文章目錄
- 前言
- 一、faster-whisper簡單介紹
- 二、pyannote.audio介紹
- 三、faster-whisper + pyannote.audio 實現語者識別
- 四、多說幾句
前言
最近在研究ASR相關的業務,也是調研了不少模型,踩了不少坑,ASR這塊,目前中文普通話效果最好的應該是阿里的modelscope上的中文模型了,英文的話,還是非whisper莫屬了,而且whisper很變態,粵語效果也還不錯,因此,如果實際業務中需要涉及到不同的語言,還是更推薦whisper多一點
一、faster-whisper簡單介紹
faster-whisper是使用CTranslate2對OpenAI的Whisper模型的重新實現,CTranslate2是一個用于Transformer模型的快速推理引擎。
在使用更少內存的情況下,該實現比openai/whisper在相同精度下快4倍。同時在CPU和GPU上進行8位量化,可以進一步提高算法效率。
官方倉庫:https://github.com/SYSTRAN/faster-whisper
二、pyannote.audio介紹
pyannote.audio是一個用Python編寫的用于揚聲器diarization的開源工具包。基于PyTorch機器學習框架,它具有最先進的預訓練模型和管道,可以進一步對自己的數據進行微調,以獲得更好的性能。
官方倉庫:https://github.com/pyannote/pyannote-audio
三、faster-whisper + pyannote.audio 實現語者識別
實際上只要將二者的識別結果進行結合即可
from pyannote.core import Segmentdef get_text_with_timestamp(transcribe_res):timestamp_texts = []for item in transcribe_res:start = item.startend = item.endtext = item.text.strip()timestamp_texts.append((Segment(start, end), text))return timestamp_textsdef add_speaker_info_to_text(timestamp_texts, ann):spk_text = []for seg, text in timestamp_texts:spk = ann.crop(seg).argmax()spk_text.append((seg, spk, text))return spk_textdef merge_cache(text_cache):sentence = ''.join([item[-1] for item in text_cache])spk = text_cache[0][1]start = round(text_cache[0][0].start, 1)end = round(text_cache[-1][0].end, 1)return Segment(start, end), spk, sentencePUNC_SENT_END = [',', '.', '?', '!', ",", "。", "?", "!"]def merge_sentence(spk_text):merged_spk_text = []pre_spk = Nonetext_cache = []for seg, spk, text in spk_text:if spk != pre_spk and pre_spk is not None and len(text_cache) > 0:merged_spk_text.append(merge_cache(text_cache))text_cache = [(seg, spk, text)]pre_spk = spkelif text and len(text) > 0 and text[-1] in PUNC_SENT_END:text_cache.append((seg, spk, text))merged_spk_text.append(merge_cache(text_cache))text_cache = []pre_spk = spkelse:text_cache.append((seg, spk, text))pre_spk = spkif len(text_cache) > 0:merged_spk_text.append(merge_cache(text_cache))return merged_spk_textdef diarize_text(transcribe_res, diarization_result):timestamp_texts = get_text_with_timestamp(transcribe_res)spk_text = add_speaker_info_to_text(timestamp_texts, diarization_result)res_processed = merge_sentence(spk_text)return res_processeddef write_to_txt(spk_sent, file):with open(file, 'w') as fp:for seg, spk, sentence in spk_sent:line = f'{seg.start:.2f} {seg.end:.2f} {spk} {sentence}\n'fp.write(line)import torch
import whisper
import numpy as np
from pydub import AudioSegment
from loguru import logger
from faster_whisper import WhisperModel
from pyannote.audio import Pipeline
from pyannote.audio import Audiofrom common.error import ErrorCodemodel_path = config["asr"]["faster-whisper-large-v3"]# 測試音頻: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_speaker_demo.wav
audio = "./test/asr/data/asr_speaker_demo.wav"
asr_model = WhisperModel(model_path, device="cuda", compute_type="float16")
spk_rec_pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token="your huggingface token")
spk_rec_pipeline.to(torch.device("cuda"))asr_result, info = asr_model.transcribe(audio, language="zh", beam_size=5)
diarization_result = spk_rec_pipeline(audio)final_result = diarize_text(asr_result, diarization_result)
for segment, spk, sent in final_result:print("[%.2fs -> %.2fs] %s %s" % (segment.start, segment.end, sent, spk))結果
[0.00s -> 9.80s] 非常高興能夠和幾位的話一起來討論互聯網企業如何決勝全球化新高地這個話題 SPEAKER_01
[9.80s -> 20.20s] 然后第二塊其實是游戲平臺所謂游戲平臺它主要是簡單來說就是一個商店家社區的這樣一個模式而這么多年 SPEAKER_03
[20.20s -> 35.70s] 我們隨著整個業務的拓張會發現跟阿里云有非常緊密的聯系因為剛開始偉光在介紹的時候也講阿里云也是阿里巴巴的云所以這個過程中一會兒也可以稍微展開跟大家講一下我們跟云是怎么一路走來的 SPEAKER_04
[35.70s -> 62.40s] 其實的確的話就對我們互聯網公司來說如果不能夠問當地的人口的話我想我們可能整個的就失去了后邊所有的動力不知道你們各位怎么看就是我們最大的這個問題是不是效率優先Yes or No然后如果是講一個最關鍵的你們是怎么來克服這一些挑戰的 SPEAKER_01
[62.40s -> 90.50s] 因為其實我們最近一直在做海外業務所以說我們碰到了一些問題可以一起分享出來給大家其實一起探討一下其實海外我們還是這個觀點說是無論你準備工作做得有多充分無論你有學習能力有多強你一個中國企業的負責人其實在出海的時候它整體還是一個強勢的是做的過程 SPEAKER_03
[90.50s -> 101.60s] 后來推到德國或者推到新加坡 印尼 越南等等這些地方每一個地方走過去都面臨的一個問題是建站的效率怎么樣能夠快速地把這個站點建起來 SPEAKER_04
[101.60s -> 122.90s] 一方面我們當初剛好從2014年剛好開始要出去的時候國內就是三個北上廣深但在海外要同時開服北美 美東 美西 歐洲 日本我還記得那個時候我們在海外如何去建立這種IDC的康碳建設基礎設施建設云服務的部署那都是一個全新的挑戰 SPEAKER_02
四、多說幾句
pyannote的模型都是從huggingface上下載下來的,所以沒有magic直接運行上面代碼可能會報443,自己想辦法搞定網絡問題。
地址:https://huggingface.co/pyannote/speaker-diarization-3.1
以上代碼即使你運行的時候把模型下載到緩存里了,偶爾還是會443,筆者猜測這玩意就算你下載下來了還是還是要聯網推理,所以,要部署到生產環境的同學最好還是使用離線加載。
pyannote離線加載模型的方式和之前NLP的模型不一樣,首先你需要配置的是config.yaml的路徑,請看:
spk_rec_pipeline = Pipeline.from_pretrained("./data/models/speaker-diarization-3.1/config.yaml")
只下載這一個模型是不行的哦,這個只是個config文件,你還要下載另外兩個模型:
https://huggingface.co/pyannote/wespeaker-voxceleb-resnet34-LM
https://huggingface.co/pyannote/segmentation-3.0
最后再修改下config.yaml里的模型路徑,參考我的:
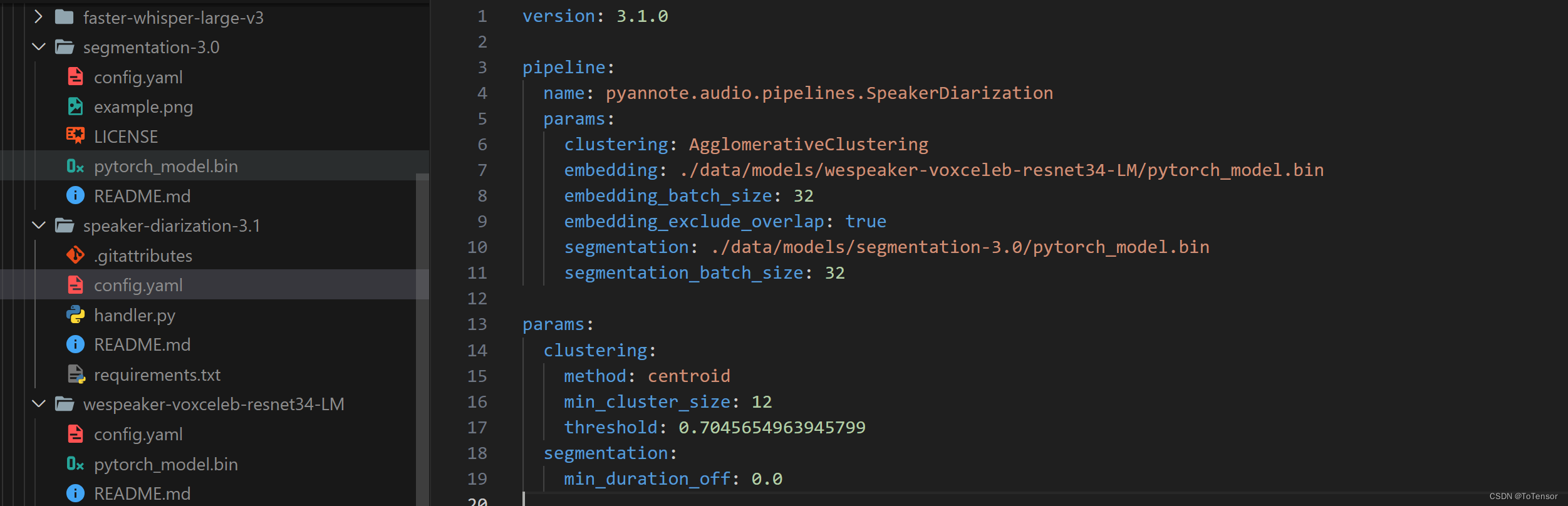
當這些都搞好后,你是不是以為完了?
正常來說應該不會有什么問題,但是我在服務器上碰到了如下問題:

而且官方也有相關的issue:https://github.com/pyannote/pyannote-audio/issues/1599
我試了,在我服務器上是沒用的
有些人說是onnx模型有問題,比如說模型下載出了問題,我重新下載了好幾遍,都無法解決,所以如果真的是模型的問題,那應該就是pyannote官方push的模型有問題。還有說是Protobuf的問題的,我認為應該不是,最后我也沒找出問題在哪,所以最后我不用pyannote了
但神奇的是,用Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token="your huggingface token")直接從緩存里加載模型就沒問題,只是偶爾報443。
最后,祝大家好運。pyannote不行,完全可以用其他模型替代的,筆者推薦去modelscope上看看。
2024/03/04更新
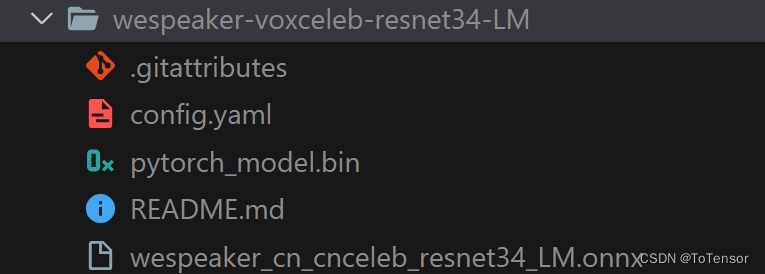
離線加載的Protobuf問題已找到原因:確實是官方提供的模型有問題,官方倉庫提供的是pytorch模型,非onnx模型,從報錯也可以看的出來,我找了半天也沒找到onnx模型在哪里,應該可以自己從pytorch模型轉到onnx模型,還有個辦法是大家可以從https://modelscope.cn/models/manyeyes/speaker_recognition_task_models_onnx_collection/files下載,下載wespeaker開頭的onnx模型就可以了,然后放到wespeaker-voxceleb-resnet34-LM目錄下,如圖:
然后再修改speaker-diarization-3.1下的config.yaml文件:
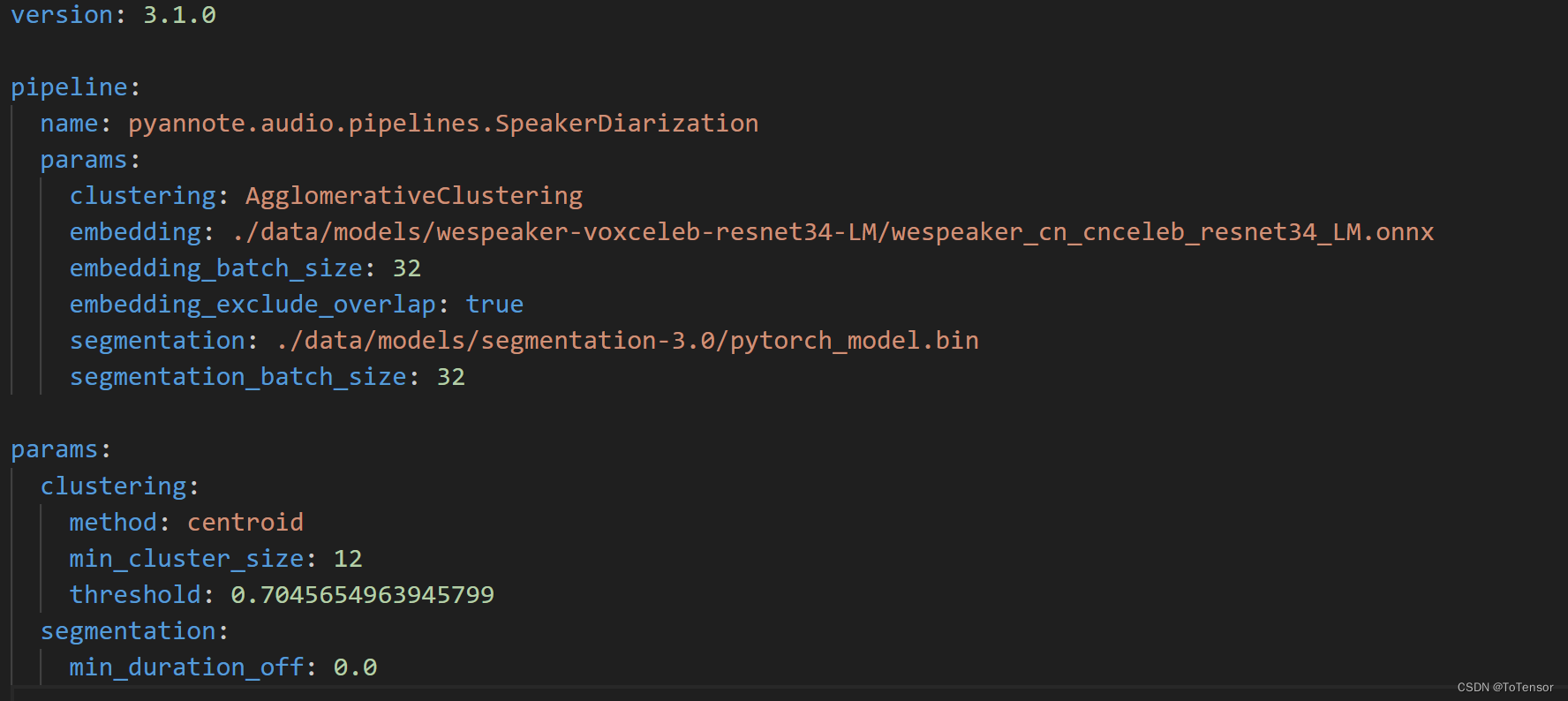
至此,大功告成啦!這都不點贊收藏實在沒良心!!!
另外,實際上我發現用whisperx來實現,更方便,但推理速度慢一點。
:課程導學)



)





![OSError: [WinError 1455] 頁面文件太小,無法完成操作。](http://pic.xiahunao.cn/OSError: [WinError 1455] 頁面文件太小,無法完成操作。)








