FFNet
- 一、文獻基本信息
- 二、背景介紹
- 三、相關研究
- 1. 以自車為中心的3D目標檢測
- 2. 車路協同3D目標檢測
- 3. 特征流
- 四、FFNet網絡架構
- 1. 車路協同3D目標檢測任務定義
- 2. 特征流網絡
- 2.1 特征流生成
- 2.2 壓縮、傳輸與解壓縮
- 2.3 車輛傳感器數據與基礎設施特征流融合
- 3. 特征流網絡訓練流程
- 五、實驗部分
- 1. 實驗設置
- 2. 實驗比較
- 3. 消融實驗
- 六、總結
一、文獻基本信息
| 文章標題 | Flow-Based feature fusion for vehicle-infrastructure cooperative 3d object detection |
|---|---|
| 會議 | NIPS(NeurIPS) |
| 作者 | Haibo Yu;Yingjuan Tang;Enze Xie;Jilei Mao;Ping Luo;Zaiqing Nie |
| 單位 | The University of Hongkong;Institute for AI Industry Research (AIR), Tsinghua University;Beijing Institute of Technology;Shanghai AI Laboratory |
| 日期 | 2023年11月3日 |
| 論文鏈接 | https://arxiv.org/abs/2311.01682 |
| 代碼鏈接 | https://github.com/haibao-yu/FFNet-VIC3D |
摘要:使用自車和基礎設施傳感器的協同數據可以顯著提升自動駕駛感知能力。然而,時間同步的不確定性和通信限制導致了融合無法對齊的問題,這限制了路側數據的使用。為了解決上述問題,作者提出了一個新的協同檢測框架——特征流網絡(FFNet)特征流網絡是一個基于流的特征融合網絡,可以用特征預測模塊來預測未來時刻的特征并幫助更好地同步車輛和路側傳感器特征。相比從靜態圖像傳輸提取特征,FFNet傳輸了時間一致的連續路側圖像特征流。此外,作者引入了一種自注意力訓練方法,可以使FFNet根據基礎設施傳感器圖像的序列,生成帶有未來時刻預測能力的特征流。在DAIR-V2X數據集上的實驗結果表明,FFNet比現有的協同檢測方法好,且與原始數據相比僅僅需要1/100的傳輸成本。 |
文章整體框架:

二、背景介紹
3D目標檢測是自動駕駛中的重要任務,其提供了周圍障礙物的位置和類別等重要信息。傳統3D目標檢測方法依賴于自車傳感器數據,這限制了感知范圍,并且在長距離檢測和盲點檢測中表現不好,帶來了許多安全隱患。為了解決這些挑戰,車路協同自動駕駛范式得到了更多關注,尤其是基于相機和激光雷達的路側傳感器,這些傳感器比自車安裝的位置更高,提供了更廣泛的感知視野。通過補充額外的路側傳感器數據,可能會獲得更有意義的信息,并提高自動駕駛感知能力。在這篇文章中,作者聚焦于解決車路協同3D目標檢測任務(vehicle-infrastructure cooperative 3D, VIC3d),來增強面對挑戰性交通場景時,自動駕駛系統的安全性和性能。
車路協同目標檢測問題可以定義為通信帶寬限制下的多傳感器感知問題,目前有兩個主要的挑戰:
- 基礎設施數據可能被不同的車輛接收,自車接收的數據和路側傳感器的數據存在同步時間的不確定性(時延不是固定的)
- 車端和路側設備的通信帶寬是有限的
為了解決上述的兩個挑戰,現有的主要融合框架包括三個:
| 融合類型 | 說明 |
|---|---|
| 前融合(early fusion) | 傳輸原始數據進行融合 |
| 后融合(late fusion) | 傳輸檢測結果進行融合 |
| 中間融合(middle fusion) | 傳輸提取特征進行融合 |
因為中間融合的方法相較于前融合降低了通信帶寬的限制,相較于后融合有效提升了融合的精度,所以大部分學者采用的是中間融合的方案。然而,現有的中間融合方案忽視了時間同步的挑戰,導致了時間融合的不對齊。因此,作者提出了FFNet來解決該問題,本文的貢獻如下:
- 本文提出了一個基于流的特征融合框架來解決車路協同目標檢測任務。FFNet傳輸特征流來為特征融合生成對齊特征,提供了一個簡單且統一的操作來融合有價值的信息
- 文本引入了自監督訓練方法來訓練特征流生成器,使得具有特征預測能力的FFNet可以減少不同延遲的帶來的融合錯誤。
- 本文在
DAIR-V2X數據集上對FFNet進行了驗證,證明了其高的檢測精度和較低的傳輸成本。
三、相關研究
1. 以自車為中心的3D目標檢測
3D目標檢測是以自車為中心的自動駕駛的基本任務。自車為中心的3D目標檢測基于傳感器的類別可以分為3類:基于相機的方法,基于激光雷達的方法和基于多傳感器融合的方法。
- 基于相機的方法:例如FCOS3D直接從一張圖像來檢測3D邊界框;或BEVFormer和 M 2 B E V M^2BEV M2BEV將3D圖像投影到BEV視圖,來實現多相機聯合的3D目標檢測。
- 基于激光雷達的方法:例如VoxelNet, SECOND, 和PointPillars將激光雷達點云分成體素(voxels)或圓柱(pillars),并從中提取特征
- 基于多傳感器融合的方法:同時利用相機和點云數據,采用基于點云的融合、基于相機的融合或基于公共空間的融合三類,來進行多傳感器融合
與上述的方法不同,本文提出的方法以點云作為輸入,利用路側和車輛傳感器的數據來克服單車視角的目標檢測。
2. 車路協同3D目標檢測
利用道路基礎設施的信息進行目標檢測,得到了工業界和學術界的廣泛關注。作者總結了一些不同視角的方法:
- 車車視角:關注于車車協同的的算法用V2VNet,DiscoNet,StarNet和SyncNet,常用的數據集包括V2X-Sim、OPV2V、V2V4Real
- 路側視角:Rope3D和BEVHeight、A9=Dataset
- 車路協同:V2X-Seq
現在的方法通過傳輸特征圖或查詢(queries)來實現協同檢測,沒有考慮時間同步的影響。在本文中,作者提出的基于流的融合框架來解決時間同步的問題,并且用簡單統一的方法來降低傳輸損失。本研究和SyncNet有本質的區別(SyncNet通過傳輸共同特征并融合每一幀特征來消除時延)
3. 特征流
流是一個來源于數學的概念,表示著點隨時間變化的運動。這已經被成功地運用到很多計算機視覺任務中,例如:光流、場景流和視頻識別。作為一個從光流中拓展的概念,特征流描述了特征圖隨時間的變化,被廣泛用于不同的視頻理解任務。朱等人1提出了一種以流為引導的特征融合來提升視頻檢測準確率。本文中,作者引入特征流來進行特征預測,從而克服車路協同目標檢測的時間同步問題。
四、FFNet網絡架構
1. 車路協同3D目標檢測任務定義
問題定義: 車路協同目標檢測是通過利用路側和車輛傳感器數據在有限制的無線通信環境下定位和識別周圍目標。本文以點云輸入作為目標,車路協同的輸入包括以下兩個部分:
- 通過自車傳感器在時間 t v t_{v} tv?時捕捉到的點云 P v ( t v ) P_{v}(t_{v}) Pv?(tv?),相對位姿為 M v ( t v ) M_{v}(t_{v}) Mv?(tv?), P v ( ? ) P_{v}\left( \cdot \right) Pv?(?)表示自車激光雷達的捕捉函數。
- 通過路側基礎設施傳感器在時間 t i t_{i} ti?時刻捕捉的點云 P i ( t i ) P_{i}(t_{i}) Pi?(ti?),相對位姿為 M i ( t i ) M_{i}(t_{i}) Mi?(ti?), P i ( ? ) P_{i}\left( \cdot \right) Pi?(?)表示路側激光雷達的捕捉函數。路側傳感器捕捉到的歷史幀也可以用來做協同檢測。
?由于從路側到車端的長距離傳輸需要大量的傳輸時間,因此時間 t i t_{i} ti?是要早于時間 t v t_{v} tv?的。
?此外,因為路側設備的傳輸數據可以被不同的自動駕駛車路接收,所以延誤 ( t v ? t i ) (t_{v}-t_{i}) (tv??ti?)是不確定的。
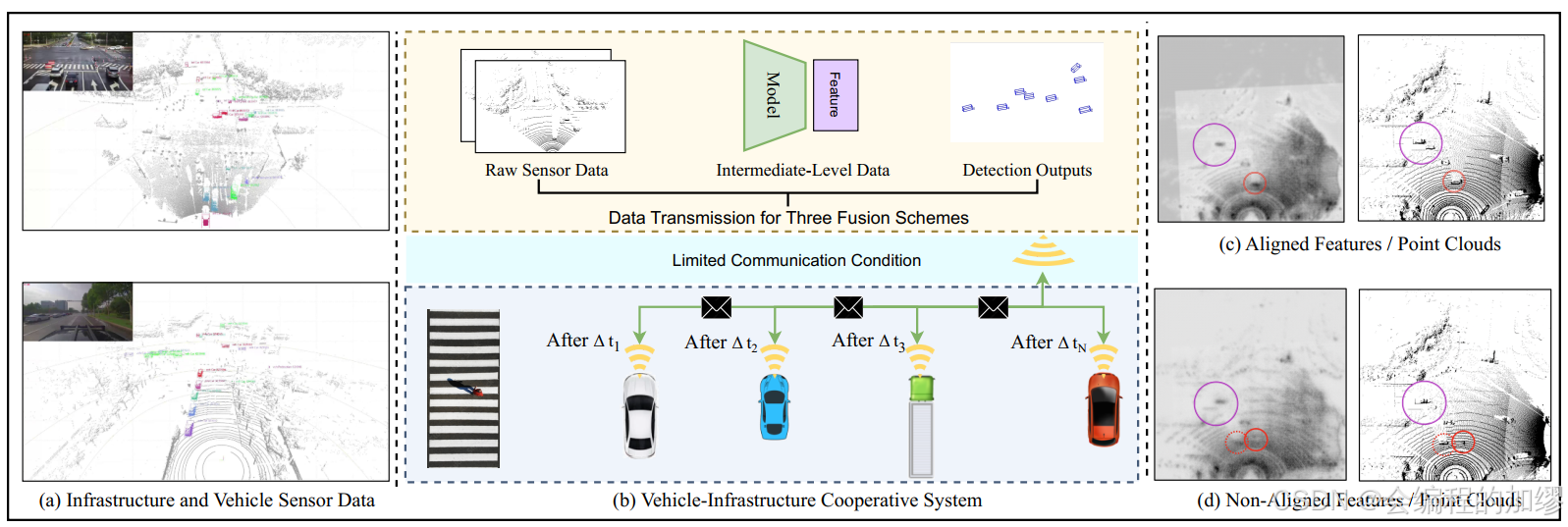
Challenges: 相較于單車自動駕駛,車路協同最大的挑戰便是時間同步和傳輸成本。
Evaluation Metrics:
?平均精度的均值(mean Average Precision, mAP): 通過計算每個類別的平均精度(AP),然后對所有類別的AP取平均值
?平均比特(Average Byte, AB): 這個概念是作者自己在他的另一篇論文中定義的(DAIR-V2X),表示每次傳輸的數據量大小。
2. 特征流網絡
特征流網絡主要包括三個模塊:
1??特征流生成(路側傳感器);
2??特征流的壓縮、傳輸和解壓(路側);
3??將特征流與車輛特征融合,得到檢測結果;
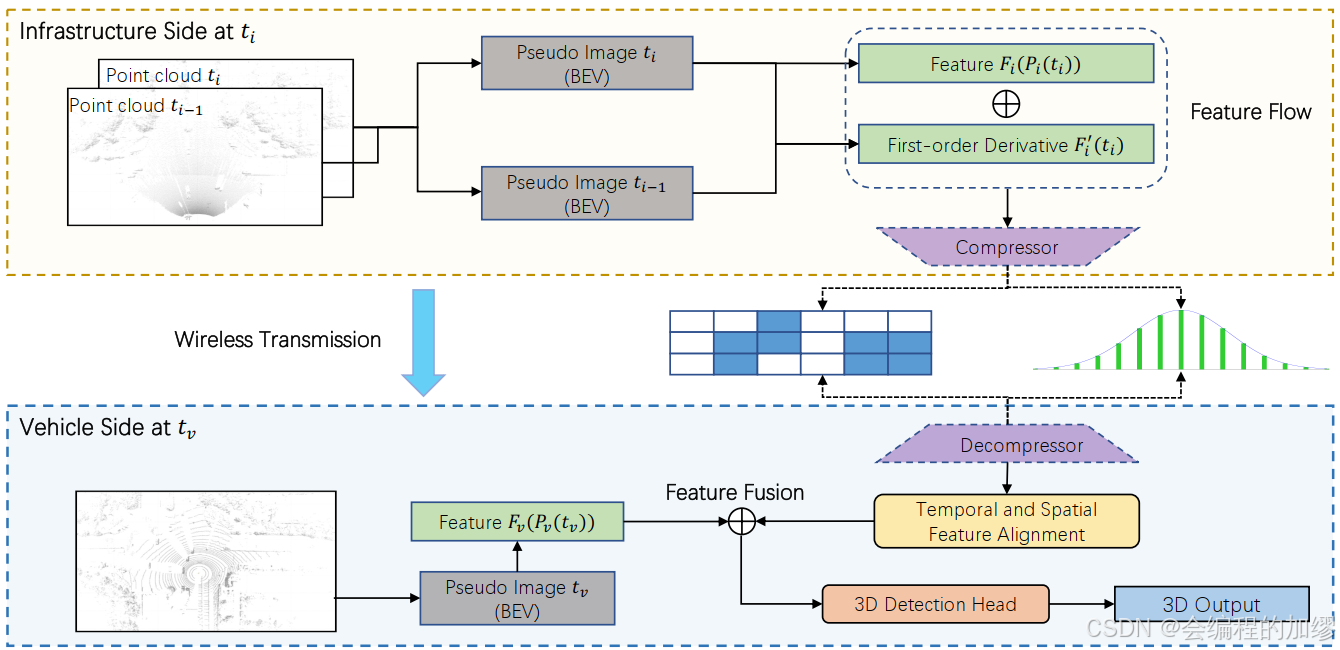
2.1 特征流生成
? 作者將特征流作為一個預測函數,來描述路側傳感器獲得的特征隨時間的改變。具體來說,作者采用了當前的點云幀 P i ( t i ) Pi(t_{i}) Pi(ti?)和路側特征提取器 F i ( ? ) F_{i}(\cdot) Fi?(?),來表征未來時刻t的特征流:
F i ( t ) = F i ( P i ( t i ) ) , t ≥ t i F_{i}(t)=F_{i}(P_{i}(t_{i})),\ \ \ \ \ \ \ \ t\ge t_{i} Fi?(t)=Fi?(Pi?(ti?)),????????t≥ti?
與之前傳輸前一幀特征 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi?(Pi?(ti?))的方法相比,特征流可以直接預測車輛傳感器數據在 t v t_{v} tv?時刻的對齊特征。(?所以采用 F i ( t ) F_{i}(t) Fi?(t),這里的 t t t可以是車輛數據的時間 t v t_{v} tv?)
? 公式中那里到底是 t i t_{i} ti?還是 t t t啊?
為了將特征流應用到傳輸和協同檢測中,兩個問題需要被解決:
1?? 表達和傳輸隨時間變化的連續特征流;
2?? 使特征流具有預測能力;
考慮到 t v → t i t_{v}\to t_{i} tv?→ti?的時間間隔特別短,所以作者采用最簡單的一階導數來表征連續特征流隨時間的變化,如下式:
F i ~ ( t i + Δ t ) ≈ F i ( P i ( t i ) ) + Δ t ? F i ′ ~ ( t i ) \tilde{F_{i}}(t_i+\Delta t) \approx F_{i}(P_{i}(t_{i})) + \Delta t * \tilde{F'_{i}}(t_{i}) Fi?~?(ti?+Δt)≈Fi?(Pi?(ti?))+Δt?Fi′?~?(ti?)
其中, F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′?~?(ti?)表示特征流的一階導數, Δ t \Delta t Δt表示未來的短時間。因此,我們僅需要獲得特征 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi?(Pi?(ti?))和特征流的一階導數 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′?~?(ti?)就可以估計特征流 F i ( t ) F_{i}(t) Fi?(t)。當一個自動駕駛汽車接收到了 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi?(Pi?(ti?))和 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′?~?(ti?)在不確定的延誤之后,本文能用最小的計算量來生成對齊車輛傳感器數據的基礎設施特征(因為它僅需要線性計算)。為了能使特征流具備預測能力,本文從基礎設施歷史幀 I i ( t i ? N + 1 ) , … , I i ( t i ? 1 ) , I i ( t i ) I_{i}(t_{i}-N+1), \dots,I_{i}(t_{i}-1),I_{i}(t_{i}) Ii?(ti??N+1),…,Ii?(ti??1),Ii?(ti?),用網絡提取特征流 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′?~?(ti?)的一階導數。在本篇文章中, N N N為2,即表示兩個連續的基礎設施幀 P i ( t i ? 1 ) P_{i}(t_{i}-1) Pi?(ti??1)和 P i ( t i ) P_{i}(t_{i}) Pi?(ti?)
? 這么設置下來,與BEVFormer中的有何區別?
特別地,我們首先用Pillar Feature Net將兩個連續的點云轉換為BEV視圖的兩個偽圖像(pseudo-images),每一幀的尺寸為[384, 288, 288] 。然后,我們拼接兩個BEV偽圖像為尺寸[768, 288, 288],將拼接后的偽圖像輸入到一個13層的主干網絡和一個3層特征金字塔網絡(FPN)中,像SECOND一樣,生成估計的一階導數 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′?~?(ti?),其尺寸為[364, 288, 288]。(作者在附錄中寫了每一個網絡的具體尺寸)
2.2 壓縮、傳輸與解壓縮
壓縮:為了減少冗余信息,減少傳輸成本,作者采用了兩個壓縮器(compressors)來壓縮特征 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi?(Pi?(ti?))和導數 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′?~?(ti?),在每個壓縮器中利用三個Conv-Bn-ReLu塊將特征尺寸從[384, 288, 288]壓縮到[12, 36, 36]。本文在廣播(broadcast)壓縮特征流來使其與路側的時間戳和標定文件相關聯。同時,作者還采用注意力蒙版(attention mask)和量化技術(quantization techniques)進行進一步壓縮,使特征關注感興趣的區域。
解壓縮:在接收到車輛發送的特征流后,車輛端采用兩個解壓器,每個解壓器采用三個Deconv-Bn-ReLU塊組成,將壓縮的特征和一階導變為原始尺寸[384, 288, 288]
2.3 車輛傳感器數據與基礎設施特征流融合
作者用特征流來預測基礎設施在特征 t v t_{v} tv?的特征,以對齊車輛的特征,如下:
F ~ i ( t v ) ≈ F i ( P i ( t i ) ) + ( t v ? t i ) ? F i ′ ~ ( t i ) \tilde{F}_{i}(t_{v}) \approx F_{i}(P_{i}(t_{i}))+(t_{v}-t_{i})*\tilde{F'_{i}}(t_{i}) F~i?(tv?)≈Fi?(Pi?(ti?))+(tv??ti?)?Fi′?~?(ti?)
F i ~ ( t v ) \tilde{F_{i}}(t_{v}) Fi?~?(tv?)表示特征流預測的路側傳感器在 t v t_{v} tv?時刻的特征,這種線性的方法有效地補償了不確定延遲,且僅需要很小的計算。隨后,預測的路側傳感器在 t v t_{v} tv?時刻的特征利用對應的標定文件,轉換到車輛坐標系。既然得到了路側傳感器和車載傳感器在 t v t_{v} tv?時刻的BEV特征圖,且他們都在車輛坐標系下,那么就可以將他們的特征進行融合。(如下圖所示)在車輛興趣區域外的特征都從車輛基礎設施特征中刪除,空的位置用0來填充。將車輛和路側的設施進行拼接,并用Conv-Bn-Relu塊來融合拼接后的特征。
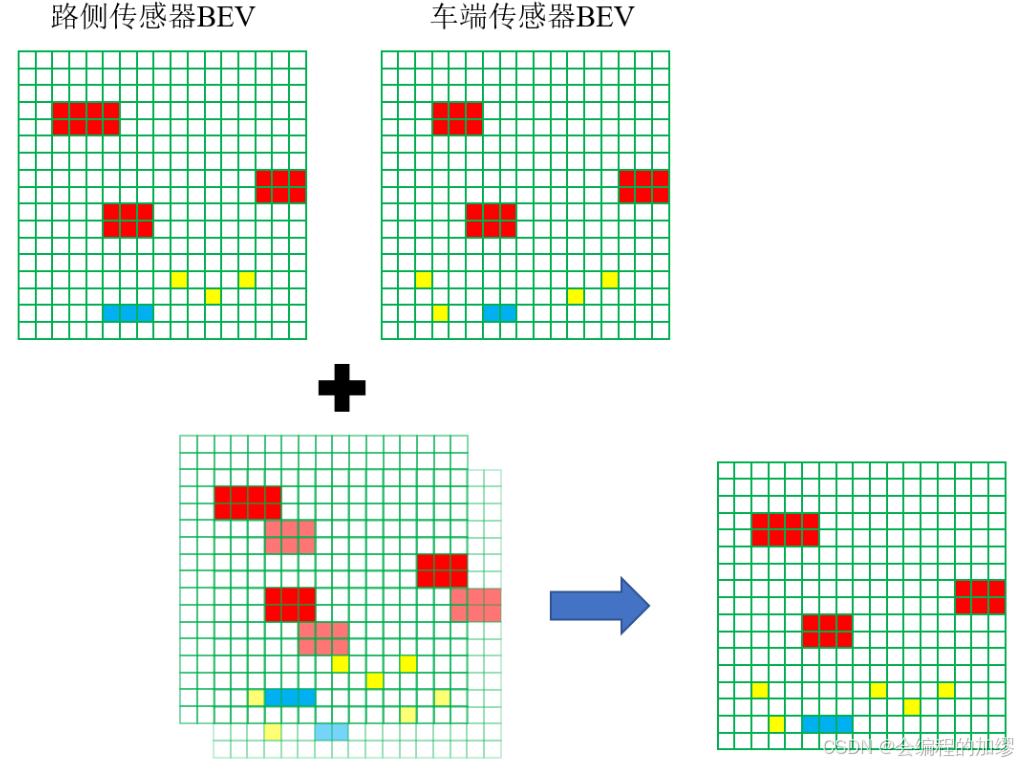
最后,將融合特征輸入到3D檢測頭中,生成更加準確的位置和識別結果。
3. 特征流網絡訓練流程
FFNet的訓練流程包括兩個階段:
1?? 用端到端的方式訓練基礎的融合框架(不考慮延遲):這一階段的目標是使FFNet融合基礎設施特征和車輛特征來增強檢測性能。具體來說,作者利用從車端和路側獲得的協同數據和標注數據來訓練FFNet。
2?? 用自監督訓練來訓練特征流生成器:通過基礎設施序列幀的時間關聯,來利用自監督學習來訓練特征生成器。這個想法是通過鄰近的基礎設施幀來構造真值,且不需要額外的手動標注。具體而言,作者生成了訓練特征對 D = { d t i , k = ( P i ( t i ? 1 ) , P i ( i ) , P i ( t i + k ) ) } D=\{d_{t_{i},k}=(P_{i}(t_{i}-1),P_{i}(i),P_{i}(t_{i}+k))\} D={dti?,k?=(Pi?(ti??1),Pi?(i),Pi?(ti?+k))},其中, P i ( t i ? 1 ) P_{i}(t_{i}-1) Pi?(ti??1) 和 P i ( i ) P_{i}(i) Pi?(i)是兩個連續的基礎設施點云幀, P i ( t i + k ) ) P_{i}(t_{i}+k)) Pi?(ti?+k))是 P i ( t i ) P_{i}(t_{i}) Pi?(ti?)的第 ( k + 1 ) (k+1) (k+1)幀
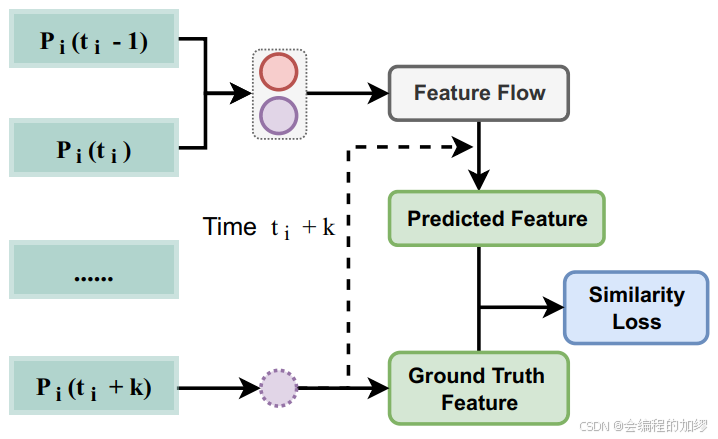
并且,作者構建了一個損失函數來優化特征生成器,該損失函數的目標是 t i + k t_{i}+k ti?+k時刻預測的特征流盡可能地接近 t i + k t_i+k ti?+k時刻的特征(作者是通過余弦相似性實現的)。
五、實驗部分
1. 實驗設置
數據集:作者使用了公開的真實世界DAIR-V2X數據集,該數據集包含100多個場景,以及在28個具有挑戰性的交通路口從基礎設施和車輛傳感器(攝像頭和激光雷達)采集的18000個數據對。該數據集包含9311對具有車路協同視角的協同3D標注數據,其中每個物體都被標注了相應的類別(轎車、公交車、卡車或廂式貨車)。數據集按5 : 2 : 3的比例劃分為訓練集、驗證集和測試集,所有模型均在驗證集上進行評估。此外,原始傳感器數據僅對測試集開放。
實施細節:作者使用MMDetection3D作為代碼庫,在DAIR-V2X訓練集上對特征融合基礎模型進行了40個epoch的訓練,學習率為0.001,權重衰減為0.01。為了構建用于訓練特征流生成器的D,我們從訓練部分中選取每一對數據,并在范圍內隨機設置k值。關于k和D的更多信息可在3.3節中找到。FFNet的預訓練使用已訓練好的特征融合基礎模型。我們在 D u D_{u} Du?上對特征流生成器進行了10個epoch的訓練,學習率為0.001,權重衰減為0.01。所有訓練和評估均在NVIDIA GeForce RTX 3090 GPU上進行。檢測性能使用KITTI評估檢測指標進行衡量,分別包括鳥瞰圖(BEV)平均精度均值(mAP)以及交并比(IoU)為0.5和0.7時的3D mAP。對于位于矩形區域[0, -39.12, 100, 39.12]內的物體,僅考慮汽車類別。附錄中提供了關于FFNet和融合方法的更多實現細節。
2. 實驗比較
作者將FFNet與四類融合方法進行了比較:非融合方法(例如,PointPillars[17]和AutoAlignV2[4])、早期融合、晚期融合、中期融合(例如,DiscoNet[20])以及V2VNet[19]。
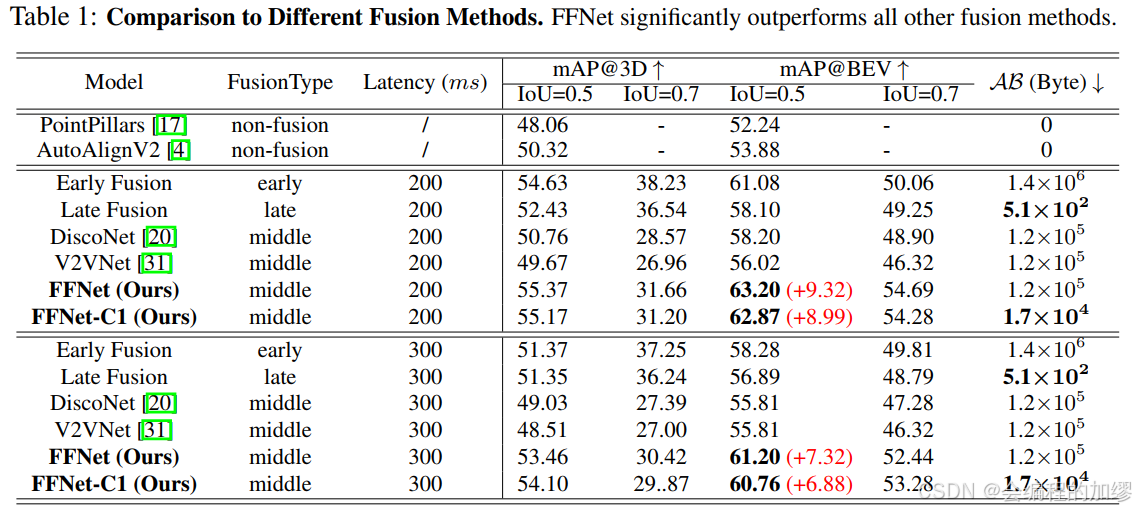
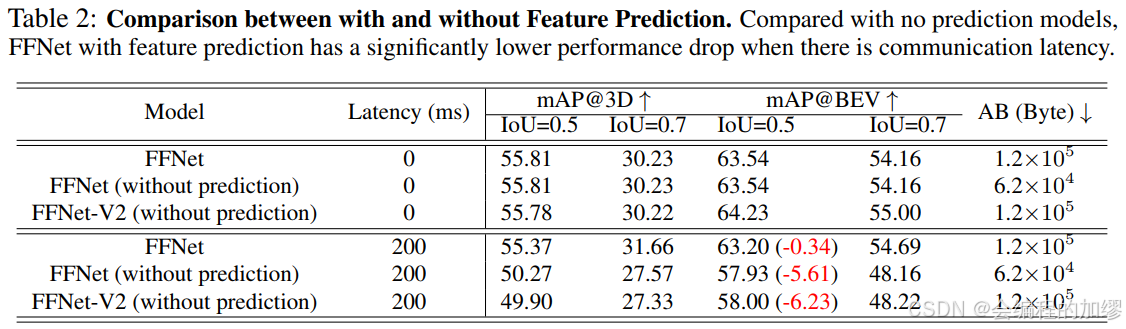
3. 消融實驗
對比了有無特征流的特征預測的效果,發現在有延遲的情況下,特征流模塊的預測效果較為明顯。
六、總結
總結: 本文介紹了FFNet,這是一種創新的用于車路協同3D(VIC3D)目標檢測的中級協同框架。FFNet通過利用壓縮的特征流進行協同檢測,有效地解決了與時間異步和傳輸成本相關的挑戰。通過在DAIR-V2X數據集上進行的大量實驗,FFNet展現出相較于現有最先進方法更優越的性能。此外,FFNet可以擴展到各種模態,包括圖像和多模態數據,使其成為一種通用的解決方案。而且,FFNet在多車協同感知領域具有很大的潛力,并通過利用額外的幀來增強特征預測能力。所提出的FFNet框架結合了特征預測和自監督學習,為VIC3D目標檢測提供了一條很有前景的途徑,并且在未來解決各種協同感知任務方面具有潛力。 |
今天給大家帶來的分享就到這里,歡迎大家交流討論!補充一點:該文中的FFNet,在作者2025年發表在AAAI的另一篇文章(見該博客)中,也是用了該思想來進行時序融合。
Xizhou Zhu, Yujie Wang, Jifeng Dai, Lu Yuan, and Yichen Wei. Flow-guided feature aggregation for video
object detection ??



















