環境:python3.8 + PyTorch2.4.1+cpu + PyCharm
參考鏈接:
快速入門 — PyTorch 教程 2.6.0+cu124 文檔
PyTorch 文檔 — PyTorch 2.4 文檔
快速入門
導入庫
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor加載數據集
使用 FashionMNIST 數據集。每個 TorchVision 都包含兩個參數: 分別是 修改樣本 和 標簽。
# Download training data from open datasets.
training_data = datasets.FashionMNIST(root="data", # 數據集存儲的位置train=True, # 加載訓練集(True則加載訓練集)download=True, # 如果數據集在指定目錄中不存在,則下載(True才會下載)transform=ToTensor(), # 應用于圖像的轉換列表,例如轉換為張量和歸一化
)# Download test data from open datasets.
test_data = datasets.FashionMNIST(root="data",train=False, # 加載測試集(False則加載測試集)download=True,transform=ToTensor(),
)
創建數據加載器
batch_size = 64# Create data loaders.
# DataLoader():batch_size每個批次的大小,shuffle=True則打亂數據
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)for X, y in test_dataloader: # 遍歷訓練數據加載器,x相當于圖片,y相當于標簽print(f"Shape of X [N, C, H, W]: {X.shape}")print(f"Shape of y: {y.shape} {y.dtype}")break?![]()
創建模型
為了在 PyTorch 中定義神經網絡,我們創建一個繼承 來自?nn.模塊。我們定義網絡的各層 ,并在函數中指定數據如何通過網絡。要加速 作,我們將其移動到 CUDA、MPS、MTIA 或 XPU 等加速器。如果當前加速器可用,我們將使用它。否則,我們使用 CPU。__init__forward
#使用加速器,并打印當前使用的加速器(當前加速器可用則使用當前的,否則使用cpu)
# device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu" # torch2.4.2并沒有accelerator這個屬性,2.6的才有,所以注釋掉
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using {device} device")# 檢查 CUDA 是否可用
print("CUDA available:", torch.cuda.is_available())# Define model
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork().to(device) #torch2.4.2并沒有accelerator這個屬性,2.6的才有,所以注釋掉不用
# model = NeuralNetwork()
print(model)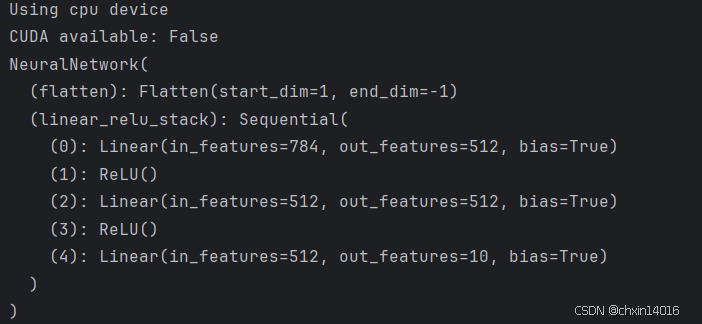
優化模型參數
要訓練模型,我們需要一個損失函數和一個優化器:
loss_fn = nn.CrossEntropyLoss() # 損失函數,nn.CrossEntropyLoss()用于多分類
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # 優化器,用于更新模型的參數,以最小化損失函數'''
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
優化器用PyTorch 提供的隨機梯度下降(Stochastic Gradient Descent, SGD)優化器
model.parameters():將模型的參數傳遞給優化器,優化器會根據這些參數計算梯度并更新它們
lr=1e-3:學習率(learning rate),控制每次參數更新的步長
(較大的學習率可能導致訓練不穩定,較小的學習率可能導致訓練速度變慢)
'''在單個訓練循環中,模型對訓練集進行預測(分批提供給它),并且 反向傳播預測誤差以調整模型的參數:
'''
訓練模型(單個epoch)
dataloader:數據加載器,用于按批次加載訓練數據
model :神經網絡模型
loss_fn :損失函數,用于計算預測值與真實值之間的誤差
optimizer :優化器,用于更新模型參數
'''
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)model.train() # 將模型設置為訓練模式(啟用 dropout 和 batch normalization 的訓練行為)for batch, (X, y) in enumerate(dataloader): # 遍歷 dataloader 中的每個批次,獲取輸入 X 和標簽 yX, y = X.to(device), y.to(device) # 將數據移動到指定設備(如 GPU 或 CPU)# Compute prediction error# 計算預測損失,同時也是前向傳播pred = model(X) # 模型的預測值,即模型的輸出loss = loss_fn(pred, y) # 計算損失:y為實際的類別標簽# Backpropagation 反向傳播和優化# 梯度清零應在每次反向傳播之前執行,以避免梯度累積(先用optimizer.zero_grad())loss.backward() # 計算梯度optimizer.step() # 使用優化器更新模型參數optimizer.zero_grad() # 清除之前的梯度(清零梯度,為下一輪計算做準備)# 梯度清零應在每次反向傳播之前執行,以避免梯度累積(在計算模型預測值前先用optimizer.zero_grad())if batch % 100 == 0: # 每 100 個批次打印一次損失值和當前處理的樣本數量loss, current = loss.item(), (batch + 1) * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")?進度條顯示:
- 如果數據集較大,訓練過程可能較慢。可以使用?
tqdm?庫添加進度條,提升用戶體驗。例如:from tqdm import tqdm for batch, (X, y) in enumerate(tqdm(dataloader, desc="Training")):...
我們還根據測試集檢查模型的性能,以確保它正在學習:
# 測試模型
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 測試集的總樣本數num_batches = len(dataloader) # 測試數據加載器(dataloader)的總批次數model.eval() # 設置為評估模式,這會關閉 dropout 和 batch normalization 的訓練行為test_loss, correct = 0, 0 # 累積測試損失和正確預測的樣本數with torch.no_grad(): # 禁用梯度計算,使用 torch.no_grad() 上下文管理器,避免計算梯度,從而節省內存并加速計算for X, y in dataloader:X, y = X.to(device), y.to(device) # 將數據加載到指定設備pred = model(X) # 模型預測test_loss += loss_fn(pred, y).item() # 累積損失correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累積正確預測數# correct += (pred.argmax(1) == y).float().sum().item() # 可以直接使用 .float(),更簡潔test_loss /= num_batches # 平均損失correct /= size # 準確率print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 累積正確預測數 # correct += (pred.argmax(1) == y).float().sum().item() # 可以直接使用 .float(),更簡潔 '''pred.argmax(1): pred 是模型的輸出(通常是未經過 softmax 的 logits,形狀為 [batch_size, num_classes])。 argmax(1) 表示在第二個維度(即類別維度)上找到最大值的索引,返回一個形狀為 [batch_size] 的張量,表示每個樣本的預測類別。pred.argmax(1) == y: y 是真實標簽(形狀為 [batch_size]),表示每個樣本的真實類別。 這一步會比較預測的類別和真實類別,返回一個布爾張量,形狀為 [batch_size],其中每個元素表示對應樣本的預測是否正確。.type(torch.float): 將布爾張量轉換為浮點數張量(True 轉為 1.0,False 轉為 0.0).sum(): 對浮點數張量求和,得到預測正確的樣本總數.item(): 將結果從張量轉換為 Python 的標量(整數) '''
- 舉例一:
pred?是模型的輸出:torch.tensor([[2.5, 0.3, 0.2], [0.1, 3.2, 0.7]])
y?是真實標簽:torch.tensor([0, 1])import torchpred = torch.tensor([[2.5, 0.3, 0.2], [0.1, 3.2, 0.7]]) y = torch.tensor([0, 1])correct = (pred.argmax(1) == y).type(torch.float).sum().item() print(correct) # 輸出: 2.0 -> 轉換為整數后為 2
- 舉例二:
import torch# 模型輸出(未經過 softmax 的 logits) pred = torch.tensor([[2.0, 1.0, 0.1], # 第一個樣本的預測分數[0.5, 3.0, 0.2], # 第二個樣本的預測分數[1.2, 0.3, 2.5]]) # 第三個樣本的預測分數# 真實標簽 y = torch.tensor([0, 1, 2]) # 第一個樣本的真實類別是 0,第二個是 1,第三個是 2# 計算預測正確的樣本數 correct = (pred.argmax(1) == y).type(torch.float).sum().item() print(f"預測正確的樣本數: {correct}") # 預測正確的樣本數: 3'''逐步分析 對每個樣本的預測分數取最大值的索引,得到預測類別: pred.argmax(1) # 輸出: tensor([0, 1, 2])比較預測類別和真實標簽,得到布爾張量: pred.argmax(1) == y # 輸出: tensor([True, True, True]).type(torch.float): 將布爾張量轉換為浮點數張量: (pred.argmax(1) == y).type(torch.float) # 輸出: tensor([1.0, 1.0, 1.0]).sum(): 對浮點數張量求和,得到預測正確的樣本總數: (pred.argmax(1) == y).type(torch.float).sum() # 輸出: tensor(3.0).item():將結果從張量轉換為 Python 標量: (pred.argmax(1) == y).type(torch.float).sum().item() # 輸出: 3在這個例子中,模型對所有 3 個樣本的預測都正確,因此預測正確的樣本數為 3。 ''' # 如果知道總樣本數,可以進一步計算準確率:# 總樣本數 total = len(y)# 準確率 accuracy = correct / total print(f"準確率: {accuracy * 100:.2f}%")
訓練過程分多次迭代 (epoch)?進行。在每個 epoch 中,模型會學習 參數進行更好的預測。
然后打印模型在每個 epoch 的準確率和損失,
期望看到 準確率Accuracy增加,損失Avg loss隨著每個 epoch 的減少而減少:
# 跑5輪,每輪皆是先訓練,然后測試
epochs = 5
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)
print("Done!")輸出:
Epoch 1
-------------------------------
loss: 2.308106 [ 64/60000]
loss: 2.292096 [ 6464/60000]
loss: 2.280747 [12864/60000]
loss: 2.273108 [19264/60000]
loss: 2.256617 [25664/60000]
loss: 2.240094 [32064/60000]
loss: 2.229981 [38464/60000]
loss: 2.204926 [44864/60000]
loss: 2.201917 [51264/60000]
loss: 2.178733 [57664/60000]
Test Error: Accuracy: 46.1%, Avg loss: 2.164820 Epoch 2
-------------------------------
loss: 2.178193 [ 64/60000]
loss: 2.160645 [ 6464/60000]
loss: 2.110801 [12864/60000]
loss: 2.129119 [19264/60000]
loss: 2.078400 [25664/60000]
loss: 2.029629 [32064/60000]
loss: 2.044328 [38464/60000]
loss: 1.972220 [44864/60000]
loss: 1.980023 [51264/60000]
loss: 1.920835 [57664/60000]
Test Error: Accuracy: 56.2%, Avg loss: 1.906657 Epoch 3
-------------------------------
loss: 1.938616 [ 64/60000]
loss: 1.902610 [ 6464/60000]
loss: 1.797264 [12864/60000]
loss: 1.844325 [19264/60000]
loss: 1.726765 [25664/60000]
loss: 1.688332 [32064/60000]
loss: 1.695883 [38464/60000]
loss: 1.605903 [44864/60000]
loss: 1.628846 [51264/60000]
loss: 1.532240 [57664/60000]
Test Error: Accuracy: 59.8%, Avg loss: 1.541237 Epoch 4
-------------------------------
loss: 1.604458 [ 64/60000]
loss: 1.563167 [ 6464/60000]
loss: 1.426733 [12864/60000]
loss: 1.503305 [19264/60000]
loss: 1.376496 [25664/60000]
loss: 1.381424 [32064/60000]
loss: 1.371971 [38464/60000]
loss: 1.312882 [44864/60000]
loss: 1.342990 [51264/60000]
loss: 1.244696 [57664/60000]
Test Error: Accuracy: 62.7%, Avg loss: 1.268371 Epoch 5
-------------------------------
loss: 1.344515 [ 64/60000]
loss: 1.318664 [ 6464/60000]
loss: 1.166471 [12864/60000]
loss: 1.275481 [19264/60000]
loss: 1.146058 [25664/60000]
loss: 1.179018 [32064/60000]
loss: 1.171105 [38464/60000]
loss: 1.129168 [44864/60000]
loss: 1.163182 [51264/60000]
loss: 1.077062 [57664/60000]
Test Error: Accuracy: 64.7%, Avg loss: 1.097442 Done!保存模型
保存模型的常用方法是序列化內部狀態字典(包含模型參數):
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")加載模型
加載模型的過程包括重新創建模型結構和加載 state 字典放入其中。
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth", weights_only=True))查看安裝的PyTorch版本
方法一:cmd終端查看
終端中輸入:
>>>python
>>>import torch
>>>torch.__version__ //注意version前后是兩個下劃線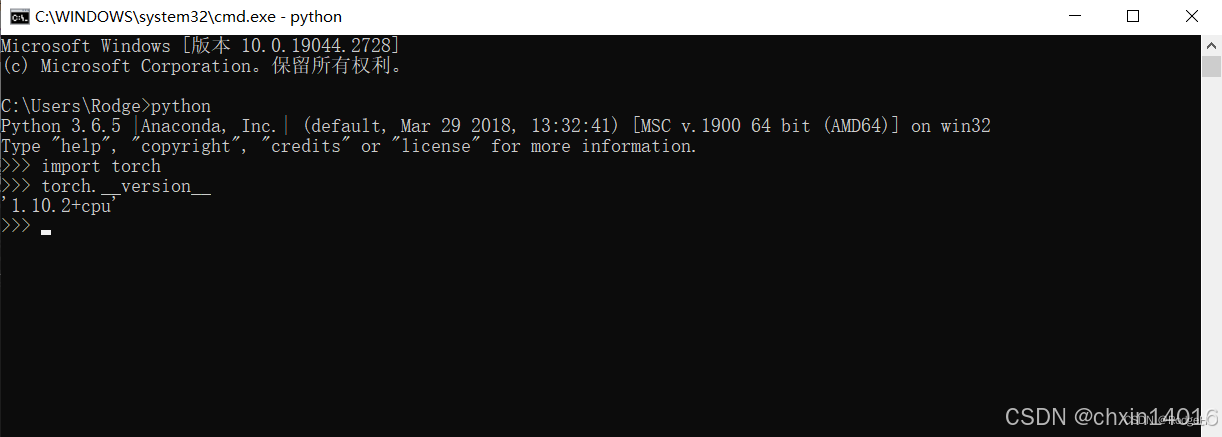
方法二:PyCharm查看
打開Pycharm,在Python控制臺中輸入:
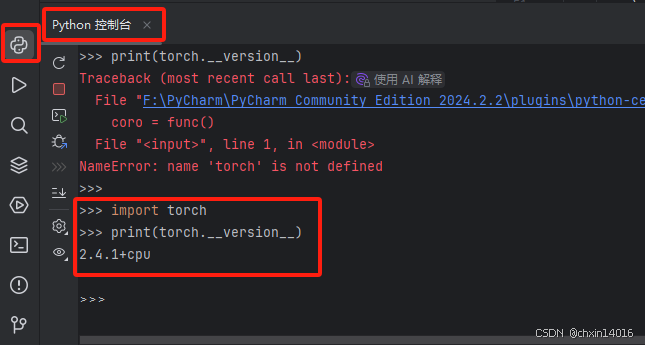
或者在Pycharm的“Python軟件包”中查看:

)

完整指南)




)








——控件的基類Control)
系統,提示詞(Prompt)表現測試(數據說話))
)