本文首發:AIWalker

https://arxiv.org/abs/2403.00522
https://github.com/Meituan-AutoML/VisionLLaMA
本文概述
大型語言模型構建在基于Transformer的架構之上來處理文本輸入, LLaMA 系列模型在眾多開源實現中脫穎而出。類似LLaMa的Transformer可以用來處理2D圖像嗎?在本文中,我們通過提出一種類似 LLaMA 的樸素和金字塔形式的Transformer來回答這個問題,稱為 VisionLLaMA。 VisionLLaMA 是一個統一的通用建模框架,用于解決大多數視覺任務。
我們采用經典的預訓練框架在圖像感知(尤其是圖像生成)任務上對齊有效性進行了充分評估。在大多數情況下,VisionLLaMA表現出了比已有SOTA ViT方案更優的性能。我們相信 VisionLLaMA 可以作為視覺生成和理解的強大新基線模型。

本文貢獻
- 提出一種類似于LLaMA的視覺轉換器架構VisionLLaMA,以減少語言和視覺之間的架構差異。
- 我們研究了兩個版式的視覺架構方案(樸素和金字塔),并評估它們在監督和自監督學習場景下的性能。此外,我們還引入了 AS2DRoPE(即自動縮放 2D RoPE),它將旋轉位置編碼從 1D 擴展到 2D,并利用插值縮放來適應任意分辨率。
- 在沒有花里胡哨的情況下,VisionLLaMA 在圖像生成、分類、語義分割和對象檢測等許多代表性任務中明顯優于廣泛使用且經過仔細微調的視覺轉換器。大量實驗表明,VisionLLaMA 比現有視覺轉換器具有更快的收斂速度和更好的性能。
本文方案

樸素版VisionLLaMA延續了ViT的處理流程,核心在于VisionLLaMA模塊,見上圖。VisionLLaMA與ViT不同之處在于:位置編碼自注意力RoPE和SwiGLU激活函數。此外,它仍然使用ViT的LayerNorm,而非RMSNorm。需要注意的是,由于1DRoPE不能很好的擴展到其他分辨率,故作者將其擴展為2維形式,描述如下:
z i j l = M H S A ( A S 2 D R o P E ( L a y e r N o r m ( z i j l ? 1 ) ) ) + z i j l ? 1 z_{ij}^{l} = MHSA(AS2DRoPE(LayerNorm(z_{ij}^{l-1}))) + z_{ij}^{l-1} zijl?=MHSA(AS2DRoPE(LayerNorm(zijl?1?)))+zijl?1?
z i j l = S w i G L U ( L a y e r N o r m ( z i j l ) ) + z i j l z_{ij}^{l} = SwiGLU(LayerNorm(z_{ij}^l)) + z_{ij}^{l} zijl?=SwiGLU(LayerNorm(zijl?))+zijl?
金字塔VisionLLaMA
更進一步,類似SwinT,作者還構建了一個金字塔版本的VisionLLaMA。在本文中,我們選擇更強的基線 Twins 來探索如何在嚴格控制的設置下構建強大的金字塔變壓器。 Twins 的原始架構利用了條件位置編碼和以局部和全局注意力的形式進行交錯的局部-全局信息交換。這些組件可以在各種變壓器中找到,這意味著按照我們的方法在其他金字塔變壓器變體中應用 VisionLLaMA 并不困難。請注意,我們的目標不是發明一種新穎的金字塔視覺轉換器,而是展示我們如何在現有設計的基礎上調整 VisionLLaMA 的基本設計。因此,我們只是遵循對架構和超參數進行最小的修改。
需要注意:我們刪除了金字塔 VisionLLaMA 中的條件位置編碼,因為 AS2DRoPE 已經包含位置信息。此外,我們還刪除了類標記并在分類頭之前使用 GAP(全局平均池)。
Training or Inference Beyond Sequence Length
處理不同的輸入分辨率是視覺任務中的常見要求。卷積神經網絡使用滑動窗口機制來處理可變長度。相反,大多數視覺轉換器應用局部窗口操作或插值。例如,DeiT在不同分辨率上訓練時采用雙三次插值。 CPVT使用基于卷積的位置編碼。
對于RoPE,作者嘗試將其從1D擴展至2D形式。給定 x i j ∈ R d x_{ij} \in R^d xij?∈Rd,其位置編碼為 x i j P E = R i j x i j x_{ij}^{PE} = R_{ij} x_{ij} xijPE?=Rij?xij?,對角矩陣如下:

本文實驗
圖像生成



圖像分類


語義分割


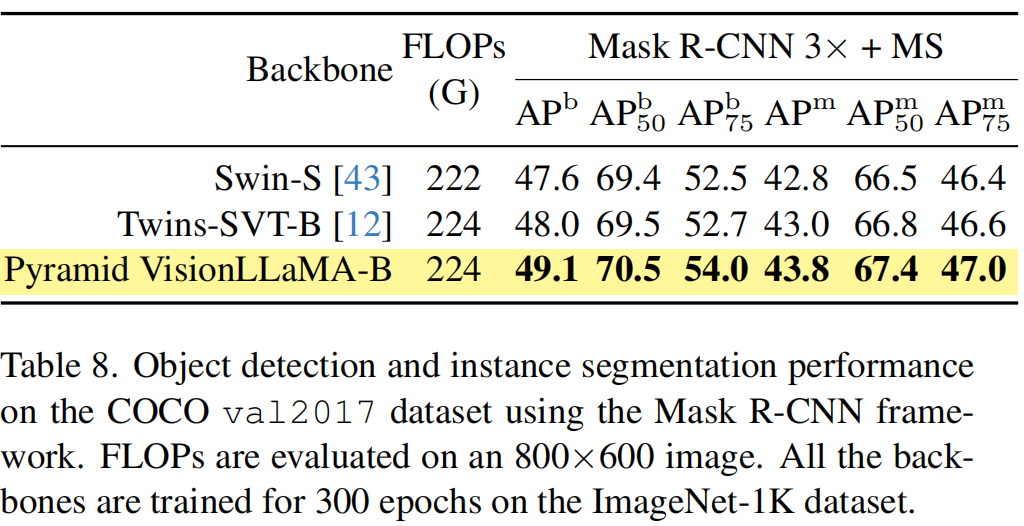
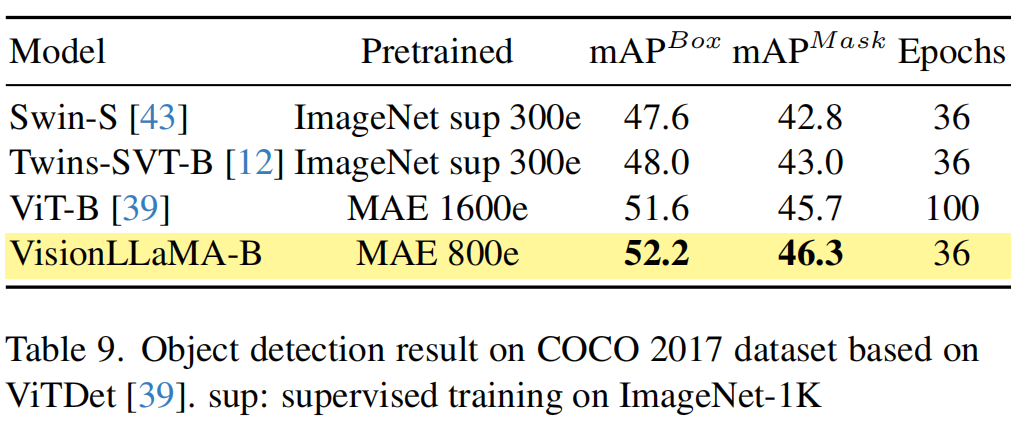
COCO檢測
推薦閱讀
- 入局CV,Mamba再顯神威!華科王興剛團隊首次將Mamba引入ViT,更高精度、更快速度、更低顯存!
- Swin版VMamba來了!精度再度提升,VMamba-S達成83.5%,超越Swin-S,已開源!
- CVPR2023 InternImage已開源 | 注入新機制,探索視覺大模型,達成COCO新紀錄65.4mAP!
- CVPR2022 | RepLKNet: 大核卷積+結構重參數讓CNN再次偉大
- DCNv4來襲,更快收斂、更高速度、更高性能!


)



)








)


)
