參考:
https://zhuanlan.zhihu.com/p/259591644
主要就是降低transformer自注意力模塊的復雜度
復雜度主要就是 Q · K^T影響的,稀疏注意力就是在Q點乘K的轉置這模塊做文章

下列式一些sparse transformer稀疏注意力方法
a、transformer原始的 , Q · K^T,其中 K^T 表示 K 的轉置
b、每個token與前后三個做自注意力計算
c、膨脹注意力(dilated attention):每個token與前后三個做自注意力計算,但這三個有間隔,就是比如第一個token看右面3,5,7
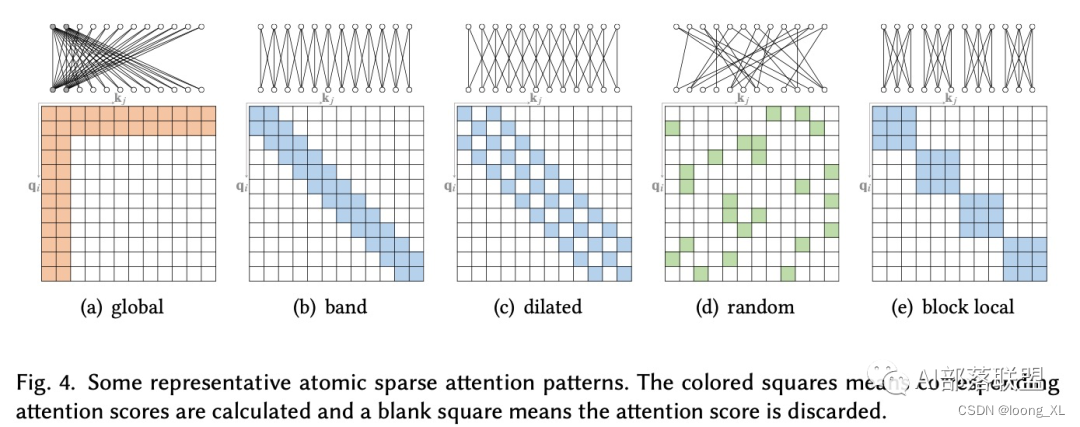
d、全局token是第一二個token看所有的token,3及后面的token只看· K^T 矩陣的1、2token;sliding劃窗見b
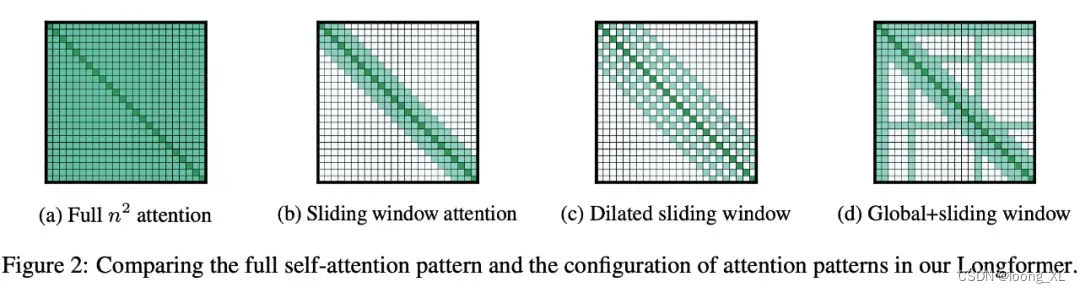
a、全局token是第一二個token看所有的token,3及后面的token只看· K^T 矩陣的1、2token
b、劃窗
c、見上面c
d、random
e、Q矩陣的123token 看 · K^T123token;Q矩陣的456token 看 · K^T456token 。。。。










)

安裝MATLAB(正版))
——鎖的升級,synchronized與lock鎖區別)

:課程導學)



)