基于Tripletloss實現的表示型文本匹配
- 目標
- 數據準備
- 參數配置
- 數據處理
- Triplet Loss目標
- Triplet Loss計算公式
- 公式說明
- 模型構建
- 網絡結構設計
- 網絡訓練目標
- 損失函數設計
- 主程序
- 推理預測
- 類初始化
- 加載問答知識庫
- 文本向量化
- 知識庫查詢
- 主程序`main`測試
- 測試效果
- 參考博客
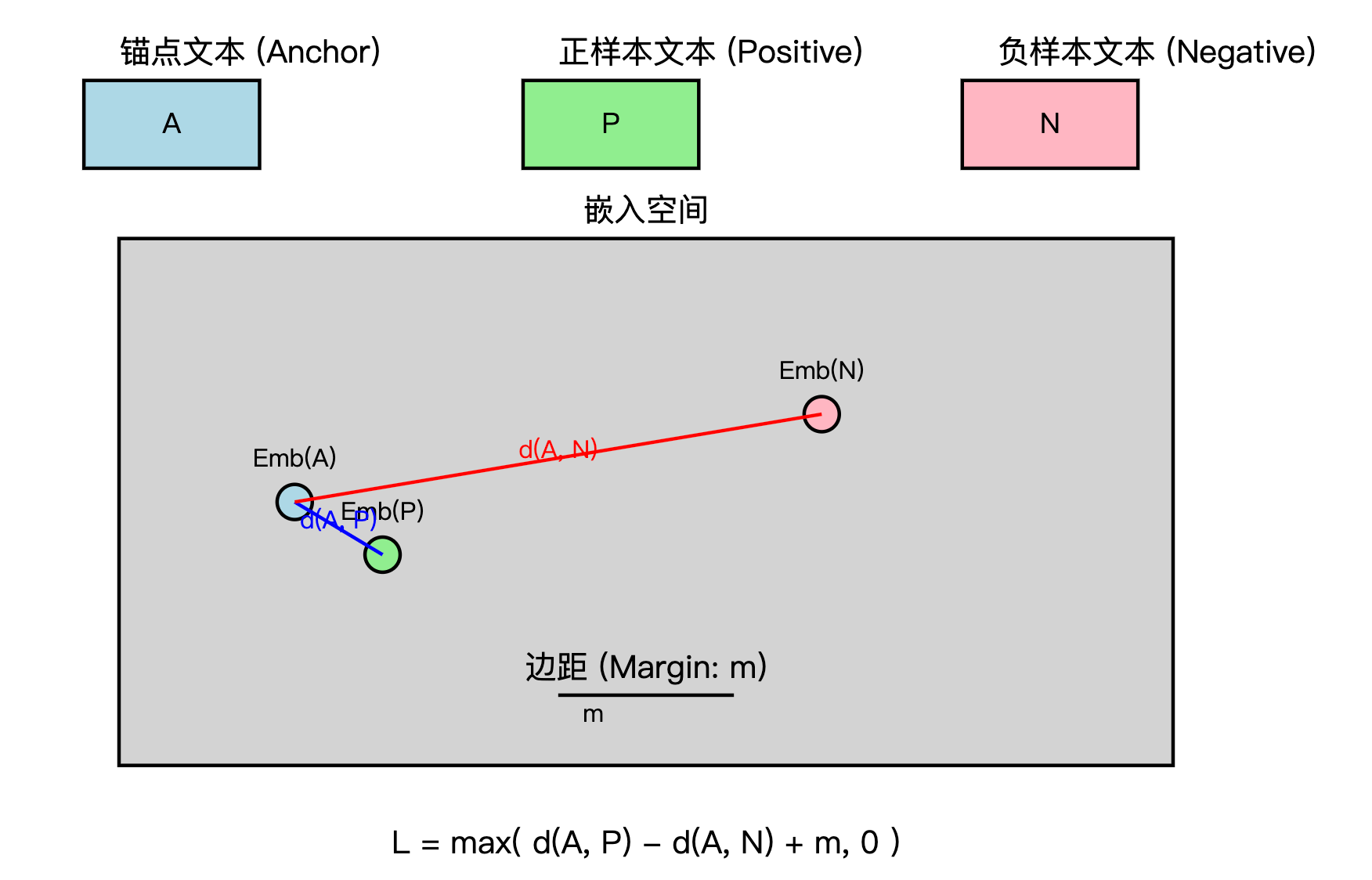
目標
在此之前已經實現了基于余弦相似度實現的文本匹配1,本文將實現基于tripletloss實現文本匹配,并實現簡單的意圖識別問答系統。主要做法同樣是基于給定的詞表,將輸入的文本基于jieba分詞分割為若干個詞,然后將詞基于詞表進行初步編碼,之后經過網絡表征層得到文本的表征向量,只不過最后在訓練的時候使用TripletMarginLoss而不是之前的CosineEmbeddingLoss,推理預測時還是使用文本的表征向量。
數據準備
預訓練模型bert-base-chinese預訓練模型
詞表文件chars.txt
類別標簽文件schema.json
{"停機保號": 0,"密碼重置": 1,"寬泛業務問題": 2,"親情號碼設置與修改": 3,"固話密碼修改": 4,"來電顯示開通": 5,"親情號碼查詢": 6,"密碼修改": 7,"無線套餐變更": 8,"月返費查詢": 9,"移動密碼修改": 10,"固定寬帶服務密碼修改": 11,"UIM反查手機號": 12,"有限寬帶障礙報修": 13,"暢聊套餐變更": 14,"呼叫轉移設置": 15,"短信套餐取消": 16,"套餐余量查詢": 17,"緊急停機": 18,"VIP密碼修改": 19,"移動密碼重置": 20,"彩信套餐變更": 21,"積分查詢": 22,"話費查詢": 23,"短信套餐開通立即生效": 24,"固話密碼重置": 25,"解掛失": 26,"掛失": 27,"無線寬帶密碼修改": 28
}
訓練集數據train.json訓練集數據
驗證集數據valid.json驗證集數據
參數配置
config.py
# -*- coding: utf-8 -*-"""
配置參數信息
"""
# -*- coding: utf-8 -*-"""
配置參數信息
"""Config = {"model_path": "model_output","schema_path": "../data/schema.json","train_data_path": "../data/train.json","valid_data_path": "../data/valid.json","pretrain_model_path":r"../../../bert-base-chinese","vocab_path":r"../../../bert-base-chinese/vocab.txt","max_length": 20,"hidden_size": 256,"epoch": 10,"batch_size": 128,"epoch_data_size": 10000, #每輪訓練中采樣數量"positive_sample_rate":0.5, #正樣本比例"optimizer": "adam","learning_rate": 1e-3,"triplet_margin": 1.0,
}
數據處理
loader.py
# -*- coding: utf-8 -*-import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
"""
數據加載
"""class DataGenerator:def __init__(self, data_path, config):self.config = configself.path = data_pathself.tokenizer = load_vocab(config["vocab_path"])self.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.schema = load_schema(config["schema_path"])self.train_data_size = config["epoch_data_size"] #由于采取隨機采樣,所以需要設定一個采樣數量,否則可以一直采self.data_type = None #用來標識加載的是訓練集還是測試集 "train" or "test"self.load()def load(self):self.data = []self.knwb = defaultdict(list)with open(self.path, encoding="utf8") as f:for line in f:line = json.loads(line)#加載訓練集if isinstance(line, dict):self.data_type = "train"questions = line["questions"]label = line["target"]for question in questions:input_id = self.encode_sentence(question)input_id = torch.LongTensor(input_id)self.knwb[self.schema[label]].append(input_id)#加載測試集else:self.data_type = "test"assert isinstance(line, list)question, label = lineinput_id = self.encode_sentence(question)input_id = torch.LongTensor(input_id)label_index = torch.LongTensor([self.schema[label]])self.data.append([input_id, label_index])returndef encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))input_id = self.padding(input_id)return input_id#補齊或截斷輸入的序列,使其可以在一個batch內運算def padding(self, input_id):input_id = input_id[:self.config["max_length"]]input_id += [0] * (self.config["max_length"] - len(input_id))return input_iddef __len__(self):if self.data_type == "train":return self.config["epoch_data_size"]else:assert self.data_type == "test", self.data_typereturn len(self.data)def __getitem__(self, index):if self.data_type == "train":return self.random_train_sample() #隨機生成一個訓練樣本else:return self.data[index]#隨機生成3元組樣本,2正1負def random_train_sample(self):standard_question_index = list(self.knwb.keys())# 先選定兩個意圖,之后從第一個意圖中取2個問題,第二個意圖中取一個問題p, n = random.sample(standard_question_index, 2)# 如果某個意圖下剛好只有一條問題,那只能兩個正樣本用一樣的;# 這種對訓練沒幫助,因為相同的樣本距離肯定是0,但是數據充分的情況下這種情況很少if len(self.knwb[p]) == 1:s1 = s2 = self.knwb[p][0]#這應當是一般情況else:s1, s2 = random.sample(self.knwb[p], 2)# 隨機一個負樣本s3 = random.choice(self.knwb[n])# 前2個相似,后1個不相似,不需要額外在輸入一個0或1的label,這與一般的loss計算不同return [s1, s2, s3]#加載字表或詞表
def load_vocab(vocab_path):token_dict = {}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):token = line.strip()token_dict[token] = index + 1 #0留給padding位置,所以從1開始return token_dict#加載schema
def load_schema(schema_path):with open(schema_path, encoding="utf8") as f:return json.loads(f.read())#用torch自帶的DataLoader類封裝數據
def load_data(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dl還是一樣自定義數據加載器 DataGenerator,用于加載和處理文本數據。主要區別在于訓練時采樣策略的處理,random_train_sample函數選取2個正樣本1個負樣本作為anchor、positive、negative。triplet loss訓練要求positive樣本和anchor相比較negative樣本更接近,也即同類樣本更加接近,不同類樣本更加遠離。它在面部識別、圖像檢索、個性化推薦等領域得到了廣泛應用。
Triplet Loss目標
其目標是通過三元組(triplet)數據,即:一個錨點(anchor)、一個正樣本(positive)和一個負樣本(negative)來學習特征空間,使得:
- 錨點與正樣本之間的距離應該盡可能小。
- 錨點與負樣本之間的距離應該盡可能大。
Triplet Loss計算公式
假設:
- ( a ) 是錨點樣本(anchor)。
- ( p ) 是與錨點相同類別的正樣本(positive)。
- ( n ) 是與錨點不同類別的負樣本(negative)。
那么,Triplet Loss 的計算公式為:
L ( a , p , n ) = max ? ( ∥ f ( a ) ? f ( p ) ∥ 2 2 ? ∥ f ( a ) ? f ( n ) ∥ 2 2 + α , 0 ) L(a, p, n) = \max \left( \| f(a) - f(p) \|_2^2 - \| f(a) - f(n) \|_2^2 + \alpha, 0 \right) L(a,p,n)=max(∥f(a)?f(p)∥22??∥f(a)?f(n)∥22?+α,0)
其中:
- f ( x ) f(x) f(x) 是輸入樣本 x x x 的特征向量(通常由神經網絡模型生成)。
- ∥ f ( a ) ? f ( p ) ∥ 2 2 \| f(a) - f(p) \|_2^2 ∥f(a)?f(p)∥22? 是錨點 a a a 和正樣本 p p p 之間的歐幾里得距離的平方。
- ∥ f ( a ) ? f ( n ) ∥ 2 2 \| f(a) - f(n) \|_2^2 ∥f(a)?f(n)∥22? 是錨點 a a a 和負樣本 n n n 之間的歐幾里得距離的平方。
- ∥ ? ∥ 2 \| \cdot \|_2 ∥?∥2? 表示歐幾里得距離(L2 距離)。
- α \alpha α 是一個超參數,稱為“邊際”或“閾值”,用于控制負樣本與錨點之間的最小距離差,防止損失值過小。
公式說明
-
錨點與正樣本的距離: ∥ f ( a ) ? f ( p ) ∥ 2 2 \| f(a) - f(p) \|_2^2 ∥f(a)?f(p)∥22?
這項度量錨點和正樣本之間的相似性,目的是最小化這個距離。 -
錨點與負樣本的距離: ∥ f ( a ) ? f ( n ) ∥ 2 2 \| f(a) - f(n) \|_2^2 ∥f(a)?f(n)∥22?
這項度量錨點和負樣本之間的差異,目標是最大化這個距離。 -
邊際 α \alpha α:
用于確保錨點與負樣本之間的距離至少大于錨點與正樣本之間的距離加上一個邊際 α \alpha α,從而避免了負樣本距離過近的情況。
模型構建
model.py
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
"""
建立網絡模型結構
"""class SentenceEncoder(nn.Module):def __init__(self, config):super(SentenceEncoder, self).__init__()hidden_size = config["hidden_size"]vocab_size = config["vocab_size"] + 1max_length = config["max_length"]self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True)self.layer = nn.Linear(hidden_size, hidden_size)self.dropout = nn.Dropout(0.5)#輸入為問題字符編碼def forward(self, x):sentence_length = torch.sum(x.gt(0), dim=-1)x = self.embedding(x)#使用lstm# x, _ = self.layer(x)#使用線性層x = self.layer(x)# x.shape[1]表示kernel_size,表示池化窗口的大小,# 輸入是一個形狀為 (batch_size, channels, length) 張量x = nn.functional.max_pool1d(x.transpose(1, 2), x.shape[1]).squeeze()return xclass SiameseNetwork(nn.Module):def __init__(self, config):super(SiameseNetwork, self).__init__()self.sentence_encoder = SentenceEncoder(config)self.margin = config["triplet_margin"]self.loss = nn.TripletMarginLoss(self.margin,2)# 計算余弦距離 1-cos(a,b)# cos=1時兩個向量相同,余弦距離為0;cos=0時,兩個向量正交,余弦距離為1def cosine_distance(self, tensor1, tensor2):tensor1 = torch.nn.functional.normalize(tensor1, dim=-1)tensor2 = torch.nn.functional.normalize(tensor2, dim=-1)cosine = torch.sum(torch.mul(tensor1, tensor2), axis=-1)return 1 - cosinedef cosine_triplet_loss(self, a, p, n, margin=None):ap = self.cosine_distance(a, p)an = self.cosine_distance(a, n)if margin is None:diff = ap - an + 0.1else:diff = ap - an + marginres = diff[diff.gt(0)]if len(res) == 0:return torch.tensor(1e-6)return torch.mean(res)#sentence : (batch_size, max_length)def forward(self, sentence1, sentence2=None, sentence3=None):#同時傳入3個句子,則做tripletloss的loss計算if sentence2 is not None and sentence3 is not None:vector1 = self.sentence_encoder(sentence1)vector2 = self.sentence_encoder(sentence2)vector3 = self.sentence_encoder(sentence3)return self.loss(vector1, vector2, vector3)return self.cosine_triplet_loss(vector1, vector2, vector3, self.margin)#單獨傳入一個句子時,認為正在使用向量化能力else:return self.sentence_encoder(sentence1)def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)網絡結構設計
該代碼實現了一個Siamese Network,主要用于計算文本的相似度。模型由兩部分組成:SentenceEncoder和SiameseNetwork。SentenceEncoder是一個句子編碼器,用于將輸入的文本轉換為固定維度的向量表示。它通過一個嵌入層(embedding layer)將單詞轉換為稠密的向量表示,然后通過線性層進行特征提取。為了捕獲句子的全局信息,使用最大池化(MaxPool)操作,從每個維度中選擇最大的值,這有助于保留關鍵信息。SiameseNetwork包含兩個這樣的編碼器,分別用于處理兩個輸入句子,并將其輸出向量進行比較。
網絡訓練目標
Siamese網絡的訓練目標是讓相似的句子對的向量表示更接近,不相似的句子對的向量表示更遠離。為了實現這一目標,模型通過計算兩個輸入句子的相似度來進行優化。這個過程通常使用對比學習的方法,在每一輪訓練時,網絡通過最小化句子對之間的距離來優化其參數。在訓練過程中,網絡將接受來自數據集的句子對,每一對包含兩個句子和它們的標簽,標簽表示句子對是否相似。通過這種方式,模型學習到如何將相似的句子映射到相近的向量空間,并將不相似的句子映射到較遠的空間。
損失函數設計
模型的損失函數設計主要有兩種選擇,具體取決于使用的距離度量方法。首先,SiameseNetwork類支持使用余弦相似度來計算句子對之間的相似度。這種方式通過計算兩個向量的余弦值來度量它們的相似性,值越大表示越相似。其次,模型還支持使用三元組損失(Triplet Loss)。三元組損失是一種常用的度量學習方法,它通過比較一個“錨”句子、正樣本(相似句子)和負樣本(不相似句子)的距離,確保正樣本距離錨點更近,負樣本距離錨點更遠。三元組損失函數通過最小化這個距離差異來訓練模型,從而優化句子編碼器的表示能力,提升模型的相似度計算精度。
該模型通過最小化損失函數來優化句子編碼器的參數,從而提升句子相似度的預測能力,廣泛應用于文本相似度計算、語義匹配等任務。模型的訓練和推理過程需要通過對比句子對(或三元組)來進行優化,最終使得模型能夠準確判斷兩個句子之間的語義相似性。
主程序
main.py
# -*- coding: utf-8 -*-import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import SiameseNetwork, choose_optimizer
from loader import load_datalogging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型訓練主程序
"""def main(config):#創建保存模型的目錄if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])#加載訓練數據train_data = load_data(config["train_data_path"], config)#加載模型model = SiameseNetwork(config)# 判斷是否有 GPU 支持mps_flag = torch.backends.mps.is_available()device = torch.device("cpu")model = model.to(device)if not mps_flag:device = torch.device("mps") # 使用 Metal 后端print("Using GPU with Metal backend")model = model.to(device) # 將模型遷移到 Metal 后端(MPS)else:print("Using CPU") # 如果沒有 GPU,則使用 CPU# # 標識是否使用gpu# cuda_flag = torch.cuda.is_available()# if cuda_flag:# logger.info("gpu可以使用,遷移模型至gpu")# model = model.cuda()#加載優化器optimizer = choose_optimizer(config, model)#訓練for epoch in range(config["epoch"]):epoch += 1model.train()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):optimizer.zero_grad()# if mps_flag: #如果gpu可用則使用gpu加速# batch_data = [d.to('mps') for d in batch_data]anchor_ids, positive_ids, negative_ids = batch_dataanchor_ids = anchor_ids.to(device)positive_ids = positive_ids.to(device)negative_ids = negative_ids.to(device)loss = model(anchor_ids, positive_ids, negative_ids) #計算losstrain_loss.append(loss.item())#每輪訓練一半的時候輸出一下loss,觀察下降情況if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)loss.backward() #反向傳播梯度計算optimizer.step() #更新模型參數logger.info("epoch average loss: %f" % np.mean(train_loss))model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)returnif __name__ == "__main__":main(Config)
主程序核心流程包括數據加載、模型訓練以及反向傳播更新。
-
訓練數據加載:通過
load_data函數從config["train_data_path"]路徑加載訓練數據,并返回train_data。每個訓練數據包含一個三元組(anchor, positive, negative),這些數據在訓練過程中用于計算Siamese Network的損失。 -
模型訓練過程:
- 首先,創建
SiameseNetwork模型并將其遷移到適當的設備(CPU或GPU/Metal后端)。模型通過model.to(device)遷移到指定設備,確保可以利用GPU加速訓練。 - 然后,定義優化器
optimizer,并開始訓練過程。每個epoch內,程序遍歷所有訓練數據,獲取當前batch的三元組(anchor_ids, positive_ids, negative_ids)。
- 首先,創建
-
損失計算與反向傳播:
- 對于每個batch,模型計算當前三元組的損失:
loss = model(anchor_ids, positive_ids, negative_ids)。這里,模型通過計算anchor和positive、negative之間的相似度來得到損失。 - 損失計算后,通過
loss.backward()進行反向傳播,計算梯度。梯度反向傳播使得模型能夠更新其參數以最小化損失。 optimizer.step()則根據計算得到的梯度更新模型的參數,從而逐步優化模型。
- 對于每個batch,模型計算當前三元組的損失:
-
訓練日志:每個batch的損失會輸出,用于跟蹤訓練進度,每個epoch結束時,計算并輸出平均損失。
最終,訓練完成后,模型參數會被保存至指定路徑。
推理預測
predict.py
# -*- coding: utf-8 -*-
import jieba
import torch
import logging
from loader import load_data
from config import Config
from model import SiameseNetwork, choose_optimizer"""
模型效果測試
"""class Predictor:def __init__(self, config, model, knwb_data):self.config = configself.model = modelself.train_data = knwb_dataif torch.cuda.is_available():self.model = model.cuda()else:self.model = model.cpu()self.model.eval()self.knwb_to_vector()#將知識庫中的問題向量化,為匹配做準備#每輪訓練的模型參數不一樣,生成的向量也不一樣,所以需要每輪測試都重新進行向量化def knwb_to_vector(self):self.question_index_to_standard_question_index = {}self.question_ids = []self.vocab = self.train_data.dataset.vocabself.schema = self.train_data.dataset.schemaself.index_to_standard_question = dict((y, x) for x, y in self.schema.items())for standard_question_index, question_ids in self.train_data.dataset.knwb.items():for question_id in question_ids:#記錄問題編號到標準問題標號的映射,用來確認答案是否正確self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_indexself.question_ids.append(question_id)with torch.no_grad():question_matrixs = torch.stack(self.question_ids, dim=0)if torch.cuda.is_available():question_matrixs = question_matrixs.cuda()self.knwb_vectors = self.model(question_matrixs)#將所有向量都作歸一化 v / |v|self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)returndef encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))return input_iddef predict(self, sentence):input_id = self.encode_sentence(sentence)input_id = torch.LongTensor([input_id])if torch.cuda.is_available():input_id = input_id.cuda()with torch.no_grad():test_question_vector = self.model(input_id) #不輸入labels,使用模型當前參數進行預測res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)hit_index = int(torch.argmax(res.squeeze())) #命中問題標號hit_index = self.question_index_to_standard_question_index[hit_index] #轉化成標準問編號return self.index_to_standard_question[hit_index]if __name__ == "__main__":knwb_data = load_data(Config["train_data_path"], Config)model = SiameseNetwork(Config)model.load_state_dict(torch.load("model_output/epoch_10.pth"))pd = Predictor(Config, model, knwb_data)sentence = "發什么有短信告訴說手機話費"res = pd.predict(sentence)print(res)while True:sentence = input("請輸入:")print(pd.predict(sentence))這段代碼主要是基于Siamese網絡的文本匹配,實現簡單文本意圖識別的問答系統。通過訓練得到的模型,系統能夠將輸入的問題與知識庫中的問題進行相似度比較,并返回最匹配的標準問題。主要功能是將輸入問題與預訓練模型進行匹配,并返回最相關的標準問題。代碼流程包括問題向量化、輸入句子編碼、相似度計算和最終的預測結果輸出。
類初始化
class Predictor:def __init__(self, config, model, knwb_data):self.config = configself.model = modelself.train_data = knwb_dataif torch.cuda.is_available():self.model = model.cuda()else:self.model = model.cpu()self.model.eval()self.knwb_to_vector()
__init__方法中,config是配置文件,model是訓練好的Siamese網絡模型,knwb_data是訓練數據。model.eval():將模型設置為推理模式,禁用掉訓練時的dropout等機制。knwb_to_vector()方法被調用,目的是將訓練數據中的問題轉化為向量,以便后續進行匹配。
加載問答知識庫
def knwb_to_vector(self):self.question_index_to_standard_question_index = {}self.question_ids = []self.vocab = self.train_data.dataset.vocabself.schema = self.train_data.dataset.schemaself.index_to_standard_question = dict((y, x) for x, y in self.schema.items())for standard_question_index, question_ids in self.train_data.dataset.knwb.items():for question_id in question_ids:self.question_index_to_standard_question_index[len(self.question_ids)] = standard_question_indexself.question_ids.append(question_id)with torch.no_grad():question_matrixs = torch.stack(self.question_ids, dim=0)if torch.cuda.is_available():question_matrixs = question_matrixs.cuda()self.knwb_vectors = self.model(question_matrixs)self.knwb_vectors = torch.nn.functional.normalize(self.knwb_vectors, dim=-1)
- 該方法的主要作用是將知識庫中的問題轉化為向量,以便之后與輸入的句子進行相似度匹配。
question_index_to_standard_question_index記錄問題編號與標準問題編號的映射,用來標記最終答案的準確性。question_matrixs是所有問題的ID集合,經過模型轉化后,得到問題的向量表示knwb_vectors。torch.nn.functional.normalize()對所有向量進行歸一化,使得它們的長度為1,便于計算相似度。
文本向量化
def encode_sentence(self, text):input_id = []if self.config["vocab_path"] == "words.txt":for word in jieba.cut(text):input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))else:for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))return input_id
- 該方法將輸入的文本句子轉換為詞或字的ID序列。如果配置文件中指定的詞匯表路徑是
words.txt,則使用jieba進行分詞,否則按字符逐一處理。 - 如果某個詞或字符在詞匯表中不存在,則使用
[UNK]代替。
知識庫查詢
def predict(self, sentence):input_id = self.encode_sentence(sentence)input_id = torch.LongTensor([input_id])if torch.cuda.is_available():input_id = input_id.cuda()with torch.no_grad():test_question_vector = self.model(input_id)res = torch.mm(test_question_vector.unsqueeze(0), self.knwb_vectors.T)hit_index = int(torch.argmax(res.squeeze()))hit_index = self.question_index_to_standard_question_index[hit_index]return self.index_to_standard_question[hit_index]
predict方法用于對用戶輸入的句子進行查詢預測。- 首先,將句子轉化為ID序列
input_id。 - 然后,輸入到模型中得到句子的向量表示
test_question_vector。 torch.mm計算該句子向量與所有知識庫問題向量的相似度。- 通過
torch.argmax(res.squeeze())得到最相似問題的索引,進而通過question_index_to_standard_question_index和index_to_standard_question映射回標準問題。
主程序main測試
if __name__ == "__main__":knwb_data = load_data(Config["train_data_path"], Config)model = SiameseNetwork(Config)model.load_state_dict(torch.load("model_output/epoch_10.pth"))pd = Predictor(Config, model, knwb_data)sentence = "發什么有短信告訴說手機話費"res = pd.predict(sentence)print(res)while True:sentence = input("請輸入:")print(pd.predict(sentence))
- 首先,通過
load_data函數加載訓練數據,并初始化模型SiameseNetwork。 - 加載訓練好的模型參數(如從
epoch_10.pth文件中讀取)。 - 創建
Predictor實例,并對某個示例句子進行預測(如“發什么有短信告訴說手機話費”)。 - 進入循環,不斷接收用戶輸入的句子并返回預測結果。
測試效果
請輸入:導航到流量余額查詢菜單
套餐余量查詢
請輸入:協議預存款的金額有規定嗎
月返費查詢
請輸入:我收到一個信息是怎么回事
寬泛業務問題
請輸入:
參考博客
1.基于余弦相似度實現的文本匹配
1 ??











在 Raspberry Pi 上配置熱點)
![[硬件]單片機下載電路講解-以ch340為例](http://pic.xiahunao.cn/[硬件]單片機下載電路講解-以ch340為例)






