25年4月來自南方科技大學、百度、英國 KCL和琶洲實驗室(廣東 AI 和數字經濟實驗室)的論文“MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving”。
自動駕駛視覺問答(AD-VQA)旨在根據給定的駕駛場景圖像回答與感知、預測和規劃相關的問題,這在很大程度上依賴于模型的空間理解能力。先前的工作通常通過坐標的文本表示來表達空間信息,導致視覺坐標表示和文本描述之間存在語義差距。這種疏忽妨礙了空間信息的準確傳遞并增加了表達負擔。為了解決這個問題,提出了一種基于標記(marker)的提示學習框架(MPDrive),它通過簡潔的視覺標記表示空間坐標,確保語言表達的一致性并提高AD-VQA中視覺感知和空間表達的準確性。具體而言,通過聘請檢測專家將物體區域與數字標簽疊加來創建標記(marker)圖像,將復雜的文本坐標生成轉換為簡單的基于文本視覺標記(marker)預測。此外,將原始圖像和標記(marker)圖像融合為場景級特征,并將它們與檢測先驗相結合以得出實例級特征。通過結合這些特征,構建雙粒度視覺提示,以刺激 LLM 的空間感知能力。
自動駕駛技術發展迅速,顯示出提高道路安全性、交通效率和減少人為錯誤的潛力 [25、45、47、52]。強大的自動駕駛系統需要能夠感知復雜環境并做出明智決策的智體。最近,多模態大語言模型 (MLLM) 已成為一種有前途的自動駕駛方法,在視覺問答 (AD-VQA) 任務中展示了強大的泛化能力 [4、7、18、29、37、40、48、49、61]。
當前的 MLLM 在自動駕駛場景的空間理解方面面臨挑戰 [24、41、62],限制了它們在駕駛場景中準確定位、識別和描述物體及其狀態的能力。雖然一些 AD-VQA 方法 [19、24、30、34、39] 試圖通過對特定領域數據集進行指令調整來提高 MLLM 性能,但它們還沒有充分解決空間推理優化的核心挑戰。在這些方法中,一些方法 [34、41] 通過整合檢測先驗來增強空間理解。然而,這些方法通常以文本格式表達空間坐標,導致基于坐標的描述和語言描述之間不一致 [5、33、53],這破壞了自動駕駛中的感知準確性和精確的空間表達。
本文專注于增強自動駕駛中坐標表示和空間理解的一致性,提出基于標記(marker)的提示學習 (MPDrive),這是一種多模態框架,它使用文本索引來注釋每個交通元素并直接預測相應索引的坐標。
如圖所示:主流MLLM方法和 MPDrive 的比較

給定一組 m 個視圖圖像 {I_1,I_2,…,I_m} 和一個文本問題 Q,AD-VQA 旨在生成一個響應序列 S? = (s?_1, s?_2, . . . , s?_N ),其中 s?_i 表示長度為 N 的序列中的第 i 個 token。AD-VQA 中 MLLM 的工作流程如下:1)從每個視圖 I_i 中提取視覺特征的一個視覺編碼器;2)將多視圖特征轉換為圖像 token 的一個連接 MLP;3)將問題 Q 轉換為文本 token 的文本 token 化器;4)融合圖像 token 和文本 token 以生成響應序列 S? 的 LLM。
基于這些 MLLM,提出 MPDrive 來增強空間理解能力。為清楚起見,使用單視圖場景說明該方法,同時所有操作自然擴展到多視圖情況。
視覺 tokens
為了彌合空間坐標表示和語言描述之間的差距,引入了視覺 tokens。這種方法通過將空間坐標生成任務轉換為直接的基于文本視覺 token 預測,簡化空間坐標生成任務。如圖所示,給定輸入圖像 I,使用檢測專家 StreamPETR [43] 來識別交通目標(例如,汽車、卡車和公共汽車),遵循 [43] 中指定的目標類別。檢測專家生成 K 個目標掩碼,表示為二進制掩碼 R = [r_1, r_2, . . . , r_K ],其中 r_k ∈ {0, 1} 表示第 k 個檢測掩碼。對于 r_k,計算其平均質心坐標 c_k = (x_k, y_k),它表示該目標的中心位置。帶注釋的標記(marker)圖像 I_m 是通過修改原始圖像 I 生成的,修改步驟分為兩個步驟:首先,在每個物體的質心 c_k =(x_k, y_k) 處注釋標記(marker)索引 k;其次,疊加相應的半透明掩碼區域 r_k 來描述物體邊界。此外,當問題 Q 中引用新的空間坐標 c_new(距離現有坐標超過 d 個像素)時,為其分配一個標記(marker)索引 K +1,并在 I_m 上注釋該索引,以保持跨視覺和文本模態的空間推理一致性。
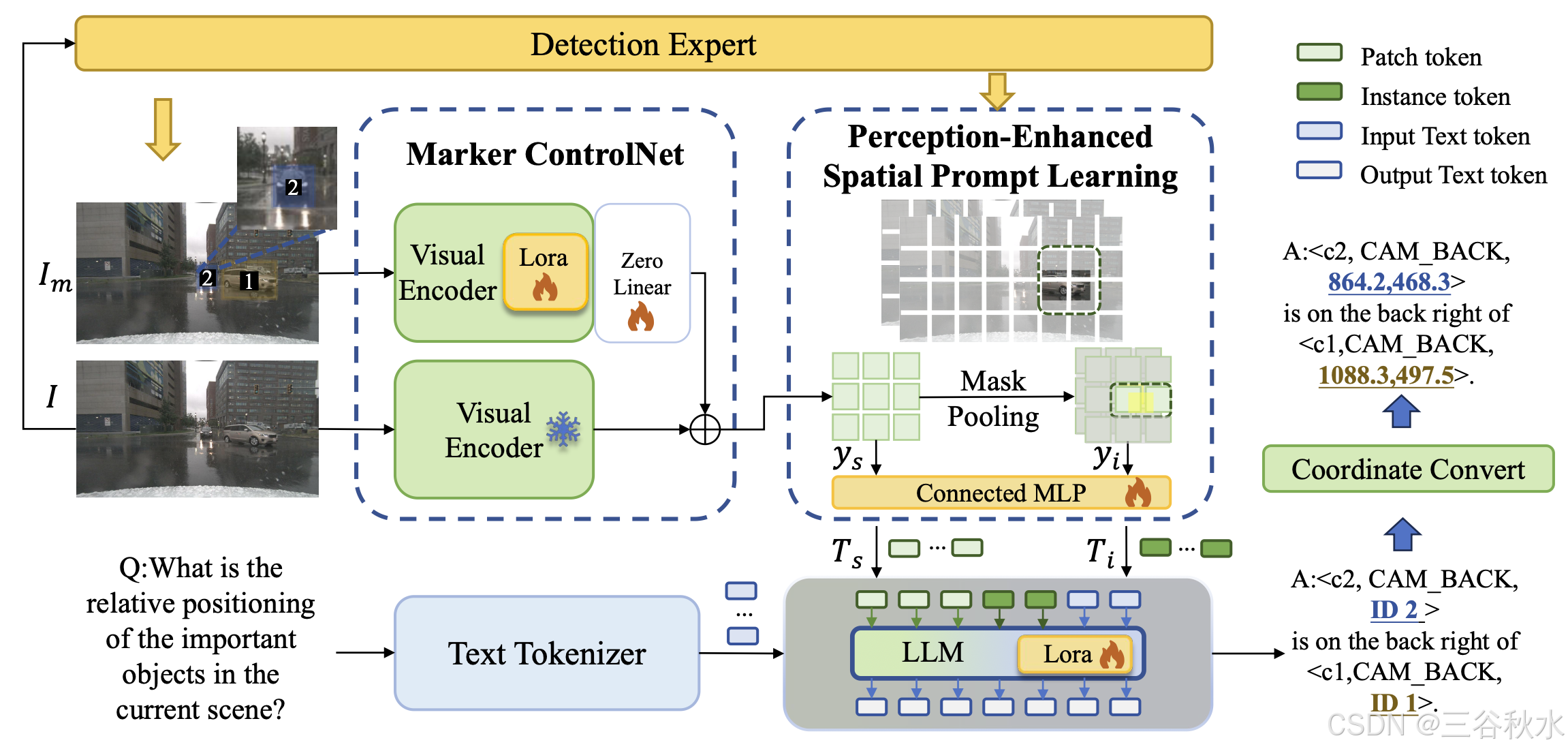
對于響應生成,利用視覺標記(Visual Marker)來提高視覺提示的有效性,并確保語言輸出的一致性。具體而言,LLM 首先根據給定的圖像和問題生成指示符 k,然后將該索引 k 映射到其對應的質心坐標 c_k = (x_k, y_k) 以進行精確定位。此過程允許 MPDrive 通過標記(marker)識別關鍵物體,而復雜的空間感知則由檢測專家處理。通過避免直接坐標輸出,這種方法減輕 LLM 的語言復雜性,確保文本輸出的一致性。
MPDrive 架構
如上圖所示,MPDrive 由兩個關鍵組件組成:MCNet 和 PSPL。MCNet 利用原始圖像和附加的視覺標記(marker)圖像增強空間表征,以實現雙層融合場景特征。基于這些提取的特征和檢測專家,PSPL 生成場景級和實例級視覺提示,從而增強對駕駛場景信息和物體信息的理解。這些組件的集成顯著提升了 MPDrive 的空間感知能力。
Marker ControlNet。為了有效保留原始圖像的關鍵特征并充分利用視覺標記(visual marker)中的豐富信息,提出標記控制網絡 (MCNet)。該模塊將原始圖像和視覺標記圖像作為輸入,并生成場景級特征。
凍結原始視覺編碼器 E 的參數 θ,并創建一個具有參數 θ_c 的可訓練編碼器副本,記為 E_c。在訓練過程中,原始視覺編碼器保持凍結狀態,專注于使用低秩自適應 (LoRA) [16] 在多頭注意模塊和秩為 16 的前饋網絡上訓練新的控制塊。用零線性層 Z 連接原始視覺編碼器和控制塊,其中權重和偏差都初始化為零,參數為 θ_z 。這些層與控制塊一起訓練,可以有效地調整參數并提高性能。使用原始視覺編碼器 E 提取原始圖像特征,而使用新控制塊 E_c 與 Z 結合提取視覺標記圖像特征。這些特征通過元素相加組合在一起,實現場景級特征融合:
y_s = E(I; θ) + Z(E_c(I_m; θ_c); θ_z),
其中 y_s 表示場景級特征。
由于零線性層的權重和偏差參數初始化為零,上述公式中的 Z 項從零開始,從而保留原始圖像特征的完整性。在后續優化階段,將通過反向傳播逐漸引入來自視覺標記圖像的有益特征。
MCNet 有效地結合了視覺標記(marker),使 MPDrive 能夠在保留原始圖像關鍵特征的同時,通過視覺標記的引導學習額外的語義信息。更重要的是,這種方法確保 MPDrive 能夠捕獲視覺標記信息,然后輸出相應的基于文本的標記(marker),從而在生成空間信息時保持語言輸出的一致性。
感知增強的空間提示學習。為了解決 MLLM 在空間表達能力方面的局限性,引入感知增強的空間提示學習 (PSPL),旨在通過利用場景級和實例級視覺提示來增強 MPDrive 的空間感知。
圖像中的視覺標記準確地表示整個場景的空間信息。因此,MCNet 的輸出特征 y_s 包含豐富的場景級空間信息。隨后,通過連接的 MLP 處理 y_s 以生成場景級視覺提示 T_s。這些場景級的視覺提示顯著提高了復雜場景中對空間信息的感知和準確理解。
為了進一步增強實例級空間信息的表示,引入實例級視覺提示。給定第k個檢測目標及其區域掩碼 r_k,場景級視覺提示 y_s,C 是通道數,W′ 是寬度,H′ 是高度,將二元區域掩碼 r_k 調整為與 y_s 相同的大小,并使用掩碼平均池化。
給定K個目標,獲得一組實例級視覺特征{y_i1,…,y_iK}。這些特征通過連接的 MLP 處理以生成實例級視覺提示T_i。這個實例級視覺提示豐富了目標的空間表示。 PSPL 將場景級視覺提示 T_s 和實例級視覺提示 T_i 連接在一起,增強 MPDrive 的空間感知能力。
大語言模型。LLM 從文本 token 化器接收輸入文本 token,從 PSPL 模塊接收空間提示 Ts 和 Ti。它使用其內部模型處理這些輸入,其中 LoRA 應用于多頭注意模塊和秩為 16 的前饋網絡,生成 N 個單詞的輸出序列 S? = (s?_1,s?_2,…,s?_N)。然后使用輸出 token 序列 S? 與真值序列 S = (s_1, s_2, …, s_N) 計算交叉熵損失。
數據集。在 DriveLM [39] 和 CODA-LM [24] 數據集上進行實驗。對于 DriveLM 數據集,遵循 EM-VLM4AD [14] 和 MiniDrive [58] 采用的數據分區策略,將數據集劃分為訓練和驗證子集,分別分配 70% 和 30% 的數據。訓練集包含 341,353 個唯一的 QA 對,而驗證集包含 18,817 個不同的 QA 對。每個 QA 對由六個視圖圖像組成:正面視圖、左正面視圖、右正面視圖、后視圖、左后視圖和右后視圖。對于 CODA-LM 數據集,使用 20,495 個 QA 對訓練集訓練 MPDrive,并使用 193 個 QA 對 mini-set 對其進行驗證。每個 QA 對,都由正面圖像組成。
在訓練階段,采用初始速率為 5e ? 4 的余弦學習調度,并使用權重衰減為 0.01 的 AdamW [28] 優化器。對于 DriveLM 數據集,使用的批量大小為 128,并在八個 A800 GPU 上進行 3,000 次迭代訓練,相當于約 1 個 epoch。對于 CODA-LM 數據集,進行 2000 次迭代訓練,相當于約 12 個 epoch。在整個訓練過程中,視覺編碼器權重保持不變。對連接的 MLP 和零 MLP 進行微調,同時將低秩自適應(LoRA)[16] 應用于 MCNet 中的視覺都將輸入圖像分辨率調整為 448×448 像素。檢測專家針對每幅圖像動態確定檢測到的物體數量 K,所有攝像機視圖中的最大物體數量限制為 100 個。我們設置新的空間坐標 dth = 50。



![[ctfshow web入門] web30](http://pic.xiahunao.cn/[ctfshow web入門] web30)





)
(附源碼))






![[藍橋杯] 挖礦(CC++雙語版)](http://pic.xiahunao.cn/[藍橋杯] 挖礦(CC++雙語版))

的訪問Swagger所做特殊處理)