在深度學習中模型量化可以分為3塊知識點,數據類型、常規模型量化與大模型量化。本文主要是對這3塊知識點進行淺要的介紹。其中數據類型是模型量化的基本點。常規模型量化是指對普通小模型的量化實現,通常止步于int8的量化,絕大部分推理引擎都支持該能力。而大模型的量化,需要再cuda層次進行能力的擴展,需要特殊的框架支持。
1、深度學習中的數據類型
1.1 常見的數據類型
在深度學習中常見的數據類型主要可以區分為int與float,在float中又可以區分為fp32、tf32、fp16、bf16等類型,這些float數據的差異在于指數位于小數位長度的差異。深度學習模型部署的參數數據類型有int64、int32、int8、int4等,int64與int32通常是用于模型進行索引操作時,int8與int4通常用于量化后模型參數的直接表示。關于模型量化還有二值量化、三值量化、稀疏量化等可以參考:https://zhuanlan.zhihu.com/p/20329244481
下圖詳細詳細的展示了fp32、tf32、fp16、bf16等4種數據類型的差異。
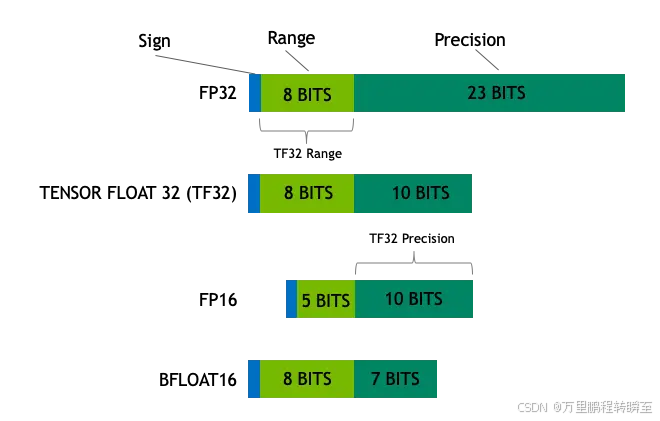
數據類型基本信息
| 數據類型 | 描述 | 特點 |
|---|---|---|
| FP32 | 32位單精度浮點數,符合IEEE 754標準,由1位符號位、8位指數位和23位尾數位組成。 | 能表示較寬的數值范圍和較高的精度,可精確表示大多數實數,是深度學習中常用的默認數據類型。 |
| TF32 | 一種特殊的32位浮點數格式,主要用于NVIDIA的Tensor Core架構。它與FP32類似,但指數范圍較小,為8位(與FP16相同),尾數位為23位。 | 相比傳統FP32,TF32在保持一定精度的同時,能利用Tensor Core的硬件加速特性,提高計算效率。 |
| FP16 | 16位半精度浮點數,由1位符號位、5位指數位和10位尾數位組成。 | 占用空間是FP32的一半,數據傳輸和計算速度快,但數值范圍和精度相對較低。 |
| BF16 | 16位腦浮點格式,由1位符號位、8位指數位和7位尾數位組成。 | 指數位與FP32相同,能表示較大數值范圍,在精度和計算效率上有一定平衡,對某些深度學習任務能在減少內存占用的同時保持較好的模型性能。 |
| Int8 | 8位有符號整數,取值范圍通常是 -128到127。 | 占用存儲空間小,計算速度快,對硬件要求低,但只能表示整數,無法精確表示小數,精度有限。 |
| Int4 | 4位有符號整數,取值范圍通常是 -8到7。 | 占用空間極小,是Int8存儲空間的一半,計算速度更快,但精度損失更為嚴重,能表示的數值范圍非常有限。 |
數據類型應用特性
| 數據類型 | 優勢 | 劣勢 | 應用場景 |
|---|---|---|---|
| FP32 | 計算精度高,模型訓練和推理結果準確,適用于各種深度學習任務,尤其是對精度要求苛刻的場景。 | 占用內存和存儲空間大,計算速度相對慢,在一些資源受限的環境中可能不太適用。 | 廣泛應用于圖像識別、自然語言處理、語音識別等各種深度學習領域,如大型復雜神經網絡的訓練和推理。 |
| TF32 | 能利用專門的硬件(如NVIDIA Tensor Core)實現高效計算,在不顯著降低精度的情況下提高計算速度,減少訓練時間。 | 依賴特定的硬件支持,不具有廣泛的兼容性,如果硬件不支持TF32,則無法發揮其優勢。 | 主要用于NVIDIA支持Tensor Core的GPU設備上進行深度學習計算,特別是在處理大規模矩陣運算的神經網絡中表現出色,如一些需要快速訓練的深度卷積神經網絡。 |
| FP16 | 減少內存占用和傳輸帶寬,提高計算速度,降低模型存儲和傳輸成本,適用于對實時性要求較高的場景。 | 精度有限,在一些復雜模型訓練中可能出現精度損失,導致模型性能下降。 | 常用于移動端、嵌入式設備以及一些對實時性要求高的場景,如自動駕駛中的實時目標檢測、移動設備上的圖像分類應用等。 |
| BF16 | 在大規模數據和復雜模型處理中,能較好地平衡精度和計算效率,可減少內存占用,同時利用硬件加速提高計算速度。 | 相比FP32精度有一定損失,雖然比FP16更能保持模型準確性,但在某些對精度要求極高的任務中可能不夠精確。 | 常用于數據中心的深度學習訓練,尤其是針對一些大型神經網絡,如大規模的語言模型訓練、圖像生成模型等,可利用支持BF16的硬件來提高訓練效率。 |
| Int8 | 降低存儲和計算成本,提高運行效率,適合內存和計算資源有限的場景,如邊緣計算設備和低功耗芯片。 | 精度丟失,不適用于高精度計算任務,在將浮點數轉換為Int8時可能會引入量化誤差,影響模型準確性。 | 常用于邊緣計算設備,如智能攝像頭中的目標檢測模型、工業物聯網設備中的預測模型等,通過量化為Int8類型,可以在不影響太多性能的前提下,減少內存占用和計算量。 |
| Int4 | 進一步降低存儲和計算成本,適用于資源極度受限的環境,如一些物聯網設備。 | 精度損失嚴重,能表示的數值范圍非常有限,對模型的準確性影響較大,需要更復雜的量化和校準技術來保證模型性能。 | 目前相對較少單獨使用,主要探索用于一些特定的超輕量級模型或對存儲和能耗有極致要求的場景,如某些簡單的物聯網傳感器數據處理模型,常與其他優化技術結合使用以平衡精度和性能。 |
1.2 不同數據類型下的算力差異
以抖音百科提煉的A100顯卡的算力數據,可以發現a100顯卡fp32計算的算力是156TFlops,但隨著數據類型的精簡,算力在翻倍。

以下是RTX 3060顯卡在不同數據格式下的算力情況圖表:
| 數據格式 | 算力 |
|---|---|
| FP32 | 12.7 TFLOPS |
| TF32 | 無官方明確數據,一般認為在利用Tensor Core加速時接近FP16性能(由于架構設計,RTX 3060的TF32性能不像A100那樣有明確區分和突出優勢) |
| FP16 | 25.4 TFLOPS |
| BF16 | 無官方明確數據,推測與FP16相近或略低,因為RTX 3060硬件對BF16的支持不是特別突出 |
| INT8 | 50.8 TOPS |
| INT4 | 暫無公開的準確官方數據,考慮到其數據位寬更窄,理論上在特定計算場景下會比INT8有更高的計算吞吐量,但具體數值需根據實際測試確定。 |
需要注意的是,實際應用中的算力表現可能會受到多種因素的影響,如顯存帶寬、算法實現、軟件優化等,以上數據僅供參考。這里也同樣可以發現表示數據的位數減少一半,顯卡的算力基本上可以提升一倍。同時a100的算力是3060顯卡的12倍以上
量化對于精度的影響
隨意截取一個論文數據,可以發現對于10b以上的模型進行int量化操作基本上沒有精度損失,而對于7b或更小的模型進行量化有一定的精度損失風險。
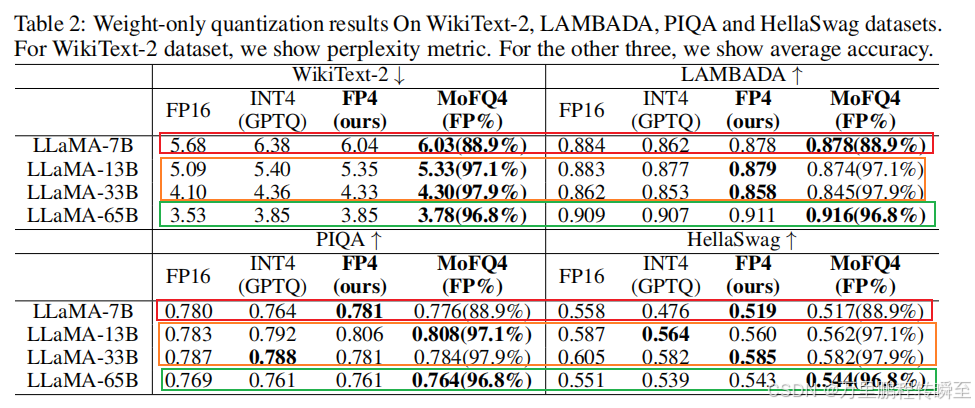
1.3 fp8與fp4
除了前面提到的各種float數據類型外,還有fp8與fp4兩個不常見的類型。FP8是由Nvidia在Hopper和Ada Lovelace架構GPU上推出的數據類型,有如下兩種形式:
- E4M3:具有4個指數位、3個尾數位和1個符號位
- E5M2:具有5個指數位、2個尾數位和1個符號位
其中E4M3支持動態范圍更小、精度更高的計算,而E5M2可提供更寬廣的動態范圍和更低的精度。LLM推理過程對精度要求較高,對數值范圍要求偏低,因此FP8-E4M3更適合于LLM推理。
在論文Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models中詳細的對比了FP8與INT8的差異。以下是關鍵信息。整體來說,就是int8適用于權重的量化,fp8適用于激活值的量化。
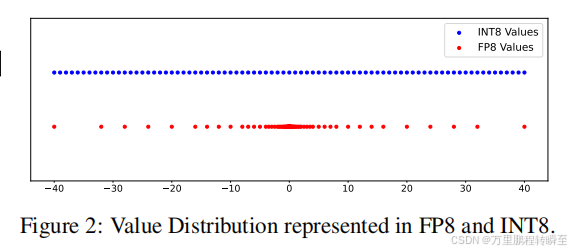
數值范圍
FP8與INT8相比,整數格式在可表示范圍內具有均勻的分布,兩個連續數字之間的差值為1。而浮點格式由于結合了指數和尾數設計而表現出非均勻分布,從而為較小的數字提供較高的精度,為較大的數字提供較低的精度。
權重量化效果
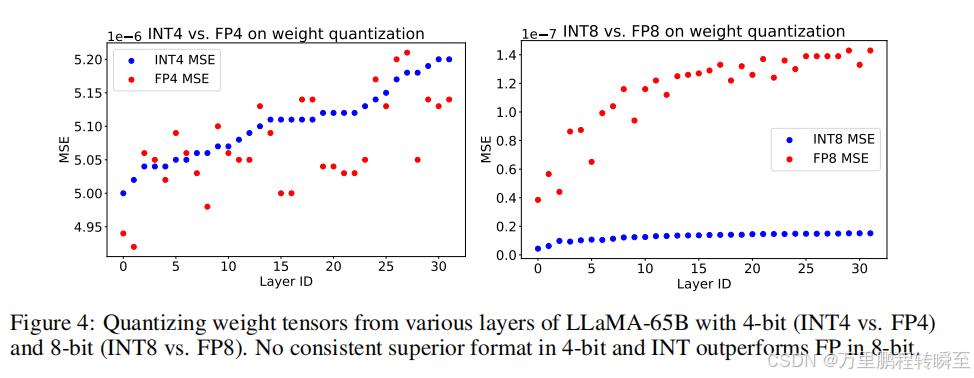
基于論文作者對于LLaMA-65B模型的權重量化實驗,可以發現int8的效果部分fp8要好很多。int8量化后的差異比較穩定,而fp8量化后的差異增長較快。
這一分析結果表明,INT在8位權重量化中具有優勢。然而,當位寬減小時,指數位也會減少,使得INT和FP的分布更加相似。在4位量化中,使用均勻分布的INT格式量化靜態張量的優勢逐漸消失,導致4位量化權重沒有明確的最優解。
激活值量化
與推理過程中的靜態權值張量不同,激活張量是動態的,并隨著每個輸入而變化。因此,校準是激活張量量化過程中確定適當尺度因子的重要步驟。作者比較了FP8和INT8量化的MSE誤差,如圖5所示。FP8的量化誤差低于INT8因為校準過程總是在多個批次中選擇最大的值來確定量化中的比例因子。這個過程傾向于為大多數批次得出一個大于合適的比例因子。然而,FP格式對于大值的精度較低,對于小值的精度較高,本質上更適合量化這種動態張量。
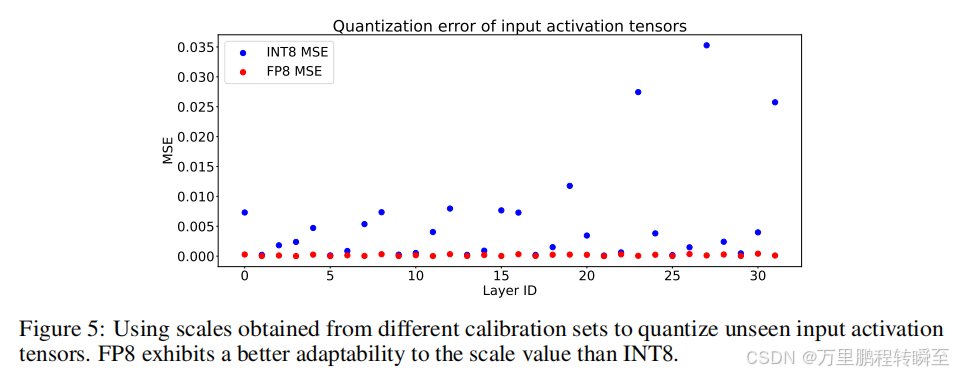
因為int8量化受極大值影響精度表示,而fp8量化不受極大值影響,反而對于極大值表示誤差反而大。而極大值可能為異常值,int8量化為極大值浪費精度,而fp8為極小值提供高精度,故fp8量化激活值效果更好
2、模型的常規量化
模型量化的精度越低,模型尺寸和推理內存占用越少,為了盡可能的減少資源占用,量化算法被發明。FP32占用4個字節,量化為int8,只需要1個字節。
本節內容參考:https://zhuanlan.zhihu.com/p/29140505773

2.1 量化方式的基本分類
量化可以分為對稱量化與非對稱量化
在對稱量化中,值域為-127到127,由于模型參數不是對稱分布的,故量化后權重的部分表示范圍被浪費了。
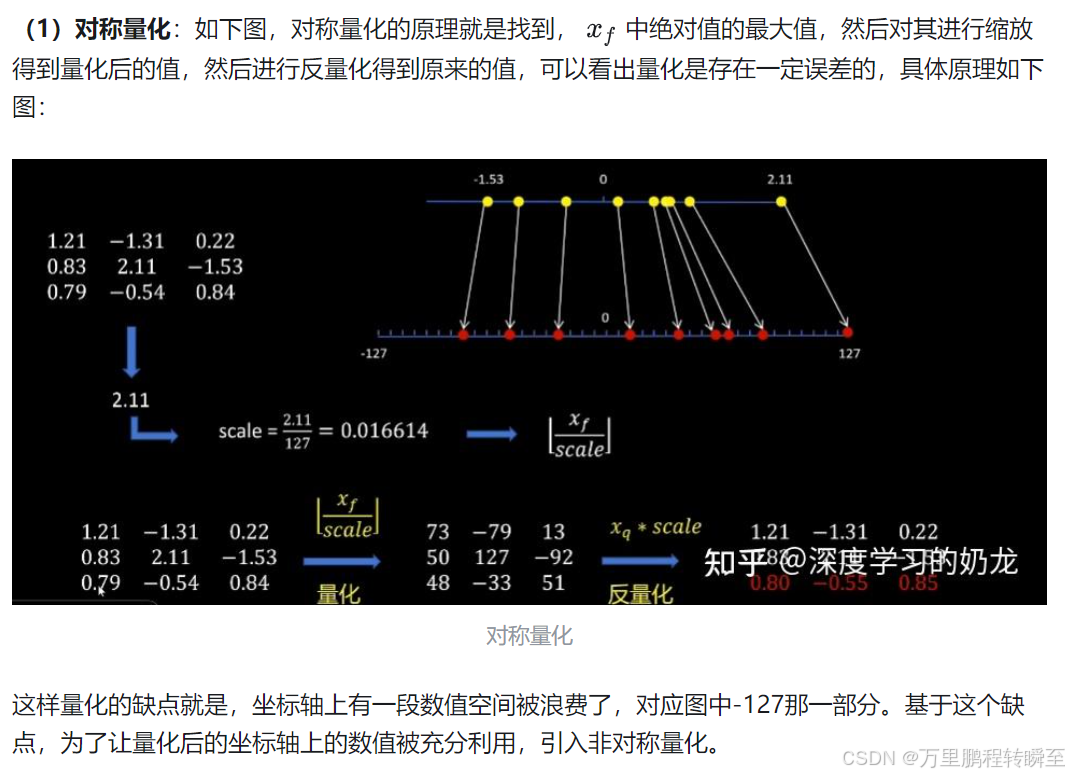
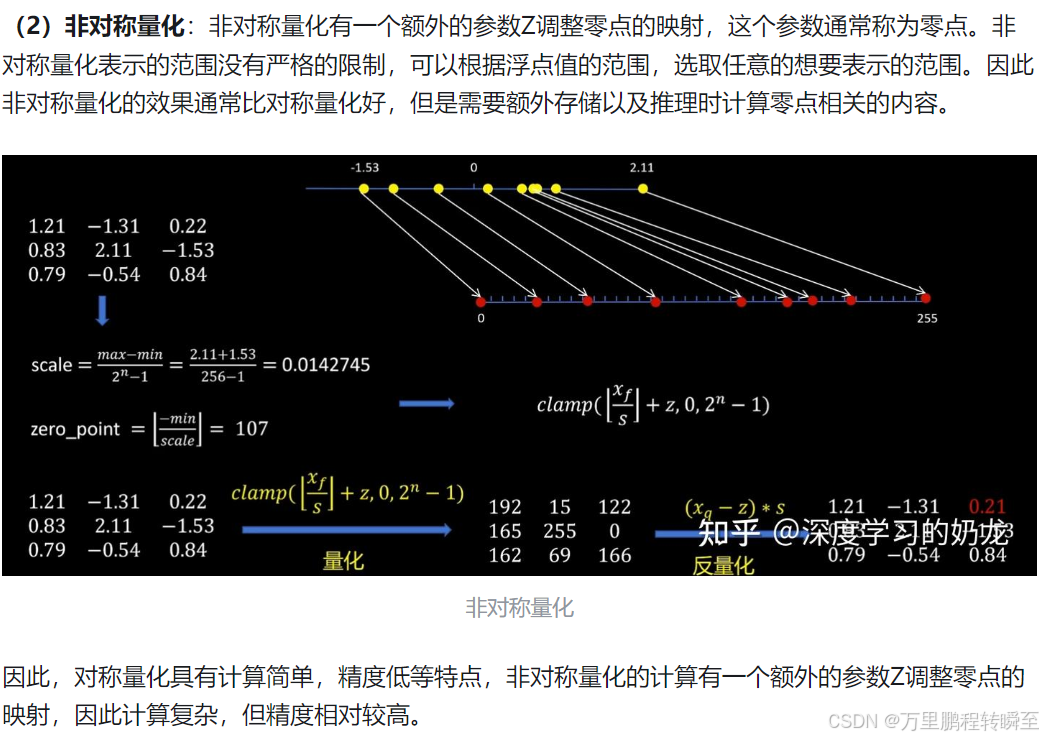
在非對稱量化中,將參數的最小值平移到0點,故值域為0到255。故量化后權重的部分表示范圍均被有效利用了。但非對稱量化,每一次都需要多一個反平移操作,計算量略多,但精度較高。
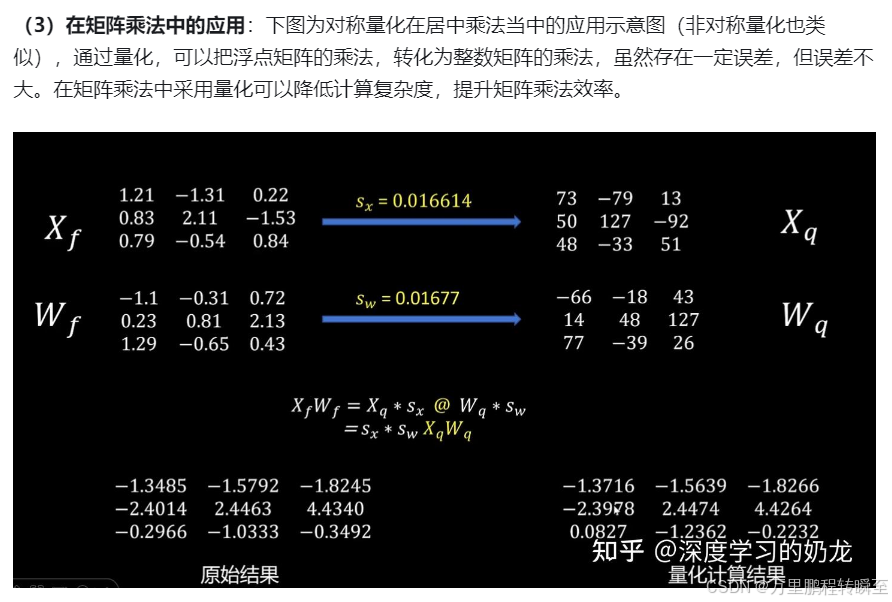
量化后的模型計算方式如下,可以看到下圖,量化后的模型將float的矩陣乘法等價為 int的矩陣乘法+2個float乘法操作,該操作大幅度的發揮了機器的計算能力,同時計算誤差較小。
2.2 量化步驟的分類
根據量化的時機,有量化感知訓練和訓練后量化兩條路徑。PTQ(Post - Training Quantization,訓練后量化)和 QAT(Quantization - Aware Training,量化感知訓練)。
PTQ
- 原理:PTQ是
在模型訓練完成后,對訓練好的浮點數模型進行量化處理,將模型的權重和激活值從較高精度的浮點數格式轉換為較低精度的定點數格式,如INT8、INT4等。其核心思想是通過對模型中的數值分布進行統計分析,確定合適的量化參數,使得量化后的模型在盡可能減少精度損失的情況下,能夠在特定的硬件上高效運行。 - 優點
- 簡單高效:不需要對模型的訓練過程進行修改,只需在訓練結束后進行一次量化操作,即可得到量化后的模型,操作相對簡單,節省了大量的訓練時間和計算資源。
- 通用性強:適用于各種已經訓練好的模型,無論是深度學習模型還是傳統的機器學習模型,只要其權重和激活值可以表示為數值形式,都可以應用PTQ進行量化。
- 缺點:由于是在訓練后進行量化,無法在訓練過程中考慮量化帶來的誤差,因此對于一些對精度要求較高的模型,可能會導致較大的精度損失。
- 應用場景:適用于對
模型精度要求不是特別高,但是希望能夠快速部署到資源受限的設備上,如嵌入式設備、移動設備等,以減少模型的存儲空間和計算量,提高推理速度。
在模型進行PTQ時通常需要收集部分校準數據,用于推斷模型中各層的權重和激活值分布信息,用于計算每個張量(權重或激活值)的量化參數,包括量化比例因子(scale)和零點(zero - point)。這里比較重要的是激活值分布信息,不同的數據輸入,激活值分布是不同的。
QAT
- 原理:QAT是一種
在模型訓練過程中就考慮量化影響的技術。它通過在訓練過程中模擬量化操作,將模型中的浮點數權重和激活值在訓練過程中逐步轉換為低精度的定點數表示。具體來說,在訓練過程中的前向傳播和反向傳播過程中,插入量化和反量化操作,使得模型在訓練過程中就能夠適應量化帶來的精度損失,從而在量化后能夠保持較好的性能。 - 優點
- 精度保持較好:由于在訓練過程中就對量化誤差進行了優化,使得模型能夠更好地適應量化后的數值表示,因此在量化后能夠保持較高的精度,尤其適用于對精度要求較高的任務,如醫學圖像分析、金融風險預測等。
- 靈活性高:可以根據具體的任務和模型特點,在訓練過程中動態調整量化參數,以達到最佳的量化效果。
- 缺點
- 訓練時間長:由于在訓練過程中增加了量化和反量化操作,以及額外的參數調整,使得訓練過程變得更加復雜,訓練時間也會顯著增加。
- 實現復雜:需要對模型的訓練框架進行一定的修改和擴展,以支持量化感知訓練的相關操作,對開發人員的技術要求較高。
- 應用場景:適用于對模型精度要求嚴格,同時又希望通過量化來提高模型的運行效率和減少存儲空間的場景,如數據中心的大規模模型部署、高性能計算等。
2.3 PAT(靜態量化與動態量化)
靜態量化和動態量化是模型量化中兩種不同的技術方法,本質上是對PTQ的不同實現步驟。
靜態量化:就是在模型推理前已經基于部分數據得到了模型的激活值的比例因子(scale)和零點(zero - point)信息。該操作會降低模型精度,但推理速度較快
動態量化:是實時根據輸入數據計算比例因子(scale)和零點(zero - point)。該操作需要對每一個輸入都計算量化因子,若推理引擎支持性差,可能速度提升不明顯,但精度保持性好
量化時機
- 靜態量化:在模型訓練后部署前,根據事先收集的數據來確定量化參數,然后一次性將模型的權重和激活值按照這些固定的量化參數進行量化,整個量化過程是在訓練后靜態進行的,不考慮模型在實際運行時數據的動態變化。
- 動態量化:是在模型部署運行時,根據當前處理的數據動態地計算量化參數,并對數據進行量化。這意味著量化參數會隨著輸入數據的不同而實時調整,以更好地適應數據的動態范圍。
量化參數計算方式
- 靜態量化:通常基于對訓練數據或一小部分代表性數據的統計分析來確定量化參數。例如,計算權重或激活值的最大值、最小值,然后根據這些統計信息計算出固定的量化比例因子和零點,這些參數在模型部署后就不再改變。
- 動態量化:在模型推理過程中,對于每個要量化的張量,會根據當前批次數據的實際分布情況實時計算量化參數。例如,對于每一批輸入數據,動態地計算其均值和標準差,然后根據這些動態統計信息來調整量化比例因子,使得量化能夠更好地適應數據的變化。
模型性能影響
- 靜態量化:優點是實現相對簡單,不需要在運行時進行復雜的參數計算,因此推理速度較快,適用于對推理速度要求較高的場景。但由于量化參數是固定的,可能無法很好地適應不同輸入數據的動態范圍,導致一定的精度損失,尤其是在數據分布變化較大的情況下。
- 動態量化:能夠更好地適應數據的動態變化,因此在量化后通常能保持較高的精度。然而,由于需要在運行時實時計算量化參數,會增加一定的計算開銷,導致推理速度相對較慢。不過,隨著硬件技術的發展,一些專門的硬件架構能夠高效地支持動態量化計算,使得這種方法在一些對精度要求較高的場景中得到了廣泛應用。
適用場景
- 靜態量化:適用于數據分布相對穩定,對模型推理速度要求較高,且能夠接受一定精度損失的場景,如一些嵌入式設備或移動設備上的模型部署,這些設備通常計算資源有限,靜態量化可以在不顯著降低性能的前提下減少模型存儲空間和計算量。
- 動態量化:更適合于數據分布復雜且變化較大,對模型精度要求較高的場景,如在數據中心或高性能計算平臺上運行的模型,這些場景通常有足夠的計算資源來支持動態量化所需的額外計算,同時能夠通過動態量化獲得更好的模型性能。
3、GPTQ與AWQ量化
GPQT與AWQ量化是常見于大模型的量化方法。GPTQ 是一種后訓練量化(PTQ)方法,主要聚焦于 GPU 推理和性能提升。它基于近似二階信息的一次性權重量化方法,能實現高精度和高效的量化。AWQ 即激活感知權重量化,由 MIT - Han Lab 開發。該方法通過觀察激活值來保護顯著權重,而非權重本身,在指令微調的語言模型和多模態語言模型上表現出色。
這里的兩個量化方法與章節2中的量化有所差異,量化后的模型需要特殊的引擎才能推理。通常來說兩個量化方式在大模型上精度保持是差不多的,但是在7b及以下小模型上的量化,awq的量化方式效果保持更好。
3.1 GPTQ量化
這里可以詳細參考:https://zhuanlan.zhihu.com/p/9270075965
GPTQ(GENERATIVE POST-TRAINING QUANTIZATION)量化基于OBQ量化方式改進。OBQ是2022年提出的一種基于二階信息的量化方法,其主要目的就是優化量化后的權重,使量化前后的模型差異值最小。GPTQ量化是一種基于靜態量化的后量化方法,只需要少量校準數據即可

OBQ其主要思想是:
- 逐個量化權重:按照權重對量化誤差的影響,從大到小依次選擇權重進行量化。
- 調整剩余權重:每次量化一個權重后,調整未量化的權重以補償誤差。
- 利用Hessian矩陣:通過二階導數信息,計算權重調整的最優值。
然而,OBQ量化方式計算復雜度比較高,不適用于大模型的量化。

關于GPTQ量化方式(OBD -> OBS -> OBQ ->GPTQ)的演進可以參考:https://zhuanlan.zhihu.com/p/18714878738
按照:https://zhuanlan.zhihu.com/p/9270075965的總結,GPTQ量化進行以下改進

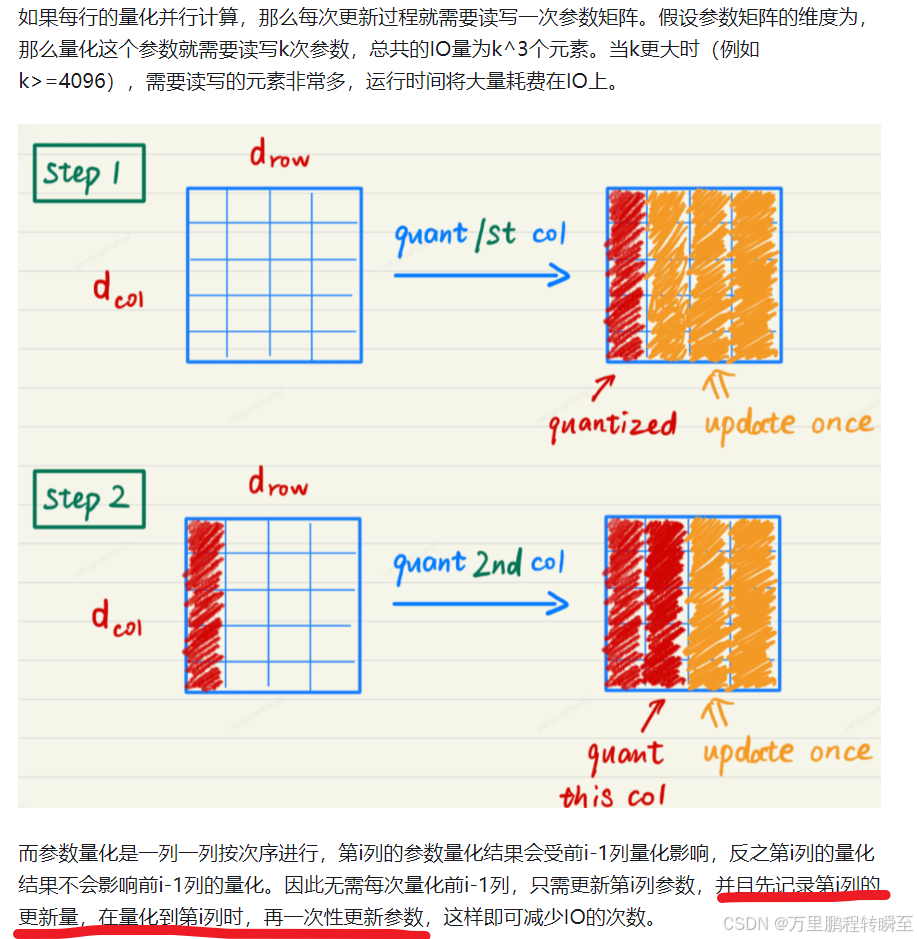
以下圖片是GPTQ減少IO操作的原理示意,針對于后續列的更新,只是先累加記錄更新值,不進行寫操作,等到量化該列時才更新參數。
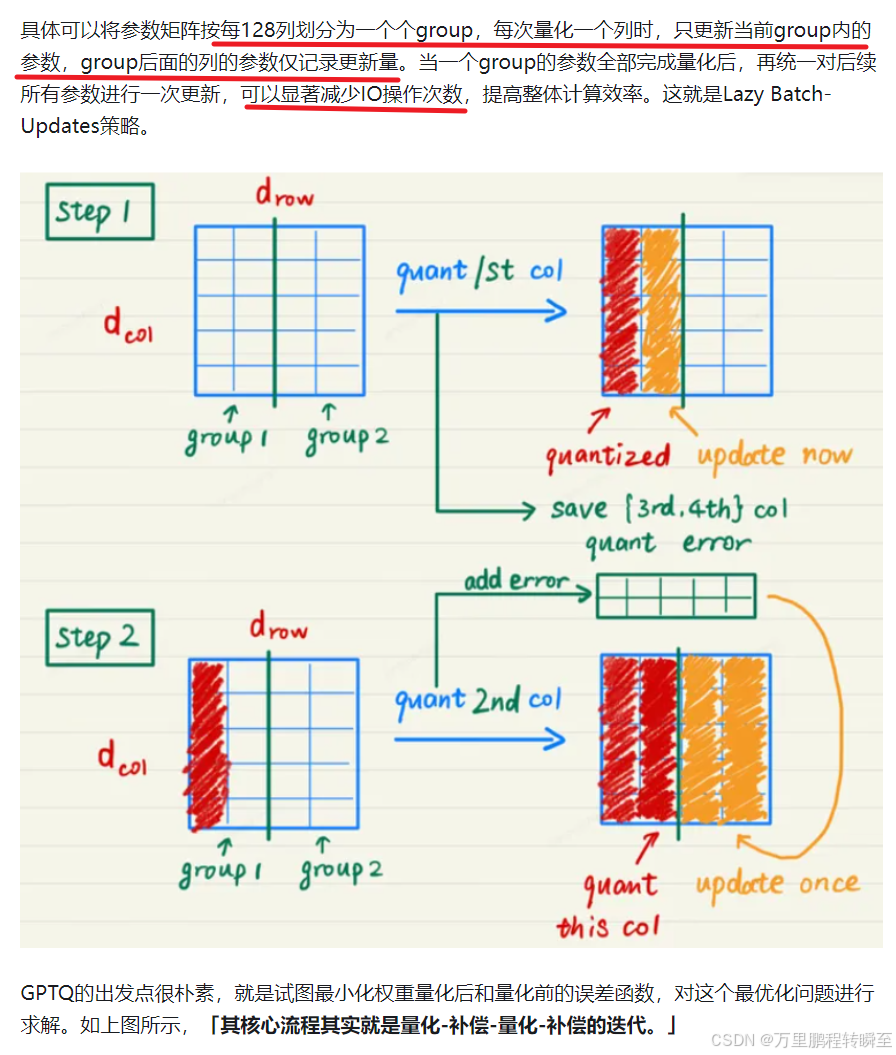
以下圖片是GPTQ減少IO操作的具體流程,與原型示意相比補充了group跟新的概念,明顯緩解了累加記錄更新值的變量需求。

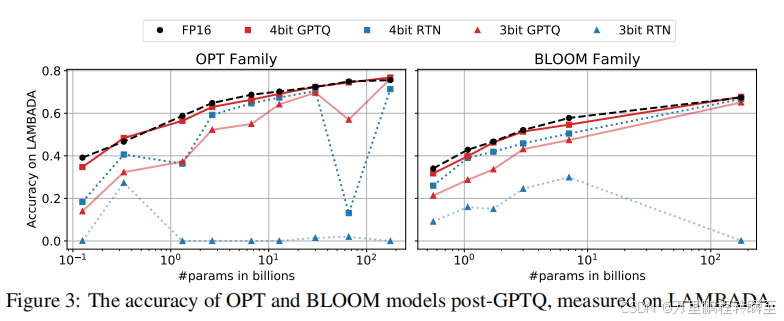
根據GPTQ論文中的數據,可以發現int4量化后于fp16保持了相同的精度
3.2 AWQ量化
激活感知權重量化 (AWQ),這是一種適合硬件的 LLM 低位權重(比如 w4)量化方法。AWQ 發現,并非所有 LLM 權重都同等重要,僅保護 1% 的顯著權重便能大幅減少量化誤差。AWQ 不依賴反向傳播或重構,因此可以泛化到不同領域和模態而不會對校準集過擬合。
以下信息參考自:https://www.armcvai.cn/2024-11-01/llm-quant-awq.html
如何選擇出重要權重
對激活值的每一列求絕對值的平均值,然后把平均值較大的一列對應的通道視作顯著通道,保留 FP16 精度。

如果權重矩陣中有的元素用FP16格式存儲,有的用INT4格式存儲,不僅存儲時很麻煩,計算時取數也很麻煩,kernel函數寫起來會很抽象。于是,作者想了一個變通的方法——Scaling。
如何利用重要權重
對于所有的元素進行int量化,但引入逐通道縮放減少關鍵權重的量化誤差,避免硬件效率問題。量化時對顯著權重進行放大即引入縮放因子 s,是可以降低量化誤差的。
計算縮放因子 s*
作者統計各通道的激活值平均值(計算輸入矩陣各列絕對值的平均值)sX ,將此作為各通道的縮放系數。


 高頻詞匯背誦)
)
)







之制作簡單的倒計時)

)



)

—— DQL)