下降路徑最小和
題目鏈接:
931. 下降路徑最小和 - 力扣(LeetCode)
題目描述:
給你一個?n x n?的?方形?整數數組?matrix?,請你找出并返回通過?matrix?的下降路徑?的?最小和?。
下降路徑?可以從第一行中的任何元素開始,并從每一行中選擇一個元素。在下一行選擇的元素和當前行所選元素最多相隔一列(即位于正下方或者沿對角線向左或者向右的第一個元素)。具體來說,位置?(row, col)?的下一個元素應當是?(row + 1, col - 1)、(row + 1, col)?或者?(row + 1, col + 1)?。
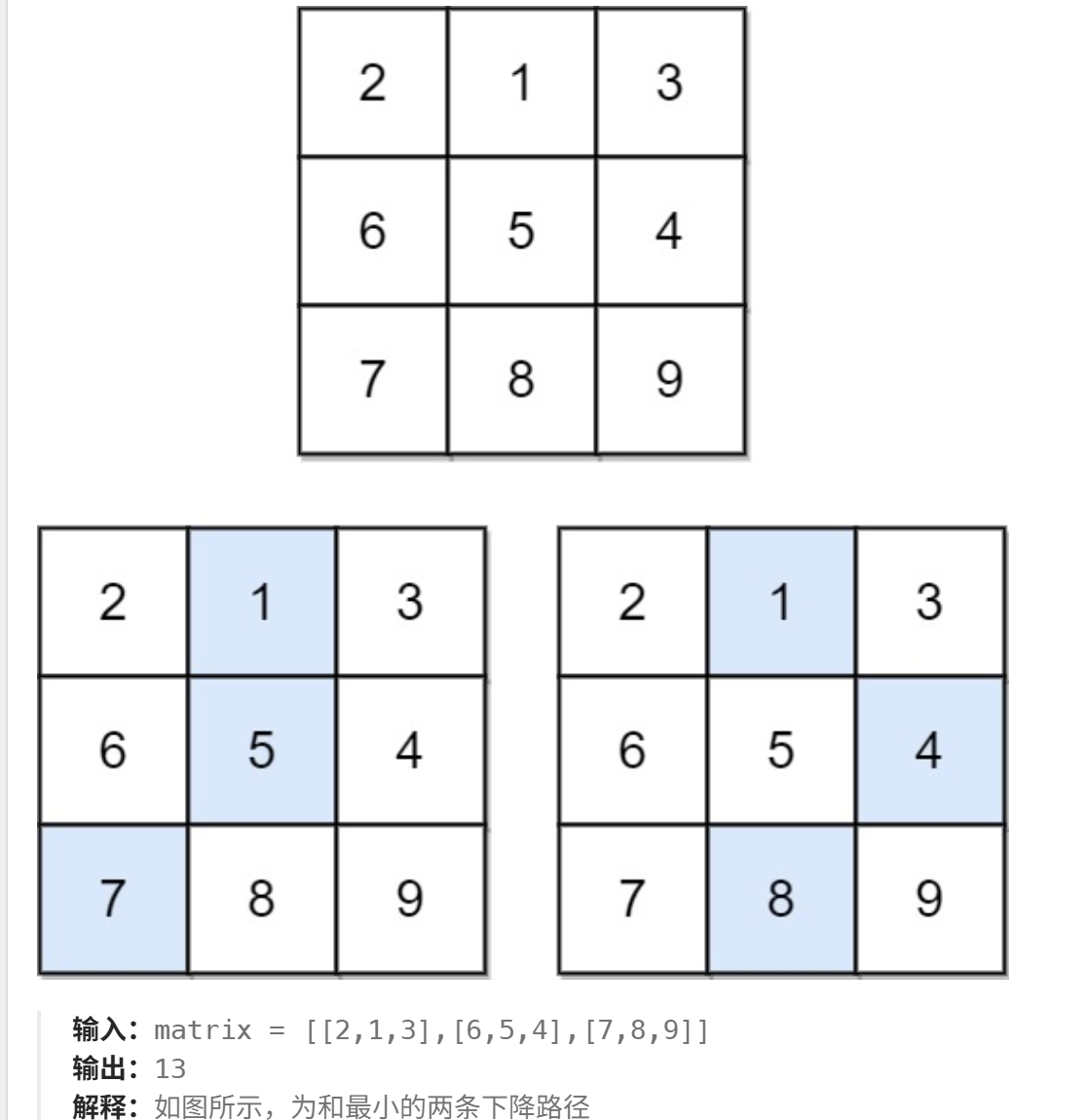
n == matrix.length == matrix[i].length1 <= n <= 100-100 <= matrix[i][j] <= 100
解題思路
這道題算比較簡單的一道動態規劃問題
我們定義一個同樣大小的 dp 數組,dp[i][j] 表示從矩陣的第一行出發,到達 matrix[i][j] 這個位置的最小下落路徑和。
dp數組的初始化這里沒有什么要求,
basecase為:
- 對于第一行(
i = 0),到達matrix[0][j]的最小路徑和就是它自身的值,因為它是路徑的起點。 - 因此,初始化
dp[0][j] = matrix[0][j]對于所有j從 0 到n-1。
這里的狀態轉移方程也比較明顯,題目中提示的比較明顯,從下面這幅圖中應該也能看出來,橙色格子的值只可能和三個藍色的格子有關,但是這個狀態轉移要考慮一下邊界 j == 0 或者j == n的情況。
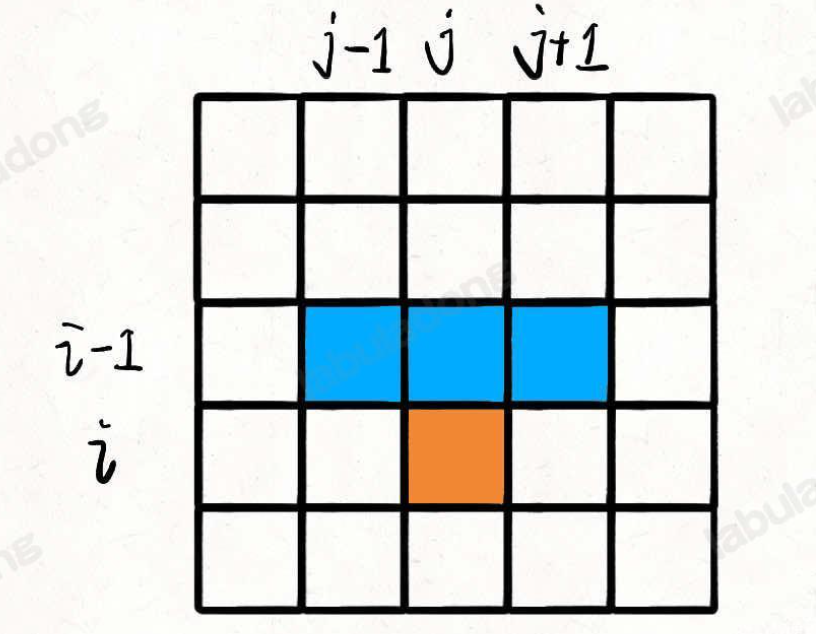
代碼實現
#include<bits/stdc++.h>
using namespace std;int minFallingPathSum(vector<vector<int>>& matrix) {int n = matrix.size();//這道題目對dp數組整體初始化沒要求,不需要初始化為一個極大值/極小值vector<vector<int>> dp(n, vector<int>(n, 0));//basecase初始化for(int i=0; i<n; i++){dp[0][i] = matrix[0][i];}for(int i=1; i<n; i++){for(int j=0; j<n; j++){if(j == 0){dp[i][j] = min(dp[i-1][j]+matrix[i][j], dp[i-1][j+1]+matrix[i][j]);}else if(j == n-1){dp[i][j] = min(dp[i-1][j-1]+matrix[i][j], dp[i-1][j]+matrix[i][j]);}else{dp[i][j] = min(dp[i-1][j+1]+matrix[i][j], min(dp[i-1][j-1]+matrix[i][j], dp[i-1][j]+matrix[i][j]) );}}}int min_length_val = INT_MAX;for(int i=0; i<n; i++){min_length_val = min(min_length_val, dp[n-1][i]);}return min_length_val;
}int main(){vector<vector<int>> matrix = {{2, 1, 3},{6, 5, 4},{7, 8, 9}};cout << "minFallingPathSum: " << minFallingPathSum(matrix);return 0;
}關于dp數組初始化問題的解釋
在上面下降路徑最小和這個問題中,我們說對于dp數組整體初始化的值沒有要求。
只需要對dp數組的第一行賦值matrix的第一行(因為這里dp數組的第一行代表著是basecase)。
所以在下降路徑最小和這道動態規劃問題中,我們的初始化部分只對basecase對應的dp做了賦值,其他非基本情況狀態對應的dp狀態沒有設置。
在上一篇dp文章中的零錢兌換和最長遞增子序列問題中,我們還需要專門考慮設計整個dp數組的初始化元素值。這道題為什么就不需要呢?別急,下面我就將來解釋一下。
動態規劃介紹,零錢兌換,最長遞增子序列-CSDN博客
在很多動態規劃問題中,我們確實需要將 dp 數組初始化為一個特定的值(例如,求最小值時初始化為 INT_MAX,求最大值時初始化為 INT_MIN,或者根據問題初始化為 0,1 或 -1 來表示狀態是否可達/已計算)等。這是因為:
- 表示不可達或未計算的狀態: 有些 DP 問題中,某些狀態可能從其他狀態無法達到,或者在計算某個狀態時,其依賴的前置狀態還沒有被計算。使用一個特殊值(如
INT_MAX或 -1)可以明確區分這些狀態。
? - 確保取 min/max 操作的正確性: 如果我們要求最小值,并且依賴的狀態還沒計算(或者不可達),但其初始值為 0,那么
min(當前值, 0)可能會錯誤地取到 0,從而影響后續計算。初始化為INT_MAX可以保證任何一個實際有效的路徑和都會小于INT_MAX,從而被正確選中。
但是,在這個特定的“最小下落路徑和”問題中,使用默認的 0 初始化是可行的,且不會影響結果的正確性。原因如下:
- 嚴格的依賴關系和計算順序: 代碼的循環結構是從
i = 1開始逐行向下計算dp[i][j]的值。計算dp[i][j]時,它只依賴于dp數組中第i-1行的值 (dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1])。 - 保證依賴值已被正確計算: 當代碼執行到計算第
i行時,它所依賴的第i-1行的所有dp值已經在前一個外層循環迭代 (i-1) 中被正確計算并存儲過了(要么是 Base Case,要么是基于更早行的計算)。 - 未使用的值為 0 不影響: 當我們計算
dp[i][j]時,雖然dp數組中第i行及之后行的值可能還是默認的 0,但這些值并沒有被用于當前dp[i][j]的計算。只有第i-1行的值被讀取,而這些值在前一步已經保證是正確的了。
簡而言之,在這個問題中,每一個 dp[i][j] 的計算都嚴格依賴于前一行已經計算好的值。因此,未被計算到的位置的初始值(在這里是 0)并不會被錯誤地用來影響當前或后續的正確計算。狀態轉移方程會作用在每一個dp狀態上面,每一個dp狀態都會運用狀態轉移方程進行計算,所以也就不需要對dp數組來進行初始化。
所以本道題中只需要basecase,整個dp數組的初始化不需要。
上面說了一堆,我想表達的是什么呢?
我這里主要想強調一下dp問題中關于dp數組的初始化問題,希望上面做出的一個淺淺的總結,可以幫助大家對于dp問題中dp數組初始化問題有一個更加深入的了解,寫代碼的時候思路更加清晰,結構更加嚴謹。
大多數情況下我們突出強調的都是狀態定義和尋找狀態轉移方程,毫無疑問這兩個問題確實是最重要的,導致我們可能很多時候會疏忽dp數組元素整體初始化這個事情,但dp數組初始化也有著對應的門道。關于什么時候需要dp數組整體初始化?or整體數組應該初始化成什么值?這些問題,也并不是能用結論直接總結出來的。
我們在拿到一個編程題目之后,需要好好想一下是否需要對dp數組進行整體初始化,以及如果整體初始化的話,初始化的值是什么?
提升的方式還是前面說的:多刷,多學,多練!!!
引入狀態壓縮(降低空間復雜度)
上面代碼實現定義了一個n*n的dp數組保存狀態,空間復雜度為O(n^2),由于當前dp行的狀態只依賴于上一行dp的狀態,我們可以進行狀態壓縮(空間優化)。
如果允許我們來修改原二維數組matrix的話,那么其實完全可以將這里對于dp數組的操作轉變到對于matrix數組的操作。這樣空間復雜度為 O(1)。
如果不能對原二維數組matrix的進行修改的話,我們可以用兩個一維數組 prev_dp 和 curr_dp,每個大小為n來實現狀態壓縮。這樣的空間復雜度為O(N)。
prev_dp存儲上一行的最小路徑和。curr_dp存儲當前行的最小路徑和。
計算完當前行后,將 curr_dp 的內容復制到 prev_dp,或者交換兩個數組的指針,為下一行的計算做準備。
#include<bits/stdc++.h>
using namespace std;int minFallingPathSum(vector<vector<int>>& matrix) {int n = matrix.size();// prev_dp 存儲上一行的最小路徑和vector<int> prev_dp = matrix[0];// curr_dp 存儲當前行的最小路徑和vector<int> curr_dp(n);for(int i=1; i<n; i++){for(int j=0; j<n; j++){if(j == 0){curr_dp[j] = min(prev_dp[j]+matrix[i][j], prev_dp[j+1]+matrix[i][j]);}else if(j == n-1){curr_dp[j] = min(prev_dp[j-1]+matrix[i][j], prev_dp[j]+matrix[i][j]);}else{curr_dp[j] = min(prev_dp[j+1]+matrix[i][j], min(prev_dp[j-1]+matrix[i][j], prev_dp[j]+matrix[i][j]) );}}prev_dp = curr_dp; //將當前行的數據變成下一行的“上一行”數據}int min_length_val = INT_MAX;for(int i=0; i<n; i++){min_length_val = min(min_length_val, curr_dp[i]);}return min_length_val;
}int main(){vector<vector<int>> matrix = {{2, 1, 3},{6, 5, 4},{7, 8, 9}};cout << "minFallingPathSum: " << minFallingPathSum(matrix);return 0;
}對于狀態壓縮,降低空間復雜度一般是代碼編寫完成,確保可以完成正常功能之后,最后一步才考慮的事情。通常的空間復雜度優化可以達到降維的效果。但是也不是所有的dp問題都可以優化空間復雜度。
空間優化要求我們對于整個dp數組的狀態填充有著比較深刻的了解。
單詞拆分
題目鏈接:
139. 單詞拆分 - 力扣(LeetCode)
題目描述:
給你一個字符串?s?和一個字符串列表?wordDict?作為字典。如果可以利用字典中出現的一個或多個單詞拼接出?s?則返回?true。
注意:不要求字典中出現的單詞全部都使用,并且字典中的單詞可以重復使用。
示例 1:
輸入: s = "leetcode", wordDict = ["leet", "code"] 輸出: true 解釋: 返回 true 因為 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
輸入: s = "applepenapple", wordDict = ["apple", "pen"] 輸出: true 解釋: 返回 true 因為 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。注意,你可以重復使用字典中的單詞。
示例 3:
輸入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 輸出: false
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s?和?wordDict[i]?僅由小寫英文字母組成wordDict?中的所有字符串?互不相同
回溯法解題思路
看到這個題目是要求一個可行解,我首先想到可以使用回溯法,首先這個題目看上去就是一個元素可重復選的排列類問題,很適合使用回溯法來完成。
除此之外動態規劃類問題一般都是求最優解(一般有多個可行解),像這種判斷是否可以組和成功的問題不是很常見。
所以綜合考慮之下,我打算先使用回溯法來試試看。
回溯法實現
很標準的一道無重復元素的排列問題,使用的是經典的回溯法的模板,然后我們額外使用了一個find_flag的變量,用來標識是否找到了一個合法的組和,如果找到了說明以及找到問題的解,那么我們便可以憑借這個變量來進行快速的函數遞歸調用的返回。
#include<bits/stdc++.h>
using namespace std;void backtrack(bool& find_flag, string& track, string& s, vector<string>& wordDict);bool wordBreak(string s, vector<string>& wordDict) {string track;bool find_flag = false;backtrack(find_flag, track, s, wordDict);return find_flag;
}void backtrack(bool& find_flag, string& track, string& s, vector<string>& wordDict){if(track == s){find_flag = true;return;}if(track.size() > s.size()){return;}for(int i=0; i<wordDict.size(); i++){//做選擇track += wordDict[i];//下一層決策樹backtrack(find_flag, track, s, wordDict);if(find_flag == true){return;}//撤銷選擇track.erase(track.size() - wordDict[i].size(), wordDict[i].size());// track -= wordDict[i];}}int main(){string s = "leedcode";vector<string> wordDict = {"leed", "abc", "a", "code"};cout << "isfind: " << wordBreak(s, wordDict);return 0;
}這個代碼取得得效果不是很理想,方法是正確的,但是由于算法的效率問題導致通過不了全部的樣例,最終結果如下:
32 / 47?個通過的測試用例
想來確實正常,因為回溯法本來就不是什么高效的算法,并且這里我們還沒有進行剪枝操作,自然時間過不去是合理的。
回溯法在最壞情況下的時間復雜度確實是指數型的。它的效率很大程度上依賴于剪枝的效果,而剪枝的效果往往難以保證能將復雜度降到多項式級別。
回溯法的總時間復雜度是 (搜索樹中被訪問的節點數量)乘以 (每個節點上進行的計算開銷)
所以回溯法時間復雜度,主要看的就是決策樹的節點數。
本題中每個節點會對應下一層決策樹的wordDict.size()個節點,題目說1 <= wordDict.length <= 1000,那么上一層決策樹的每個節點最多會對應下一層決策樹的1000個節點。
然后我們再來看決策樹的高度,1 <= s.length <= 300,每條邊選擇一個子字符串。
回溯算法時間復雜度很難很難計算,這里我們就粗糙地認為最壞情況為1000^300(當然實際上不可能有這么多節點)。
下一步我們嘗試來進行剪枝優化~
回溯法+前綴剪枝
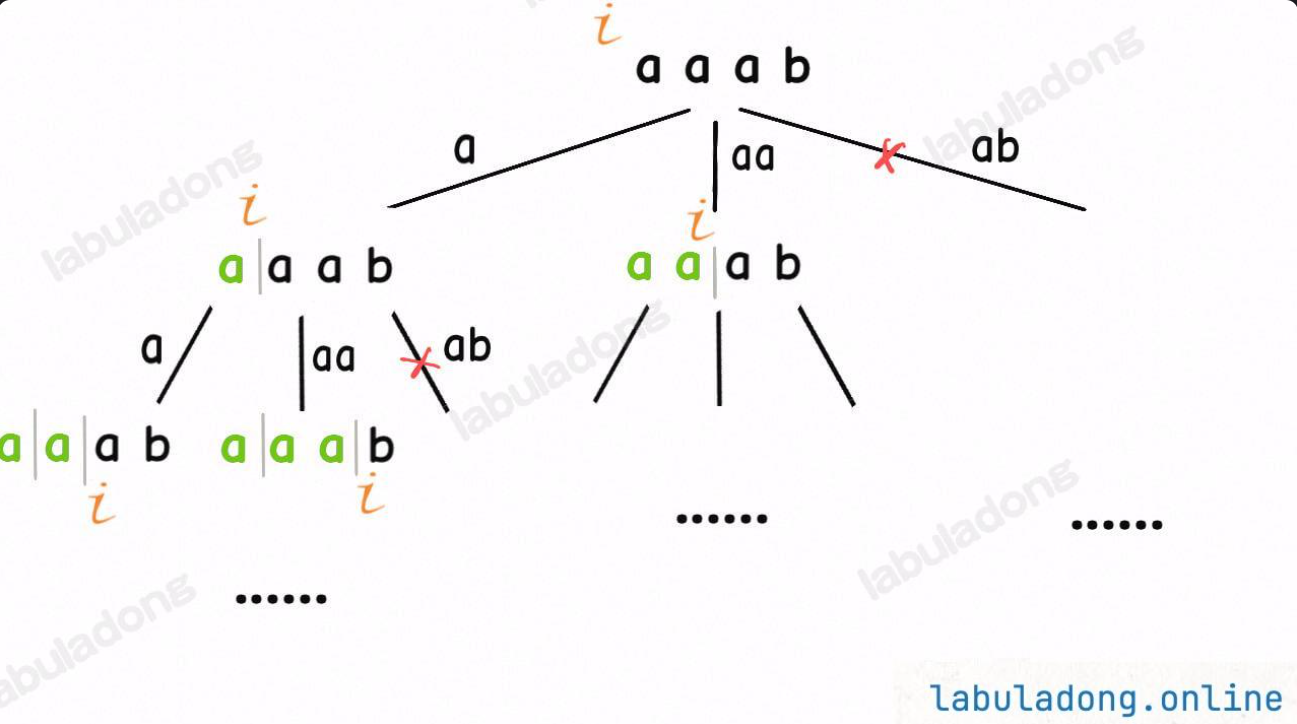
通過上面這幅圖,我們可以看出來,只有在前綴匹配的情況下,我們才需要接著對于這個決策樹進行匹配,所以可以用track中保存的前綴與s前面部分做對比,這樣對于前綴不匹配的枝條就可以直接砍掉!
事實上對于track中的前綴來說,我們實際上只需要檢查決策樹當前層次要加入的wordDict中的字符串wordDict[i]是否和s中的某部分匹配就可以了,因為track中的前面部分一定是匹配成功了s的前綴的才會加入到track,所以實際上我們只需要,將想要加入到track中的這部分前綴與字符串s中對應部分進行匹配就可以。
我們需要加入的邏輯只有一點點,其余代碼和上面回溯法一樣:
//根據前綴是否匹配來進行剪枝
if( wordDict[i] != s.substr(track.size(), wordDict[i].size()) ){continue;
}完整代碼實現如下:
#include<bits/stdc++.h>
using namespace std;void backtrack(bool& find_flag, string& track, string& s, vector<string>& wordDict);bool wordBreak(string s, vector<string>& wordDict) {string track;//保存當前的字符串路徑bool find_flag = false;//當找到一個解后,可以借助find_flag變量快速退出backtrack函數backtrack(find_flag, track, s, wordDict);return find_flag;
}void backtrack(bool& find_flag, string& track, string& s, vector<string>& wordDict){if(track == s){find_flag = true;return;}if(track.size() > s.size()){return;}for(int i=0; i<wordDict.size(); i++){//根據前綴是否匹配來進行剪枝if( wordDict[i] != s.substr(track.size(), wordDict[i].size()) ){continue;}//做選擇track += wordDict[i];//做下一層決策backtrack(find_flag, track, s, wordDict);if(find_flag == true){return;}//撤銷選擇track.erase(track.size() - wordDict[i].size(), wordDict[i].size());// track -= wordDict[i];}}int main(){string s = "leedcode";vector<string> wordDict = {"leed", "abc", "a", "code"};cout << "isfind: " << wordBreak(s, wordDict);return 0;
}這個代碼確實進行了一定的剪枝優化,但是最終的結果為
35?/ 47?個通過的測試用例
還是由于算法的效率問題導致通過不了全部的樣例,不過不要氣餒,加上了上面的剪枝優化我們已經多通過了3個樣例,勝利就在眼前!!!!!
回溯法+剪枝+記憶化
為什么仍會超時&解決方案
說實話,你要是讓我想,我一個人是想不到可以用到記憶化的方式來繼續對于這個問題進行優化的。可能下面的記憶化有一點難理解,但是這個優化的思路是非常值得借鑒與學習的!!!
上面前綴剪枝的代碼其實還存在大量的重復計算。
首先,讓我們明確在這個 Word Break 問題中的子問題是什么?對于回溯函數 backtrack(find_flag, track, s, wordDict),它的核心任務是判斷:能否將字符串 s 的剩余部分(也就是從 track.size() 索引開始到末尾的部分)通過字典中的單詞完全匹配完?
所以,一個子問題可以被定義為:對于原始字符串 s 的子串 s[i...s.size()-1](從索引 i 開始到末尾),能否將其分割成字典中的單詞序列? 在我的代碼中,track.size() 實際上就代表了這個起始索引 i。
假設:wordDict = ["apple", "pen", "applepen"]。
初始狀態: track = "",需要匹配 s[0...12] ("applepenapple")。
無論是通過路徑 "apple" + "pen" 還是通過路徑 "applepen",我們都到達了完全相同的狀態:track 是 "applepen",需要解決的子問題是判斷 s 從索引 8 開始的剩余部分 "apple" 能否被分割。
這就是重疊子問題:同一個子問題(能否匹配 s[i...s.size()-1])在回溯樹的不同分支中被多次遇到和重復計算。
想必你這時候應該就知道了為什么加上了剪枝之后代碼仍然超時叭,嘻嘻!
剪枝解決的是: 在一個給定的狀態(例如 track 的長度確定后),只嘗試那些 立即 匹配當前剩余部分前綴的字典單詞。
剪枝不解決的是: 即使剪枝后,你仍然可能通過 不同的歷史路徑 到達 同一個中間狀態(同一個 track 長度,對應同一個子問題),然后重復計算該子問題的解。
為什么會導致 TLE?
當字符串
s很長,并且字典中的單詞能夠以多種方式組合形成s的不同前綴時,回溯樹會非常龐大。即使有剪枝,由于重疊子問題的存在,大量的計算是重復的。想象一個字符串s全部由 'a' 組成,字典是["a", "aa", "aaa"]。計算s前綴 "aaaaa" 是否可拆分,可能需要判斷 "aaaa" + "a","aaa" + "aa","aa" + "aaa","a" + "aaaa" 等,這里的 "aaaa", "aaa", "aa" 等都是重疊子問題,會被反復計算。當s的長度達到幾百甚至上千,這種重復計算會導致調用棧過深且計算量呈指數級增長,最終超過時間限制。
?
如何解決重疊子問題?
- 記憶化搜索 (Memoization): 在你的回溯函數中,增加一個機制來存儲每個子問題(由起始索引
i定義)的結果。通常用一個數組或哈希表memo[i]來記錄s[i...s.size()-1]是否可分割的結果。在計算一個子問題前,先查找memo[i]。如果已經計算過,直接返回存儲的結果;否則,正常計算,并將結果存儲到memo[i]中。
? - 動態規劃 (Dynamic Programming): 構建一個布爾數組
dp,其中dp[i]表示s[0...i-1]是否可以被分割。通過迭代的方式,從dp[0](空字符串,通常為 true) 開始,計算dp[1], dp[2], ...直到dp[s.size()]。計算dp[i]時,遍歷所有可能的分割點j < i,檢查dp[j]是否為 true 并且s[j...i-1]是字典中的單詞。這種自底向上的方式天然避免了重復計算。
由于這里我們介紹的是回溯法,所以就在原本代碼上面加上記憶化來解決,后面會單獨介紹到使用dp的方案。?
代碼實現
#include<bits/stdc++.h>
using namespace std;void backtrack(unordered_set<string>& memo, bool& find_flag, string& track, string& s, vector<string>& wordDict);bool wordBreak(string s, vector<string>& wordDict) {string track;//保存當前的字符串路徑bool find_flag = false;//當找到一個解后,可以借助find_flag變量快速退出backtrack函數unordered_set<string> memo;//記錄以及驗證的,不可劃分匹配的剩余子串backtrack(memo, find_flag, track, s, wordDict);return find_flag;
}void backtrack(unordered_set<string>& memo, bool& find_flag, string& track, string& s, vector<string>& wordDict){if(track == s){find_flag = true;return;}if(track.size() > s.size()){return;}if(memo.count(s.substr(track.size()))==1 ){return;}for(int i=0; i<wordDict.size(); i++){//根據前綴來進行剪枝if( wordDict[i] != s.substr(track.size(), wordDict[i].size()) ){continue;}//做選擇track += wordDict[i];//做下一層決策backtrack(memo, find_flag, track, s, wordDict);if(find_flag == true){return;}//撤銷選擇track.erase(track.size() - wordDict[i].size(), wordDict[i].size());// track -= wordDict[i];}memo.insert(s.substr(track.size()));}int main(){string s = "leedcode";vector<string> wordDict = {"leed", "abc", "a", "code"};cout << "isfind: " << wordBreak(s, wordDict);return 0;
}substr函數的使用
本題中多次用到了substr函數,之前我確實用的不熟練,這里進行一下淺淺總結。
substr 是 C++ 中 string 類的一個非常常用的成員函數。它的作用是從當前字符串中提取一個子串并返回一個新的字符串。
substr主要有下面兩種常見的使用:
- substr(pos, count):從索引 pos 開始,取 count 個字符。
- substr(pos):從索引 pos 開始,取到字符串末尾。
注意:
- substr 方法不會修改原始字符串,它總是返回一個新的字符串對象。
? - 如果 pos 大于或等于當前字符串的長度 (size()),會拋出 out_of_range 異常。
? - 如果 pos + count 超過了當前字符串的長度,那么實際提取的字符數會少于 count,它會提取從 pos 到字符串末尾的所有字符。
由于本文比較長了,所以在下一篇文章中會講解到單詞拆分的dp法實現,以及會講到單詞拆分(二)
)



)

)




notificationManager.cancelAll)




![[PRO_A7] SZ501 FPGA開發板簡介](http://pic.xiahunao.cn/[PRO_A7] SZ501 FPGA開發板簡介)


)