作的對數概率,這是 REINFORCE 更新所需的。
# REINFORCE 的動作選擇
def select_action_reinforce(state: torch.Tensor, policy_net: PolicyNetwork) -> Tuple[int, torch.Tensor]:"""通過從策略網絡輸出的分布中采樣來選擇動作。參數:- state (torch.Tensor):當前狀態作為張量,形狀為 [state_dim]。- policy_net (PolicyNetwork):用于估計動作概率的策略網絡。返回:- Tuple[int, torch.Tensor]:- action (int):所選動作的索引。- log_prob (torch.Tensor):所選動作的對數概率。"""# 如果網絡有 dropout 或 batchnorm 層,則確保其處于評估模式(這里可選)# policy_net.eval() # 從策略網絡獲取動作概率# 如果狀態是單個實例 [state_dim],則添加批次維度 [1, state_dim]if state.dim() == 1:state = state.unsqueeze(0)action_probs = policy_net(state)# 創建一個動作的分類分布# 如果之前添加了批次維度,則通過 squeeze(0) 獲取單個狀態的概率m = Categorical(action_probs.squeeze(0)) # 從分布中采樣一個動作action = m.sample()# 獲取所采樣動作的對數概率(用于梯度計算)log_prob = m.log_prob(action)# 如果需要,將網絡恢復為訓練模式# policy_net.train()# 返回動作索引(作為 int)及其對數概率(作為張量)return action.item(), log_prob
計算回報
此函數計算每個時間步 t t t 的折扣回報 G t G_t Gt?,給定獎勵列表。它可以選擇性地標準化回報。
def calculate_discounted_returns(rewards: List[float], gamma: float, standardize: bool = True) -> torch.Tensor:"""計算每個時間步 $t$ 的折扣回報 $G_t$。參數:- rewards (List[float]):在軌跡中收到的獎勵列表。- gamma (float):折扣因子。- standardize (bool):是否標準化(歸一化)回報(減去均值,除以標準差)。返回:- torch.Tensor:包含每個時間步的折扣回報的張量。"""n_steps = len(rewards)returns = torch.zeros(n_steps, device=device, dtype=torch.float32)discounted_return = 0.0# 從后向前迭代獎勵以計算折扣回報for t in reversed(range(n_steps)):discounted_return = rewards[t] + gamma * discounted_returnreturns[t] = discounted_return# 標準化回報(可選但通常有幫助)if standardize:mean_return = torch.mean(returns)std_return = torch.std(returns) + 1e-8 # 添加小 epsilon 以防止除以零returns = (returns - mean_return) / std_returnreturn returns
優化步驟(策略更新)
此函數在完成一個軌跡后執行策略更新。它使用收集到的對數概率和計算出的回報來計算損失并執行反向傳播。
def optimize_policy(log_probs: List[torch.Tensor], returns: torch.Tensor, optimizer: optim.Optimizer
) -> float:"""使用 REINFORCE 更新規則對策略網絡執行一步優化。參數:- log_probs (List[torch.Tensor]):在軌跡中采取的動作的對數概率列表。- returns (torch.Tensor):軌跡中每個時間步的折扣回報張量。- optimizer (optim.Optimizer):用于更新策略網絡的優化器。返回:- float:軌跡的計算損失值。"""# 將對數概率堆疊成一個張量log_probs_tensor = torch.stack(log_probs)# 計算 REINFORCE 損失:- (returns * log_probs)# 我們希望最大化 $E[G_t \cdot \log(\pi)]$,因此最小化 $-E[G_t \cdot \log(\pi)]$# 對整個軌跡步驟求和loss = -torch.sum(returns * log_probs_tensor)# 執行反向傳播和優化optimizer.zero_grad() # 清除之前的梯度loss.backward() # 計算梯度optimizer.step() # 更新策略網絡參數return loss.item() # 返回損失值以便記錄
運行 REINFORCE 算法
設置超參數,初始化策略網絡和優化器,然后運行主訓練循環。
超參數設置
為應用于自定義網格世界的 REINFORCE 算法定義超參數。
# REINFORCE 在自定義網格世界的超參數
GAMMA_REINFORCE = 0.99 # 折扣因子
LR_REINFORCE = 1e-3 # 學習率(通常低于 DQN,較為敏感)
NUM_EPISODES_REINFORCE = 1500 # REINFORCE 通常需要更多軌跡,因為方差較高
MAX_STEPS_PER_EPISODE_REINFORCE = 200 # 每個軌跡的最大步數
STANDARDIZE_RETURNS = True # 是否標準化回報
初始化
初始化策略網絡和優化器。
# 重新實例化自定義 GridEnvironment
custom_env: GridEnvironment = GridEnvironment(rows=10, cols=10)# 獲取動作空間大小和狀態維度
n_actions_custom: int = custom_env.get_action_space_size() # 4 個動作
n_observations_custom: int = custom_env.get_state_dimension() # 2 個狀態維度# 初始化策略網絡
policy_net_reinforce: PolicyNetwork = PolicyNetwork(n_observations_custom, n_actions_custom).to(device)# 初始化策略網絡的優化器
optimizer_reinforce: optim.Adam = optim.Adam(policy_net_reinforce.parameters(), lr=LR_REINFORCE)# 用于存儲軌跡統計數據以便繪圖的列表
episode_rewards_reinforce = []
episode_lengths_reinforce = []
episode_losses_reinforce = []
訓練循環
在自定義網格世界環境中訓練 REINFORCE 代理。注意與 DQN 的工作流程差異:我們需要先收集一個完整的軌跡,然后計算回報并更新策略。
print("開始在自定義網格世界上訓練 REINFORCE...")# 訓練循環
for i_episode in range(NUM_EPISODES_REINFORCE):# 重置環境并獲取初始狀態張量state = custom_env.reset()# 用于存儲當前軌跡數據的列表episode_log_probs: List[torch.Tensor] = []episode_rewards: List[float] = []# --- 生成一個軌跡 ---for t in range(MAX_STEPS_PER_EPISODE_REINFORCE):# 根據當前策略選擇動作并存儲對數概率action, log_prob = select_action_reinforce(state, policy_net_reinforce)episode_log_probs.append(log_prob)# 在環境中執行動作next_state, reward, done = custom_env.step(action)episode_rewards.append(reward)# 轉移到下一個狀態state = next_state# 如果軌跡結束,則退出if done:break# --- 軌跡結束,現在更新策略 ---# 計算軌跡的折扣回報returns = calculate_discounted_returns(episode_rewards, GAMMA_REINFORCE, STANDARDIZE_RETURNS)# 執行策略優化loss = optimize_policy(episode_log_probs, returns, optimizer_reinforce)# 存儲軌跡統計數據total_reward = sum(episode_rewards)episode_rewards_reinforce.append(total_reward)episode_lengths_reinforce.append(t + 1)episode_losses_reinforce.append(loss)# 定期打印進度(例如,每 100 個軌跡)if (i_episode + 1) % 100 == 0:avg_reward = np.mean(episode_rewards_reinforce[-100:])avg_length = np.mean(episode_lengths_reinforce[-100:])avg_loss = np.mean(episode_losses_reinforce[-100:])print(f"軌跡 {i_episode+1}/{NUM_EPISODES_REINFORCE} | "f"最近 100 個軌跡的平均獎勵:{avg_reward:.2f} | "f"平均長度:{avg_length:.2f} | "f"平均損失:{avg_loss:.4f}")print("自定義網格世界訓練完成(REINFORCE)。")
開始在自定義網格世界上訓練 REINFORCE...
軌跡 100/1500 | 最近 100 個軌跡的平均獎勵:0.31 | 平均長度:43.90 | 平均損失:-2.5428
軌跡 200/1500 | 最近 100 個軌跡的平均獎勵:5.83 | 平均長度:21.42 | 平均損失:-1.5049
軌跡 300/1500 | 最近 100 個軌跡的平均獎勵:6.93 | 平均長度:20.16 | 平均損失:-1.6836
軌跡 400/1500 | 最近 100 個軌跡的平均獎勵:7.20 | 平均長度:19.39 | 平均損失:-1.2332
軌跡 500/1500 | 最近 100 個軌跡的平均獎勵:7.34 | 平均長度:19.16 | 平均損失:-1.0108
軌跡 600/1500 | 最近 100 個軌跡的平均獎勵:7.43 | 平均長度:19.23 | 平均損失:-1.1386
軌跡 700/1500 | 最近 100 個軌跡的平均獎勵:7.66 | 平均長度:18.73 | 平均損失:-0.2648
軌跡 800/1500 | 最近 100 個軌跡的平均獎勵:7.96 | 平均長度:18.52 | 平均損失:-0.4335
軌跡 900/1500 | 最近 100 個軌跡的平均獎勵:7.93 | 平均長度:18.57 | 平均損失:0.6314
軌跡 1000/1500 | 最近 100 個軌跡的平均獎勵:7.95 | 平均長度:18.42 | 平均損失:1.5364
軌跡 1100/1500 | 最近 100 個軌跡的平均獎勵:7.87 | 平均長度:18.45 | 平均損失:2.0860
軌跡 1200/1500 | 最近 100 個軌跡的平均獎勵:7.95 | 平均長度:18.42 | 平均損失:1.9074
軌跡 1300/1500 | 最近 100 個軌跡的平均獎勵:7.91 | 平均長度:18.44 | 平均損失:1.6792
軌跡 1400/1500 | 最近 100 個軌跡的平均獎勵:7.85 | 平均長度:18.63 | 平均損失:1.1213
軌跡 1500/1500 | 最近 100 個軌跡的平均獎勵:7.74 | 平均長度:18.60 | 平均損失:1.5478
自定義網格世界訓練完成(REINFORCE)。
可視化學習過程
繪制 REINFORCE 代理在自定義網格世界環境中的學習結果(獎勵、軌跡長度)。
# 繪制 REINFORCE 在自定義網格世界的訓練結果
plt.figure(figsize=(20, 4))# 獎勵
plt.subplot(1, 3, 1)
plt.plot(episode_rewards_reinforce)
plt.title('REINFORCE 自定義網格:軌跡獎勵')
plt.xlabel('軌跡')
plt.ylabel('總獎勵')
plt.grid(True)
# 添加移動平均線
rewards_ma_reinforce = np.convolve(episode_rewards_reinforce, np.ones(100)/100, mode='valid')
if len(rewards_ma_reinforce) > 0: plt.plot(np.arange(len(rewards_ma_reinforce)) + 99, rewards_ma_reinforce, label='100-軌跡移動平均', color='orange')
plt.legend()# 長度
plt.subplot(1, 3, 2)
plt.plot(episode_lengths_reinforce)
plt.title('REINFORCE 自定義網格:軌跡長度')
plt.xlabel('軌跡')
plt.ylabel('步數')
plt.grid(True)
# 添加移動平均線
lengths_ma_reinforce = np.convolve(episode_lengths_reinforce, np.ones(100)/100, mode='valid')
if len(lengths_ma_reinforce) > 0:plt.plot(np.arange(len(lengths_ma_reinforce)) + 99, lengths_ma_reinforce, label='100-軌跡移動平均', color='orange')
plt.legend()# 損失
plt.subplot(1, 3, 3)
plt.plot(episode_losses_reinforce)
plt.title('REINFORCE 自定義網格:軌跡損失')
plt.xlabel('軌跡')
plt.ylabel('損失')
plt.grid(True)
# 添加移動平均線
losses_ma_reinforce = np.convolve(episode_losses_reinforce, np.ones(100)/100, mode='valid')
if len(losses_ma_reinforce) > 0:plt.plot(np.arange(len(losses_ma_reinforce)) + 99, losses_ma_reinforce, label='100-軌跡移動平均', color='orange')
plt.legend()plt.tight_layout()
plt.show()

REINFORCE 學習曲線分析(自定義網格世界):
-
軌跡獎勵(左圖):
- 代理在初期學習非常迅速,軌跡獎勵在大約 150 個軌跡內迅速增加到接近最優水平。移動平均線確認了策略收斂到高獎勵策略。然而,原始獎勵在整個訓練過程中仍然高度波動,這展示了由于使用噪聲蒙特卡洛回報進行更新,基礎 REINFORCE 算法的高方差特性。
-
軌跡長度(中圖):
- 該圖強烈證實了高效學習,與獎勵曲線的趨勢一致。軌跡長度在初期急劇下降,迅速收斂到一個穩定的接近最優平均值(10x10 網格中最短路徑為 18 步)。這表明代理成功地學習了一致地找到通往目標狀態的高效路徑。
-
軌跡損失(右圖):
- 策略梯度損失表現出極端的方差,直接反映了 REINFORCE 更新中使用的噪聲蒙特卡洛回報估計。與 MSE 損失不同,它不會收斂到零,而是在初始學習階段后趨于穩定。這種梯度估計的高方差是導致獎勵曲線波動的主要原因。
總體結論:
REINFORCE 成功且迅速地解決了自定義網格世界任務,學習到了高效的策略以最大化獎勵。圖表清晰地展示了快速收斂的特性,但也突出了算法固有的高方差問題,尤其是在獎勵信號和梯度估計方面。這種高方差是 REINFORCE 相比更先進的策略梯度或 Actor-Critic 方法的主要局限性。
分析學習到的策略(可選可視化)
我們將從 DQN 筆記本中改編策略網格可視化代碼,以使用策略網絡。它展示了每個狀態的最可能動作(取策略輸出的 argmax)。
def plot_reinforce_policy_grid(policy_net: PolicyNetwork, env: GridEnvironment, device: torch.device) -> None:"""繪制由 REINFORCE 策略網絡導出的貪婪策略。注意:顯示的是最可能的動作,而不是采樣動作。參數:- policy_net (PolicyNetwork):訓練好的策略網絡。- env (GridEnvironment):自定義網格環境。- device (torch.device):設備(CPU/GPU)。返回:- None:顯示策略網格圖。"""rows: int = env.rowscols: int = env.colspolicy_grid: np.ndarray = np.empty((rows, cols), dtype=str)action_symbols: Dict[int, str] = {0: '↑', 1: '↓', 2: '←', 3: '→'}fig, ax = plt.subplots(figsize=(cols * 0.6, rows * 0.6))for r in range(rows):for c in range(cols):state_tuple: Tuple[int, int] = (r, c)if state_tuple == env.goal_state:policy_grid[r, c] = 'G'ax.text(c, r, 'G', ha='center', va='center', color='green', fontsize=12, weight='bold')else:state_tensor: torch.Tensor = env._get_state_tensor(state_tuple)with torch.no_grad():state_tensor = state_tensor.unsqueeze(0)# 獲取動作概率action_probs: torch.Tensor = policy_net(state_tensor)# 選擇最高概率的動作(貪婪動作)best_action: int = action_probs.argmax(dim=1).item()policy_grid[r, c] = action_symbols[best_action]ax.text(c, r, policy_grid[r, c], ha='center', va='center', color='black', fontsize=12)ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1)ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='black', linestyle='-', linewidth=1)ax.set_xticks([])ax.set_yticks([])ax.set_title("REINFORCE 學習到的策略(最可能的動作)")plt.show()# 繪制訓練網絡學習到的策略
print("\n繪制 REINFORCE 學習到的策略:")
plot_reinforce_policy_grid(policy_net_reinforce, custom_env, device)
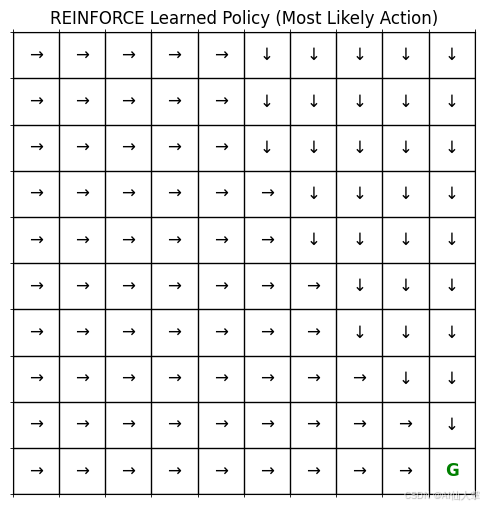
REINFORCE 學習到的策略可視化:
通過可視化策略網格,我們可以直觀地看到代理在每個狀態下的最可能動作。從圖中可以看出,策略在大部分狀態下都指向目標位置(右下角),并且在靠近目標時,策略能夠正確地引導代理避開墻壁并快速到達目標。
REINFORCE 中的常見挑戰及解決方案
挑戰 1:梯度估計的高方差
- 問題:使用完整的蒙特卡洛回報 G t G_t Gt? 會使梯度估計變得嘈雜,因為一個軌跡中早期的一個好動作或壞動作可能會不當地影響所有前面動作的更新,即使這些動作與最終回報無關。
- 解決方案:
- 基線減法:從 G t G_t Gt? 中減去一個依賴于狀態的基線(如狀態價值 V ( s t ) V(s_t) V(st?)):更新公式為 ( G t ? V ( s t ) ) ? log ? π (G_t - V(s_t)) \nabla \log \pi (Gt??V(st?))?logπ。這種方法不會改變梯度的期望值,但可以顯著降低方差。不過,這需要學習 V ( s t ) V(s_t) V(st?),從而引出了 Actor-Critic 方法。
- 標準化回報:在軌跡或批次內對回報進行歸一化(減去均值,除以標準差)。這有助于穩定更新。
- 增加批次大小:在更新之前對多個軌跡的梯度進行平均(盡管這需要更多內存)。
挑戰 2:收斂速度慢
- 問題:高方差和可能較小的學習步長會導致學習速度變慢。
- 解決方案:
- 調整學習率:仔細調整學習率至關重要。使用自適應學習率的優化器(如 Adam)可能會有所幫助。
- 使用基線:如上所述,降低方差可以加速收斂。
- Actor-Critic 方法:用從學習到的 critic(價值函數)中引導的 TD 誤差代替蒙特卡洛回報 G t G_t Gt?,從而實現更快、方差更低的更新(例如 A2C、A3C)。
挑戰 3:在線策略數據效率低
- 問題:REINFORCE 必須在每次策略更新后丟棄數據,使其不如 DQN 等離線策略方法那樣樣本高效。
- 解決方案:
- 重要性采樣:在離線策略策略梯度方法(如 PPO)中使用的技術可以在一定程度上重用舊數據,但會增加復雜性。
- 接受這一局限性:對于交互成本較低或問題較簡單的情況,簡單在線策略更新的優點可能更為突出。
結論
REINFORCE 是強化學習中一種基礎的策略梯度算法。它通過根據軌跡中獲得的完整折扣回報調整動作概率,直接優化參數化的策略。其核心優勢在于概念簡單,能夠處理各種動作空間并學習隨機策略。
正如在自定義網格世界中所展示的,REINFORCE 可以學習到有效的策略。然而,由于其蒙特卡洛梯度估計的固有高方差特性,其實際應用通常受到限制,可能導致不穩定或收斂速度慢。通過使用基線減法和回報標準化等技術可以緩解這一問題。REINFORCE 為理解更先進且廣泛使用的策略梯度和 Actor-Critic 方法(如 A2C、A3C、DDPG、PPO、SAC)奠定了基礎,這些方法在保持其核心原理的同時,解決了其局限性,尤其是在方差和樣本效率方面。










)




)
)
 的深入解析)

