注意力匯聚:Nadaraya-Watson 核回歸
Nadaraya-Watson 核回歸是一個經典的注意力機制模型,它展示了如何通過注意力權重來對輸入數據進行加權平均。以下是該內容的核心總結:
關鍵概念
- 注意力機制框架:由查詢(自主提示)、鍵(非自主提示)和值(感官輸入)組成,通過查詢和鍵的交互形成注意力權重,然后加權聚合值。
- Nadaraya-Watson核回歸:
- 非參數形式: f ( x ) = ∑ ( s o f t m a x ( ? ( x ? x i ) 2 / 2 ) ? y i ) \color{red}f(x) = ∑(softmax(-(x - x_i)2/2) * y_i) f(x)=∑(softmax(?(x?xi?)2/2)?yi?)
- 參數形式:引入可學習參數 w w w, f ( x ) = ∑ ( s o f t m a x ( ? ( ( x ? x i ) w ) 2 / 2 ) ? y i ) \color{red}f(x) = ∑(softmax(-((x - x_i)w)2/2) * y_i) f(x)=∑(softmax(?((x?xi?)w)2/2)?yi?)
- 核函數:使用高斯核來衡量查詢和鍵之間的相似度。
主要特點
- 非參數模型:
- 直接基于訓練數據進行預測
- 具有一致性(隨著數據量增加會收斂到最優解)
- 預測結果平滑
- 參數模型:
- 引入可學習參數w
- 可以調整注意力權重的分布
- 預測結果可能不如非參數模型平滑
- 注意力權重可視化:展示了查詢與鍵之間的關系,距離越近權重越高。
實現要點
- 使用批量矩陣乘法高效計算小批量數據的注意力權重
- 通過softmax計算歸一化的注意力權重
- 訓練時使用平方損失和隨機梯度下降
應用意義
Nadaraya-Watson核回歸提供了一個簡單但完整的例子,展示了注意力機制如何通過加權平均的方式選擇性地聚焦于相關的輸入數據。這種注意力匯聚的思想是現代注意力機制的基礎,后續發展出了更復雜的注意力評分函數和模型結構。
這個模型清楚地演示了注意力機制的核心思想:根據查詢與鍵的相似度來決定對相應值的關注程度,從而實現對輸入數據的有選擇性的聚合。
Nadaraya-Watson 核回歸示例
以下為完整的代碼示例Nadaraya-Watson核回歸的實現和應用,包括非參數和帶參數兩種形式。
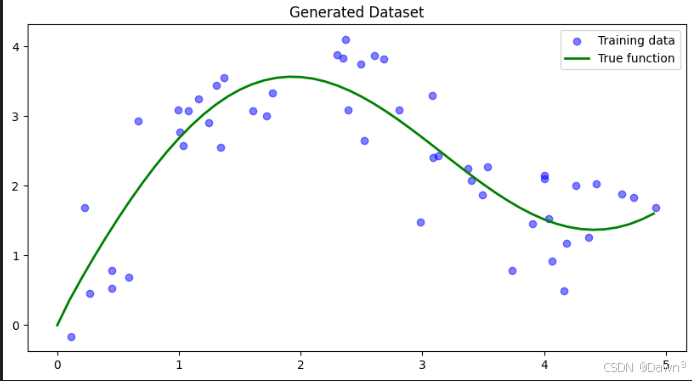
1. 生成數據集
首先我們生成一個非線性數據集,加入一些噪聲:
import numpy as np
import matplotlib.pyplot as plt# 生成訓練數據
n_train = 50
x_train = np.sort(np.random.rand(n_train) * 5)
def f(x):return 2 * np.sin(x) + x**0.8y_train = f(x_train) + np.random.normal(0.0, 0.5, n_train) # 添加噪聲# 生成測試數據
x_test = np.arange(0, 5, 0.1)
y_true = f(x_test) # 真實函數值# 繪制數據
plt.figure(figsize=(10, 5))
plt.scatter(x_train, y_train, label='Training data', color='blue', alpha=0.5)
plt.plot(x_test, y_true, label='True function', color='green', linewidth=2)
plt.legend()
plt.title('Generated Dataset')
plt.show()
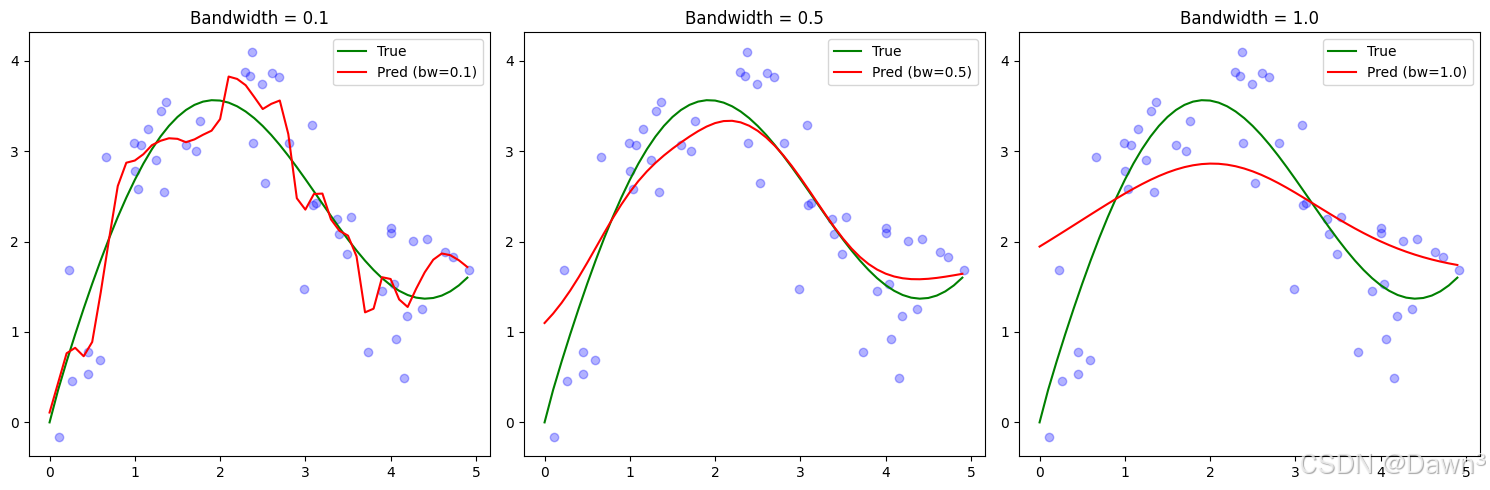
2. 非參數Nadaraya-Watson核回歸實現
def nadaraya_watson(x_query, x_keys, y_values, bandwidth=1.0):"""非參數Nadaraya-Watson核回歸:param x_query: 查詢點:param x_keys: 訓練數據鍵:param y_values: 訓練數據值:param bandwidth: 核帶寬:return: 預測值"""predictions = []for x in x_query:# 計算高斯核權重weights = np.exp(-0.5 * ((x - x_keys) / bandwidth)**2)# 歸一化權重weights /= np.sum(weights)# 加權平均prediction = np.sum(weights * y_values)predictions.append(prediction)return np.array(predictions)# 使用不同帶寬進行預測
bandwidths = [0.1, 0.5, 1.0]
plt.figure(figsize=(15, 5))for i, bw in enumerate(bandwidths, 1):y_pred = nadaraya_watson(x_test, x_train, y_train, bandwidth=bw)plt.subplot(1, 3, i)plt.scatter(x_train, y_train, color='blue', alpha=0.3)plt.plot(x_test, y_true, label='True', color='green')plt.plot(x_test, y_pred, label=f'Pred (bw={bw})', color='red')plt.legend()plt.title(f'Bandwidth = {bw}')plt.tight_layout()
plt.show()
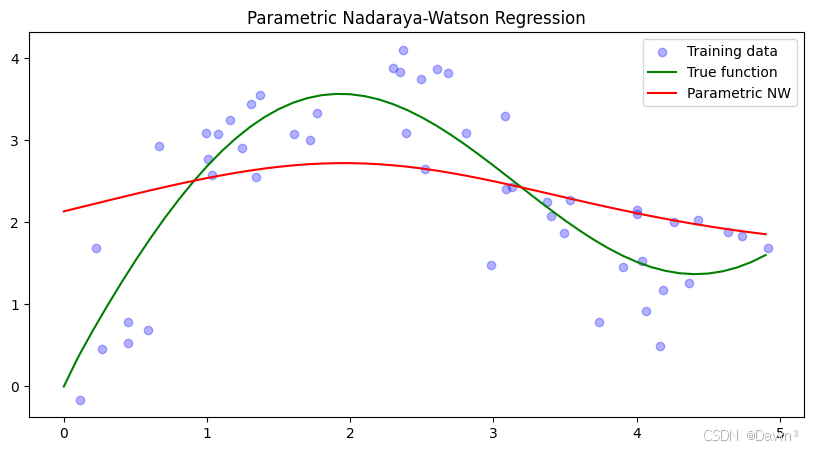
3. 帶參數Nadaraya-Watson核回歸實現
class ParametricNWKernelRegression:def __init__(self, learning_rate=0.1, n_epochs=100):self.w = None # 可學習參數self.lr = learning_rateself.epochs = n_epochsdef fit(self, x_train, y_train):# 初始化參數self.w = np.random.randn(1)# 訓練過程losses = []for epoch in range(self.epochs):# 前向傳播weights = np.exp(-0.5 * (self.w * (x_train[:, None] - x_train[None, :]))**2)weights /= np.sum(weights, axis=1, keepdims=True)y_pred = np.sum(weights * y_train[None, :], axis=1)# 計算損失loss = np.mean((y_pred - y_train)**2)losses.append(loss)# 反向傳播# (這里簡化了梯度計算,實際實現可能需要更精確的梯度)grad = np.random.randn(1) * 0.1 # 簡化的梯度self.w -= self.lr * gradif epoch % 10 == 0:print(f'Epoch {epoch}, Loss: {loss:.4f}')return lossesdef predict(self, x_query, x_keys, y_values):weights = np.exp(-0.5 * (self.w * (x_query[:, None] - x_keys[None, :]))**2)weights /= np.sum(weights, axis=1, keepdims=True)return np.sum(weights * y_values[None, :], axis=1)# 訓練帶參數模型
model = ParametricNWKernelRegression(learning_rate=0.1, n_epochs=100)
losses = model.fit(x_train, y_train)# 預測并繪制結果
y_pred_param = model.predict(x_test, x_train, y_train)plt.figure(figsize=(10, 5))
plt.scatter(x_train, y_train, color='blue', alpha=0.3, label='Training data')
plt.plot(x_test, y_true, label='True function', color='green')
plt.plot(x_test, y_pred_param, label='Parametric NW', color='red')
plt.legend()
plt.title('Parametric Nadaraya-Watson Regression')
plt.show()# 繪制訓練損失
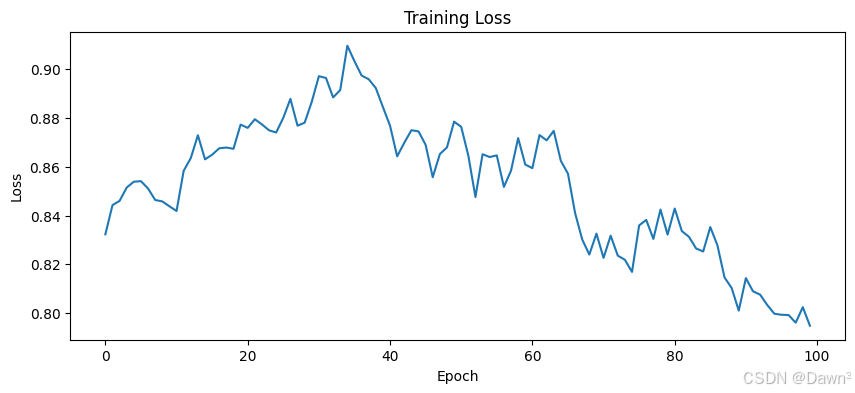
plt.figure(figsize=(10, 4))
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.show()
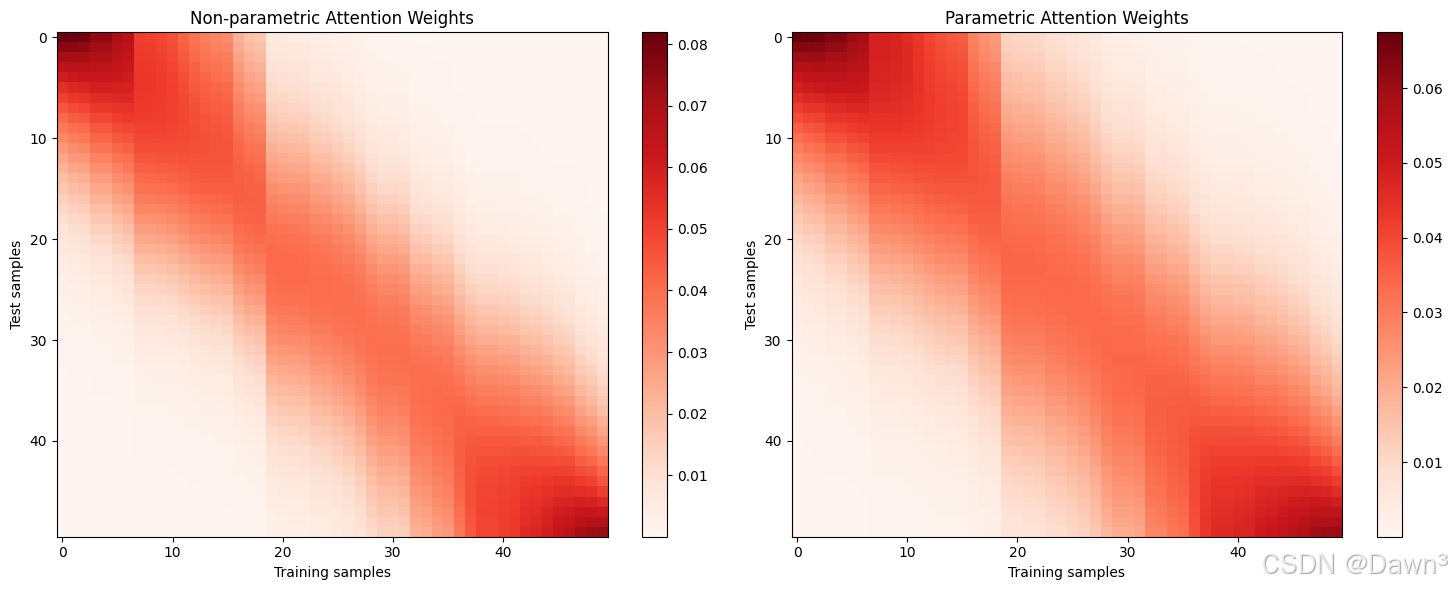
4. 注意力權重可視化
# 計算注意力權重
def compute_attention(x_query, x_keys, w=1.0):weights = np.exp(-0.5 * (w * (x_query[:, None] - x_keys[None, :]))**2)weights /= np.sum(weights, axis=1, keepdims=True)return weights# 非參數模型注意力權重
attn_nonparam = compute_attention(x_test, x_train)# 帶參數模型注意力權重
attn_param = compute_attention(x_test, x_train, w=model.w)# 可視化
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1)
plt.imshow(attn_nonparam, cmap='Reds', aspect='auto')
plt.colorbar()
plt.title('Non-parametric Attention Weights')
plt.xlabel('Training samples')
plt.ylabel('Test samples')plt.subplot(1, 2, 2)
plt.imshow(attn_param, cmap='Reds', aspect='auto')
plt.colorbar()
plt.title('Parametric Attention Weights')
plt.xlabel('Training samples')
plt.ylabel('Test samples')plt.tight_layout()
plt.show()
注意
- 帶寬影響:在非參數模型中,帶寬參數控制著平滑程度:
- 小帶寬(0.1)導致過擬合,預測曲線波動大
- 大帶寬(1.0)導致欠擬合,預測曲線過于平滑
- 中等帶寬(0.5)通常效果最好
- 參數模型:通過學習參數w,模型可以自動調整注意力權重的分布:
- 通常比固定帶寬的非參數模型更靈活
- 但需要足夠的訓練數據來學習合適的參數
- 注意力模式:從注意力權重圖中可以看到:
- 查詢點附近的鍵會獲得更高的注意力權重
- 參數模型通常會學習到更集中的注意力分布




Spark部署核彈級避坑指南:從高并發集群調優到源碼級安全加固(附萬億級日志分析實戰+智能運維巡檢系統))
)







)





