25年4月來自Nvidia、多倫多大學、NYU和斯坦福大學的論文“Data Scaling Laws for End-to-End Autonomous Driving”。
自動駕駛汽車 (AV) 棧傳統上依賴于分解方法,使用單獨的模塊處理感知、預測和規劃。然而,這種設計在模塊間通信期間會引入信息丟失,增加計算開銷,并可能導致復合錯誤。為了應對這些挑戰,最近的研究提出將所有組件集成到端到端可微分模型中的架構,從而實現整體系統優化。這種轉變強調數據工程而不是軟件集成,只需擴大訓練資源規模即可提供提高系統性能的潛力。這項工作評估一種簡單的端到端駕駛架構在內部駕駛數據集上的性能,該數據集的大小從 16 到 8192 小時,包括開環指標和閉環模擬。具體來說,其研究需要多少額外的訓練數據才能實現目標性能提升,例如,將運動預測準確度提高 5%。通過了解模型性能和訓練數據集大小之間的關系,旨在為自動駕駛開發中的數據驅動決策提供見解。
傳統上,自動駕駛系統采用模塊化方法,將感知、預測和規劃分成不同的組件,每個組件都根據各自的目標進行獨立優化 [14, 43–45, 53, 61]。雖然這種模塊化設計將自動駕駛汽車開發的工作分散到各個專業團隊,但在集成過程中也帶來了巨大的挑戰,例如模塊間信息丟失、誤差疊加以及資源利用效率低下。為了突破這些限制,最近提出了端到端架構。這些模型接收傳感器輸入,例如激光雷達和攝像頭圖像,并直接輸出規劃的駕駛路徑,將多個模塊集成到一個框架中,所有組件都朝著一個統一的目標進行聯合優化:運動規劃。這種統一的優化方法有可能通過擴展訓練資源來提升系統性能。然而,一個關鍵問題依然存在:在端到端自動駕駛系統中,需要多少訓練數據才能實現有意義的性能提升?在自然語言處理 (NLP) 領域,大量研究已經從訓練數據大小和模型性能的角度探討了規模化規律 [1, 39, 77]。然而,在自動駕駛領域,公共數據集的規模相對有限,阻礙了類似的大規模分析。這一差距使得我們無法確定縮放如何影響基于學習的自動駕駛系統的開環性能,更重要的是,如何影響閉環性能。此外,目前尚不清楚規模化端到端駕駛架構的特定組件(例如感知或預測)是否能顯著提高性能。這種缺乏明確性帶來了挑戰,因為收集和注釋自動駕駛數據的成本很高。建立可靠的規模化規律可以讓自動駕駛開發人員更好地將數據和訓練投資與性能提升相結合,從而節省大量資源。
為此,本文使用一個具有代表性的端到端駕駛棧(類似于 [5] 和 [11] 等早期研究中使用的棧)來檢驗自動駕駛汽車模型的數據規模化規律,該棧采用模仿學習將視覺輸入(即 RGB 攝像頭圖像)直接映射到軌跡。具體而言,使用標準開環指標,在 16 到 8192 小時駕駛數據的內部數據集上訓練和評估該模型。然后,在閉環模擬器中評估其性能,其中基于規則的控制器將預測的軌跡轉換為控制命令。
如圖所示:在不同動作類型體現的規模化定律
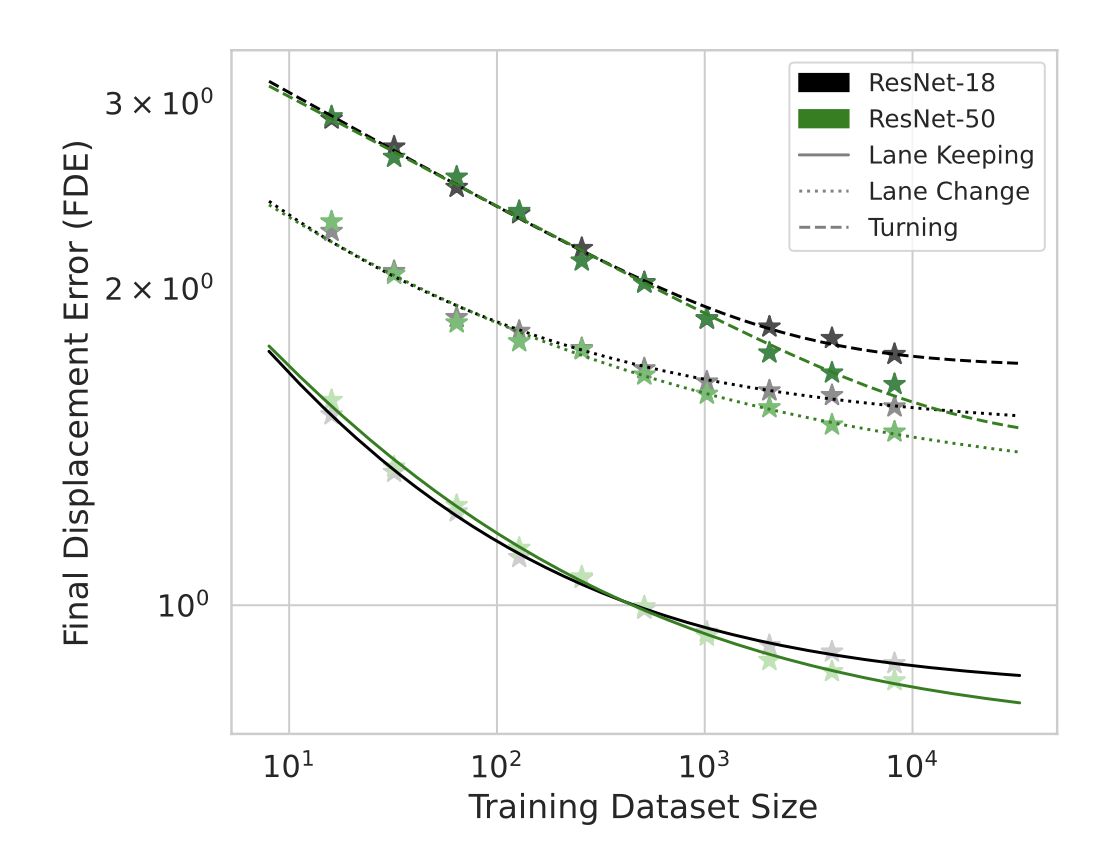
注:最近的一個工作“Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving”(https://arxiv.org/abs/2412.02689)探索了端到端自動駕駛汽車系統中的數據規模化,但缺乏結構化的框架,忽略了關鍵分析,例如不同的規模化趨勢、不同動作類型的性能差異以及模型容量效應。相比之下,本文工作建立了一種系統的方法來測量規模化行為和數據需求估計。
為了分析端到端自動駕駛的規模化規律,從超過10個國家的內部駕駛數據中整理出一個行業規模的數據集,該數據集時長超過8000小時,行駛里程超過40萬公里。該數據集提供3張校正(rectified)圖像,這些圖像分別來自3個廣角攝像頭,分別朝向自動駕駛汽車的前方、左側和右側,分辨率為734×270,采樣率為10Hz,如圖所示。

車輛自身軌跡以5Hz的采樣率均勻重采樣,采樣范圍為未來3秒。為了評估規模化規律,準備不同大小的訓練數據集,其大小范圍從16小時到8192小時,均為2的冪次方。這種方法使數據集規模與流行的公共基準測試(例如 nuScenes [6] (15h)、WOMD [70] (574h)、Lyft [29] (1001h) 和 nuPlan [23] (1282h))的規模保持一致,從而可以在自動駕駛研究中進行相關的比較。
為了防止跨數據分區的信息泄露,為訓練、驗證和測試數據集建立互斥的地理區域,主要分布在歐洲和北美,以確保空間數據的完全隔離。通過構建一個全局無向圖來實現這一點,其中駕駛會話和訪問過的 H3 單元表示為節點,并通過邊將會話連接到各自的 H3 節點。通過識別該圖中的連接組件,確定會話集群,即適合訓練、驗證或測試且不存在重疊風險的地理上不相交會話組。
除了確保訓練、驗證和測試分割在地理上不相交之外,保持所選操作設計域 (ODD) 在這些分割中的分布相似也至關重要。
因為模型只輸出一條軌跡,所以需要導航輸入命令來消除轉彎和變道等駕駛動作的歧義。為了檢索這些動作輸入,利用每個時間點的矢量化地圖標簽(即車道折線和多邊形),稱為地圖快照(map snapshot)。由于這些數據會隨時間步長而變化,將每個地圖快照解析為 trajdata [36] 格式,并估算任何缺失的道路拓撲信息,例如橫向車道連通性。由于在使用基于位置和方向的車道匹配 [55] 時存在定位的時間一致性問題,實現一個 trajdata 擴展,它可以按照 [52] 生成不同的基于地圖錨路徑 (DMAP)。遍歷該圖以識別自車何時:(1) 轉彎(所有具有多個出站縱向邊的情況??)和 (2) 變道(遍歷橫向邊的情況??)。
模型由兩個主要組件組成:一個對攝像機圖像進行編碼的感知模塊和一個生成未來軌跡的預測模塊。雖然更先進、最先進的架構有可能提升最終性能,但重點在于對具有代表性的數據驅動模型進行系統性規模化規律分析的方法和程序,而不是實現絕對最高的準確率。具體來說,特意排除過去的歷史,因為它可以壓倒性地預示未來的狀態 [42],以確保模型主要從當前的視覺輸入中學習解讀環境。這種更簡單的設計選擇不會改變基本的規模化動力學,使分析更具泛化能力,并能夠更有效地進行實驗。
感知模塊將校正后的多視角攝像頭圖像作為輸入。如果僅提供單個前置攝像頭視圖,感知模塊會直接將提取的特征 轉發到預測模塊進行軌跡生成。當有多個攝像頭視圖可用時,用交叉注意機制融合多視角信息,類似于 [57]。這種融合策略確保橫向視圖(左視圖和右視圖)的融合不帶偏見或不依賴于處理順序。
預測模塊基于感知模塊生成的特征,結合額外的動作命令和運動學信息,生成最終的軌跡輸出。
在對感知、動作和運動特征進行編碼之后,使用交叉注意將其融合,以捕捉這些模態之間的依賴關系。
在訓練中,采用余弦退火方案來促進平穩高效的學習 [39]。然而,這需要提前知道總訓練時長,因為必須預先定義周期長度。與之前要么固定總計算量,要么固定每個數據集大小的 epoch 數量 [24] 的工作不同,本文提出一種線性遞減的計算方案。具體而言,對包含 2^k 小時駕駛數據的數據集進行 m × (1 + l ? k) 個 epoch 的訓練,其中 m = 2 表示 epoch 的底數,l = 13 是最大數據集分割的指數 k。這種方法在有限的計算資源和有效的訓練之間取得了平衡。
如圖所示,恒定 epoch 方法 (a) 無論數據集大小如何都應用相同數量的 epoch,這導致較大數據集的計算需求大幅增加。相比之下,恒定計算方法 (b) 在不同的數據集大小上保持固定的計算量,使得較大的數據集能夠進行足夠的迭代次數,但在較小的分塊上計算量過大。
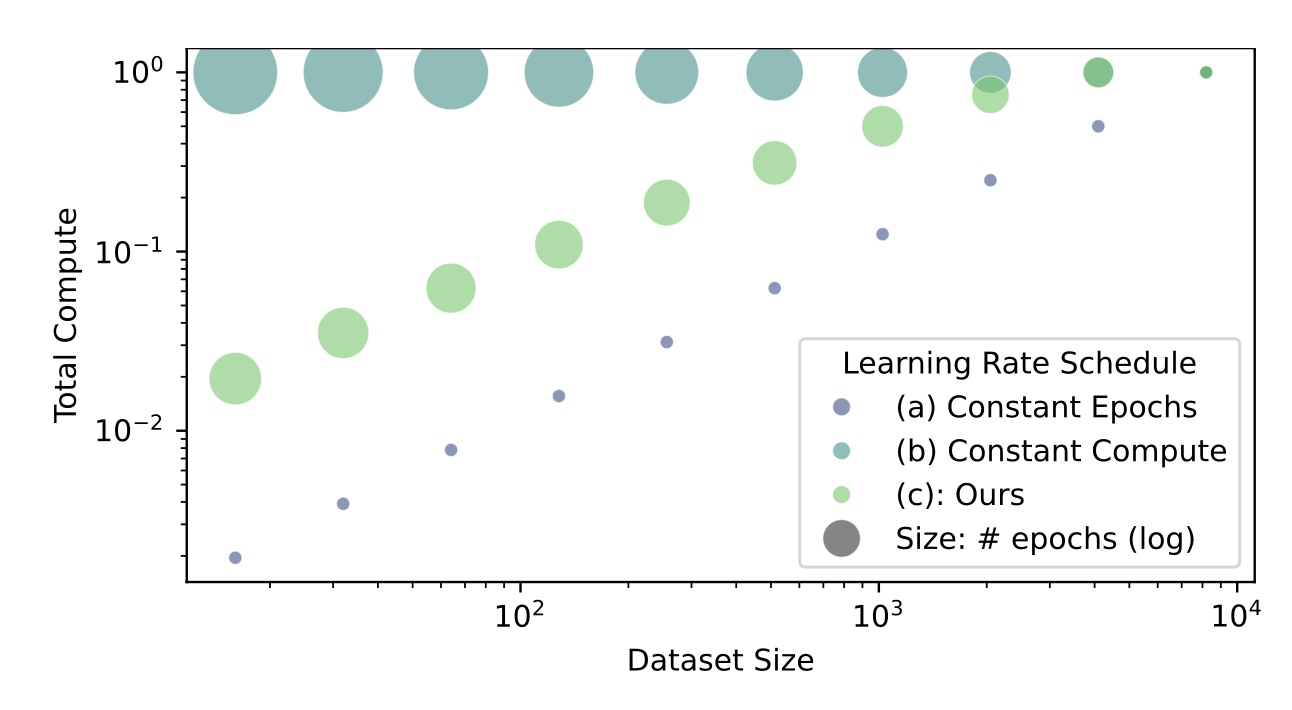
冷卻階段的額外要求也使得它比余弦退火 [24] 更復雜。自適應方法 ? 會根據數據集大小擴展 epoch 數量,從而在不為較小數據集過度分配資源的情況下提供足夠的訓練,同時仍確保為較大數據集提供足夠的資源。這種逐步規模化的方法可以在不同的數據集大小上實現平滑收斂,并提供一種計算余弦退火使用周期長度的方法 [39]。
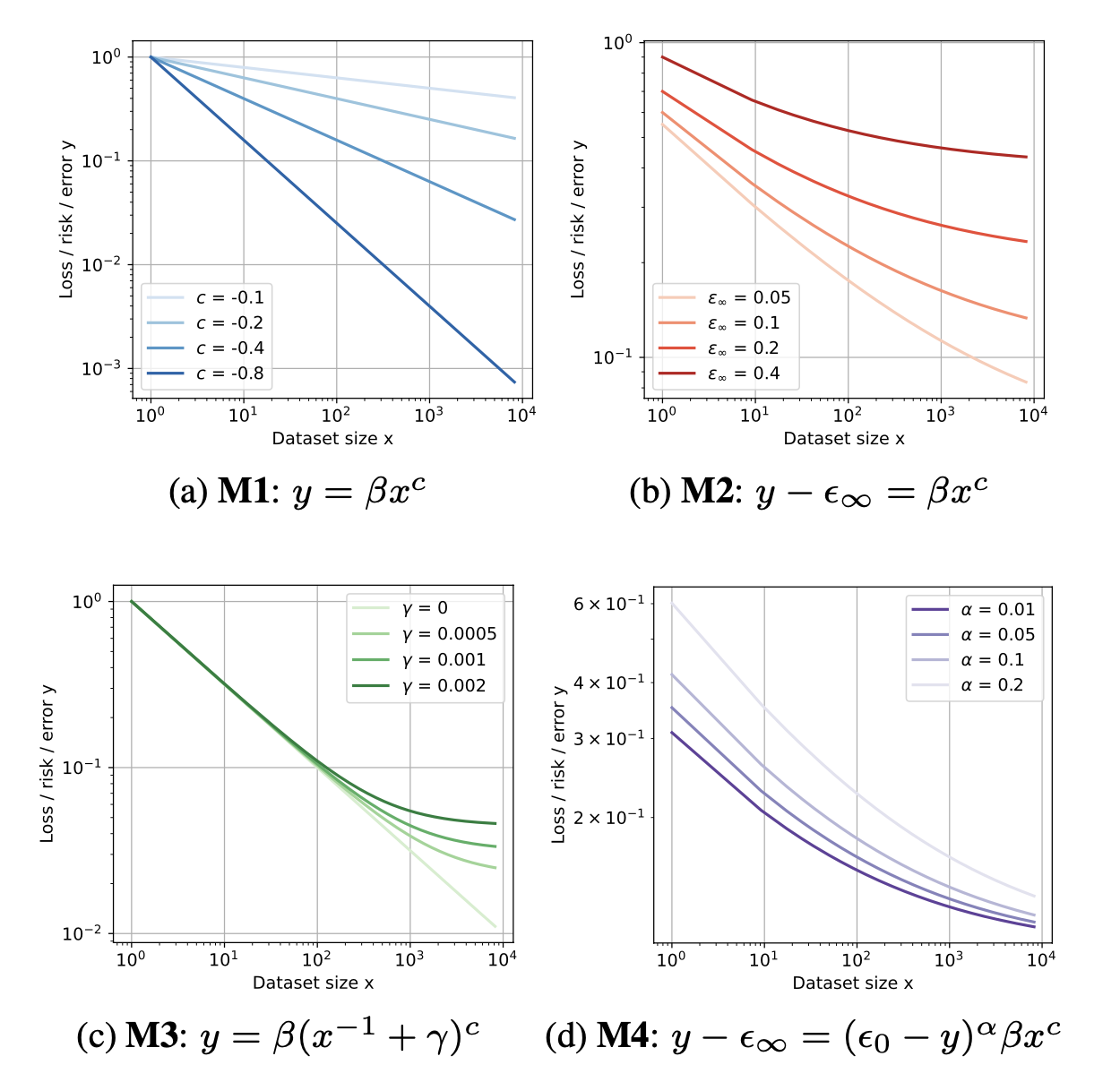
規模化規律估計器通常采用 y = f (x; θ) 的形式,其中 y 表示損失、誤差或測試集上的某些指標,x 表示訓練數據集的大小,θ 表示估計器參數。本研究評估四個候選規模化規律估計器(分別記為 M1、M2、M3 和 M4),每個估計器的復雜度級別均逐級遞增,如圖所示。














)




)