1.問題背景:集群內存風暴引發的危機
最近某大數據集群頻繁出現節點掉線事故,物理內存監控持續爆紅。運維人員發現當節點內存使用率達到95%以上時,機器會進入不可響應狀態,最終導致服務中斷。這種"內存雪崩"現象往往由單個異常任務引發,如何快速定位問題作業成為當務之急。
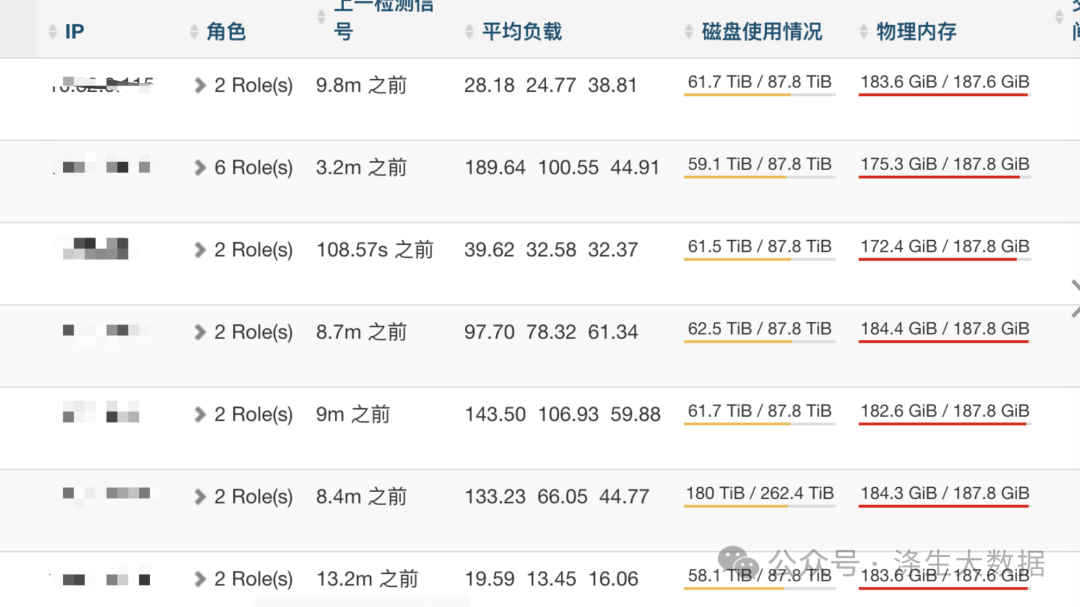
2.排查武器庫:核心工具與數據源
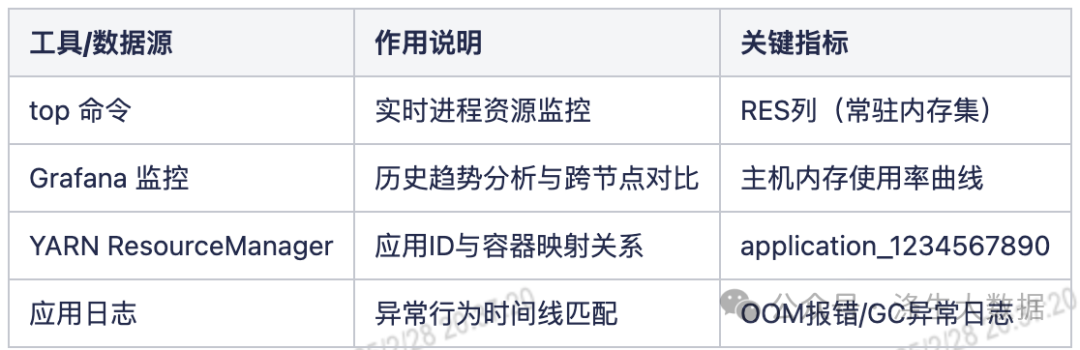
3.四步定位法實戰演示

步驟1:內存異常節點鎖定
通過Grafana篩選出滿足以下特征的節點:
-
內存使用率曲線呈階梯狀持續增長
-
當前內存使用率>85%但未完全宕機
-
出現時間集中在業務高峰時段
# 示例節點內存趨勢
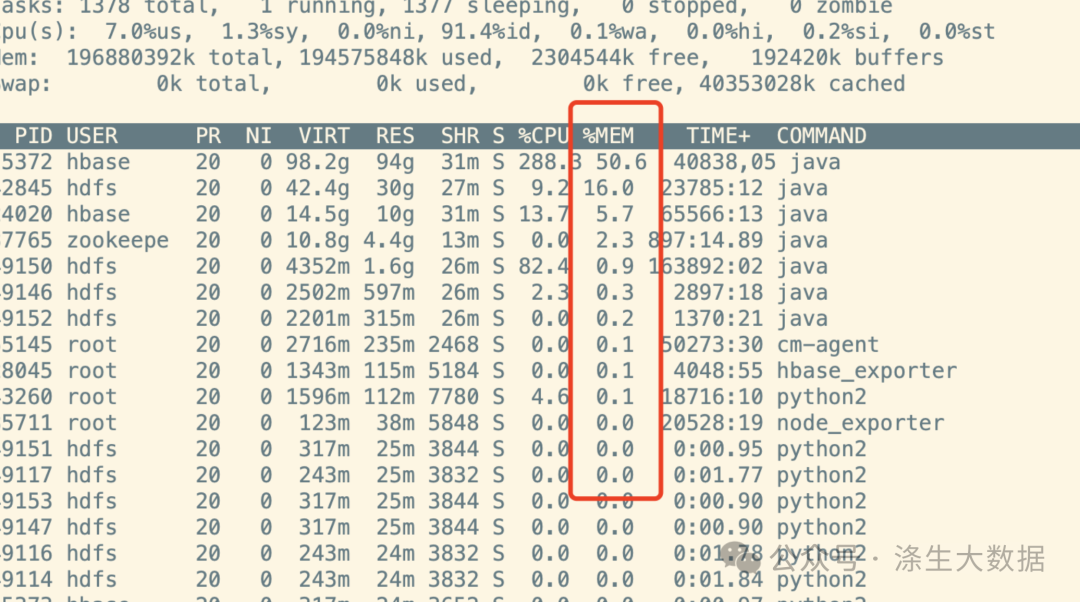
步驟2:內存占用雙重驗證
通過top命令與監控數據交叉驗證:
通過 grafana 監控選定主機查看內存使用率,此時會發現?top計算出來的內存使用會比監控采集的內存小很多,且監控中能發現,主機的內存在某個時間點之后持續攀升。注意點:當top顯示的RES總和遠小于實際內存消耗時,可能存在:
-
Buffer/Cache未被及時釋放
-
內存碎片化嚴重
-
內核級內存泄漏(需排查slabinfo)
步驟3:異常進程關聯應用ID
通過進程PID反向查找YARN應用:
再用 top 指令拿到本機內存使用很高的幾個 PID,通過 ps 獲取到PID 對應的application ID。
提示:多找幾臺機器重復上面的操作,選出幾臺機器同時共存的 application ID。
步驟4:時空關聯分析
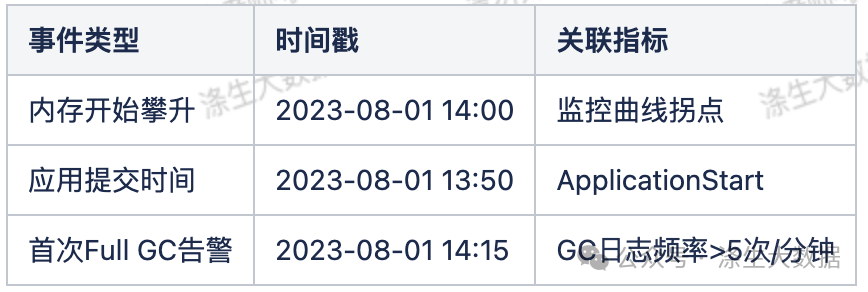
建立時間線對照表:
通過觀察上面步驟找出來的 appid,主要看這幾個 application 的運行日志是否異常、提交時間和機器內存異常攀升的時間點是否吻合。
4.典型內存泄漏模式識別
1. 堆外內存泄露特征
-
JVM堆內存穩定,但RES持續增長
-
Netty等NIO框架使用后未釋放DirectBuffer
-
出現?
java.lang.OutOfMemoryError: Direct buffer memory
2. 元空間泄露特征
-
Metaspace使用量超過-XX:MaxMetaspaceSize
-
頻繁動態生成類(如Groovy腳本引擎)
-
日志出現?
java.lang.OutOfMemoryError: Metaspace
3. 緩存失控增長
-
Guava Cache未設置過期策略
-
使用靜態Map做緩存且無淘汰機制
-
緩存命中率持續下降,堆內存直線上升
5.防御性編程實踐
1. 容器化部署約束

2. JVM參數加固

3. 監控體系增強
建議部署以下監控項:
-
每個容器的RES/VIRT內存使用量
-
JVM各內存池(Old/Young/Metaspace)占比
-
容器存活狀態心跳檢測
-
Full GC頻率與持續時間
6.總結與反思
通過本次排查我們得出以下經驗:
-
內存問題要早于OOM發生前介入,85%使用率即需預警
-
多維度數據交叉驗證(主機/容器/JVM三級監控)
-
優先在測試環境復現問題,避免生產環境直接操作
建議后續優化方向:
-
建立應用內存畫像基線,識別異常增長模式
-
在調度層添加內存使用率彈性約束
-
定期進行內存泄露專項測試(如JMeter壓力測試)

![[Xilinx]工具篇_PetaLinux自動編譯](http://pic.xiahunao.cn/[Xilinx]工具篇_PetaLinux自動編譯)



上課板書+課件匯總(動態內存管理)--數據結構常用)
![uv - Getting Started 開始使用 [官方文檔翻譯]](http://pic.xiahunao.cn/uv - Getting Started 開始使用 [官方文檔翻譯])





選擇結構和條件判斷)

)




