這次我們繼續解讀代碼,我們主要來看下面兩個部分;
至于人臉識別成功的要點我們在最后總結~
具體代碼學習:
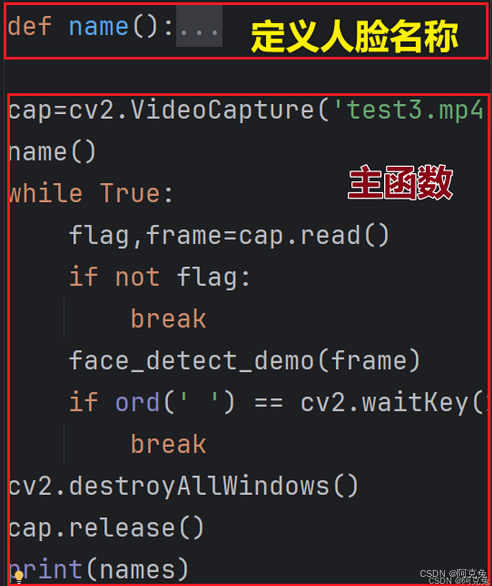
#定義人臉名稱
def name():#預學習照片存放位置path = 'M:/python/workspace/PythonProject/face/'imagePaths=[os.path.join(path,f) for f in os.listdir(path)]for imagePath in imagePaths:name = str(os.path.split(imagePath)[1].split('.',2)[1])names.append(name)(1)os.path.join()協調文件路徑中'/'?? '\'差異
???? 將多個路徑組件智能地拼接成一個完整的路徑。由于不同操作系統的差異,os.path.join() 可以根據當前操作系統自動處理這些差異。
補充:不同操作系統使用不同的路徑分隔符。
?????????? Windows 使用反斜杠 \,Unix/Linux 和 macOS 使用正斜杠 /
#舉例:
import os# 拼接路徑
path = os.path.join('home', 'user', 'documents')
print(path)- 在 Windows 系統上,輸出可能是
home\user\documents。 - 在 Unix/Linux 或 macOS 系統上,輸出為
home/user/documents。
(2)os.listdir()輸出某目錄下所有文件名

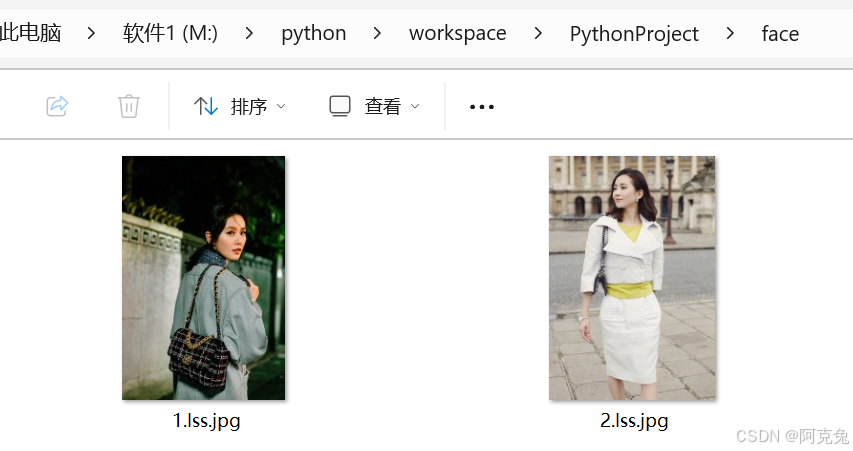
即os.listdir(path)獲得了['1.lss.jpg', '2.lss.jpg']
os.path.join()將路徑M:\python\workspace\PythonProject\face替換為
M:/python/workspace/PythonProject/face/1.lss.jpg
M:/python/workspace/PythonProject/face/2.lss.jpg
os.path.join(path, f)這里path是前面指定的目錄路徑,f是os.listdir(path)返回列表中的每個元素(即文件或文件夾名稱)。- 代碼比較長,我們來看一下這個循環的內容:

????? 這行代碼遍歷 os.listdir(path) 返回的列表,對每個文件名 調用 os.path.join(path, f) 進行路徑拼接,最終將所有拼接好的完整路徑組成一個新的列表。
??? 我們可以把整段代碼的閱讀順序做如下表達:

讓我們繼續解讀:
for imagePath in imagePaths:name = str(os.path.split(imagePath)[1].split('.',2)[1])names.append(name) for imagePath in imagePaths是在剛形成的imagePath列表里自己進行循環
(3)os.path.split()將一個文件路徑拆分為目錄部分和文件名部分。
- 通過上一個代碼我們獲取了imagePath=M:/python/workspace/PythonProject/face/1.lss.jpg
- os.path.split(imagePath)就是把M:/python/workspace/PythonProject/face/1.lss.jpg拆為:
- 文件目錄M:/python/workspace/PythonProject/face/
- 文件名1.lss.jpg
os.path.split(imagePath)[1]是從文件目錄和文件名中獲取第二個文件名,即1.lss.jpg
補充:這里的第二個元素是因為列表、元組和字符串的索引都是從 0 開始,即[0]代表首位,[1]代表第二個,以此類推。
(4)split() 將字符串按照指定的分隔符分割成多個子字符串,并返回一個包含這些子字符串的列表
str.split(sep=None, maxsplit=-1)
sep:可選參數,指定分隔符。如果不提供該參數,默認使用空白字符(空格、制表符、換行符等)作為分隔符。maxsplit:可選參數,指定最大分割次數。如果不提供該參數,表示不限制分割次數。
-
split('.', 2)的含義就是分隔符為 . 最多分隔2次。 -
對
'1.lss.jpg'調用split( )后,會得到列表['1', 'lss', 'jpg']。 -
split('.',2)[1]這里從文件名1.lss.jpg中取出第二個元素,即lss
整行代碼解讀為:

(5)append()在列表的末尾添加一個新元素
list.append(object)
list:表示要操作的列表對象。object:表示要添加到列表末尾的任意 Python 對象,比如字符串、整數、列表、元組等。

names.append(name)這里就是把開頭創建的names列表填進了內容name
解讀主函數:
內容我們都學過,就直接標注了
#打開視頻test3.mp4讀取每一幀
cap=cv2.VideoCapture('test3.mp4')
#調用自定義name函數
name()
while True:#讀取視頻里的幀flag,frame=cap.read()#如果沒有幀則中斷if not flag:break#調用自定義face_detect_demo函數,進行人臉識別和標注face_detect_demo(frame)if ord(' ') == cv2.waitKey(10):break?(5)全部代碼解讀為:
import cv2
#導入與操作系統交互 os 模塊
import os#創建一個 LBPH(局部二值模式直方圖)人臉識別器對象,用于訓練和識別人臉。
recogizer=cv2.face.LBPHFaceRecognizer_create()
#讀取訓練好的人臉識別模型yml文件
recogizer.read('M:/python/workspace/PythonProject/trainer/trainer.yml')
#初始化一個空列表names,用于存儲人臉對應的名稱。
names=[]
#初始化一個全局變量warningtime,用于記錄未知人臉出現的次數。
warningtime = 1#自定義人臉識別
def face_detect_demo(img):#彩圖轉化為灰圖gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#調用人臉識別分類器face_detector=cv2.CascadeClassifier('M:/python/pythoninstall/Lib/site-packages/cv2/data/haarcascade_frontalface_alt.xml')#灰圖中檢測人臉face=face_detector.detectMultiScale(gray)for x,y,w,h in face:#原彩圖中用紅色矩形框人臉cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)#人臉中心畫綠圓cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)#識別輸入人臉,獲取標簽ids,置信度confidenceids, confidence = recogizer.predict(gray[y:y + h, x:x + w])#如果置信度confidence>80if confidence > 80:#warningtime作為全局變量global warningtime#每次出現都+1warningtime += 1#控制臺輸出warningtime=,值為warningtimeprint('warningtime=',warningtime)#圖像上繪制文本,文本是unknown,位置是x向右偏移10個像素。y向上偏移10個像素,字體無襯線,字體大小0.75,綠色cv2.putText(img, 'unknown', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)else:#圖像上繪制文本,文本是names列表中的,其余同上#坐標移動規律:+ 號撒腿右下跑,- 號轉身左上飄cv2.putText(img,str(names[ids - 1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)#彈出窗口名為resultcv2.imshow('result',img)#定義人臉名稱
def name():#預學習照片存放位置path = 'M:/python/workspace/PythonProject/face/'#獲取path路徑下文件名,將文件名+路徑拼接完整路徑,將完整路徑存到imagePaths中imagePaths=[os.path.join(path,f) for f in os.listdir(path)]for imagePath in imagePaths:#獲取文件名中的一部分作為name,即name=lssname = str(os.path.split(imagePath)[1].split('.',2)[1])#將提取出的人臉名稱 name 添加到 names 列表中names.append(name)#打開視頻test3.mp4讀取每一幀
cap=cv2.VideoCapture('test3.mp4')
#調用自定義name函數
name()
while True:#讀取視頻里的幀flag,frame=cap.read()#如果沒有幀則中斷if not flag:break#調用自定義face_detect_demo函數,進行人臉識別和標注face_detect_demo(frame)if ord(' ') == cv2.waitKey(10):breakcv2.destroyAllWindows()
cap.release()
print(names)
(6)人臉識別成功的要點
?? 本次識別我們用兩張人像即實現了人臉識別,這有賴于LBPH分類器的局部特征特性,少量圖片即可識別。同時在素材選擇中刻意選擇了差異較大的人物,且目標人像的角度基本一致而檢測任務則為其他角度。如果想提升識別準確性目前我所了解的一個是提升訓練樣本量,更改分類器或者用其他方式進行識別。在實驗中我嘗試了用130多張圖用LBPH分類器,但訓練效果不佳。所以目前的成果對于材料的選擇有較高的要求。
(7)補充[]和()的區別
- 方括號
[]用于表示列表(list)。列表是一種可變的、有序的數據集合,列表支持元素的添加、刪除、修改等操作 - 方括號
[]用于索引和切片操作
my_list = [1, 'apple', True]my_list = [1, 2, 3, 4, 5]
# 索引操作,獲取第一個元素
first_element = my_list[0]# 切片操作,獲取第 2 到第 4 個元素
sub_list = my_list[1:4]
print(sub_list) # 輸出: [2, 3, 4]my_tuple = (1, 2, 3, 4, 5)
# 元組的索引操作
first_tuple_element = my_tuple[0]
print(first_tuple_element) # 輸出: 1squares = [i**2 for i in range(1, 6)]- 圓括號
()用于表示元組(tuple)。元組是一種不可變的、有序的數據集合,一旦創建就不能修改其元素 - 圓括號
()用于函數調用。調用函數時,需要使用圓括號將參數括起來。如果函數不需要參數,也需要使用空的圓括號。
my_tuple = (1, 'apple', True)def greet(name):def say_hi():綜上大部分情況都使用圓括號()
(8)總結
- os.path.join()協調文件路徑中/\差異
- os.listdir()輸出某目錄下所有文件名
- os.path.split()將一個文件路徑拆分為目錄部分和文件名部分
split()將字符串按照指定的分隔符分割成多個子字符串,并返回一個包含這些子字符串的列表append()在列表的末尾添加一個新元素





)



)
)






![java處理pgsql的text[]類型數據問題](http://pic.xiahunao.cn/java處理pgsql的text[]類型數據問題)
)
)