引入
在過去的幾篇文章里,我們看到了大數據的流式處理系統是如何一步一步進化的。從最早出現的S4,到能夠做到“至少一次”處理的Storm,最后是能夠做到“正好一次”數據處理的MillWheel。我們會發現,這些流式處理框架,每一個都很相似,它們都采用了有向無環圖一樣的設計。但是在實現和具體接口上又很不一樣,每一個框架都定義了一個屬于自己的邏輯。
S4是無中心的架構,一切都是PE;Storm是中心化的架構,定義了發送數據的Spout和處理數據的Bolt;而MillWheel則更加復雜,不僅有Computation、Stream、Key這些有向無環圖里的邏輯概念,還引入了Timer、State這些為了持久化狀態和處理時鐘差異的概念。
和我們在大數據的批處理看到的不同,S4、Storm以及MillWheel其實是某一個數據處理系統,而不是MapReduce這樣高度抽象的編程模型。每一個流式數據處理系統各自有各自對于問題的抽象和理解, 很多概念不是從模型角度的“該怎么樣”抽象出來,而是從實際框架里具體實現的“是怎么樣”的角度,抽象出來的。
不過,我們也看到了這些系統有很多相似之處,它們都采用了有向無環圖模型,也都把同一個Key的數據在邏輯上作為一個單元進行抽象。隨著工業界對于流式數據處理系統的不斷研發和運用,到了2015年,仍然是Google,發表了今天我們要看的這一篇 The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing 論文。
數據流模型:一種在大規模、無界、無序數據處理中平衡正確性、延遲和成本的實用方法
摘要
無界、無序的全球規模數據集在日常業務中越來越常見(例如網絡日志、移動設備使用統計數據以及傳感器網絡數據)。與此同時,這些數據集的使用者產生了復雜的需求,除了對更快獲取結果的迫切渴望之外,還包括事件時間排序以及依據數據自身特征進行窗口化處理等。然而,實際情況是,對于這類輸入數據,永遠無法在正確性、延遲和成本的所有維度上都做到完全優化。因此,數據處理從業者面臨著如何調和這些看似相互矛盾的要求之間的矛盾這一難題,這往往導致出現各種各樣不同的實現方式和系統。
我們認為,為了應對現代數據處理中這些不斷演變的需求,有必要從根本上轉變方法。作為一個領域,我們不應再試圖將無界數據集整理成最終會變得完整的有限信息池,而應基于這樣一種假設來開展工作:我們永遠不知道是否或何時已經看到了所有數據,只知道會有新數據到來,舊數據可能會被撤回,而使這個問題變得易于處理的唯一方法是通過有原則的抽象,讓從業者能夠在感興趣的維度(正確性、延遲和成本)上做出合適的權衡選擇。
在本文中,我們提出了這樣一種方法 —— 數據流模型 1 ,同時詳細審視了它所支持的語義,概述了指導其設計的核心原則,并通過促成其發展的實際經驗對該模型本身進行了驗證。
1: 我們使用 “數據流模型” 這一術語來描述谷歌云數據流(Google Cloud Dataflow [20])的處理模型,該模型基于來自 FlumeJava [12] 和 MillWheel [2] 的技術。
?1. 引言
現代數據處理是一個既復雜又令人興奮的領域。從 MapReduce [16] 及其后繼者(如 Hadoop [4]、Pig [18]、Hive [29]、Spark [33])所實現的規模處理,到 SQL 領域內關于流處理的大量研究工作(如查詢系統 [1, 14, 15]、窗口化處理 [22]、數據流 [24]、時間域 [28]、語義模型 [9]),再到最近在低延遲處理方面的嘗試,如 Spark Streaming [34]、MillWheel 和 Storm [5],現代數據使用者在將大規模無序數據整理成具有更高價值的有序結構方面擁有強大的能力。然而,現有的模型和系統在許多常見用例中仍存在不足。
考慮一個初始示例:一家流媒體視頻提供商希望通過展示視頻廣告來實現其內容的貨幣化,并根據廣告觀看量向廣告商收費。該平臺支持內容和廣告的在線和離線觀看。視頻提供商想知道每天向每個廣告商收取多少費用,以及有關視頻和廣告的匯總統計信息。此外,他們希望能高效地對大量歷史數據進行離線實驗。
廣告商 / 內容提供商想知道他們的視頻被觀看的頻率和時長,與哪些內容 / 廣告一起被觀看,以及受眾的人口統計信息。他們還想知道自己被收取 / 支付了多少費用。他們希望盡快獲得所有這些信息,以便盡可能實時地調整預算和出價、改變目標定位、調整廣告活動并規劃未來方向。由于涉及資金,正確性至關重要。
盡管數據處理系統本質上很復雜,但視頻提供商希望有一個簡單且靈活的編程模型。最后,由于互聯網極大地擴展了任何可以依托其架構開展的業務的覆蓋范圍,他們還需要一個能夠處理全球規模離散數據的系統。
對于這樣一個用例,必須計算的信息本質上是每次視頻觀看的時間和時長、觀看者是誰以及與哪個廣告或內容配對(即每個用戶、每次視頻觀看會話)。從概念上講,這很直接,但現有的模型和系統都無法滿足上述要求。
諸如 MapReduce(及其 Hadoop 變體,包括 Pig 和 Hive)、FlumeJava 和 Spark 等批處理系統,存在在處理前將所有輸入數據收集到一個批次中所固有的延遲問題。對于許多流處理系統而言,尚不清楚它們在大規模情況下如何保持容錯能力(Aurora [1]、TelegraphCQ [14]、Niagara [15]、Esper [17])。那些提供可擴展性和容錯性的系統在表達能力或正確性方面有所欠缺。許多系統缺乏提供精確一次性語義的能力(Storm、Samza [7]、Pulsar [26]),這影響了正確性。其他一些系統則根本缺乏窗口化所需的時間原語 2 (Tigon [11]),或者提供的窗口化語義僅限于基于元組或處理時間的窗口(Spark Streaming [34]、Sonora [32]、Trident [5])。大多數提供基于事件時間窗口化的系統,要么依賴排序(SQLStream [27]),要么在事件時間模式下窗口觸發 3 語義有限(Stratosphere/Flink [3, 6])。CEDR [8] 和 Trill [13] 值得注意,因為它們不僅通過標點符號 [30, 28] 提供了有用的觸發語義,還提供了一個與我們在此提出的總體增量模型非常相似的模型;然而,它們的窗口化語義不足以表達會話,并且其周期性標點符號對于第 3.3 節中的某些用例來說是不夠的。MillWheel 和 Spark Streaming 都具有足夠的可擴展性、容錯性和低延遲,可以作為合理的基礎,但缺乏使事件時間會話計算變得簡單直接的高級編程模型。
據我們所知,唯一支持像會話這樣的非對齊窗口 4 高級概念的可擴展系統是 Pulsar,但如上文所述,該系統無法保證正確性。Lambda 架構 [25] 系統可以滿足許多期望的要求,但由于必須構建和維護兩個系統,在簡單性方面有所不足。Summingbird [10] 通過在單個接口后抽象底層批處理和流處理系統來改善這種實現復雜性,但這樣做對可以執行的計算類型施加了限制,并且仍然需要兩倍的操作復雜性。
2:這里 “windowing” 指窗口化操作,在數據處理中常用于按特定時間或數據特征對數據進行分組處理。
這里我們所說的窗口化,是指如 Li [22] 中所定義的那樣,即將數據切分成有限的數據塊進行處理。更多內容見 1.2 節。
3:“window triggering” 指窗口觸發,決定何時基于窗口內的數據進行計算或輸出結果。這里我們所說的觸發,是指在分組操作時促使特定窗口產生輸出。更多內容見 2.3 節。
4:“unaligned windows” 指非對齊窗口,與基于固定時間間隔等規則對齊的窗口相對,非對齊窗口可根據數據自身特征等靈活定義。這里我們所說的非對齊窗口,是指并非跨越整個數據源,而僅跨越其一個子集的窗口,例如按用戶劃分的窗口。這本質上是 Whiteneck [31] 中提出的幀(frames)概念。更多內容見 1.2 節。
這些缺點并非無法解決,而且正在積極開發的系統很可能在適當的時候克服它們。但我們認為,上述所有模型和系統(CEDR 和 Trill 除外)的一個主要缺點是,它們將輸入數據(無論是否無界)視為在某個時刻會變得完整的東西。我們認為,當當今龐大且高度無序的數據集的現實與用戶所要求的語義和及時性發生沖突時,這種方法從根本上就是有缺陷的。我們還認為,任何一種方法,若要在當今如此多樣和繁雜的一系列用例(更不用說那些即將出現的用例)中具有廣泛的實用價值,就必須提供簡單而強大的工具,以便根據手頭特定用例平衡正確性、延遲和成本。
最后,我們認為是時候超越由執行引擎決定系統語義的主流思維模式了;經過合理設計和構建的批處理、微批處理和流處理系統都能提供同等程度的正確性,并且這三種方式如今在無界數據處理中都得到了廣泛應用。在一個具有足夠通用性和靈活性的模型之下進行抽象,我們相信執行引擎的選擇可以僅僅基于它們之間實際存在的差異:即延遲和資源成本方面的差異。
從這個角度來看,本文在概念上的貢獻是一個單一的統一模型,該模型:
- 允許在無界、無序的數據源上,根據數據自身特征進行窗口化,計算按事件時間 5 排序的結果,并且正確性、延遲和成本可在廣泛的組合范圍內進行調整。
- 從四個相關維度分解管道實現,提供清晰性、可組合性和靈活性:
- 正在計算什么結果。
- 在事件時間的哪個點進行計算。
- 在處理時間的何時將結果具體化。
- 早期結果與后期細化結果之間的關系。
- 將數據處理的邏輯概念與底層物理實現分離,使得批處理、微批處理或流處理引擎的選擇僅僅成為正確性、延遲和成本方面的選擇。
具體而言,這一貢獻通過以下方式得以實現:
- 一個窗口化模型,支持非對齊的事件時間窗口,并提供一個簡單的 API 用于創建和使用這些窗口(第 2.2 節)。
- 一個觸發模型,將結果的輸出時間與管道的運行時特征綁定,并帶有一個強大且靈活的聲明式 API,用于描述所需的觸發語義(第 2.3 節)。
- 一個增量處理模型,將撤回和更新集成到上述窗口化和觸發模型中(第 2.3 節)。
- 在 MillWheel 流處理引擎和 FlumeJava 批處理引擎之上對上述內容進行可擴展的實現,并為 Google Cloud Dataflow 進行外部重新實現,包括一個與運行時無關的開源軟件開發工具包(SDK)[19](第 3.1 節)。
- 一組指導該模型設計的核心原則(第 3.2 節)。
- 簡要討論我們在谷歌進行大規模、無界、無序數據處理的實際經驗,這些經驗推動了該模型的開發(第 3.3 節)。
最后值得注意的是,這個模型并沒有什么神奇之處。在現有的強一致性批處理、微批處理、流處理或 Lambda 架構系統中,那些在計算上不切實際的事情,在這個模型中依然如此,CPU、內存和磁盤的固有約束依然存在。它所提供的是一個通用框架,允許以一種獨立于底層執行引擎的方式相對簡單地表達并行計算,同時還能夠根據手頭數據和資源的實際情況,為任何特定問題領域精確調整延遲和正確性的程度。從這個意義上說,它是一個旨在便于構建實用的大規模數據處理管道的模型。
5:事件時間(event time)是指數據所描述事件實際發生的時間,與數據進入系統被處理的時間(處理時間,processing time)相對。在流數據處理中,區分這兩種時間概念對于準確處理和分析數據很重要。
所謂事件時間,我們指的是事件實際發生的時間,而非事件被處理的時間。更多內容見 1.3 節。
 ?
?
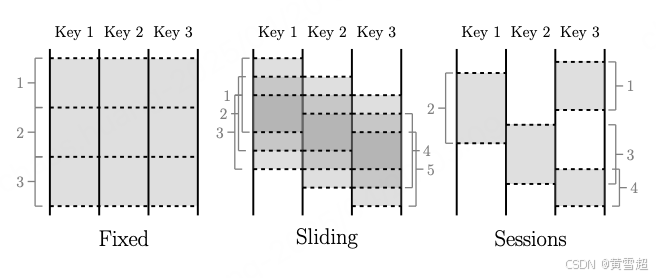
圖 1:常見的窗口化模式
1.1 無界 / 有界與流處理 / 批處理
在描述無限 / 有限數據集時,我們更傾向于使用 “無界 / 有界” 這兩個術語,而非 “流處理 / 批處理”,因為后一組術語暗示了對特定類型執行引擎的使用。實際上,自無界數據集誕生以來,人們就一直通過重復運行批處理系統來處理它們,而且設計良好的流處理系統完全有能力處理有界數據。
從模型的角度來看,流處理或批處理的區分在很大程度上并不重要,因此我們僅將這些術語用于描述運行時執行引擎。
1.2 窗口化
窗口化 [22] 是將數據集切分成有限的數據塊,以便作為一個組進行處理。在處理無界數據時,某些操作需要窗口化(在大多數形式的分組中劃定有限邊界,如聚合、外連接、有時限的操作等),而其他操作則不需要(過濾、映射、內連接等)。對于有界數據,窗口化本質上是可選的,不過在許多情況下它在語義上仍然是一個有用的概念(例如,對先前計算的無界數據源的部分進行大規模回填更新)。窗口化實際上始終是基于時間的;雖然許多系統支持基于元組的窗口化,但這本質上是在一個邏輯時間域上的基于時間的窗口化,其中按順序排列的元素具有依次遞增的邏輯時間戳。窗口可以是對齊的,即在相關的時間窗口內應用于所有數據;也可以是非對齊的,即在給定的時間窗口內僅應用于數據的特定子集(例如,按鍵劃分)。圖 1 突出顯示了處理無界數據時遇到的三種主要窗口類型。
固定窗口(有時稱為滾動窗口)由靜態窗口大小定義,例如每小時窗口或每天窗口。它們通常是對齊的,即每個窗口在相應的時間段內應用于所有數據。為了將窗口完成的負載在時間上均勻分布,有時會通過將每個鍵的窗口相位偏移某個隨機值來使其不對齊。
滑動窗口由窗口大小和滑動周期定義,例如每分鐘開始的每小時窗口。周期可能小于窗口大小,這意味著窗口可能會重疊。滑動窗口通常也是對齊的;盡管在圖中繪制的方式給人一種滑動的感覺,但圖中的所有五個窗口將應用于所有三個鍵,而不僅僅是窗口 3。固定窗口實際上是滑動窗口的一種特殊情況,即窗口大小等于周期。
會話窗口是捕獲數據子集上某段活動時間的窗口,在這種情況下是按鍵劃分。通常,它們由超時間隔定義。在小于超時時間的時間段內發生的任何事件都被分組到一個會話中。會話窗口是非對齊窗口。例如,窗口 2 僅應用于鍵 1,窗口 3 僅應用于鍵 2,窗口 1 和窗口 4 僅應用于鍵 3。
1.3 時間域
在處理與時間事件相關的數據時,有兩個固有的時間域需要考慮。盡管在各種文獻(特別是時間管理 [28] 和語義模型 [9],但也包括窗口化 [22]、無序處理 [23]、標點符號 [30]、心跳 [21]、水位線 [2]、幀 [31])中都有涉及,但在腦海中清晰明確這些概念后,2.3 節中的詳細示例會更容易理解。我們關注的兩個時間域是:
- 事件時間:即事件本身實際發生的時間,也就是事件發生時(無論哪個系統生成該事件)系統時鐘時間的記錄。
- 處理時間:即事件在管道處理過程中任何給定點被觀測到的時間,也就是根據系統時鐘的當前時間。請注意,我們不對分布式系統內的時鐘同步做任何假設。
給定事件的事件時間本質上永遠不會改變,但隨著每個事件在管道中流動且時間不斷向前推進,其處理時間會不斷變化。在穩健地分析事件發生的時間背景時,這是一個重要的區別。
在處理過程中,所使用系統的實際情況(通信延遲、調度算法、處理時間、管道序列化等)會導致這兩個時間域之間存在固有的、動態變化的偏差。全局進度指標,如標點符號或水位線,為可視化這種偏差提供了一種好方法。就我們的目的而言,我們將考慮類似 MillWheel 的水位線,它是管道已處理事件時間的下限(通常通過啟發式方法確定 6 )。正如我們上面已經明確指出的,完整性的概念通常與正確性不兼容,因此我們不會依賴水位線來確保完整性。然而,它們確實提供了一個有用的概念,即系統何時認為在事件時間的某個給定點之前的所有數據都可能已被觀測到,因此不僅在可視化偏差方面有應用,還在監測整個系統的健康狀況和進展方面有應用,并且在做出不需要完全準確的關于進展的決策時也有應用,例如基本的垃圾回收策略。
6:對于大多數現實世界中的分布式數據集,系統缺乏足夠的信息來確定 100% 準確的水位線。例如,在視頻會話用例中,考慮離線觀看情況。如果有人帶著移動設備進入荒野,系統實際上無法知曉他們何時會回到有網絡的地方,重新建立連接,并開始上傳那段時間的視頻觀看數據。因此,大多數水位線必須根據有限的可用信息通過啟發式方法來定義。對于像日志文件這樣能提供有關未觀測數據元數據的結構化輸入源,我們發現這些啟發式方法非常準確,因此在許多用例中作為完成度估計實際上很有用。此外,重要的是,一旦通過啟發式方法確定了水位線,它就可以像標點符號一樣準確地在管道的其余部分向下游傳播,盡管這個整體指標本身仍然是基于啟發式的。
在理想情況下,時間域偏差始終為零;我們會在所有事件發生時立即處理它們。然而,現實并非如此理想,我們最終得到的情況往往更像圖 2。大約從 12:00 開始,隨著管道滯后,水位線開始偏離實時時間,在 12:02 左右又回到接近實時時間,然后到 12:03 時又明顯滯后。這種偏差的動態變化在分布式數據處理系統中非常常見,并且在定義提供正確、可重復結果所需的功能方面將發揮重要作用。
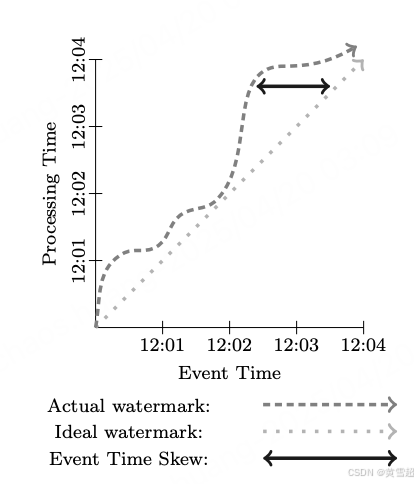
圖 2:時間域偏差
2. 數據流模型
在本節中,我們將定義該系統的形式化模型,并解釋為什么其語義具有足夠的通用性,可以涵蓋標準的批處理、微批處理和流處理模型,以及 Lambda 架構的混合流批處理語義。對于代碼示例,我們將使用 Dataflow Java SDK 的簡化變體,它本身是 FlumeJava API 的演進版本。
2.1 核心原語
首先,讓我們考慮經典批處理模型中的原語。Dataflow SDK 有兩個核心轉換操作,作用于流經系統的(鍵,值)對 7 :
- ParDo:用于通用并行處理。每個要處理的輸入元素(其本身可能是一個有限集合)被提供給一個用戶定義的函數(在 Dataflow 中稱為 DoFn),該函數每個輸入可以產生零個或多個輸出元素。例如,考慮一個擴展輸入鍵所有前綴的操作,將值復制到這些前綴上:
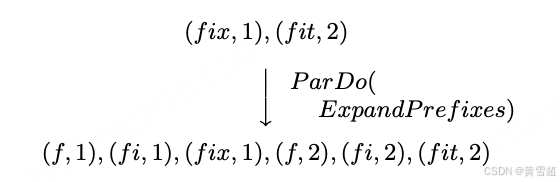
- GroupByKey:用于對(鍵,值)對進行按鍵分組:
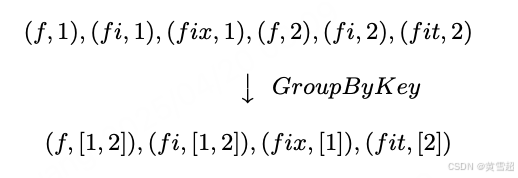
7:不失一般性,我們將系統中的所有元素都視為(鍵,值)對,盡管對于某些操作(如 ParDo)實際上并不需要鍵。大多數有意義的討論都圍繞著確實需要鍵的 GroupByKey 展開,所以假設鍵存在會更簡單。
ParDo操作對每個輸入元素按元素進行處理,因此自然適用于無界數據。另一方面,GroupByKey操作會在將數據發送到下游進行歸約之前,先收集給定鍵的所有數據。如果輸入源是無界的,我們無從知曉它何時結束。解決這個問題的常見方法是對數據進行窗口化處理。
2.2 窗口化
支持分組的系統通常將其 GroupByKey 操作重新定義為本質上的 GroupByKeyAndWindow 操作。我們在此的主要貢獻是支持非對齊窗口,這基于兩個關鍵見解。第一,從模型的角度來看,將所有窗口化策略都視為非對齊的處理方式更為簡單,并允許底層實現在適用的情況下對對齊情況應用相關優化。第二,窗口化可以分解為兩個相關操作:
- Set<Window> AssignWindows(T datum):將元素分配到零個或多個窗口。這本質上是 Li [22] 中的桶操作符。
- Set<Window> MergeWindows(Set<Window> windows):在分組時合并窗口。這允許隨著數據的到達和分組,隨時間構建數據驅動的窗口。
對于任何給定的窗口化策略,這兩個操作密切相關;滑動窗口分配需要滑動窗口合并,會話窗口分配需要會話窗口合并,等等。
請注意,為了原生支持事件時間窗口化,我們現在不再通過系統傳遞(鍵,值)對,而是傳遞(鍵,值,事件時間,窗口)四元組。元素帶著事件時間戳(在管道的任何點也可以修改 8)被提供給系統,并且最初被分配到一個默認的全局窗口,該窗口覆蓋所有事件時間,提供與標準批處理模型中默認設置相匹配的語義。
8:然而,請注意,某些時間戳修改操作與水位線等進度跟蹤指標相悖;將時間戳移到水位線之后會使給定元素相對于該水位線而言成為遲到數據。
2.2.1 窗口分配
從模型的角度來看,窗口分配會在元素被分配到的每個窗口中創建該元素的一個新副本。例如,考慮對一個數據集按寬度為兩分鐘、周期為一分鐘的滑動窗口進行窗口化,如圖 3 所示(為簡潔起見,時間戳以 HH:MM 格式給出)。

圖 3:窗口分配
在這種情況下,兩個(鍵,值)對中的每一個都被復制,以便存在于與元素時間戳重疊的兩個窗口中。由于窗口直接與它們所屬的元素相關聯,這意味著窗口分配可以在管道中應用分組之前的任何位置進行。這一點很重要,因為分組操作可能隱藏在復合轉換(例如 Sum.integersPerKey ())下游的某個位置。
2.2.2 窗口合并
窗口合并是 GroupByKeyAndWindow 操作的一部分,結合示例來解釋最為合適。我們將使用會話窗口化,因為這是我們的主要用例。圖 4 展示了四個示例數據,其中三個屬于鍵 k1,一個屬于鍵 k2,它們按會話窗口化,會話超時時間為 30 分鐘。所有數據最初都由系統放置在默認的全局窗口中。AssignWindows 的會話實現將每個元素放入一個單獨的窗口,該窗口在其自身時間戳之后延伸 30 分鐘;這個窗口表示如果后續事件要被視為同一會話的一部分,它們可以落入的時間范圍。然后我們開始 GroupByKeyAndWindow 操作,這實際上是一個由五個部分組成的復合操作:
- DropTimestamps:丟棄元素時間戳,因為從這一步開始只有窗口是相關的 9 。
- GroupByKey:按鍵對(值,窗口)元組進行分組。
- MergeWindows:合并當前為一個鍵緩沖的窗口集合。實際的合并邏輯由窗口化策略定義。在這種情況下,v1 和 v4 的窗口重疊,因此會話窗口化策略將它們合并為一個新的、更大的會話,如加粗部分所示。
- GroupAlsoByWindow:對于每個鍵,按窗口對值進行分組。在上一步合并之后,v1 和 v4 現在處于相同的窗口中,因此在這一步被分組在一起。
- ExpandToElements:將每個鍵、每個窗口的一組值擴展為(鍵,值,事件時間,窗口)元組,并帶有新的每個窗口的時間戳。在這個示例中,我們將時間戳設置為窗口的結束時間,但任何大于或等于窗口中最早事件時間戳的時間戳,就水位線正確性而言都是有效的。

圖 4:窗口合并
2.2.3 API
作為窗口化在實踐中使用的一個簡要示例,考慮以下 Cloud Dataflow SDK 代碼,用于計算按鍵的整數總和:
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input.apply(Sum.integersPerKey());
要執行相同的操作,但像圖 4 中那樣窗口化為超時時間為 30 分鐘的會話窗口,在啟動求和操作之前添加一個單一的 Window.into 調用:
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(30)))).apply(Sum.integersPerKey());
2.3 觸發器與增量處理
構建非對齊的事件時間窗口的能力是一種改進,但現在我們還有另外兩個缺點需要解決:
- 我們需要某種方式來支持基于元組和處理時間的窗口,否則相對于現有的其他系統,我們的窗口化語義會退化。
- 我們需要某種方式來知道何時為一個窗口發出結果。由于數據相對于事件時間是無序的,我們需要其他某種信號來告訴我們窗口何時完成。
我們將在 2.4 節解決窗口完整性問題之后,再處理基于元組和處理時間的窗口問題。至于窗口完整性,解決它的最初想法可能是使用某種全局事件時間進度指標,如水位線。然而,水位線本身在正確性方面有兩個主要缺點:
- 它們有時太快,這意味著可能會有遲來的數據在水位線之后到達。對于許多分布式數據源,要得出完全完美的事件時間水位線是難以處理的,因此如果我們希望輸出數據具有 100% 的正確性,就不可能僅僅依賴它。
- 它們有時太慢。因為它們是全局進度指標,水位線可能會因為單個緩慢的數據而被整個管道拖累。即使對于事件時間偏差變化不大的健康管道,偏差的基線水平可能仍然有幾分鐘甚至更多,這取決于輸入源。因此,與例如可比的 Lambda 架構管道相比,僅使用水位線作為發出窗口結果的唯一信號可能會導致整體結果的延遲更高。
基于這些原因,我們假設僅靠水位線是不夠的。解決完整性問題的一個有用見解是,Lambda 架構實際上回避了這個問題:它不是通過某種方式更快地提供正確答案來解決完整性問題;它只是提供流處理管道所能提供的結果的最佳低延遲估計,并承諾一旦批處理管道運行,最終會達到一致性和正確性 10 。
10:請注意,在現實中,只有在批處理作業運行時輸入數據完整,批處理作業的輸出才是正確的;如果數據隨時間變化,必須檢測到這種變化并重新執行批處理作業。
如果我們想在單個管道內(無論執行引擎是什么)做同樣的事情,那么我們將需要一種方法為任何給定窗口提供多個答案(或窗格)。我們將此功能稱為觸發器,因為它們允許指定何時為給定窗口觸發輸出結果。
簡而言之,觸發器是一種響應內部或外部信號刺激 GroupByKeyAndWindow 結果產生的機制。它們與窗口化模型互補,因為它們各自沿著不同的時間軸影響系統行為:
- 窗口化決定在事件時間的哪個位置將數據分組在一起進行處理。
- 觸發決定在處理時間的何時將分組結果作為窗格發出 11 。
11:特定的觸發器,比如水位線觸發器,在其提供的功能中會利用事件時間,但它們在管道內產生的效果仍是在處理時間軸上得以體現。
我們的系統提供預定義的觸發器實現,用于在完成估計時觸發(例如水位線,包括百分位水位線,當你更關心快速處理最小百分比的輸入數據而不是處理每一個最后的數據時,它為處理批處理和流處理執行引擎中的掉隊數據提供了有用的語義)、在處理時間的特定點觸發,以及響應數據到達(計數、字節數、數據標點符號、模式匹配等)觸發。我們還支持將觸發器組合成邏輯組合(與、或等)、循環、序列以及其他此類結構。此外,用戶可以利用執行運行時的底層原語(例如水位線定時器、處理時間定時器、數據到達、組合支持)以及任何其他相關外部信號(數據注入請求、外部進度指標、RPC 完成回調等)定義自己的觸發器。
我們將在 2.4 節更詳細地查看示例。
除了控制結果何時發出之外,觸發器系統還通過三種不同的細化模式提供了一種控制同一窗口的多個窗格如何相互關聯的方法:
- 丟棄模式:觸發時,窗口內容被丟棄,后續結果與先前結果無關。這種模式在數據的下游消費者(無論是管道內部還是外部)期望來自各種觸發事件的值相互獨立的情況下很有用(例如,當注入到一個生成注入值總和的系統中時)。就緩沖的數據量而言,它也是最有效的,盡管對于可以建模為 Dataflow Combiner 的結合律和交換律操作,效率差異通常很小。對于我們的視頻會話用例,這是不夠的,因為要求我們數據的下游消費者拼接部分會話是不切實際的。
- 累積模式:觸發時,窗口內容在持久狀態中保持不變,后續結果成為先前結果的細化。當下游消費者期望在收到同一窗口的多個結果時用新值覆蓋舊值時,這種模式很有用,實際上這是 Lambda 架構系統中使用的模式,其中流處理管道產生低延遲結果,然后在未來被批處理管道的結果覆蓋。對于視頻會話,如果我們只是計算會話,然后立即將它們寫入某個支持更新的輸出源(例如數據庫或鍵值存儲),這可能就足夠了。
- 累積與撤回模式:觸發時,除了累積語義之外,還會在持久狀態中存儲發出值的一個副本。當窗口在未來再次觸發時,將首先發出先前值的撤回,然后是作為普通數據的新值 12 。在具有多個串行 GroupByKeyAndWindow 操作的管道中,撤回是必要的,因為單個窗口在后續觸發事件中生成的多個結果在下游分組時可能最終落在不同的鍵上。在這種情況下,除非通過撤回通知第二個分組操作原始輸出的影響應該被逆轉,否則它將為這些鍵生成不正確的結果。也是可逆的 Dataflow Combiner 操作可以通過 uncombine 方法有效地支持撤回。對于視頻會話,這種模式是理想的。例如,如果我們在會話創建的下游執行依賴于會話自身屬性的聚合操作,例如檢測不受歡迎的廣告(例如在大多數會話中觀看時間少于五秒的廣告),隨著時間推移輸入數據發生變化,初始結果可能會無效,例如大量離線移動觀眾重新上線并上傳會話數據。撤回為我們提供了一種在具有多個串行分組階段的復雜管道中適應這些類型變化的方法。
12:撤回處理的一種簡單實現需要確定性操作,但通過增加復雜性和成本,也可以支持非確定性操作;我們已經見過需要這種操作的用例,比如概率建模。
2.4 示例
我們現在將考慮一系列示例,這些示例突出了數據流模型支持的多種有用輸出模式。我們將在 2.2.3 節整數求和管道的上下文中查看每個示例:
PCollection<KV<String, Integer>> output = input.apply(Sum.integersPerKey());
假設我們有一個輸入源,從中觀測到十個數據點,每個數據點都是較小的整數值。我們將在有界和無界數據源的兩種情況下考慮這些數據。為簡化圖示,我們假定所有這些數據都屬于同一個鍵;在實際的管道中,我們在此描述的操作類型會針對多個鍵并行發生。圖 5 展示了這些數據如何在我們關注的兩個時間軸上相互關聯。X 軸繪制的是數據的事件時間(即事件實際發生的時間),而 Y 軸繪制的是數據的處理時間(即管道觀測到數據的時間)。除非另有說明,所有示例均假定在我們的流處理引擎上執行。
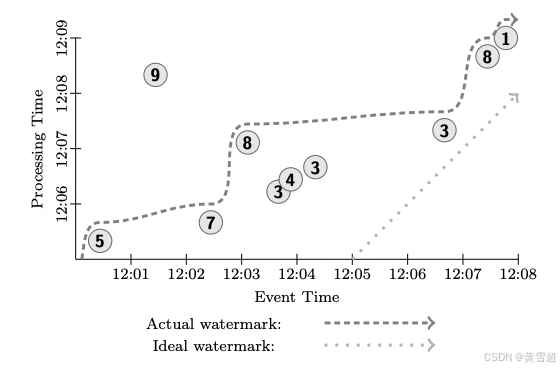
圖 5:示例輸入
許多示例還會依賴水位線,在這種情況下,我們會在圖示中包含它們。我們將同時繪制理想水位線和一個實際水位線示例。斜率為 1 的直虛線代表理想水位線,即假設不存在事件時間偏差,且所有事件在發生時都由系統進行處理。鑒于分布式系統的復雜性,偏差是常見現象;圖 5 中實際水位線的曲折路徑就是例證,用較深的虛線表示。還需注意的是,這條水位線的啟發式特性通過值為 9 的單個 “遲到” 數據體現出來,該數據出現在水位線之后。
如果我們要在經典批處理系統中使用上述求和管道處理這些數據,我們會等待所有數據到達,將它們歸為一組(因為這些數據都屬于同一個鍵),然后對它們的值求和,得到總計為 51 的結果。這個結果由圖 6 中的深色矩形表示,其面積涵蓋了求和所涉及的事件時間和處理時間范圍(矩形頂部表示在處理時間中結果具體化的時間)。由于經典批處理不區分事件時間,結果包含在一個覆蓋所有事件時間的單一全局窗口內。并且由于只有在接收到所有輸入后才計算輸出,結果涵蓋了執行過程中的所有處理時間。
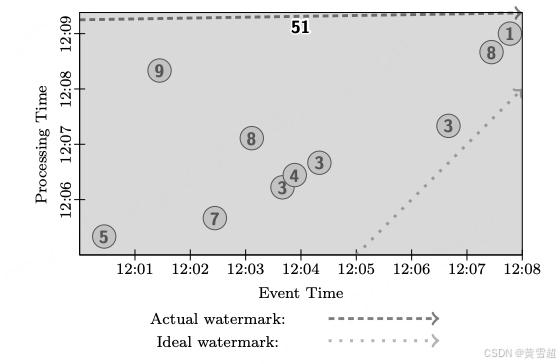
圖6:經典批處理執行情況
請注意此圖中包含了水位線。雖然水位線通常不用于經典批處理,但從語義上講,水位線會保持在起始時間,直到所有數據都被處理完畢,然后推進到無窮大。需要注意的一個要點是,通過以這種方式推進水位線,在流處理系統中運行數據可以獲得與經典批處理相同的語義。
現在假設我們想將此管道轉換為在無界數據源上運行。在 Dataflow 中,默認的觸發語義是當水位線經過窗口時發出窗口。但是,當對無界輸入源使用全局窗口時,我們確定這種情況永遠不會發生,因為全局窗口涵蓋了所有事件時間。因此,我們需要通過除默認觸發器之外的其他方式觸發,或者使用除全局窗口之外的其他窗口方式。否則,我們將永遠得不到任何輸出。
我們首先來看更改觸發器,因為這將使我們能夠生成概念上相同的輸出(隨時間的全局按鍵總和),但會有定期更新。在這個例子中,我們應用一個 Window.trigger 操作,它在每分鐘的處理時間周期邊界上重復觸發。我們還指定了累積模式,以便全局總和隨時間細化(這假定我們有一個輸出接收器,在其中我們可以簡單地用新結果覆蓋該鍵的先前結果,例如數據庫或鍵值存儲)。因此,在圖 7 中,我們在每分鐘的處理時間生成更新后的全局總和。請注意,半透明的輸出矩形是如何重疊的,因為累積窗格通過合并處理時間的重疊區域在先前結果的基礎上構建:
PCollection<KV<String, Integer>> output = input.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE))).accumulating()).apply(Sum.integersPerKey());
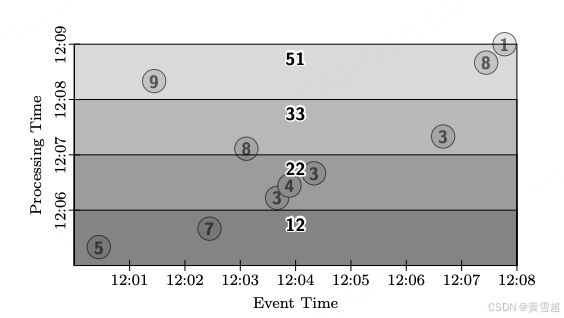
圖7:全局窗口、按周期觸發、累積模式
如果我們希望每分鐘生成總和的增量,我們可以切換到丟棄模式,如圖 8 所示。請注意,這實際上提供了許多流處理系統所提供的處理時間窗口語義。輸出窗格不再重疊,因為它們的結果包含來自獨立處理時間區域的數據。
PCollection<KV<String, Integer>> output = input.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE))).discarding()).apply(Sum.integersPerKey());
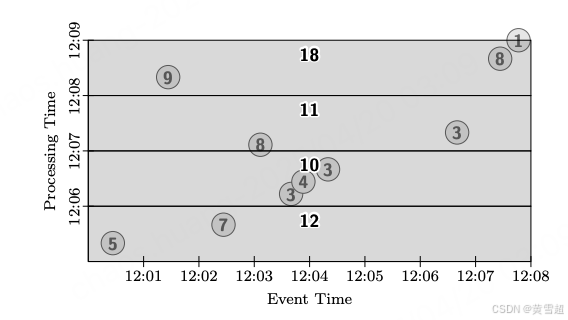
圖 8:全局窗口、按周期觸發、丟棄模式
另一種更可靠的提供處理時間窗口語義的方法是在數據進入時簡單地將到達時間指定為事件時間,然后使用事件時間窗口化。使用到達時間作為事件時間的一個好處是,系統完全知曉傳輸中的事件時間,因此可以提供完美的(即非啟發式的)水位線,且不會有遲到數據。對于真實事件時間并非必要或不可用的用例,這是一種處理無界數據的有效且經濟高效的方式。
在我們更深入研究其他窗口選項之前,讓我們考慮對此管道的觸發器再做一個更改。我們希望建模的另一種常見窗口模式是基于元組的窗口。我們可以通過簡單地更改觸發器,使其在一定數量(比如說兩個)的數據到達后觸發,來提供這種功能。在圖 9 中,我們得到五個輸出,每個輸出包含兩個相鄰(按處理時間)數據的總和。更復雜的基于元組的窗口方案(例如滑動基于元組的窗口)需要自定義窗口策略,但在其他方面是受支持的。
PCollection<KV<String, Integer>> output = input.apply(Window.trigger(Repeat(AtCount(2))).discarding()).apply(Sum.integersPerKey());
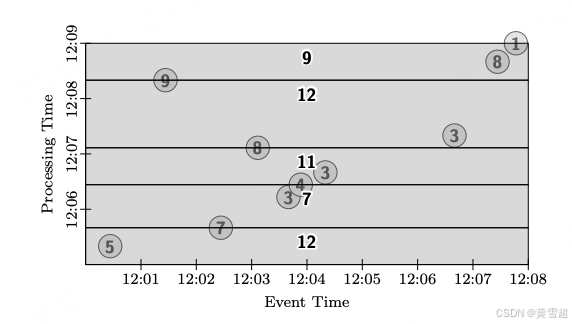
圖 9:全局窗口、按計數觸發、丟棄模式
現在讓我們回到支持無界源的另一個選項:放棄全局窗口化。首先,讓我們將數據窗口化為固定的、兩分鐘的累積窗口:
PCollection<KV<String, Integer>> output = input.apply(Window.into(FixedWindows.of(2, MINUTES).accumulating()).apply(Sum.integersPerKey());
在未指定觸發策略的情況下,系統將使用默認觸發器,實際上就是:
PCollection<KV<String, Integer>> output = input.apply(Window.into(FixedWindows.of(2, MINUTES)).trigger(Repeat(AtWatermark()))).accumulating()).apply(Sum.integersPerKey());
當水位線經過相關窗口的末尾時,水位線觸發器會觸發。批處理和流處理引擎都實現了水位線,如 3.1 節所詳述。觸發器中的 Repeat 調用用于處理遲到數據;如果有任何數據在水位線之后到達,它們將實例化重復的水位線觸發器,由于水位線已經經過,該觸發器將立即觸發。
圖 10 - 12 分別描述了此管道在不同類型運行時引擎上的情況。我們首先觀察此管道在批處理引擎上的執行情況。根據我們當前的實現,數據源必須是有界的,所以與上述經典批處理示例一樣,我們會等待批處理中的所有數據到達。然后我們將按事件時間順序處理數據,隨著模擬水位線的推進發出窗口,如圖 10 所示:
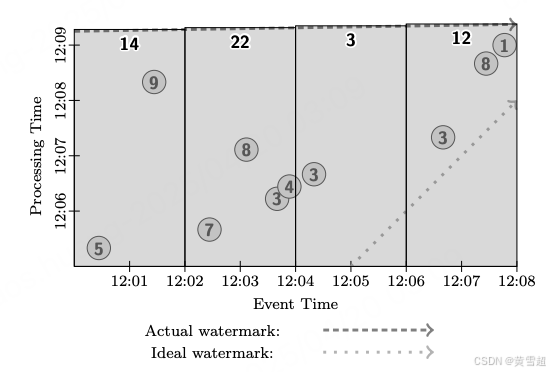
圖 10:固定窗口,批處理模式
現在想象在這個數據源上使用一分鐘微批次運行微批處理引擎。系統會收集一分鐘的輸入數據,進行處理,然后重復這個過程。每次,當前批次的水位線將從起始時間開始推進到結束時間(嚴格來說,會瞬間從批次的結束時間跳到時間的結束,因為在該時間段內不存在數據)。因此,每一輪微批次我們都會得到一個新的水位線,以及自上一輪以來內容發生變化的所有窗口的相應輸出。這在延遲和最終正確性之間提供了很好的平衡,如圖 11 所示:
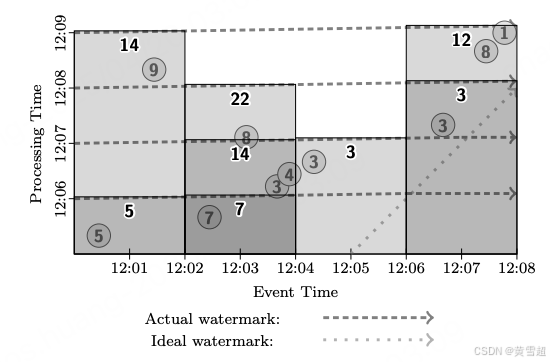
圖11:固定窗口,微批處理模式
接下來,考慮此管道在流處理引擎上執行的情況,如圖 12 所示。大多數窗口在水位線經過時發出。然而請注意,值為 9 的數據相對于水位線實際上是遲到的。由于某種原因(移動輸入源離線、網絡分區等),系統沒有意識到該數據尚未注入,因此,在觀測到值為 5 的數據后,允許水位線推進到最終會被值為 9 的數據占據的事件時間點之后。因此,一旦值為 9 的數據最終到達,它會導致第一個窗口(事件時間范圍為 [12:00, 12:02))重新觸發,并更新總和:
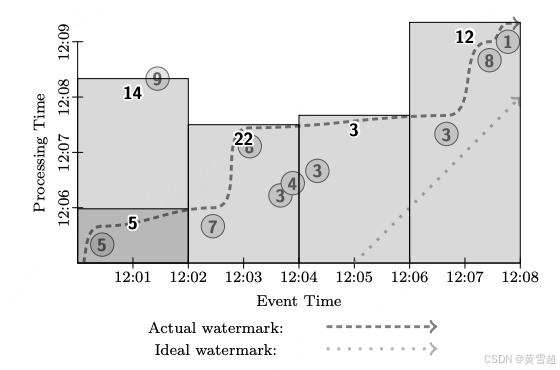
圖 12:固定窗口,流處理模式
這種輸出模式很好,因為每個窗口大致有一個輸出,在遲到數據的情況下有一次細化。但由于必須等待水位線推進,結果的整體延遲明顯比微批處理系統更差;這就是 2.3 節中提到的水位線太慢的情況。
如果我們希望通過為所有窗口提供多個部分結果來降低延遲,我們可以添加一些額外的基于處理時間的觸發器,以便在水位線實際經過之前定期提供更新,如圖 13 所示。這比微批處理管道的延遲略好,因為數據在到達時會累積在窗口中,而不是以小批次進行處理。對于強一致性的微批處理和流處理引擎,它們之間的選擇(以及微批大小的選擇)實際上就變成了延遲與成本之間的權衡,這正是我們使用此模型要實現的目標之一。
PCollection<KV<String, Integer>> output = input.apply(Window.into(FixedWindows.of(2, MINUTES)).trigger(SequenceOf(RepeatUntil(AtPeriod(1, MINUTE),AtWatermark()),Repeat(AtWatermark()))).accumulating()).apply(Sum.integersPerKey());
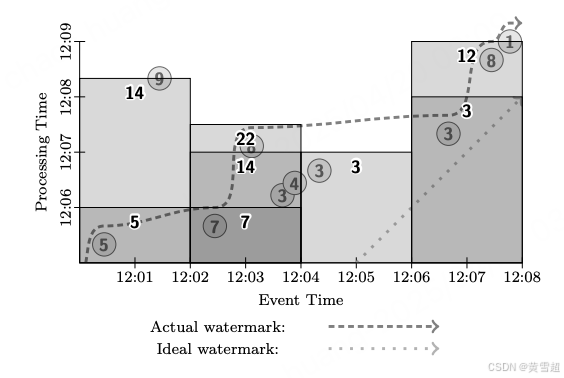
圖13:固定窗口、流處理、部分結果模式
作為最后一個練習,讓我們更新示例以滿足視頻會話的要求(為保持圖示一致性,仍使用求和作為聚合操作;切換到其他聚合操作很簡單),更新為超時時間為一分鐘的會話窗口化并啟用撤回功能。這突出了將模型分解為四個部分(計算什么、在事件時間的何處計算、在處理時間的何時觀測答案以及這些答案與后續細化的關系)所提供的可組合性,同時也說明了撤銷先前值的作用,否則這些先前值可能與作為替代提供的值無關。
PCollection<KV<String, Integer>> output = input.apply(Window.into(Sessions.withGapDuration(1, MINUTE)).trigger(SequenceOf(RepeatUntil(AtPeriod(1, MINUTE),AtWatermark()),Repeat(AtWatermark()))).accumulatingAndRetracting()).apply(Sum.integersPerKey());
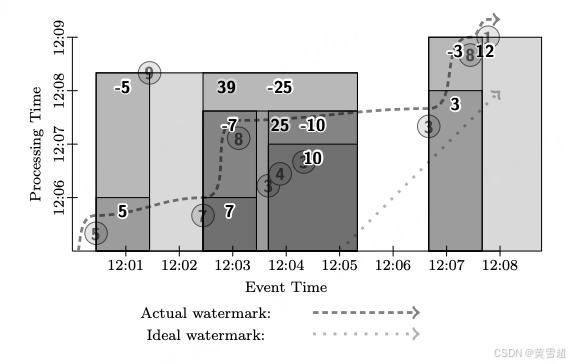
圖 14:會話窗口、可撤回模式
在這個例子中,在第一個一分鐘處理時間邊界,我們輸出值為 5 和 7 的初始單例會話。在第二個分鐘邊界,我們輸出值為 10 的第三個會話,它由值 3、4 和 3 組成。當最終觀測到值為 8 的數據時,它將值為 7 和 10 的兩個會話合并。當水位線經過這個新合并會話的末尾時,會發出值為 7 和 10 的會話的撤回信息,以及值為 25 的新會話的正常數據。類似地,當值為 9 的數據(遲到)到達時,它將值為 5 的會話與會值為 25 的會話合并。重復的水位線觸發器隨后立即發出值為 5 和 25 的撤回信息,接著是值為 39 的合并會話。對于值 3、8 和 1 也會發生類似的情況,最終以值為 3 的初始會話的撤回信息結束,接著是值為 12 的合并會話。
3.實現與設計
3.1 實現
我們已在 FlumeJava 內部實現了該模型,在流模式下將 MillWheel 用作底層執行引擎;此外,在撰寫本文時,針對 Cloud Dataflow 的外部重新實現已基本完成。由于先前文獻中已對這些內部系統進行過描述,且 Cloud Dataflow 已公開可用,為簡潔起見,此處省略實現細節。一個有趣的點是,核心的窗口化和觸發代碼具有很強的通用性,其中很大一部分在批處理和流處理實現中是共享的;該系統本身值得在未來的工作中進行更詳細的分析。
3.2 設計原則
盡管我們的大部分設計靈感來自于下文 3.3 節中詳細介紹的實際經驗,但也受到一組核心原則的指導,我們認為我們的模型應體現這些原則:
- 絕不依賴任何關于完整性的概念。
- 保持靈活性,以適應已知和未來可能出現的各種用例。
- 在每個設想的執行引擎環境中,不僅要有意義,還要有價值。
- 鼓勵清晰的實現。
- 支持在數據產生的上下文中對數據進行穩健的分析。
雖然以下經驗影響了模型的特定功能,但這些原則決定了模型的整體形態和特征,我們相信最終會得到一個更全面、通用的結果。
3.3 實際經驗啟發
在設計 Dataflow 模型時,我們考慮了多年來在 FlumeJava 和 MillWheel 方面的實際經驗。運行良好的部分,我們確保在模型中體現;運行不太好的部分則促使我們改變方法。以下是一些影響我們設計的經驗簡述。
3.3.1 大規模回填與 Lambda 架構:統一模型
多個團隊在 MillWheel 上運行日志合并管道。一個特別大的日志合并管道默認在 MillWheel 上以流模式運行,但有一個單獨的 FlumeJava 批處理實現用于大規模回填。更好的設置是使用統一模型編寫一個單一實現,無需修改即可在流模式和批處理模式下運行。這成為了統一批處理、微批處理和流引擎的最初動機用例,并在圖 10 - 12 中有所體現。
統一模型的另一個動機來自于 Lambda 架構的經驗。盡管谷歌的大多數數據處理用例由批處理或流系統單獨處理,但有一個 MillWheel 客戶以弱一致性模式運行他們的流管道,并通過每晚的 MapReduce 生成真實數據。他們發現隨著時間推移,客戶不再信任弱一致性結果,因此圍繞強一致性重新實現了他們的系統,以便提供可靠、低延遲的結果。這一經驗進一步促使我們希望在執行引擎之間實現靈活選擇。
3.3.2 非對齊窗口:會話
從一開始,我們就知道需要支持會話;實際上,這是我們的窗口模型相對于現有模型的主要貢獻。會話在谷歌內部是一個極其重要的用例(實際上也是創建 MillWheel 的原因之一),并在包括搜索、廣告、分析、社交和 YouTube 等多個產品領域中使用。幾乎任何關心在一段時間內關聯原本不相關的用戶活動突發情況的人,都會通過計算會話來實現。因此,在我們的設計中,對會話的支持至關重要。如圖 14 所示,在 Dataflow 模型中生成會話很簡單。
3.3.3 計費:觸發、累積與撤回
兩個基于 MillWheel 構建計費管道的團隊遇到了一些問題,這些問題推動了模型部分內容的設計。當時的推薦做法是使用水印作為完成指標,并采用臨時邏輯處理延遲數據或源數據的變化。由于缺乏更新和撤回的原則性系統,一個處理資源利用率統計信息的團隊最終離開了我們的平臺,構建了一個定制解決方案(其模型最終與我們同時開發的模型非常相似)。另一個計費團隊在處理輸入中的拖后腿數據導致的水印滯后方面遇到了重大問題。這些缺點成為我們設計中的主要動機,并影響了關注點從追求完整性向隨著時間推移的適應性轉變。結果有兩方面:觸發機制,它允許簡潔靈活地指定結果何時具體化,如圖 7 - 14 中同一數據集上可能出現的各種輸出模式所示;以及通過累積(圖 7 和圖 8)和撤回(圖 14)提供增量處理支持。
3.3.4 統計計算:水印觸發
許多 MillWheel 管道計算聚合統計信息(例如延遲平均值)。對于這些管道,不需要 100% 的準確性,但需要在合理時間內對數據有一個大致完整的視圖。鑒于我們使用水印對日志文件等結構化輸入源能達到較高的準確性,此類客戶發現水印在觸發每個窗口的單個、高精度聚合方面非常有效。水印觸發在圖 12 中突出顯示。
許多濫用檢測管道在 MillWheel 上運行。濫用檢測是另一個用例示例,快速處理大部分數據比更慢地處理 100% 的數據更有用。因此,它們大量使用 MillWheel 的百分位水印,這也是模型中能夠支持百分位水印觸發的一個強烈動機案例。
相關地,批處理作業的一個痛點是拖后腿的任務會導致執行時間變長。雖然動態重新平衡可以幫助解決這個問題,但 FlumeJava 有一個自定義功能,允許根據總體進度提前終止作業。批處理模式統一模型的好處之一是,現在這種提前終止標準可以自然地使用標準觸發機制來表達,而不需要自定義功能。
3.3.5 推薦系統:處理時間觸發
我們考慮的另一個管道在谷歌的一個大型屬性上構建用戶活動樹(本質上是會話樹)。然后使用這些樹來構建針對用戶興趣的推薦。這個管道值得注意的是,它使用處理時間定時器來驅動輸出。這是因為對于他們的系統,定期更新的部分數據視圖比等待水印通過會話結束后獲得大致完整的視圖更有價值。這也意味著由于少量慢速數據導致的水印進度滯后不會影響其余數據輸出的及時性。因此,這個管道促使我們在圖 7 和圖 8 中加入處理時間觸發。
3.3.6 異常檢測:數據驅動和復合觸發
在 MillWheel 論文中,我們描述了一個用于跟蹤谷歌網頁搜索查詢趨勢的異常檢測管道。在開發觸發機制時,他們的差異檢測系統啟發了數據驅動觸發。這些差異檢測觀察查詢流,并計算是否存在峰值的統計估計。當它們認為出現峰值時,會發出開始記錄,當認為峰值停止時,會發出停止記錄。雖然你可以使用像 Trill 的標點符號這樣的周期性內容來驅動差異輸出,但對于異常檢測,理想情況下你希望一旦確定發現異常就盡快輸出;使用標點符號本質上會將流系統轉換為微批處理,引入額外延遲。雖然對于許多用例來說是實用的,但最終并不完全適合這個用例,因此促使我們支持自定義數據驅動觸發。這也是觸發組合的一個動機案例,因為在現實中,系統同時運行多個差異檢測,并根據一組明確定義的邏輯對它們的輸出進行復用。圖 9 中使用的 AtCount 觸發就是數據驅動觸發的示例;圖 10 - 14 使用了復合觸發。
4.結論
數據處理的未來在于無界數據。盡管有界數據始終會有重要且有用的地位,但從語義上講,它被無界數據所包含。此外,無界數據集在現代商業中的擴散程度驚人。與此同時,處理后數據的消費者日益精明,要求諸如事件時間排序和非對齊窗口等強大的構造。當今存在的模型和系統為構建未來的數據處理工具提供了出色的基礎,但我們堅信,為了使這些工具能夠全面滿足無界數據消費者的需求,整體思維方式的轉變是必要的。
基于我們多年在谷歌內部處理真實世界、大規模、無界數據的經驗,我們相信這里提出的模型朝著這個方向邁出了良好的一步。它支持現代數據消費者所需的非對齊、事件時間排序窗口。它提供靈活的觸發以及集成的累積和撤回功能,將方法的重點從在數據中尋找完整性轉變為適應現實世界數據集中始終存在的變化。它抽象掉了批處理、微批處理和流處理之間的區別,使管道構建者能夠在它們之間更靈活地選擇,同時使他們免受針對單個底層系統的模型中不可避免出現的特定于系統的構造的影響。其整體靈活性使管道構建者能夠適當地平衡正確性、延遲和成本等維度以適應他們的用例,鑒于存在的需求多樣性,這一點至關重要。最后,它通過分離正在計算什么結果、在事件時間的何處計算、在處理時間的何時具體化以及早期結果與后期細化之間的關系等概念,使管道實現更加清晰。我們希望其他人會發現這個模型有用,因為我們都在繼續推動這個迷人且極其復雜領域的技術發展。
6.參考文獻
[1] D. J. Abadi et al. Aurora: A New Model and Architecture for Data Stream Management. The VLDB Journal, 12(2):120–139, Aug. 2003.
[2] T. Akidau et al. MillWheel: Fault-Tolerant Stream Processing at Internet Scale. In Proc. of the 39th Int.Conf. on Very Large Data Bases (VLDB), 2013.
[3] A. Alexandrov et al. The Stratosphere Platform for Big Data Analytics. The VLDB Journal,23(6):939–964, 2014.
[4] Apache. Apache Hadoop.http://hadoop.apache.org, 2012.
[5] Apache. Apache Storm.http://storm.apache.org, 2013.
[6] Apache. Apache Flink.http://flink.apache.org/, 2014.
[7] Apache. Apache Samza.http://samza.apache.org, 2014.
[8] R. S. Barga et al. Consistent Streaming Through Time: A Vision for Event Stream Processing. In Proc.of the Third Biennial Conf. on Innovative Data Systems Research (CIDR), pages 363–374, 2007.
[9] Botan et al. SECRET: A Model for Analysis of the Execution Semantics of Stream Processing Systems.Proc. VLDB Endow., 3(1-2):232–243, Sept. 2010.
[10] O. Boykin et al. Summingbird: A Framework for Integrating Batch and Online MapReduce Computations. Proc. VLDB Endow., 7(13):1441–1451, Aug. 2014.
[11] Cask. Tigon. http://tigon.io/, 2015.
[12] C. Chambers et al. FlumeJava: Easy, Efficient Data-Parallel Pipelines. In Proc. of the 2010 ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI), pages 363–375, 2010.
[13] B. Chandramouli et al. Trill: A High-Performance Incremental Query Processor for Diverse Analytics. In Proc. of the 41st Int. Conf. on Very Large Data Bases (VLDB), 2015.
[14] S. Chandrasekaran et al. TelegraphCQ: Continuous Dataflow Processing. In Proc. of the 2003 ACM SIGMOD Int. Conf. on Management of Data(SIGMOD), SIGMOD ’03, pages 668–668, New York,NY, USA, 2003. ACM.
[15] J. Chen et al. NiagaraCQ: A Scalable Continuous Query System for Internet Databases. In Proc. of the 2000 ACM SIGMOD Int. Conf. on Management of Data (SIGMOD), pages 379–390, 2000.
[16] J. Dean and S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. In Proc. of the Sixth Symposium on Operating System Design and Implementation (OSDI), 2004.
[17] EsperTech. Esper.http://www.espertech.com/esper/, 2006.
[18] Gates et al. Building a High-level Dataflow System on Top of Map-Reduce: The Pig Experience. Proc.VLDB Endow., 2(2):1414–1425, Aug. 2009.
[19] Google. Dataflow SDK. https://github.com/GoogleCloudPlatform/DataflowJavaSDK, 2015.
[20] Google. Google Cloud Dataflow. https://cloud.google.com/dataflow/, 2015.
[21] T. Johnson et al. A Heartbeat Mechanism and its Application in Gigascope. In Proc. of the 31st Int. Conf. on Very Large Data Bases (VLDB), pages 1079–1088, 2005.
[22] J. Li et al. Semantics and Evaluation Techniques for Window Aggregates in Data Streams. In Proceedings og the ACM SIGMOD Int. Conf. on Management of Data (SIGMOD), pages 311–322, 2005.
[23] J. Li et al. Out-of-order Processing: A New Architecture for High-performance Stream Systems.Proc. VLDB Endow., 1(1):274–288, Aug. 2008.
[24] D. Maier et al. Semantics of Data Streams and Operators. In Proc. of the 10th Int. Conf. on Database Theory (ICDT), pages 37–52, 2005.
[25] N. Marz. How to beat the CAP theorem. http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html, 2011.
[26] S. Murthy et al. Pulsar – Real-Time Analytics at Scale. Technical report, eBay, 2015.
[27] SQLStream. http://sqlstream.com/, 2015.
[28] U. Srivastava and J. Widom. Flexible Time Management in Data Stream Systems. In Proc. of the 23rd ACM SIGMOD-SIGACT-SIGART Symp. on Princ. of Database Systems, pages 263–274, 2004.
[29] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, S. Anthony, H. Liu, P. Wyckoff, and R. Murthy. Hive: A Warehousing Solution over a Map-reduce Framework. Proc. VLDB Endow., 2(2):1626–1629, Aug. 2009.
[30] P. A. Tucker et al. Exploiting punctuation semantics in continuous data streams. IEEE Transactions on Knowledge and Data Engineering, 15, 2003.
[31] J. Whiteneck et al. Framing the Question: Detecting and Filling Spatial- Temporal Windows. In Proc. of the ACM SIGSPATIAL Int. Workshop on GeoStreaming (IWGS), 2010.
[32] F. Yang and others. Sonora: A Platform for Continuous Mobile-Cloud Computing. Technical Report MSR-TR-2012-34, Microsoft Research Asia.
[33] M. Zaharia et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. In Proc. of the 9th USENIX Conf. on Networked Systems Design and Implementation (NSDI), pages 15–28, 2012.
[34] M. Zaharia et al. Discretized Streams: Fault-Tolerant Streaming Computation at Scale. In Proc. of the 24th ACM Symp. on Operating Systems Principles, 2013.


 吳恩達版提示詞工程 5. 推理 (情緒分類,控制輸出格式,輸出 JSON,集成多個任務,文本主題推斷和索引,主題內容提醒))




)

)
)
![[架構之美]Ubuntu源碼部署APISIX全流程詳解(含避坑指南)](http://pic.xiahunao.cn/[架構之美]Ubuntu源碼部署APISIX全流程詳解(含避坑指南))
)

)




![[詳細無套路]MDI Jade6.5安裝包下載安裝教程](http://pic.xiahunao.cn/[詳細無套路]MDI Jade6.5安裝包下載安裝教程)