作者:付宇軒(計緣)
DeepSeek/QWen 普惠 AI 趨勢
隨著 DeepSeek-R1 的橫空出世,又一次點燃了原本已經有點冷淡的大語言模型市場和話題,并且快速成為了現象級,小到中小學生,大到父母輩都知道了中國出了一個叫 DeepSeek 的大語言模型。各個行業,各個企業又都開啟了新一輪的 AI 賦能/改進業務的浪潮。工信部發文力推最新AI技術普惠應用,三家運營商全面接入 DeepSeek。國務院國資委召開中央企業“AI+”專項行動深化部署會。種種現象都表名,在 DeepSeek 引發的“鯰魚效應”下,AI 熱潮持續升溫,各個企業都愿意花錢進行嘗試,云廠商 GPU 形態,線下一體機形態,云廠商 DS API 形態多種形態并存。

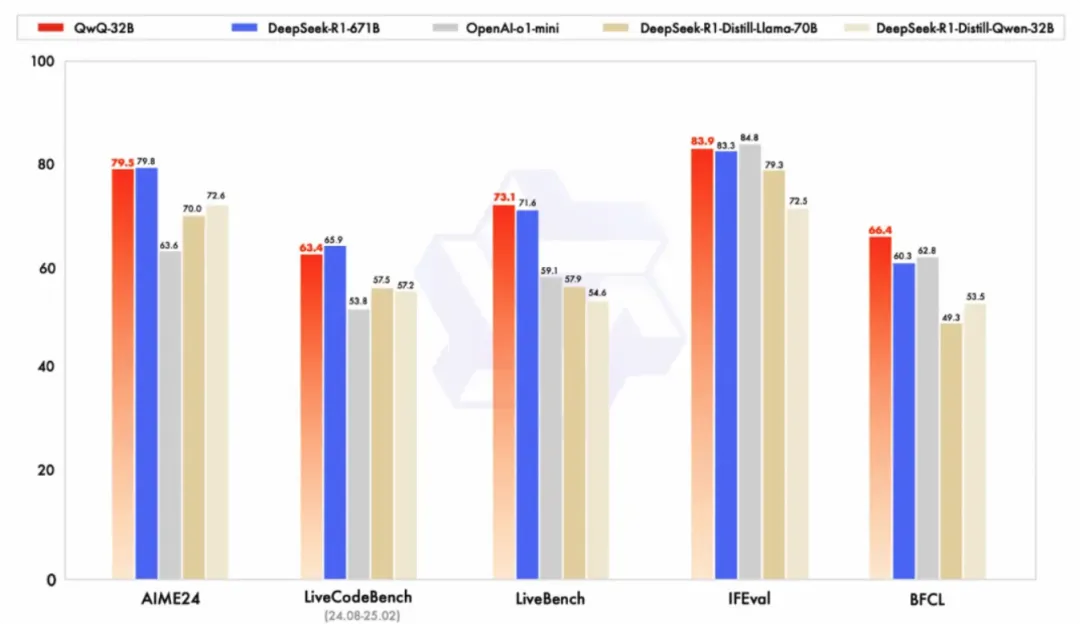
3 月 6 日凌晨,阿里云通義千問發布了最新的 QWQ 32B 模型,在僅有 DeepSeek-R1 約 1/20 參數量的情況下, 用強化學習,實現了性能上的驚人跨越,并且同樣是開源開放的。Qwen 團隊表示,QwQ-32B 的發布只是他們在強化學習方向上的初步嘗試。未來,他們將繼續深入探索 RL 的潛力,并將其與更強大的基礎模型相結合,利用更大的計算資源,致力于打造下一代 Qwen 模型,并最終邁向通用人工智能 (AGI) 目標。所以可見模型尺寸更小,性能更強是未來的一個趨勢,也是大語言模型普惠市場,AI 普惠市場的基石。
LLM 生產項目中必然會遇到的問題
在AI普惠的過程中,有一個顯著的特點就是用戶們選擇使用 LLM 的方式變多了,自主可控能力變強了。比如可以購買 GPU 資源自己部署模型,可以在線下機房部署,也可以使用阿里云的PAI或者函數計算 FC 來部署。也可以使用各個模型托管平臺,通過 API 的方式來使用大語言模型。但無論選擇哪種方式,在 LLM 應用上生產項目的過程中,必然都會遇到一系列問題:
- 成本平衡問題:部署 DeepSeek R1 671B 滿血版模型,至少需要 2 臺 8 卡 H20 機器,列表價年度超過 100W,但 2 臺的 TPS 有限,無法滿足生產部署中多個用戶的并發請求,需要有方案找到 TPS 和成本之間的平衡點。
- 模型幻覺問題:即使是 DeepSeek R1 671B 滿血版模型,如果沒有聯網搜索,依然有很嚴重的幻覺問題。
- 多模型切換問題:單一模型服務有較大的風險和局限性,比如穩定性風險,比如無法根據業務(消費者)選擇最優模型。目前也沒有開源組件和框架解決這類問題。
- 安全合規問題:企業客戶需要對問答過程做審計,確保合規,減少使用風險。
- 模型服務高可用問題:自建平臺性能達到瓶頸時需要有一個大模型兜底方案,提升客戶大模型使用體驗。
- 閉源模型 QPS/Token 限制問題:商業大模型都有基于 API Key 維度的 QPS/Token 配額限制,需要一個好的方式能夠做到快速擴展配額限制。
云原生 API 網關簡述
阿里云的云原生 API 網關是將流量網關、微服務網關、安全網關和 AI 網關四合一的網關產品,實現碎片化網關的架構統一,提供服務暴露及流量管控、AI 應用流量入口與集成、API 全生命周期管理等能力,具有性能更強勁(高出自建 1~5 倍)、穩定更可靠(技術積淀已久,歷經多年雙 11 考驗 )、多重安全防御(mTLS 雙向認證、登錄認證、集成應用防火墻、自定義安全插件)、擴展性強(提供豐富的插件,支持熱更新),是高性能、安全、AI 友好的統一型網關。
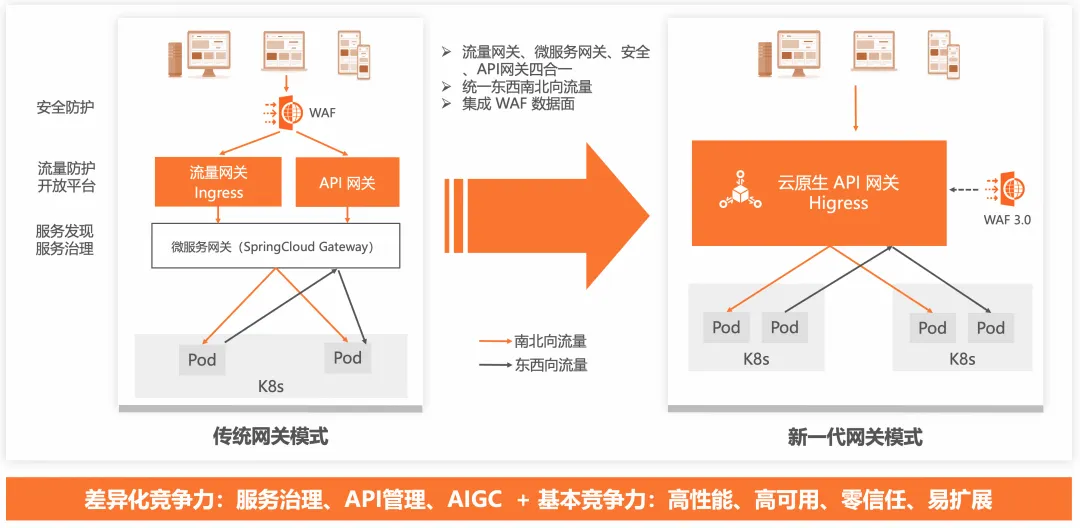
它在整個應用架構中起到鏈接的核心作用,比如:
- 在整個系統的入口層,作為流量網關,鏈接各類終端,管控流量。
- 在微服務場景下作為東西向的網關,鏈接前臺服務和后臺服務,肩負流量管控、鑒權等職責。
- 在 SaaS 行業,開發者平臺,API 平臺這類場景下,作為 API 網關統一管理各個生態的流量,肩負消費者認證、安全、流控等職責。
- 在 AI 場景下,作為代理 LLM 服務的 AI 網關,肩負基于 Token 限流、模型切換、多 API Key 管理、安全等職責。
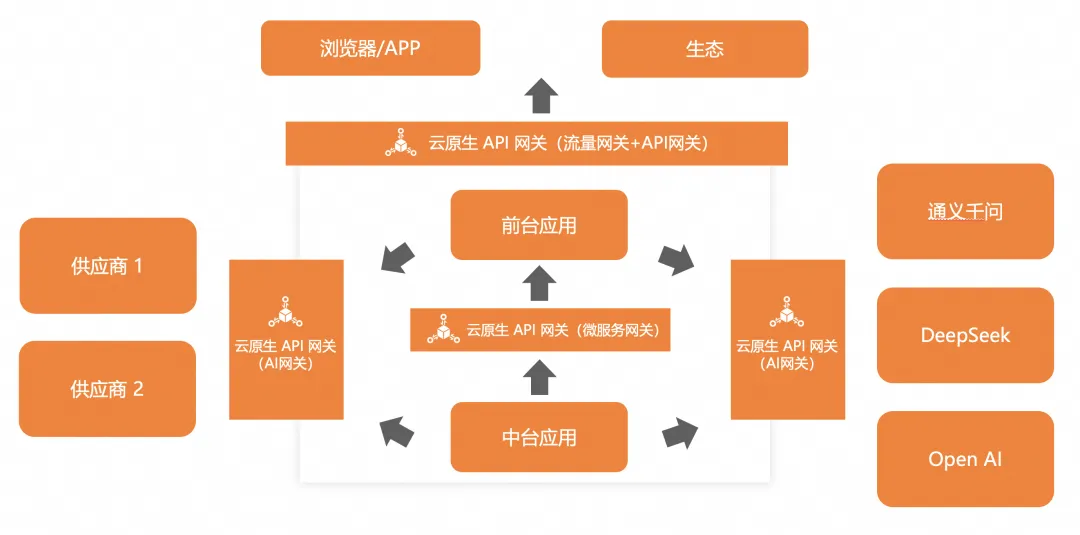
云原生 AI 網關簡述
云原生 AI 網關其實并不是一個新的獨立的產品,而是屬于云原生 API 網關產品內的一部分功能,基于 AI 的場景,設計了更貼合 AI 業務的 AI API 及各個功能。同時也具備云原生 API 網關本身提供的各個通用能力。
目前通義、百煉、PAI 都集成云原生 AI 網關,每天承載億級別的多模態請求,通過真實生產項目去打磨,踐行了 Dog Food 原則。
云原生 AI 網關整體的核心能分為四大塊:
- 多模型適配:可以代理市面上所有主流的模型托管服務,以及兼容 OpenAI 協議的 AI 服務。在這個模塊中包括協議轉換、多 API Key 管理、Fallback、多模型切換等多個核心功能。
- AI 安全防護:安全防護分為三個層面,一個是輸入輸出的內容安全防護,另一個是保護下游 LLM 服務的穩定,以及管控AI接口消費者。在這個模塊中包括內容審核、基于 Token 的限流降級、消費者認證等多個核心功能。
- AI 插件:AI 網關的靈活擴展機制我們使用插件的形式來實現,目前有很多預置的插件,用戶也可以開發自定義插件來豐富 AI 場景流量的管控。比如基于 AI 插件機制我們實現了結果緩存、提示詞裝飾器、向量檢索等能力。
- AI 可觀測:AI 場景的可觀測和傳統場景的可觀測是有很大區別的,監控和關注的指標都是不同的,云原生 AI 網關結合阿里云日志服務和可觀測產品實現了貼合 AI 應用業務語義的可觀測模塊和 AI 觀測大盤,支持比如 Tokens 消費觀測,流式/非流式的 RT,首包 RT,緩存命中等可觀指標。同時所有的輸入輸出 Tokens 也都記錄在日志服務 SLS 中,可供用戶做更詳細的分析。
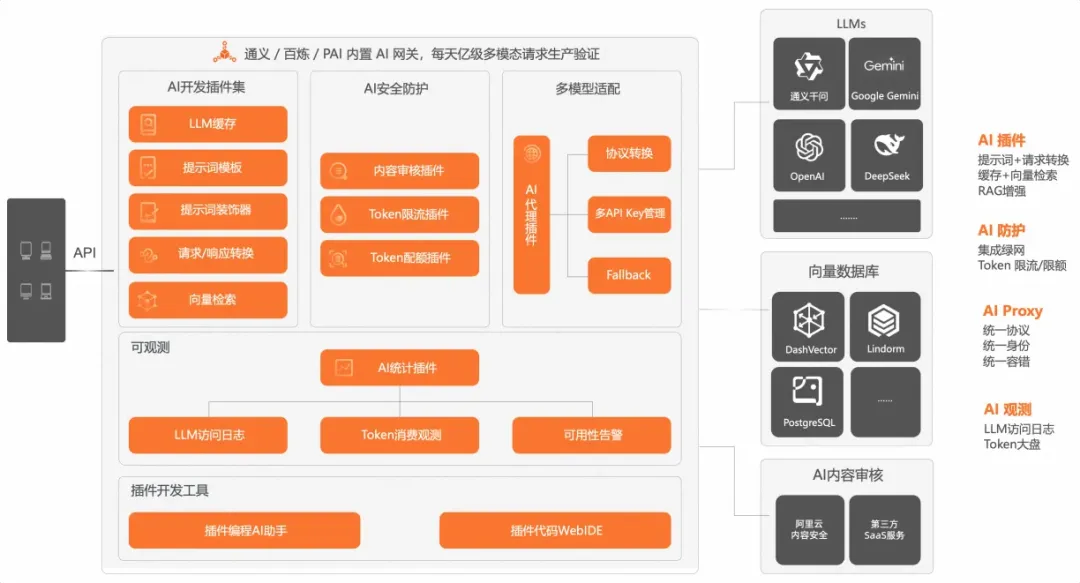
云原生 AI 網關代理 LLMs 方案
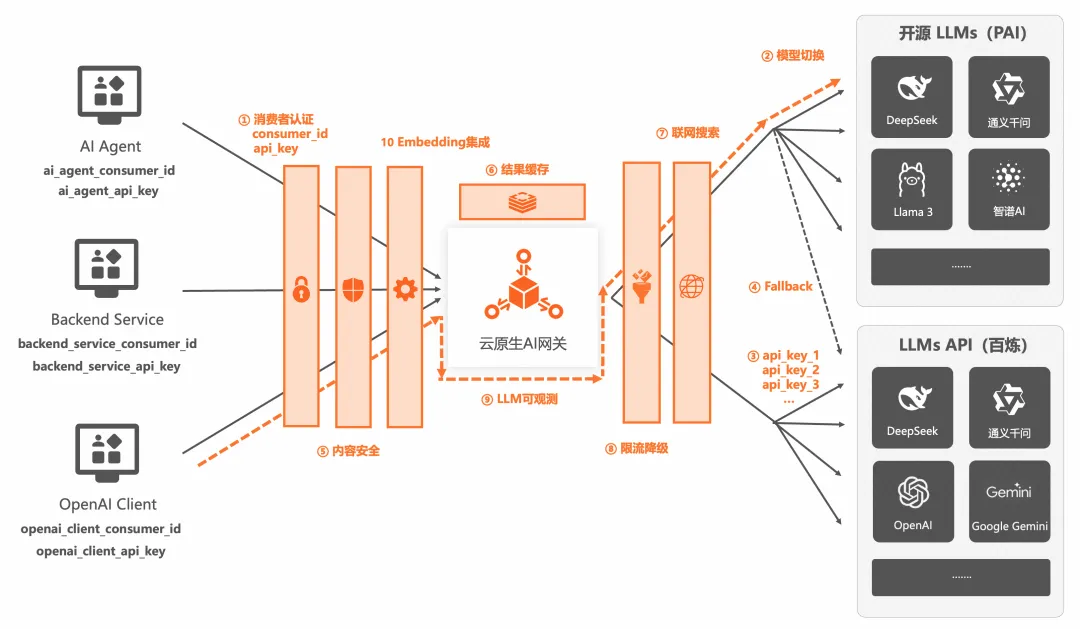
從上圖架構中可以看出,AI 網關代理 LLM 方案的架構并不復雜,但是在 AI 應用上生產的過程中通常會遇到 9 個核心的問題,然而在上面這個并不復雜的架構下,通過 AI 網關都可以很有效的解決。接下來我們通過用戶視角、業務場景視角來逐一分析和說明。
解決用戶管理失控的問題
現在大大小小的企業應該都在部署 LLM,想方設法的融入到業務中,或日常工作中,那么站在運維團隊或者類似中臺團隊的視角下,可能會有兩個核心的問題:
- 核心問題 1:我以什么樣的方式將 LLM 服務和能力暴露給大家呢?
- 核心問題 2:企業內部部署 DeepSeek-R1 滿血版,公司好幾千人,但 GPU 資源有限,如何限制用戶?
第一個問題很好解決,OpenAI API 的協議基本已經是標準協議,目前市場面上幾乎所有的 LLM 都支持 OpenAI API 協議。所以提供遵循 OpenAI API 協議的 HTTP 接口就可以讓企業員工通過各種方式使用 LLM 服務和能力。
對于第二個問題,AI 接口一旦暴露出去,基本上不可能只讓一小部分人知道,所以需要對訪問 LLM 服務的用戶做以限制,只讓能訪問的人訪問,不能訪問的人即便知道了接口也無法訪問。
所以可以使用 AI 網關具備的消費者認證的能力來解決這個問題。
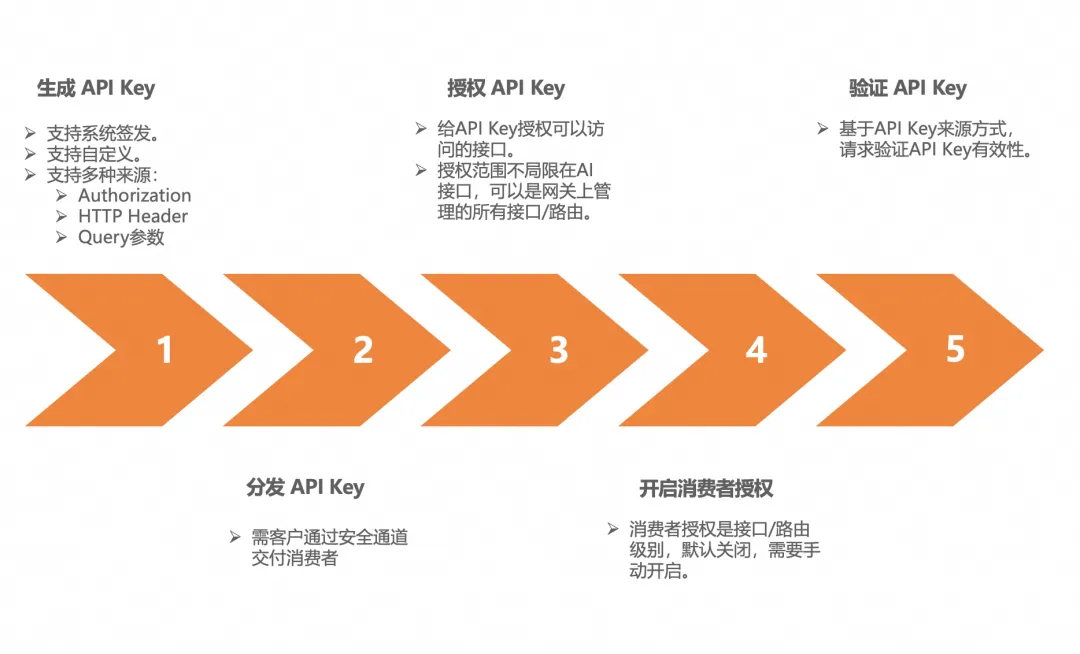
核心邏輯是將一個人或一組人抽象為消費者的概念,可以對消費者做權限配置,既可以訪問哪些接口,消費者下可以生成不同類型的 API Key,請求接口時需要帶著 API Key,然后基于權限規則去校驗 API Key 的合法性。通過這種就可以精細化的管理訪問 AI 接口用戶了。
消費者認證的核心價值:
- 身份可信:確保請求方為注冊/授權用戶或系統。
- 風險攔截:防止惡意攻擊、非法調用與資源濫用。
- 合規保障:滿足數據安全法規及企業審計要求。
- 成本控制:基于鑒權實現精準計費與 API 配額管理。
典型鑒權場景與 API Key 應用場景:
-
第三方應用接入:
- 挑戰:開發者身份混雜,權限難隔離。
- 解決方案:為每個應用分配獨立 API Key,綁定細粒度權限策略。
-
企業內部服務調用:
- 挑戰:內網環境仍需防越權訪問。
- 解決方案:API Key + IP 白名單雙重驗證,限制訪問范圍。
-
付費用戶 API 訪問:
- 挑戰:防止 Key 泄露導致超額調用。
- 解決方案:針對 API Key 限流。
-
跨云/混合部署:
- 挑戰:異構環境統一身份管理。
- 解決方案:集中式 API Key 管理平臺,支持多集群同步鑒權。
解決同一域名訪問不同模型的問題
核心問題:公司 GPU 資源有限,部署了滿血版 DeepSeek-R1,還有其他一些小模型以及使用百煉的模型服務,現在域名都不統一,分發、管理、集成的成本都很高,如何使用同一個域名來訪問不同的模型?
這個問題是本質是滿血 DS R1 和其他模型或者閉源 LLM API 服務共存,保持同一個 API 接口,不同業務通過請求中的模型名稱,切換不同的模型。因為目前 LLM 的 API 都是遵循了 OpenAI 協議的,所以使用請求 Body 里的模型名稱來切換模式是更加通用的。
云原生 AI網關支持一個 AI API 下配置多個模型服務的能力,每個模型服務通過 Glob 語法來匹配模型名稱,從而實現上述需求。
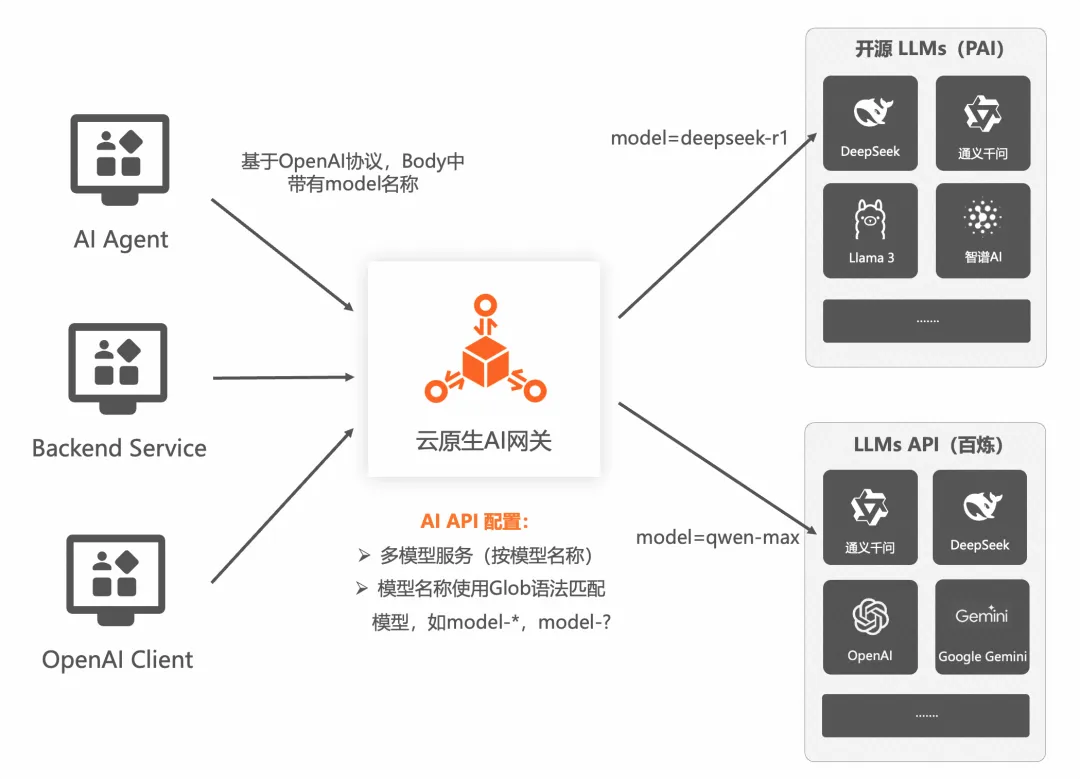
再延伸一下模型切換的核心價值:
- 業務需求適配:根據業務復雜性或性能要求選擇不同模型。
- 數據隱私與合規性:在處理敏感數據時,可能需要切換到符合特定法規的模型,確保數據處理的安全性。
- 性能優化:根據實時性能需求,可能會切換到更快的模型以減少延遲。
- 成本與性能平衡:根據預算動態選擇性價比最優的模型
- 領域特定需求:針對特定領域(如法律、醫學),可能需要切換到在相關領域微調過的模型,以提高推理準確性。
- 容災與故障轉移:主模型服務異常時快速切換備用模型。
解決閉源模型&模型托管平臺 QPM/TPM 限制的問題
像 ChatGPT,豆包這類閉源 LLM,或者百煉這種托管 LLM 平臺,都是以提供 API 的方式供大家使用 LLM 的能力,但是受限底層 GPU 資源的壓力,以及整體平臺的穩定性,每個用戶都有請求 QPS 的最大限制(基于平臺的 API Key 的維度),且上調比較困難。所以很多客戶都有這個核心問題:如何突破這個限制問題?
這個問題有兩類解決方案:
- 我們知道這些平臺上調限制額度比較困難,那么就用曲線救國的方式,既多申請一些帳號,來變相的把限制額度撐大,但是又會帶來新的問題,那就是這些帳號的 API Key 如何管理的問題。
- 另一個方法就是對輸入/輸出內容做緩存,減少對模型服務的請求次數以及 Token 消耗,從而提升業務側的請求性能,相當于變相增加了限制額度。
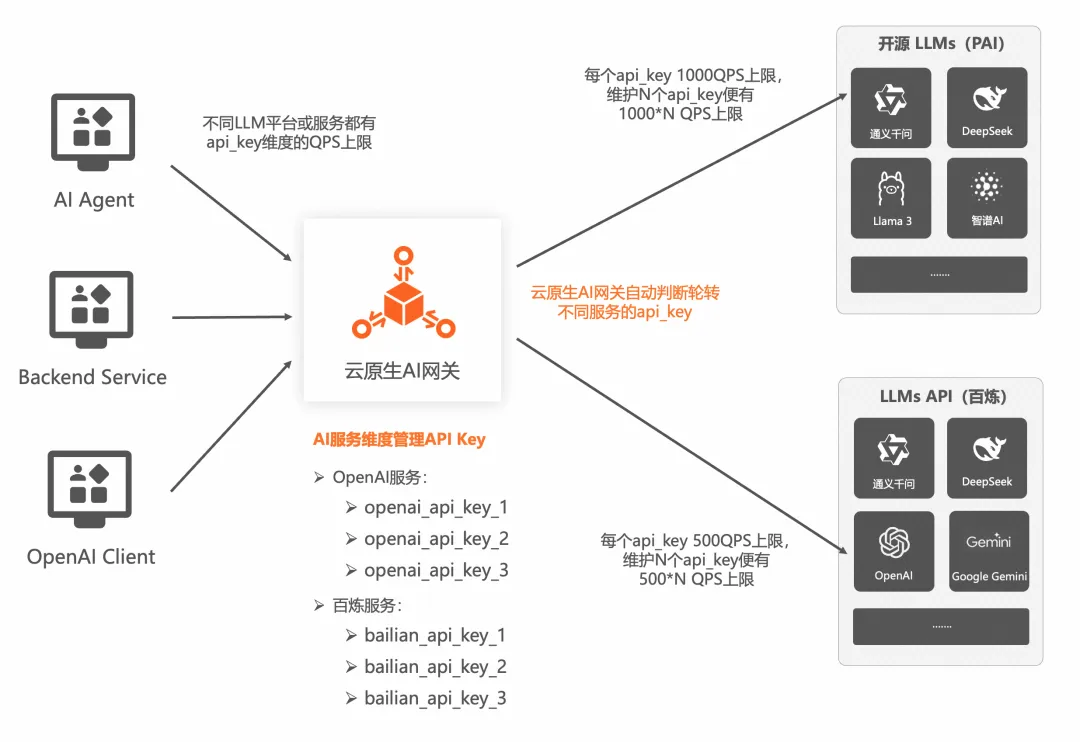
多API Key管理
云原生 AI 網關在 AI 服務級別支持多 API Key 管理的能力,每次請求會輪循取一個 API Key 向后端模型服務請求。并且 API Key 可以動態新增和刪除,極大減輕了用戶自己維護多個 API Key 的問題。
結果緩存
云原生 API 網關提供了擴展點,可以將請求和響應的內容緩存到 Redis,提升推理效率。目前支持按照問題精確匹配,基于向量化檢索的匹配也在支持中。
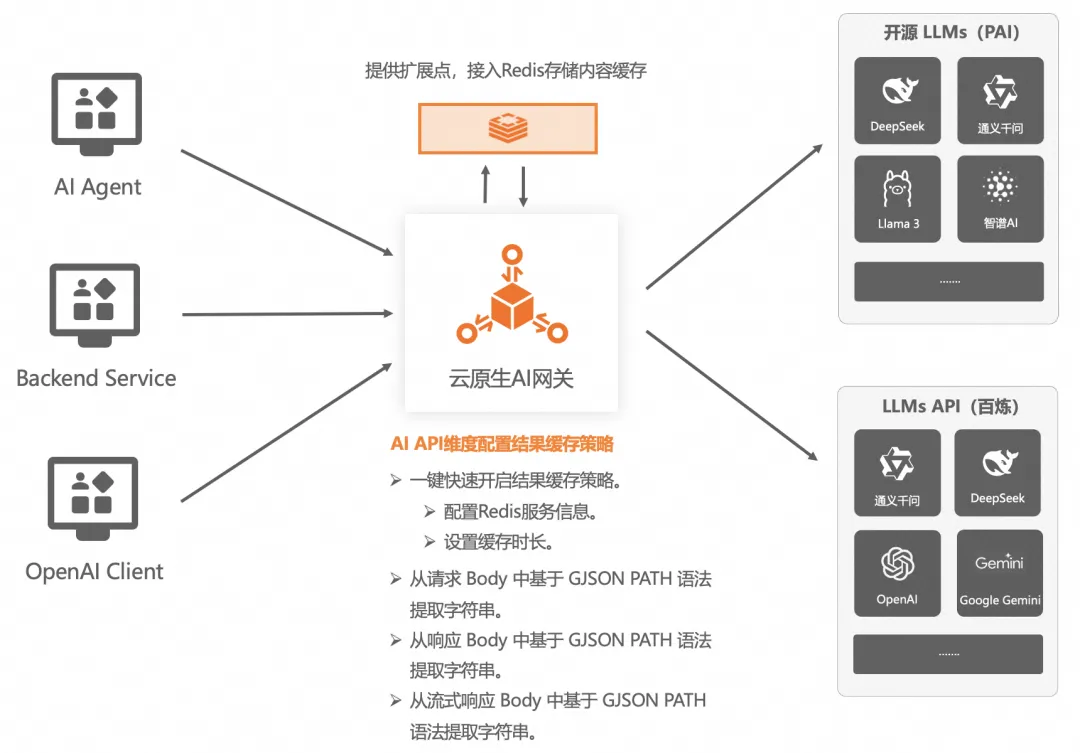
需要注意的是,這個功能建議只在非常垂直類的應用場景下適合使用,在泛業務場景下開啟結果緩存可能會降低推理精度或準確性,需要結合業務判斷和考量。
解決模型服務高可用的問題
現在 GPU 的資源是昂貴的,所以無論是自購 GPU 部署 LLM 還是模型托管平臺都不會基于流量峰值去儲備資源,所以才會有上文中的 QPM/TPM 限制的情況。但是站在用戶業務健壯性的角度來看,如何在成本、穩定性、健壯性之間找到一個平衡點是更需要考慮的事。比如:我們公司的主力模型是 PAI 上部署的 DS R1 671B,但 GPU 資源并不是基于流量峰值儲備的,所以當高峰期時,DS 服務會請求失敗,有什么辦法可以保證業務健壯性?
這類問題可以有兩種做法,并且可以搭配使用:
- 可以構建多個個兜底模型服務,如果要保證模型一致,可以主力使用 PAI 上部署的,兜底使用百煉平臺提供的。實現當 PAI 上部署的 DS 服務請求失敗時,Fallback 到百煉平臺托管的 DS R1 服務。從而保證業務的連續性和健壯性。
- 通過基于 Tokens 的限流策略,解決 Burst 流量,保護后端模型服務。
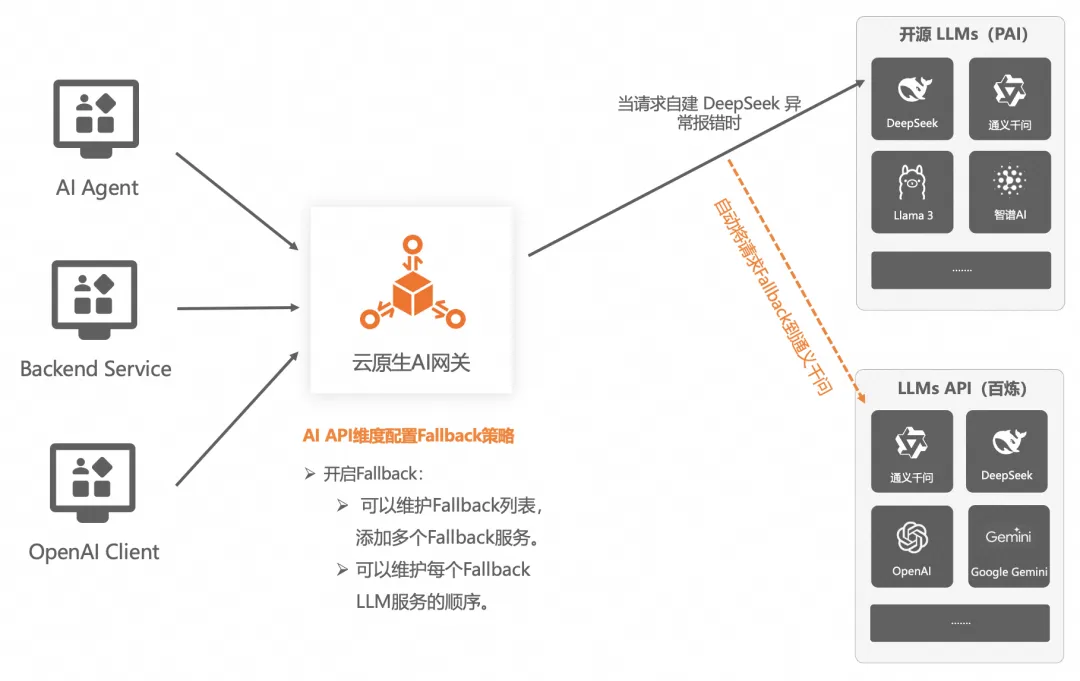
LLM 服務 Fallback
云原生 AI 網關在 AI API 維度支持 LLM 服務的 Fallback 機制,并且可以配置多個 Fallback LLM 服務。當主 LLM 服務因為各種原因出現異常,不能提供服務時,網關側可以快速將請求 Fallback 到配置的其他 LLM 服務,雖然可能推理質量有所下降,但是保證了業務的持續性,爭取了排查主 LLM 服務的時間。
Token 維度限流
除了傳統的 QPS 限流降級以外,云原生AI網關支持更貼合 LLM 推理場景的 Token 維度的限流能力。可以針對 AI API 級別配置一個下游 LLM 服務可以承載的請求量級,在一定程度上保證了整體業務的健壯性,至于被限流的請求,可以返回一些人性化的信息,比如 DeepSeek 官網的服務器繁忙。
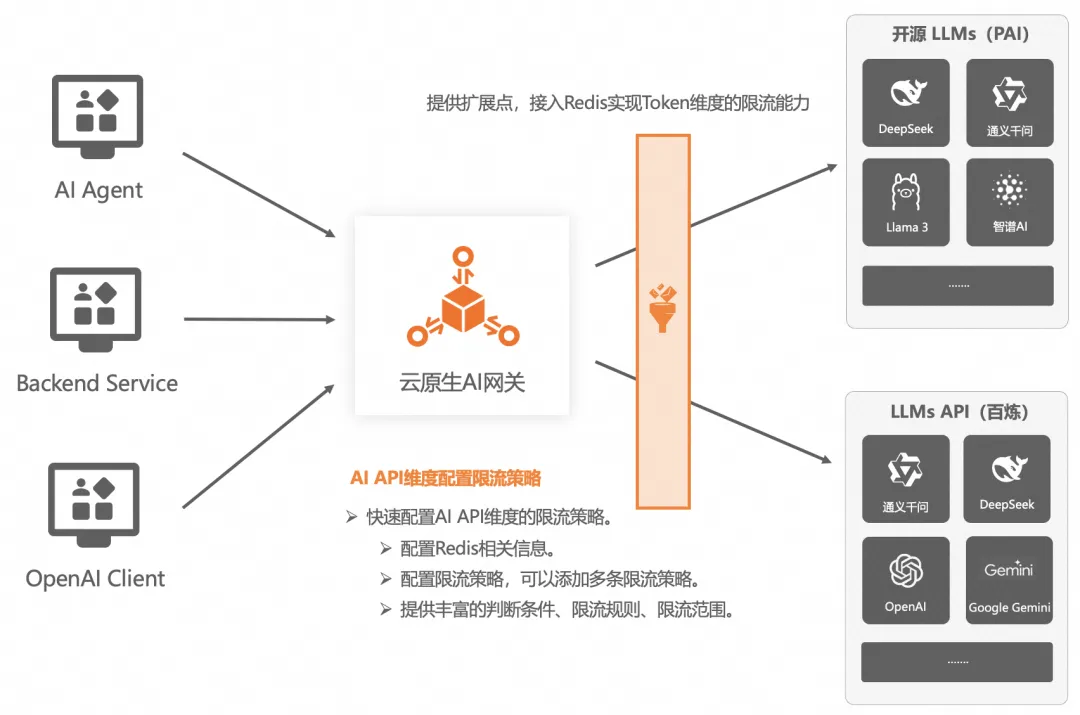
我們可以再延伸一下基于 Token 維度限流的其他核心價值:
- 成本管理:LLM 的費用通常基于 Token 數量計算,限流幫助用戶避免超支。例如,服務提供商可能按 Token 使用量提供不同定價層。
- 資源管理:LLM 需要大量計算資源,限流防止系統過載,確保所有用戶都能獲得穩定性能,尤其在高峰期。
- 用戶分層:可以基于 ConsumerId 或者 API Key 進行 Token 限流。
- 防止惡意使用:通過限制 Token 數量來減少垃圾請求或攻擊。
解決安全合規問題
AI 應用場景下的內容安全問題是大家都很重視的核心問題,模型托管平臺通常都自帶好幾層內容安全審核機制,但是我們在 IDC 部署或者在 PAI 部署的,如何能方便的接入內容安全審核服務?
AI 網關中的 AI API 集成了阿里云的內容安全防護服務,可以一鍵開啟,支持請求內容檢測和響應內容檢測。不過安全防護的規則還是要在內容安全服務側配置。比如“樹中兩條路徑之間的距離”這個可以讓 LLM 無限推理的問題,從內容安全的常規規則來看,它是合規的,但是它卻能對 LLM 服務的穩定性造成隱患,所以在 AI 網關開啟了內容安全防護后,便可以快速的在內容安全防護服務中添加自定義規則來杜絕這類有潛在風險的請求信息。
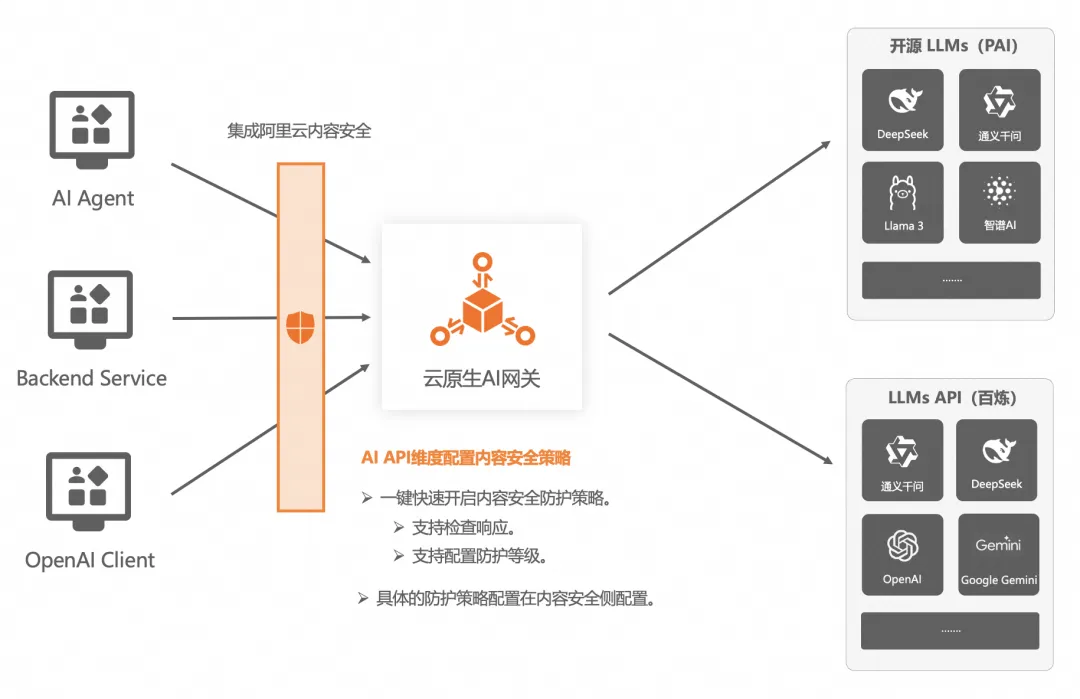
延伸到內容安全在 AI 領域的核心價值有五類:
- 防止攻擊:驗證輸入可以阻止惡意提示注入,防止模型生成有害內容。
- 維護模型完整性:避免輸入操縱模型,導致錯誤或偏見輸出。
- 用戶安全:確保輸出沒有有害或誤導性內容,保護用戶免受不良影響。
- 內容適度:過濾掉不適當的內容,如仇恨言論或不雅語言,特別是在公共應用中。
- 法律合規:確保輸出符合法律和倫理標準,尤其在醫療或金融領域。
解決大語言模型幻覺的問題
有些個人用戶或者企業用戶可能會發現部署了 DeepSeek R1 671B 的模型,但推理的結果和 DS 官網推理的結果有差距,似乎不滿血?
推理的結果和 DeepSeek 官網推理的結果有差距是因為 DeepSeek 官網開啟了聯網搜索。DeepSeek R1 671B 的模型推理能力是很強,但訓練的數據也是有限的,所以要解決幻覺還需是要在推理前先搜索和處理出比較確切的信息后,再由 DeepSeek R1 推理,所以聯網搜索是非常關鍵的。目前模型托管平臺提供的 DeepSeek R1 API 和自己部署的 DeepSeek R1 都需要自己實現聯網搜索。
其實不只是 DeepSeek,目前除了百煉上的通義千問 Max 以外,其他的模型在 API 層面都不支持聯網搜索,即使 ChatGPT 是最早推出聯網搜索功能的,但 OpenAI 的 API 協議目前也還沒有支持聯網搜索。
云原生 AI 網關目前在 AI API 維度支持了夸克和必應的聯網搜索能力,提供多種搜索策略,可將搜索結果自動如何進輸入 Prompt,無需用戶對后端 LLM 服務做額外處理,并且我們對輸入的問題也通過 LLM 做了意圖識別,避免了很多無效的聯網搜索。
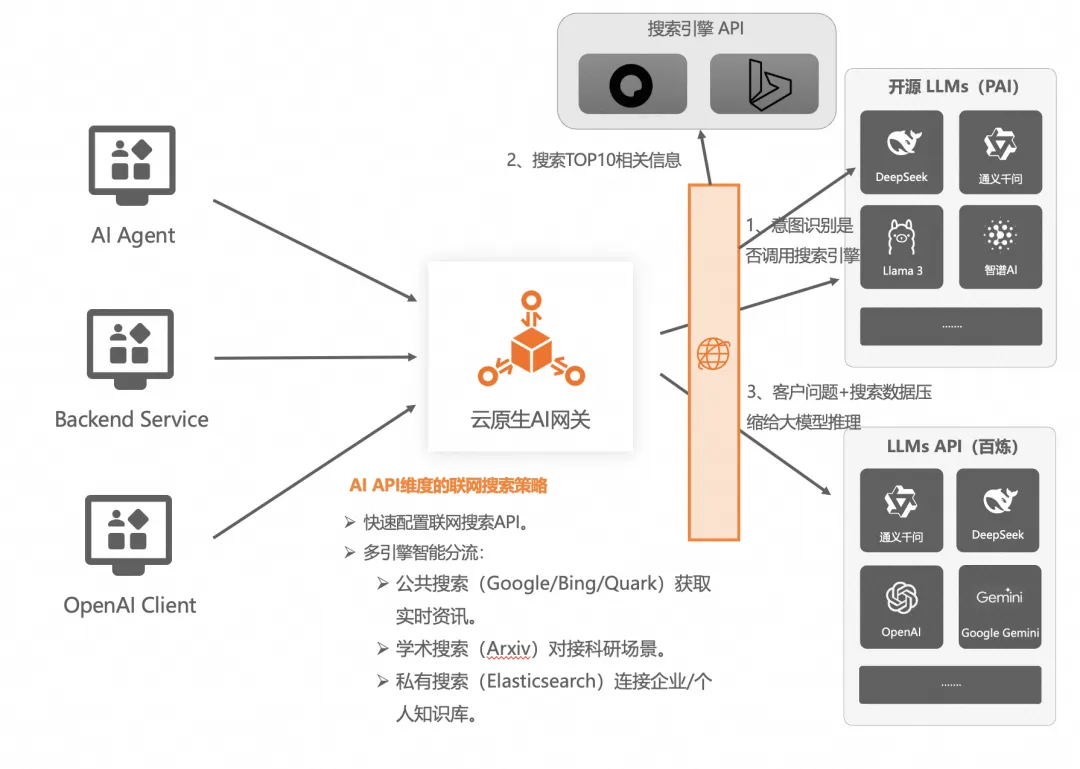
解決 AI 領域可觀測問題
可觀測是任何一個領域都必不可少的需求,但是 AI 場景的可觀測和傳統場景的可觀測是有很大區別的,監控和關注的指標都是不同的,云原生 AI 網關結合阿里云日志服務和可觀測產品實現了貼合 AI 應用業務語義的可觀測模塊和 AI 觀測大盤,支持比如 Tokens 消費觀測,流式/非流式的 RT,首包 RT,緩存命中等可觀指標。同時所有的輸入輸出 Tokens 也都記錄在日志服務 SLS 中,可供用戶做更詳細的分析。
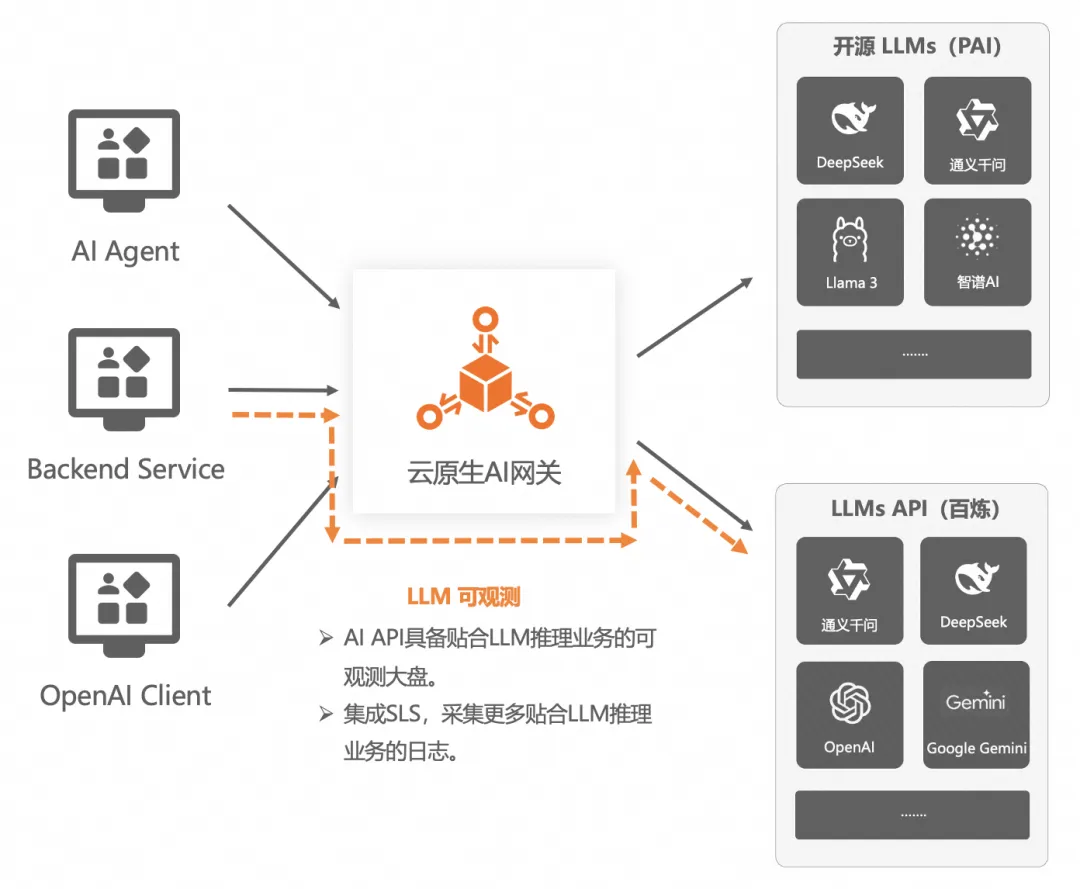
AI 網關可觀測核心能力:
- 訪問日志,其中的 ai_log 字段可以自動打印大語言模型的輸入、輸出。
- 大語言模型的 metrics 信息: 首字延時(TTFT-Time To First Token), tokens per second。
- 傳統指標: QPS( request per second), RT(延時),錯誤率。
- 網關功能指標:
- 基于 consumer 的 token 消耗統計(需要把 consumer 的 header 信息加到 sls 的日志里)
- 基于模型的 token 消耗統計。
- 限流指標: 每單位時間內有多少次請求因為限流被攔截; 限流消費者統計(是哪些消費者在被限流)。
- 緩存命中情況。
- 安全統計:風險類型統計、風險消費者統計。


![Muduo網絡庫實現 [九] - EventLoopThread模塊](http://pic.xiahunao.cn/Muduo網絡庫實現 [九] - EventLoopThread模塊)

面向對象--封裝(6)C#中的拓展方法與運算符重載: 讓代碼更“聰明”的魔法)









——Vision Transformer(ViT)模型架構介紹)
>)


----替換主干網絡之StarNet)
