python三大庫之—pandas(二)
文章目錄
- python三大庫之---pandas(二)
- 六,函數
- 6.1、常用的統計學函數
- 6.2重置索引
- 6.3 遍歷
- 6.3.1DataFrame 遍歷
- 6.3.2 itertuples()
- 6.3.3 使用屬性遍歷
- 6.4 排序
- 6.4.1 sort_index
- 6.4.2 sort_values
- 6.5 去重
- 6.6 分組
- 6.6.1 groupby
- 6.6.2 filter
- 6.7 合并
- 6.8 隨機抽樣
- 6.9空值處理
- 6.9.1 檢測空值
- 6.9.2 填充空值
- 6.9.3 刪除空值
- 七,讀取CSV文件
- 7.1 to_csv()
- 7.2 read_csv()
- 八,繪圖
六,函數
6.1、常用的統計學函數
| 函數名稱 | 描述說明 |
|---|---|
| count() | 統計某個非空值的數量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位數 |
| std() | 求標準差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求絕對值 |
| prod() | 求所有數值的乘積 |
numpy的方差默認為總體方差,pandas默認為樣本方差
#常用的統計學函數
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
print(df.mean())#計算均值
print(df.median())#計算中位數
print(df.mode())#計算眾數
print(df.var())#計算方差
print(df.std())#計算標準差
print(df.sum())#計算總和
print(df.min())#計算最小值
print(df.max())#計算最大值
print(df.count())#計算非空值的個數
print(df.prod())#計算乘積
print(df.abs())#計算絕對值
A 2.5
B 6.5
C 10.5
dtype: float64
A 2.5
B 6.5
C 10.5
dtype: float64A B C
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
A 1.666667
B 1.666667
C 1.666667
dtype: float64
A 1.290994
B 1.290994
C 1.290994
dtype: float64
A 10
B 26
C 42
dtype: int64
A 1
B 5
C 9
dtype: int64
A 4
B 8
C 12
dtype: int64
A 4
B 4
C 4
dtype: int64
A 24
B 1680
C 11880
dtype: int64A B C
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
6.2重置索引
重置索引(reindex)可以更改原 DataFrame 的行標簽或列標簽,并使更改后的行、列標簽與 DataFrame 中的數據逐一匹配。通過重置索引操作,您可以完成對現有數據的重新排序。如果重置的索引標簽在原 DataFrame 中不存在,那么該標簽對應的元素值將全部填充為 NaN。
reindex
reindex() 方法用于重新索引 DataFrame 或 Series 對象。重新索引意味著根據新的索引標簽重新排列數據,并填充缺失值。如果重置的索引標簽在原 DataFrame 中不存在,那么該標簽對應的元素值將全部填充為 NaN。
- 語法
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=np.nan, limit=None, tolerance=None)
參數:
- labels:
- 類型:數組或列表,默認為 None。
- 描述:新的索引標簽。
- index:
- 類型:數組或列表,默認為 None。
- 描述:新的行索引標簽。
- columns:
- 類型:數組或列表,默認為 None。
- 描述:新的列索引標簽。
- axis:
- 類型:整數或字符串,默認為 None。
- 描述:指定重新索引的軸。0 或 ‘index’ 表示行,1 或 ‘columns’ 表示列。
- method:
- 類型:字符串,默認為 None。
- 描述:用于填充缺失值的方法。可選值包括 ‘ffill’(前向填充)、‘bfill’(后向填充)等。
- copy:
- 類型:布爾值,默認為 True。
- 描述:是否返回新的 DataFrame 或 Series。
- level:
- 類型:整數或級別名稱,默認為 None。
- 描述:用于多級索引(MultiIndex),指定要重新索引的級別。
- fill_value:
- 類型:標量,默認為 np.nan。
- 描述:用于填充缺失值的值。
- limit:
- 類型:整數,默認為 None。
- 描述:指定連續填充的最大數量。
- tolerance:
- 類型:標量或字典,默認為 None。
- 描述:指定重新索引時的容差。
- 重置索引行
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引行
new_index = ['a','b','c','d','e']
print(df.reindex(new_index))#重置索引 A B C
a 1.0 5.0 9.0
b 2.0 6.0 10.0
c 3.0 7.0 11.0
d 4.0 8.0 12.0
e NaN NaN NaN
- 重置索引列
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引列
new_columns = ['A','B','C','D']
print(df.reindex(columns=new_columns))
A B C D
a 1 5 9 NaN
b 2 6 10 NaN
c 3 7 11 NaN
d 4 8 12 NaN
- 重置索引行,并使用向前填充
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引行,并使用向前填充
new_index = ['a','b','c','d','e']
print(df.reindex(new_index,method='ffill')) A B C
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
e 4 8 12
- 重置索引行,并使用指定值填充
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引行,并使用指定值填充
new_index = ['a','b','c','d','e']
print(df.reindex(new_index,method='ffill',fill_value=0)) A B C
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
e 4 8 12
6.3 遍歷
6.3.1DataFrame 遍歷
# DataFrame 的遍歷
data = pd.DataFrame({'A': pd.Series([1, 2, 3],index=['a','b','c']),'B': pd.Series([5, 6, 7, 8],index=['a','b','c','d']),
})
df = pd.DataFrame(data)
print(df)
for i in df:print(i) A B
a 1.0 5
b 2.0 6
c 3.0 7
d NaN 8
A
B
6.3.2 itertuples()
#使用 itertuples() 遍歷行
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
#如果index為False,則打印出的元組過濾掉行索引信息
for i in df.itertuples(index=False):print(i)for j in i:print(j)
Pandas(A=1, B=4, C=7)
1
4
7
Pandas(A=2, B=5, C=8)
2
5
8
Pandas(A=3, B=6, C=9)
3
6
6.3.3 使用屬性遍歷
#使用屬性遍歷
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
#使用屬性遍歷
for inx in df.index:for col in df.columns:print(df.loc[inx,col])
1
4
7
2
5
8
3
6
9
6.4 排序
6.4.1 sort_index
sort_index 方法用于對 DataFrame 或 Series 的索引進行排序。
DataFrame.sort_index(axis=0, ascending=True, inplace=False)
Series.sort_index(axis=0, ascending=True, inplace=False)
參數:
- axis:指定要排序的軸。默認為 0,表示按行索引排序。如果設置為 1,將按列索引排序。
- ascending:布爾值,指定是升序排序(True)還是降序排序(False)。
- inplace:布爾值,指定是否在原地修改數據。如果為 True,則會修改原始數據;如果為 False,則返回一個新的排序后的對象。
6.4.2 sort_values
sort_values 方法用于根據一個或多個列的值對 DataFrame 進行排序。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
參數:
- by:列的標簽或列的標簽列表。指定要排序的列。
- axis:指定沿著哪個軸排序。默認為 0,表示按行排序。如果設置為 1,將按列排序。
- ascending:布爾值或布爾值列表,指定是升序排序(True)還是降序排序(False)。可以為每個列指定不同的排序方向。
- inplace:布爾值,指定是否在原地修改數據。如果為 True,則會修改原始數據;如果為 False,則返回一個新的排序后的對象。
- kind:排序算法。默認為 ‘quicksort’,也可以選擇 ‘mergesort’(歸并排序) 或 ‘heapsort’(堆排序)。
- na_position:指定缺失值(NaN)的位置。可以是 ‘first’ 或 ‘last’。
#sort_values排序
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 25, 35, 30],'Score': [85, 90, 80, 95, 88]
}
df = pd.DataFrame(data)
print(df)print(df.sort_values(by='Age'))
print(df.sort_values(by=['Age','Score']))
print(df.sort_values(by=['Age','Score'],ascending=[True,False])) Name Age Score
0 Alice 25 85
1 Bob 30 90
2 Charlie 25 80
3 David 35 95
4 Eve 30 88Name Age Score
0 Alice 25 85
2 Charlie 25 80
1 Bob 30 90
4 Eve 30 88
3 David 35 95Name Age Score
2 Charlie 25 80
0 Alice 25 85
4 Eve 30 88
1 Bob 30 90
3 David 35 95Name Age Score
0 Alice 25 85
2 Charlie 25 80
1 Bob 30 90
4 Eve 30 88
3 David 35 95
6.5 去重
drop_duplicates 方法用于刪除 DataFrame 或 Series 中的重復行或元素。
- 語法
drop_duplicates(by=None, subset=None, keep='first', inplace=False)
Series.drop_duplicates(keep='first', inplace=False)
參數:
-
by:用于標識重復項的列名或列名列表。如果未指定,則使用所有列。
-
subset:與 by 類似,但用于指定列的子集。
-
keep:指定如何處理重復項。可以是:
- ‘first’:保留第一個出現的重復項(默認值)。
- ‘last’:保留最后一個出現的重復項。
- False:刪除所有重復項。
-
inplace:布爾值,指定是否在原地修改數據。如果為 True,則會修改原始數據;如果為 False,則返回一個新的刪除重復項后的對象。
#去重
data = {'A':[1,2,2,3],'B':[4,5,5,6],'C':[7,8,8,9],
}
df = pd.DataFrame(data)#按照所有列去重
print(df.drop_duplicates())
#按照指定列去重
print(df.drop_duplicates(subset='A'))
print(df.drop_duplicates(keep='last'))
A B C
0 1 4 7
1 2 5 8
3 3 6 9A B C
0 1 4 7
1 2 5 8
3 3 6 9A B C
0 1 4 7
2 2 5 8
3 3 6 9
6.6 分組
6.6.1 groupby
groupby 方法用于對數據進行分組操作,這是數據分析中非常常見的一個步驟。通過 groupby,你可以將數據集按照某個列(或多個列)的值分組,然后對每個組應用聚合函數,比如求和、平均值、最大值等。
- 語法
groupby 方法用于對數據進行分組操作,這是數據分析中非常常見的一個步驟。通過 groupby,你可以將數據集按照某個列(或多個列)的值分組,然后對每個組應用聚合函數,比如求和、平均值、最大值等。
參數**:
- by:用于分組的列名或列名列表。
- axis:指定沿著哪個軸進行分組。默認為 0,表示按行分組。
- level:用于分組的 MultiIndex 的級別。
- as_index:布爾值,指定分組后索引是否保留。如果為 True,則分組列將成為結果的索引;如果為 False,則返回一個列包含分組信息的 DataFrame。
- sort:布爾值,指定在分組操作中是否對數據進行排序。默認為 True。
- group_keys:布爾值,指定是否在結果中添加組鍵。
- squeeze:布爾值,如果為 True,并且分組結果返回一個元素,則返回該元素而不是單列 DataFrame。
- observed:布爾值,如果為 True,則只考慮數據中出現的標簽。
#分組
data = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]}
df = pd.DataFrame(data)
print(df)#按A分組
# 查看分組結果
grouped = df.groupby('A')
print(list(grouped))# 按Af分組,然后計算每個分組的C的平均值
grouped = df.groupby('A')['C']
print(grouped.mean())#按A分組,計算所有列(如果報錯使有非數字類型的值)
grouped = df.groupby(['A'])
print(grouped.mean)#通過transform()函數對分組進行操作,保存到DataFrame中
grouped = df.groupby('A')['C'].transform('mean')
df['C_mean'] = grouped
print(df)#可以使用匿名函數來對分組進行操作,比如正態分布的標準化
grouped = df.groupby('A')['C'].transform(lambda x: (x - x.mean()) / x.std())
df['C_norm'] = grouped
print(df)
A B C D
0 foo one 1 10
1 bar one 2 20
2 foo two 3 30
3 bar three 4 40
4 foo two 5 50
5 bar two 6 60
6 foo one 7 70
7 foo three 8 80
[('bar', A B C D
1 bar one 2 20
3 bar three 4 40
5 bar two 6 60), ('foo', A B C D
0 foo one 1 10
2 foo two 3 30
4 foo two 5 50
6 foo one 7 70
7 foo three 8 80)]
A
bar 4.0
foo 4.8
Name: C, dtype: float64A B C D C_mean
0 foo one 1 10 4.8
1 bar one 2 20 4.0
2 foo two 3 30 4.8
3 bar three 4 40 4.0
4 foo two 5 50 4.8
5 bar two 6 60 4.0
6 foo one 7 70 4.8
7 foo three 8 80 4.8A B C D C_mean C_norm
0 foo one 1 10 4.8 -1.327018
1 bar one 2 20 4.0 -1.000000
2 foo two 3 30 4.8 -0.628587
3 bar three 4 40 4.0 0.000000
4 foo two 5 50 4.8 0.069843
5 bar two 6 60 4.0 1.000000
6 foo one 7 70 4.8 0.768273
7 foo three 8 80 4.8 1.117488
6.6.2 filter
通過 filter() 函數可以實現數據的篩選,該函數根據定義的條件過濾數據并返回一個新的數據集
# # 按列 'A' 分組,并過濾掉列 'C' 的平均值小于 4 的組
# filter
data = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]
}
df = pd.DataFrame(data)
filtered_df = df.groupby('A').filter(lambda x: x['C'].mean() > 4)
print(filtered_df) A B C D
0 foo one 1 10
2 foo two 3 30
4 foo two 5 50
6 foo one 7 70
7 foo three 8 80
6.7 合并
merge 函數用于將兩個 DataFrame 對象根據一個或多個鍵進行合并,類似于 SQL 中的 JOIN 操作。這個方法非常適合用來基于某些共同字段將不同數據源的數據組合在一起,最后拼接成一個新的 DataFrame 數據表。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
-
left:左側的 DataFrame 對象。
-
right:右側的 DataFrame 對象。
-
how:合并方式,可以是 ‘inner’、‘outer’、‘left’ 或 ‘right’。默認為 ‘inner’。
- ‘inner’:內連接,返回兩個 DataFrame 共有的鍵。
- ‘outer’:外連接,返回兩個 DataFrame 的所有鍵。
- ‘left’:左連接,返回左側 DataFrame 的所有鍵,以及右側 DataFrame 匹配的鍵。
- ‘right’:右連接,返回右側 DataFrame 的所有鍵,以及左側 DataFrame 匹配的鍵。
-
on:用于連接的列名。如果未指定,則使用兩個 DataFrame 中相同的列名。
-
left_on 和 right_on:分別指定左側和右側 DataFrame 的連接列名。
-
left_index 和 right_index:布爾值,指定是否使用索引作為連接鍵。
-
sort:布爾值,指定是否在合并后對結果進行排序。
-
suffixes:一個元組,指定當列名沖突時,右側和左側 DataFrame 的后綴。
-
copy:布爾值,指定是否返回一個新的 DataFrame。如果為 False,則可能修改原始 DataFrame。
-
indicator:布爾值,如果為 True,則在結果中添加一個名為 __merge 的列,指示每行是如何合并的。
-
validate:驗證合并是否符合特定的模式。
#合并
# 創建兩個示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})# 內連接,只連接key相同的行
df = pd.merge(left, right, on='key', how='inner')
print(df)# 左連接,連接所有左邊的行,右邊沒有的用NaN填充
df = pd.merge(left, right, on='key', how='left')
print(df)# 右連接,連接所有右邊的行,左邊沒有的用NaN填充
df = pd.merge(left, right, on='key', how='right')
print(df)# 外連接,連接所有行,沒有的用NaN填充
df = pd.merge(left, right, on='key', how='outer')
print(df)
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaNkey A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K4 NaN NaN C3 D3key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN
4 K4 NaN NaN C3 D3
6.8 隨機抽樣
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
參數:
- n:要抽取的行數
- frac:抽取的比例,比如 frac=0.5,代表抽取總體數據的50%
- replace:布爾值參數,表示是否以有放回抽樣的方式進行選擇,默認為 False,取出數據后不再放回
- weights:可選參數,代表每個樣本的權重值,參數值是字符串或者數組
- random_state:可選參數,控制隨機狀態,默認為 None,表示隨機數據不會重復;若為 1 表示會取得重復數據
- axis:表示在哪個方向上抽取數據(axis=1 表示列/axis=0 表示行)
# 隨機抽樣
def sample_test():df = pd.DataFrame({"company": ['百度', '阿里', '騰訊'],"salary": [43000, 24000, 40000],"age": [25, 35, 49]})print(df.sample(frac=0.4))#隨機抽取40%,4舍五入print(df.sample(n=2,axis=0))#隨機抽取2條數據print(df.sample(n=1,axis=1))#隨機抽取1列數據print(df.sample(n=2,axis=0,random_state=1))#隨機抽取2條數據,并指定隨機種子print(df.sample(frac=0.5, replace=True))#隨機抽取50%,允許重復sample_test() company salary age
1 阿里 24000 35company salary age
2 騰訊 40000 49
1 阿里 24000 35age
0 25
1 35
2 49company salary age
0 百度 43000 25
2 騰訊 40000 49company salary age
0 百度 43000 25
0 百度 43000 25
6.9空值處理
6.9.1 檢測空值
isnull()用于檢測 DataFrame 或 Series 中的空值,返回一個布爾值的 DataFrame 或 Series。
notnull()用于檢測 DataFrame 或 Series 中的非空值,返回一個布爾值的 DataFrame 或 Series。
#空值檢測
#isnull,檢測DataFrame中的空值,返回一個布爾值矩陣,True表示空值,False表示非空值
def isnull_test():df = pd.DataFrame({"company": ['百度', '阿里', '騰訊'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.isnull())print(df.isnull().sum())#統計空值print(df.isnull().sum().sum())#統計空值總數isnull_test()
#notnull,檢測DataFrame中的非空值,返回一個布爾值矩陣,True表示非空值,False表示空值
def notnull_test():df = pd.DataFrame({"company": ['百度', '阿里', '騰訊'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.notnull())print(df.notnull().sum())#統計非空值print(df.notnull().sum().sum())#統計非空值總數
company salary age
0 False False False
1 False True False
2 False False False
company 0
salary 1
age 0
dtype: int64
1
6.9.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
#空值填充
def fillna_test():df = pd.DataFrame({"company": ['百度', '阿里', '騰訊'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.fillna(0))#填充0print(df.fillna(method='ffill'))#填充前一個值fillna_test()
company salary age
0 百度 43000.0 25
1 阿里 0.0 35
2 騰訊 40000.0 49
6.9.3 刪除空值
dropna() 方法用于刪除 DataFrame 或 Series 中的空值。
#刪除空值
def dropna_test():df = pd.DataFrame({"company": ['百度', '阿里', '騰訊'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.dropna())#刪除空值print(df.dropna(axis=1))#刪除空值所在列dropna_test()
company salary age
0 百度 43000.0 25
2 騰訊 40000.0 49company age
0 百度 25
1 阿里 35
2 騰訊 49
七,讀取CSV文件
CSV(Comma-Separated Values,逗號分隔值,有時也稱為字符分隔值,因為分隔字符也可以不是逗號),其文件以純文本形式存儲表格數據(數字和文本);
CSV 是一種通用的、相對簡單的文件格式,被用戶、商業和科學廣泛應用。
7.1 to_csv()
to_csv() 方法將 DataFrame 存儲為 csv 文件
#存csv文件
#to_csv()
def to_csv_test():df = pd.DataFrame({"company": ['百度', '阿里', '騰訊'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})df.to_csv('test.csv',index=False)#index=False表示不保存索引to_csv_test()
7.2 read_csv()
read_csv() 表示從 CSV 文件中讀取數據,并創建 DataFrame 對象。
#讀取csv文件
def read_csv_test():df = pd.read_csv('test.csv')print(df)read_csv_test()
company salary age
0 百度 43000.0 25
1 阿里 NaN 35
2 騰訊 40000.0 49
八,繪圖
Pandas 在數據分析、數據可視化方面有著較為廣泛的應用,Pandas 對 Matplotlib 繪圖軟件包的基礎上單獨封裝了一個plot()接口,通過調用該接口可以實現常用的繪圖操作;
Pandas 之所以能夠實現了數據可視化,主要利用了 Matplotlib 庫的 plot() 方法,它對 plot() 方法做了簡單的封裝,因此您可以直接調用該接口;
只用 pandas 繪制圖片可能可以編譯,但是不會顯示圖片,需要使用 matplotlib 庫,調用 show() 方法顯示圖形。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#繪圖
import matplotlib.pyplot as plt
data = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 25, 30, 40]
}
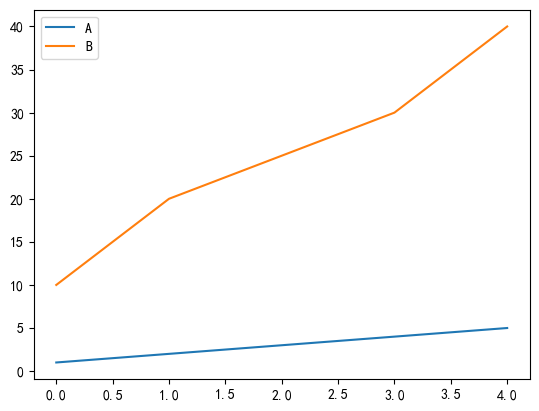
df = pd.DataFrame(data)# 折線圖
df.plot(kind='line')
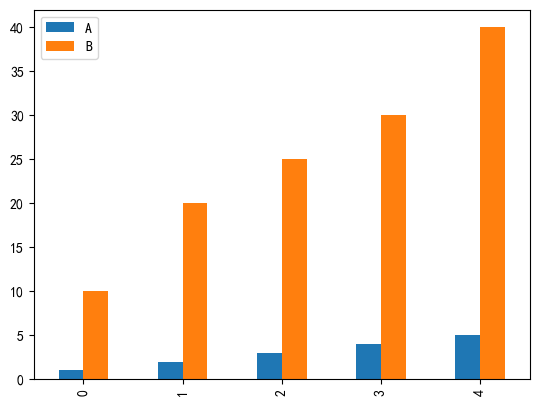
plt.show()# 柱狀圖
df.plot(kind='bar')
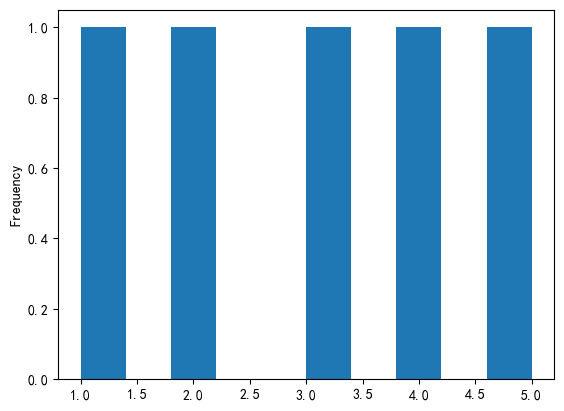
plt.show()#直方圖
df['A'].plot(kind='hist')
plt.show()#散點圖
df.plot(kind='scatter',x='A',y='B')
plt.show()# 餅圖
# 創建一個示例
data = {'A': 10,'B': 20,'C': 30,'D': 40
}
pd = pd.Series(data)
# 繪制餅圖
pd.plot(kind='pie', autopct='%1.1f%%')
# 顯示圖表
plt.show()







】)

+異常處理)
)



)
)

)

