
實現消息序列化
- 為什么不使用JSON來序列化
- 直接使用二進制序列化
- 實現序列化方法toBytes()
- 1: 創建內存緩沖區??
- 2 :創建對象序列化通道?
- 3:執行序列化操作?
- 4:提取二進制數據,轉換成byte[]
- 序列化圖示流程:
- 序列化完整代碼:
- 反序列化方法fromBytes():
- 1 :創建內存輸入流?
- 2 : 創建對象反序列化通道
- 3 : 執行反序列化操作?
- 圖示流程:
- 完整代碼:
- 實現Serializable接口
- 把消息寫入文件中
- 線程安全問題:
- 刪除消息
- 加載文件中所有的信息
什么叫做序列化?
把一個對象,也就是一個結構化的數據,給轉換成一個字符串/字節數組
什么是反序列化?
把一個字符串/字節數組給轉換為一個對象/一個結構化數據
我們需要保證在完成序列化之后,對象的信息是不丟失的,對象中的所有信息在序列化之后,都會被保存到字符串/字節數組中的
如此之后,才可以在后面進行反序列化
序列化的目的就是為了最終進行反序列化,序列化是為了方便存儲和傳輸
存儲就是在文件中存儲,因為文件只能存字符串/二進制數據,文件是不能直接存儲對象,需要把對象通過序列化轉換成一個字符串
為什么不使用JSON來序列化
我們之前是使用了JSON來完成序列化和反序列化
由于Message里面存儲的body部分是二進制數據,不方便使用JSON進行序列化
因為JSON序列化得到的結果是文本數據,無法存儲二進制數據:
在JSON格式中有很多特殊符號,會影響到JSON格式的解析,所以JSON格式不能存儲二進制
所以我們不使用JSON進行序列化,
我們直接使用二進制的序列化方式,針對Message對象進行序列化
直接使用二進制序列化
針對二進制序列化有很多解決方案,我們就采取最直接的一種:
使用Java標準庫中的提供的序列化方案:ObjectInputStream和ObjectOutputStream
這樣不用引入額外的依賴了,其他的方案需要引入額外的依賴:
- protobuffer
- thrift
我們將序列化操作都編寫在一個BinaryTool類中去:
這種序列化操作是偏向于一種公共的代碼,客戶端和服務器都需要使用到序列化,所以我們就直接把這個序列化的代碼編寫到公共目錄下即可:
- 序列化:ObjectOutputStream
- 反序列化:ObjectInputStream
實現序列化方法toBytes()
下面我們去實現一個序列化方法toBytes():
這個toBytes方法的具體流程如下所示:
1: 創建內存緩沖區??
try(ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()) { ... }
??作用??:ByteArrayOutputStream 是一個內存中的字節容器,用來臨時存儲序列化后的二進制數據。
??類比??:就像快遞打包時使用的空紙箱,用來裝載物品(對象的二進制數據)
2 :創建對象序列化通道?
try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)) { ... }
??作用??:ObjectOutputStream 是對象序列化的核心工具,負責將Java對象轉換為二進制流。
??流程: 通過構造函數將 ObjectOutputStream 與 ByteArrayOutputStream 綁定,形成數據傳輸管道(類似給紙箱貼上快遞單)
ObjectOutputStream 會自動寫入序列化協議頭(標識該流是序列化數據)
3:執行序列化操作?
objectOutputStream.writeObject(object);
4:提取二進制數據,轉換成byte[]
return byteArrayOutputStream.toByteArray();
序列化圖示流程:
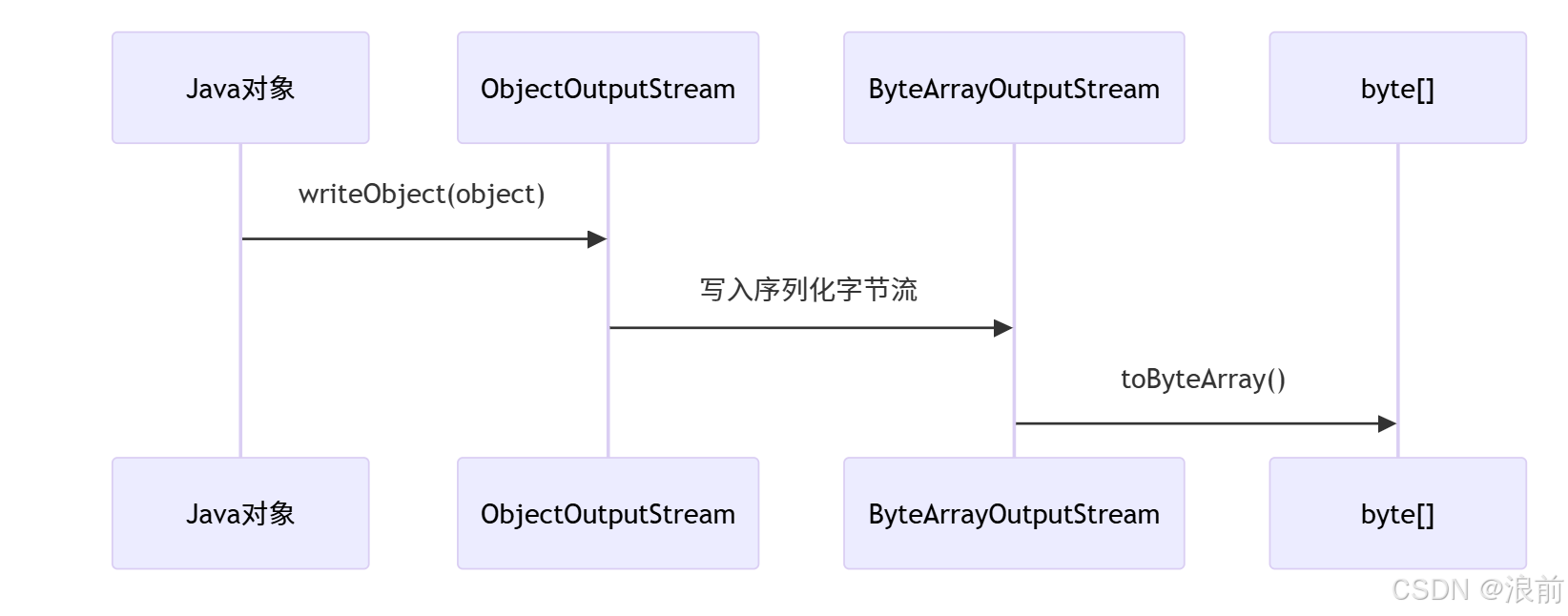
序列化完整代碼:
//序列化:把一個對象序列化為一個字節數組
public static byte[] toBytes(Object object) throws IOException { //這個流對象類似于一個變長的字節數組: //可以把Object序列化的數據給逐漸地寫入到byteArrayOutputStream中,然后再統一轉成byte[] try(ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){ try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)){ //此處的writeObject就會把該對象進行序列化,生成的二進制字節數據,就會寫入到ObjectOutputStream中 //由于ObjectOutputStream是關聯著ByteArrayOutputStream //所以結果就直接寫入到了ByteArrayOutputStream中: objectOutputStream.writeObject(object); } //這個操作是把byteArrayOutputStream中持有的二進制數據取出來,轉換成byte[] return byteArrayOutputStream.toByteArray(); }
}
反序列化方法fromBytes():
1 :創建內存輸入流?
try(ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)) { ... }
??作用??:將 byte[] 數據包裝為內存輸入流,允許按字節順序讀取數據
??類比??:就像把打包好的快遞箱拆封后擺上傳輸帶
2 : 創建對象反序列化通道
try(ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)) { ... }
3 : 執行反序列化操作?
object = objectInputStream.readObject();
圖示流程:
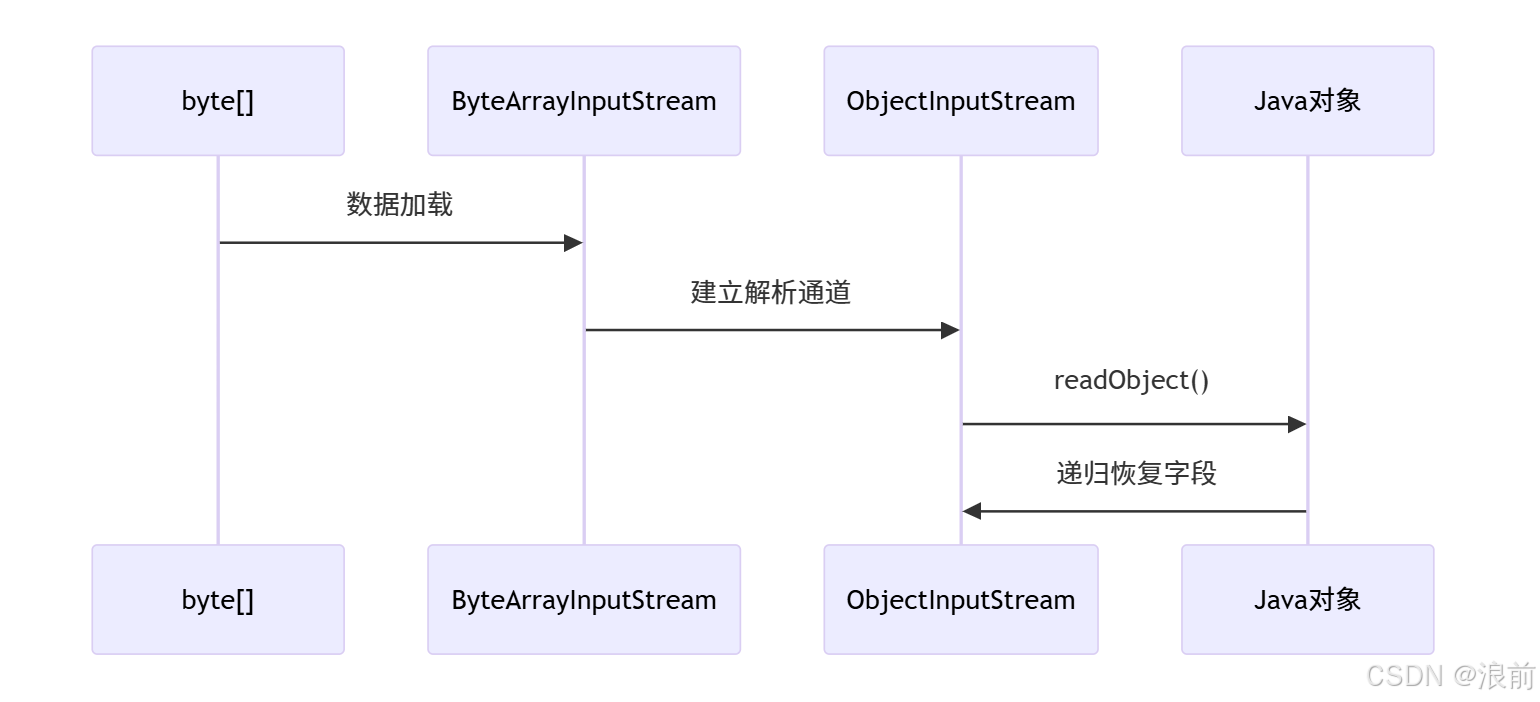
完整代碼:
//反序列化:把一個字節數組反序列化為一個對象:
private static Object fromBytes(byte[] data) throws IOException, ClassNotFoundException { Object object; try(ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)){ try(ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)){ //此處的readObject就是從data這個byte[]中讀取的數據并進行反序列化: object = objectInputStream.readObject(); } } return object;
}
實現Serializable接口
如果希望這個類可以實現序列化和反序列化,就需要讓這個類去實現一個接口:Serializable:
最后這個類的代碼如下所示:
package org.example.mq.common; import java.io.*; public class BinaryTool implements Serializable { //序列化:把一個對象序列化為一個字節數組 public static byte[] toBytes(Object object) throws IOException { //這個流對象類似于一個變長的字節數組: //可以把Object序列化的數據給逐漸地寫入到byteArrayOutputStream中,載統一轉成byte[] try(ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){ try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)){ //此處的writeObject就會把該對象進行序列化,生成的二進制字節數據,就會寫入到ObjectOutputStream中 //由于ObjectOutputStream是關聯著ByteArrayOutputStream //所以結果就直接寫入到了ByteArrayOutputStream中: objectOutputStream.writeObject(object); } //這個操作是把byteArrayOutputStream中持有的二進制數據取出來,轉換成byte[] return byteArrayOutputStream.toByteArray(); } } //反序列化:把一個字節數組反序列化為一個對象: private static Object fromBytes(byte[] data) throws IOException, ClassNotFoundException { Object object; try(ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)){ try(ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)){ //此處的readObject就是從data這個byte[]中讀取的數據并進行反序列化: object = objectInputStream.readObject(); } } return object; }
}
把消息寫入文件中
在MessageFileManager類中寫這樣的一個方法:
方法的大致步驟如下所示:
- 檢查要寫入的文件是否存在
- 把Message對象進行序列化,轉成二進制字節數組
- 獲取到隊列數據文件的長度
- 計算出Message對象的offsetBeg和offsetEnd,來看看從隊列的哪一個位置寫入對象
- 開始將消息寫入到隊列,追加寫(true)
- 先寫消息長度
- 再寫消息本體
- 最后通過stat更新消息的統計文件
//這個方法用來把一個新的消息放到隊列對應的文件中
//第一個參數是寫入的目的隊列,第二個參數是寫入的消息
public void sendMessage(MSGQueue queue, Message message) throws MqException, IOException { //檢查一下當前要寫入的隊列對應的文件是否存在: if(!checkFilesExits(queue.getName())){ throw new MqException("[MessageFileManager] 隊列對應的文件不存在!queueName:"+queue.getName()); } //2.把Message對象,進行序列化,轉成二進制的字節數組: byte[] messageBinary = BinaryTool.toBytes(message); //3.先獲取到當前的隊列數據文件的長度,用這個來計算出Message對象的offsetBeg和offsetEnd //把新的Message數據寫入到隊列數據文件的末尾,此時Message對象的offsetBeg就是當前文件長度+4 //offsetEnd就是當前文件長度 + 4 + message資深的長度: File queueDataFile = new File(getQueueDataPath(queue.getName())); //通過length方法獲取數據文件的長度,單位是字節: //計算出offsetBeg和offsetEnd: message.setOffsetBeg(queueDataFile.length() + 4); message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length); //4.開始寫入消息到數據文件:此處是追加寫,不是覆蓋寫(加上了true參數) try(OutputStream outputStream = new FileOutputStream(queueDataFile,true)){ try(DataOutputStream dataOutputStream = new DataOutputStream(outputStream)){ //接下來寫入消息的消息長度,占據4個字節: dataOutputStream.writeInt(messageBinary.length); //寫入消息體: dataOutputStream.write(messageBinary); } } //5.更新消息統計文件: Stat stat = readStat(queue.getName()); stat.totalCount += 1; stat.validCount += 1; writeStat(queue.getName(),stat);
}
線程安全問題:
方法中如果多個客戶端同時向隊列中寫入消息的時候,會出現線程安全的問題
我們現在寫的是一個消息隊列服務器,服務器就會對應到多個客戶端,會出現多個線程調用message的情況,同時調用這個sendMessage方法去往隊列中寫入消息
如圖所示:

還有一個線程安全問題:
我們方法中的如下代碼也會出現線程安全問題:
//5.更新消息統計文件:
Stat stat = readStat(queue.getName());
stat.totalCount += 1;
stat.validCount += 1;
writeStat(queue.getName(),stat);
這個代碼和我們之前講過的博客文章中出現的線程安全問題類似:【多線程】之線程安全問題
目前解決線程安全問題的方法就是去加鎖
具體以哪個對象加鎖,當線程遇到鎖對象的時候就進行阻塞等待,以此來解決線程安全問題
我們當前就使用隊列對象作為鎖對象進行加鎖即可
如果兩個線程,在同一時刻,是往同一個隊列中寫入消息,那么就要阻塞等待
如果兩個線程,在同一時刻,是往不同的隊列中寫入消息,就不需要阻塞等待
不同隊列是不同的文件,各寫各的,不會出現線程安全問題了
我們把代碼中的寫入消息到隊列中這個整個過程進行加鎖操作即可
如下代碼所示:
//這個方法用來把一個新的消息放到隊列對應的文件中
//第一個參數是寫入的目的隊列,第二個參數是寫入的消息
public void sendMessage(MSGQueue queue, Message message) throws MqException, IOException { //檢查一下當前要寫入的隊列對應的文件是否存在: if(!checkFilesExits(queue.getName())){ throw new MqException("[MessageFileManager] 隊列對應的文件不存在!queueName:"+queue.getName()); } //2.把Message對象,進行序列化,轉成二進制的字節數組: byte[] messageBinary = BinaryTool.toBytes(message); synchronized (queue){ //3.先獲取到當前的隊列數據文件的長度,用這個來計算出Message對象的offsetBeg和offsetEnd //把新的Message數據寫入到隊列數據文件的末尾,此時Message對象的offsetBeg就是當前文件長度+4 //offsetEnd就是當前文件長度 + 4 + message資深的長度: File queueDataFile = new File(getQueueDataPath(queue.getName())); //通過length方法獲取數據文件的長度,單位是字節: //計算出offsetBeg和offsetEnd: message.setOffsetBeg(queueDataFile.length() + 4); message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length); //4.開始寫入消息到數據文件:此處是追加寫,不是覆蓋寫(加上了true參數) try(OutputStream outputStream = new FileOutputStream(queueDataFile,true)){ try(DataOutputStream dataOutputStream = new DataOutputStream(outputStream)){ //接下來寫入消息的消息長度,占據4個字節: dataOutputStream.writeInt(messageBinary.length); //寫入消息體: dataOutputStream.write(messageBinary); } } //5.更新消息統計文件: Stat stat = readStat(queue.getName()); stat.totalCount += 1; stat.validCount += 1; writeStat(queue.getName(),stat); } }
我們現在加鎖的時候為什么出現警告呢?
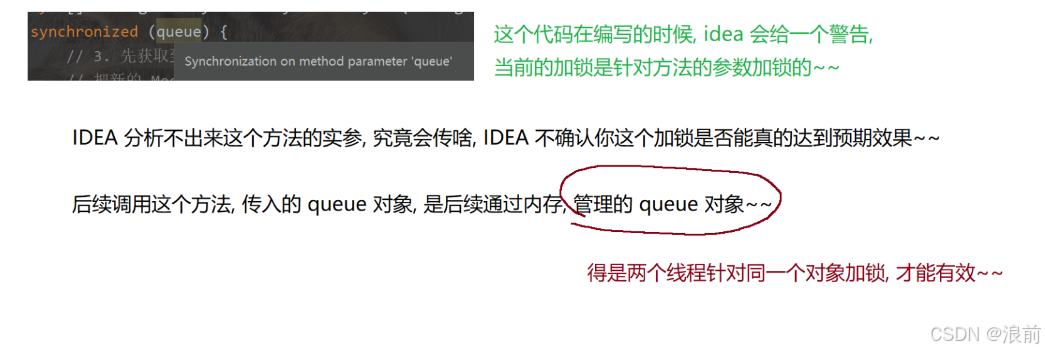
刪除消息
刪除消息的方法,是邏輯刪除,也就是把硬盤上存儲的這個數據里面的那個isValid屬性設置為0:
這個刪除消息的方法的具體步驟:
- 先把文件中的這一段數據給讀出來,還原回Message對象
- 把isValid修改成0
- 把上述數據重新寫回到文件中
此處這個參數中的message對象,必須得包含有效的offsetBeg和offsetEnd:
1: 先把文件中的數據讀取出來,還原回Message對象:
我們之前使用的FileInputStream和FileOutputStream都是從文件頭開始讀寫的
但是此處讀取數據我們需要進行隨機訪問(在文件中的指定位置進行讀取)
使用的是另一個類:RandomAccessFile:

隨機訪問:
內存就支持隨機訪問,內存上的隨機訪問就是訪問內存上面的任意一個地址,開銷成本都一樣
這也是為什么數組可以取下標同時時間復雜度是O(1)的原因
硬盤也能夠支持隨機訪問,但是硬盤的隨機訪問的成本比內存高得多
RandomAccessFile這個類所提供的方法:
- read
- write
- seek:調整當前的文件光標(當前要讀寫的位置)
seek可以移動文件光標,同時read和write也會引起文件光標的移動的,
刪除消息的方法的具體步驟如下所示:
1.
下面開始編寫代碼:
//刪除消息的方法:將isValid屬性設置為0:
public void deleteMessage(MSGQueue queue, Message message) throws IOException, ClassNotFoundException { try(RandomAccessFile randomAccessFile = new RandomAccessFile(getQueueDataPath(queue.getName()), "rw")){ //1.先從文件中讀取對應的Message數據: //讀取操作肯定是從硬盤讀取到內存上 //按照要讀取的Message的長度去創建一個對應的byte空間出來: byte[] bufferSrc = new byte[(int) (message.getOffsetEnd() - message.getOffsetBeg())]; //指定文件光標。指定到message開始的位置: randomAccessFile.seek(message.getOffsetBeg()); //從光標開始的位置,也就是message開始的位置進行讀取:讀取一個bufferSrc大小空間的數據: randomAccessFile.read(bufferSrc); //2.把當前從硬盤上讀取過來的數據(讀取出來的二進制數據)給轉換成Message對象:(反序列化) Message diskMessage =(Message)(BinaryTool.fromBytes(bufferSrc)); //3.把isValid設置為無效(0):邏輯刪除: diskMessage.setIsValid((byte)(0x0)); //4.將刪除完畢的數據重新寫入文件:序列化: byte[] bufferDest = BinaryTool.toBytes(diskMessage); //雖然剛剛已經seek過,但是剛剛seek完了之后,進行了讀操作,導致光標變了: //所以需要重新回到原來的Message數據開始的位置: randomAccessFile.seek(message.getOffsetBeg()); //在原來Message的位置重新寫入刪除完畢之后的數據: randomAccessFile.write(bufferDest); } //更新統計文件,我們把一個消息設置為無效了,此時總消息個數不變,但是有效消息個數就減一: Stat stat = readStat(queue.getName()); if(stat.validCount > 0){ stat.validCount -= 1; } writeStat(queue.getName(),stat);
}
同時這個刪除消息的方法和剛剛的把消息寫入到文件中的方法一樣,也會出現線程安全的問題:
所以也是需要針對鎖對象(隊列對象)進行加鎖操作的:
//刪除消息的方法:將isValid屬性設置為0:
public void deleteMessage(MSGQueue queue, Message message) throws IOException, ClassNotFoundException { synchronized (queue) { try (RandomAccessFile randomAccessFile = new RandomAccessFile(getQueueDataPath(queue.getName()), "rw")) { //1.先從文件中讀取對應的Message數據: //讀取操作肯定是從硬盤讀取到內存上 //按照要讀取的Message的長度去創建一個對應的byte空間出來: byte[] bufferSrc = new byte[(int) (message.getOffsetEnd() - message.getOffsetBeg())]; //指定文件光標。指定到message開始的位置: randomAccessFile.seek(message.getOffsetBeg()); //從光標開始的位置,也就是message開始的位置進行讀取:讀取一個bufferSrc大小空間的數據: randomAccessFile.read(bufferSrc); //2.把當前從硬盤上讀取過來的數據(讀取出來的二進制數據)給轉換成Message對象:(反序列化) Message diskMessage = (Message) (BinaryTool.fromBytes(bufferSrc)); //3.把isValid設置為無效(0):邏輯刪除: diskMessage.setIsValid((byte) (0x0)); //4.將刪除完畢的數據重新寫入文件:序列化: byte[] bufferDest = BinaryTool.toBytes(diskMessage); //雖然剛剛已經seek過,但是剛剛seek完了之后,進行了讀操作,導致光標變了: //所以需要重新回到原來的Message數據開始的位置: randomAccessFile.seek(message.getOffsetBeg()); //在原來Message的位置重新寫入刪除完畢之后的數據: randomAccessFile.write(bufferDest); } //更新統計文件,我們把一個消息設置為無效了,此時總消息個數不變,但是有效消息個數就減一: Stat stat = readStat(queue.getName()); if (stat.validCount > 0) { stat.validCount -= 1; } writeStat(queue.getName(), stat); }
}
刪除方法中聲明的參數對象Message message這個對象是在內存上管理的消息對象
而我們在方法里面寫的diskMessage對象是硬盤上管理的消息對象
這個刪除方法什么時候調用呢,就是當我們需要刪除消息的時候就會去調用這個刪除消息的方法,刪除消息的時機就是消費者將這個消息給正確處理了之后就需要把這個消息給刪除掉了
這個刪除就是要把硬盤上的Message對象和內存上的Message對象都全部進行刪除
而我們剛剛寫的這個刪除方法deleteMessage方法是刪除的是硬盤上面的Message對象的
isValid屬性只是用來在文件中標識這個消息有效還是無效的作用,這個屬性在內存中不起作用
內存中刪除Message對象只需要使用集合類來刪除即可
所以此處就不需要給這個參數的Message對象的isValid設置為無效了,因為這個參數代表的是內存上管理的Message對象,這個對象很快就會從內存上被銷毀了

加載文件中所有的信息
下面這個方法的目的是把所有的文件都讀取出來,加載到內存當中去
這個方法準備在程序啟動的時候去進行調用:
希望在brokerServer重啟了之后,內存上的數據都不會丟失,這個可以把之前保存的消息都能夠還原到內存中去:
服務器重啟的時候,可以把整個文件中所有的消息單獨拎出來放到這個LinkedList鏈表中,交給內存管理器去負責管理:
使用LinkedList主要是為了進行頭刪操作:
這個方法的參數只是一個String的queueName,沒有傳遞queue對象,是因為只需要使用到這個queueName,不需要使用到queue對象
而且這個方法不會出現線程安全問題,不需要進行加鎖操作,因為這個方法是在程序啟動的時候才去調用的,不涉及多線程操作文件
//這個方法目的是把所有的消息內容讀取出來加載到內存中
//這個方法準備在程序啟動的時候調用
public LinkedList<Message> loadAllMessageFromQueue(String queueName) throws IOException, MqException, ClassNotFoundException { LinkedList<Message> messages = new LinkedList<>(); try(InputStream inputStream = new FileInputStream(getDataPath(queueName))){ try(DataInputStream dataInputStream = new DataInputStream(inputStream)){ //使用currentOffset記錄當前文件光標 long currentOffset = 0; //一個文件中包含了很多的信息所以需要循環讀取消息 while(true){ //1.讀取當前消息的長度 // readInt方法讀取到文件末尾,會拋出EOFException異常,這一點和之前的很多流對象都不一樣 int messageSize = dataInputStream.readInt(); //2. 按照這個讀取到的消息長度去讀取消息的內容 byte[] buffer = new byte[messageSize]; int actualSize = dataInputStream.read(buffer); if(messageSize != actualSize){ //大小不匹配,說明文件格式錯亂了 throw new MqException("[MessageFileManager] 文件格式錯誤,queueName = " + queueName); } //3.把讀取到的這個二進制數據給反序列化為Message對象 Message message = (Message)BinaryTool.fromBytes(buffer); //4. 判定一下這個消息對象是不是無效對象 if(message.isValid() != 0x1){ //無效對象,直接跳過,不讀取無效數據 // 雖然消息是無效數據的,但是offset不要忘記更新 currentOffset += (4 + messageSize); continue; } //5. 如果是有效數據,就把當前這個Message對象加入到鏈表中,加入之前還需要填寫offsetBeg和offsetEnd // 進行計算offset的時候,需要知道當前文件光標的位置的,由于當下使用的DataInputStream不方便直接獲取到文件光標 //因此就需要手動計算出文件光標 message.setOffsetBeg(currentOffset + 4); message.setOffsetEnd(currentOffset + 4 + messageSize); currentOffset += (4 + messageSize); messages.add(message); } }catch(EOFException e){ //這個catch不是處理異常,而是處理正常的業務邏輯,文件讀取到末尾的時候,會被readInt拋出這個異常 // 這個catch異常中不需要做任何特殊處理,只是代表我們的文件是正常讀取結束了 System.out.println("[MessageFileManager] 恢復Message數據完成了"); } } return messages;
}
一般情況下,異常表示的是出乎意料的事情,異常的定義是正常業務邏輯之外的事情,預期之外的事情,出乎意料的事情,


GD32VF103 MCU架構了解)







 - PWM調制模擬)






)

