淘汰策略
- 只有 redis 內存空間已滿并且往里面寫新數據,才會觸發淘汰策略。
- 通過 expire / / /pexpire 讓 key-value 過期,從而讓 redis 清除這個 key-value。
- value 的數據結構
typedef struct redisObject {unsigned tpye:4;unsigned encoding:4;// 判斷哪些 key 要被刪除unsigned lru:LRU_BITS; // 占用 24位,8位用來記錄訪問的次數(0-255次),16位用來記錄上一次訪問的時間int refcount; // 引用計數void *ptr; // 指向 value 的存儲空間 } robj;object idletime key # 展示 value 的 lru 字段 - 配置淘汰策略
- 如果 redis 內存空間已滿,并且沒有設置淘汰策略,再 set key value 會直接返回錯誤,提示內存空間已滿;如果設置了淘汰策略,redis 會按照淘汰策略選擇數據進行刪除,再 set key value 就會成功。
# redis.conf maxmemory <bytes> # redis 最多可以使用多少空間 maxmemory-policy # 淘汰策略,默認為 noeviction, 不進行淘汰 maxmemory-samples # 默認為 5,選擇多少個 key 進行淘汰 - 過期 key 中
- volatile-lru:最長時間沒有使用。
- volatile-lfu:最少次數使用,隨機采樣。
- volatile-ttl:最近要過期。
- volatile-random:隨機。
- 所有 key
- allkeys-lru。
- allkeys-lfu 。
- allkeys-random 。
- 禁止淘汰:no-eviction。
- 如果 redis 內存空間已滿,并且沒有設置淘汰策略,再 set key value 會直接返回錯誤,提示內存空間已滿;如果設置了淘汰策略,redis 會按照淘汰策略選擇數據進行刪除,再 set key value 就會成功。
持久化
- redis 為什么需要持久化 ?
- 因為 redis 是內存數據庫,一旦關閉,內存中的數據就丟失了,所以需要把內存中的數據寫到磁盤中,這樣 redis 重啟后就可以從磁盤中加載原來的數據到內存中。
- 只有寫操作(增刪改操作,會引起數據庫變更的操作)才會進行持久化。
- redis 持久化方式
- aof
- 持久化的是寫操作協議內容(通過重放恢復內存中的數據),會有很多冗余數據;在 redis 進程中完成,every_sec 會另啟線程做持久化。
*3 $3 set $4 mark $1 2 - 策略
- no:關閉 aof。
- always:先將數據持久化到磁盤,再響應客戶端。(效率很低,一般不采用)
- every_sec:只要內存修改成功,立刻響應客戶端。
- 先將數據寫到 aof buffer 中,一秒后將 aof buffer 中的數據持久化到磁盤,這個過程是異步的,使用 bio_fsync_aof。
- always 和 every_sec 會調用
fsync(fd)將 page cache 中的數據立刻持久化到磁盤。
- aof-rewrite
- 因為 aof 文件過大,數據恢復速度太慢,所以要減少 aof 文件大小。
- 工作原理
- fork 進程,根據內存數據生成 aof 文件,避免同一個 key 的歷史冗余數據。
- 在重寫 aof 期間,對 redis 的寫操作會被記錄到重寫緩沖區,在重寫 aof 結束后,再將這些寫操作附加到 aof 文件末尾(可能有冗余數據)。
- 持久化的是寫操作協議內容(通過重放恢復內存中的數據),會有很多冗余數據;在 redis 進程中完成,every_sec 會另啟線程做持久化。
- rdb
- 持久化的是二進制數據(根據磁盤中的二進制數據恢復內存中的數據);另啟進程做持久化。
- 工作原理:通過 fork 子進程進行持久化,基于內存中對象編碼直接持久化。
- fork 相當于給父進程的內存做了一個快照。
- fork 寫時復制

- 頁表存儲了虛擬內存和物理內存之間的映射關系。
- linux 為了加快 fork 的流程,fork 僅僅會復制頁表,然后將兩個頁表中的所有保護位修改為只讀,此時父進程和子進程共用一塊物理內存;父進程依然對外提供服務。
- 當父進程處理寫操作時,首先會找到虛擬內存的內存頁,然后通過頁表寫物理內存頁的時候,發現保護位是只讀的,此時會觸發寫保護中斷:在物理內存中完成一次物理頁復制(把原來的物理頁復制一份),然后把數據寫入到復制后物理頁中,最后在寫保護中斷的處理函數中將頁表中的保護位修改為可讀可寫,并且重新構建頁表中的映射關系(頁表中該虛擬內存的指向變為新的物理頁)。
- rdb-aof 混用
- 通過 fork 子進程,根據內存數據生成 rdb 文件。
- 在 rdb 持久化期間,對 redis 的寫操作會被記錄到重寫緩沖區,在 rdb 持久化結束后,采用 aof 的方式附加到文件末尾。
- aof
- redis 持久化方式優缺點
- aof
- 優點:數據可靠,丟失較少;持久化過程代價較低(是順序磁盤 IO,持久化速度快)。
- 缺點:aof 文件過大,數據恢復慢(通過重放恢復內存中的數據)。
- rdb
- 優點:rdb 文件小,數據恢復快。
- 缺點:數據丟失較多;持久化過程代價較高。
- aof
- 大 key 問題:kv 中,value 如果占用大量空間就是大 key,比如 value 是 hash、zset,里面存儲大量元素。
- fsync 壓力大。
- 因為頁表大,所以 fork 時間長,寫時復制造成持久化時間長。
高可用
- 為什么實際業務中有高可用的需求 ?
- 比如服務器依賴 redis,如果 redis 宕機了,那么服務器就不能給客戶端響應了,此時整個服務器處于不可用狀態。
- redis 高可用:如果 redis 中的一個節點宕機了,會有備用節點頂替它,服務器不會因為 redis 中的一個節點宕機了,造成服務不可用。
- 什么是高可用 ?
- 在合理的時間內給出合理的回復。
- 合理的時間:秒級的。
- 合理的回復:給一個請求,如果發生錯誤,需要回復是到底是什么錯誤,不能模棱兩可。
- 在合理的時間內給出合理的回復。
- 如何實現高可用 ?
- 數據備份。
- 節點切換策略。
主從復制
- 主從復制不能保證高可用,只起到了數據備份的作用。
- 含義
- 主從復制是異步復制,服務器寫數據到主數據庫(master),主數據庫立刻返回;從數據庫(replica)不斷地從主數據庫中拉取數據并保存,以達到從數據庫和主數據庫數據一致。
- replica 主動向 master 建立連接(否則無法線上新增 replica)
- replica 主動向 master 拉取數據(若網絡出現問題,replica 持有同步位置:復制偏移量)
- 缺點:可能帶來數據不一致:某一時刻如果從 replica 中獲取數據,數據可能不是最新的。
- 實現

- master 記錄了一個環形緩沖區和一個復制偏移量,replica 記錄了一個復制偏移量。
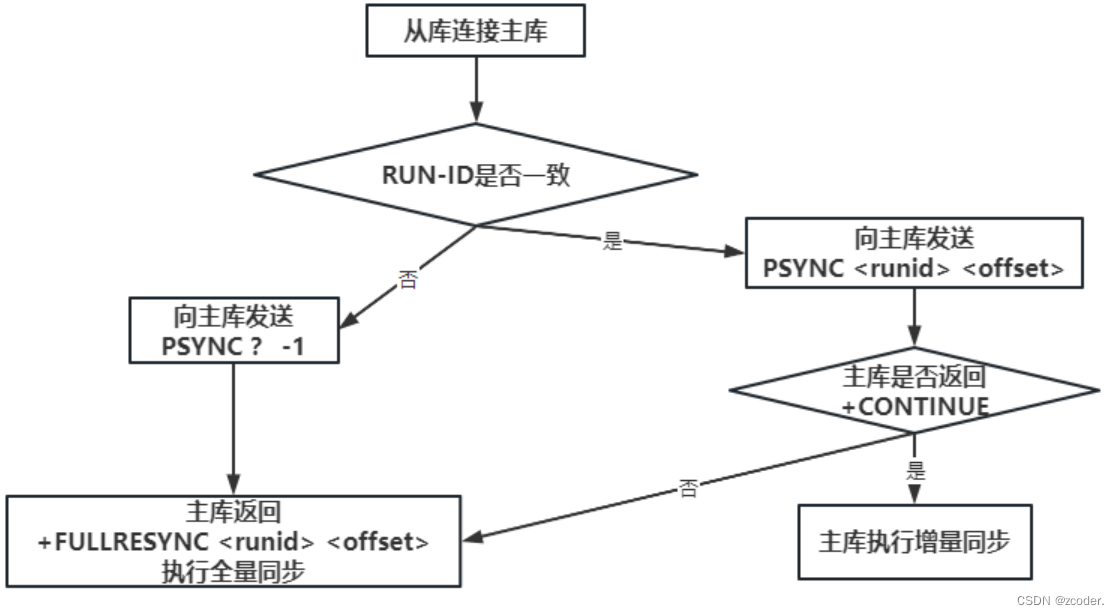
- RUN ID:
- 無論 master 還是 replica 都有自己的 RUN ID,RUN ID 在其啟動時自動產生,由 40 個隨機的十六進制字符組成。
- 當 replica 對 master 初次復制時,master 將自身的 RUN ID 發送給 replica,replica 會將 RUN ID 保存;當 replica 斷線重連 master 時,replica 將向 master 發送之前保存的 RUN ID。
- 如果 replica RUN ID 和 master RUN ID 一致,說明 replica 斷線前復制的就是當前的 master,master 嘗試執行增量更新。若不一致,說明 replica 斷線前復制的 master 并不是當前的 master,則 master 將對 replica 執行全量更新。
- 復制偏移量 offset(64 位的整數且一直累加):
- master 和 offset 都會維護一個復制偏移量;master 向 replica 發送 N 個字節的數據時,將自己的復制偏移量加上 N,replica 接收到 master 發送的 N 個字節的數據時,將自己的復制偏移量加上 N。
- 如果 replica 記錄的復制偏移量在環形緩沖區中,就將 master 中的數據偏移和 replica 的數據偏移之間的數據發給 replica(增量更新)。
- 如果 replica 記錄的復制偏移量不在環形緩沖區中,就把 master 中的 rdb 數據發給 replica(全量更新)。
- 通過比較主從偏移量得知主從之間數據是否一致;偏移量相同則數據一致,偏移量不同則數據不一致。
復制偏移量越大,數據越新。
哨兵模式

- 哨兵模式是 redis 高可用的解決方案:
- 由一個或多個 sentinel 實例構成 sentinel 集群,該集群可以監視任意多個主庫以及這些主庫所屬的從庫;當主庫處于下線狀態,會自動將該主庫所屬的某個數據最新的從庫升級為新的主庫。
- 客戶端連接集群時,首先會連接 sentinel(任意一個 sentinel),通過 sentinel 來查詢主庫的地址(ip 地址 + 端口),并且通過 subscribe 監聽主庫切換,然后再連接主庫進行數據交互。
- 當主庫發生故障時,sentinel 會主動推送新的主庫地址。這樣客戶端無須重啟即可自動完成節點切換。
- 檢測異常
- 主觀下線:sentinel 會以每秒一次的頻率向所有節點(其他 sentinel、主節點、從節點)發送 ping 消息,然后通過接收返回判斷該節點是否下線;如果配置指定了 down-after-milliseconds,則在該時間內沒有返回就被判斷為主觀下線。
- 客觀下線:當一個 sentinel 節點將一個主節點判斷為主觀下線之后,為了確
認這個主節點是否真的下線,它會向其他 sentinel 節點進行詢問,如果收到一定數量(半數以上)的已下線回復,sentinel 會將主節點判定為客觀下線,并通過領頭 sentinel 節點對主節點執行故障轉移。 - 故障轉移:
- 在從節點中選舉一個節點作為新的主節點(選復制偏移量最大的從節點)。
- 通知其他從節點復制連接新的主節點。
- 若故障主節點重新連接,將作為新的主節點的從節點。
- 缺點:
- 延遲較大:redis 采用異步復制的方式,意味著當主節點掛掉時,從節點可能沒有收到全部的同步消息,這部分未同步的消息將會丟失。如果主從延遲特別大,那么丟失可能會特別多。
- 不能進行數據擴容。
- 部署麻煩。
- 配置
# sentinel.cnf # sentinel 只需指定檢測主節點就行了,通過主節點自動發現從節點 sentinel monitor mymaster 127.0.0.1 6379 2 # 判斷主觀下線時長 sentinel down-after-milliseconds mymaster 30000 # 指定可以有多少個 redis 服務同步新的主機,一般而言,這個數字越小同步時間越長; 越大,則對網絡資源要求越高 sentinel parallel-syncs mymaster 1 # 指定故障切換允許的毫秒數,超過這個時間,就認為故障切換失敗,默認為 3分鐘 sentinel failover-timeout mymaster 180000
cluster 集群

- 實現高可用
- 數據備份:每個主節點都會有多個從節點。
- 主節點轉移:集群節點間會互相發送消息,交換節點的狀態信息;若某主節點下線,將會被其它節點標記下線,接著在該下線主節點的從節點中選擇一個數據最新的從節點作為主節點;從節點繼承下線主節點的槽位信息,并廣播改消息給集群中的其它節點。
- 特征:
- 去中心化:沒有中心節點。
- 主節點對等。
- 能夠進行數據擴容。
- 讀寫數據只會通過主節點進入集群。
- 流程:
- 連接集群中任意一個節點。
- 若數據不在該節點,將收到連接切換的命令,繼而連接到目標節點。
- 缺點:因為主從采用異步復制,在主節點轉移時仍存在數據丟失的情況。
- 配置集群

# 創建 6 個文件夾
mkdir -p 7001 7002 7003 7004 7005 7006
cd 7001
vi 7001.conf# 7001.conf 中的內容如下
pidfile "/home/zcoder/redis-cluster/7001/7001.pid"
logfile "/home/zcoder/redis-cluster/7001/7001.log"
dir /home/zcoder/redis-cluster/7001/
port 7001
daemonize yes
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000# 復制配置
cp 7001/7001.conf 7002/7002.conf
cp 7001/7001.conf 7003/7003.conf
cp 7001/7001.conf 7004/7004.conf
cp 7001/7001.conf 7005/7005.conf
cp 7001/7001.conf 7006/7006.conf# 查看目錄結構
tree .# 修改配置
sed -i 's/7001/7002/g' 7002/7002.conf
sed -i 's/7001/7003/g' 7003/7003.conf
sed -i 's/7001/7004/g' 7004/7004.conf
sed -i 's/7001/7005/g' 7005/7005.conf
sed -i 's/7001/7006/g' 7006/7006.conf
#!/bin/bash
# 創建啟動配置 start.sh
redis-server 7001/7001.conf
redis-server 7002/7002.conf
redis-server 7003/7003.conf
redis-server 7004/7004.conf
redis-server 7005/7005.conf
redis-server 7006/7006.conf
# 增加可執行權限
chmod +x start.sh # 啟動全部 redis 節點
./start.sh
# 查看 redis 節點是否全部啟動
ps aux | grep redis-server# 智能創建 redis 集群
# --cluster-replicas: 一個主節點對應幾個從節點
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
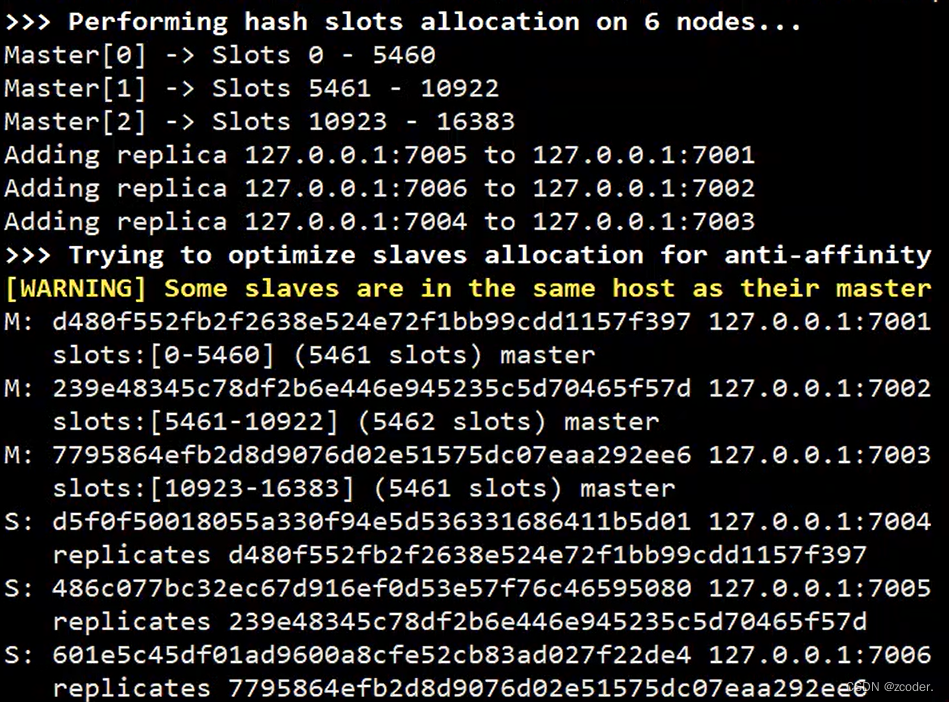
# 讀寫數據只會通過主節點進入集群
# 進入指定的 redis 節點
redis-cli -c -p 7006 # 127.0.0.1:7006
set zcoder 1 # 會重定向到存儲該數據的主節點
# 主節點宕機
redis-cli -p 7001 shutdown
# 主節點重啟
redis-server 7001/7001.conf
- 使用 crc16(zcoder) % 16384,通過增大樣本數,讓各個主節點存儲的數據量較為均衡。

- 擴容:先增加節點,再分配槽位。
cp -R 7001 7007 cd 7007 mv 7001.conf 7007.conf rm 7001.log dump.rdb nodes-7001.conf sed -i "s/7001/7007/g" 7007.conf cp -R 7007 7008 cd 7008 mv 7007.conf 7008.conf sed -i "s/7007/7008/g" 7008.conf cd .. redis-server 7007/7007.conf redis-server 7008/7008.conf # 7007 是主節點,7008 是從節點 redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id 主節點的id# 將槽位重新分配到整個集群的所有節點中 redis-cli --cluster reshard 127.0.0.1:7001 How many slots do you want to move (from 1 to 16384)? #1000 What is the receiving node ID? # 主節點的id Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node # all# 將節點 A 的槽位遷移到節點 B redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 節點A的id --cluster-to 節點B的id --cluster-slots 1000 - 縮容:先移動槽位,再刪除節點
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 節點B的id --cluster-to 節點A的id --cluster-slots 1000 # 刪除節點 7007 redis-cli --cluster del-node 127.0.0.1:7001 節點7007的id # 此時 7008 成為其他節點的從節點 redis-cli --cluster del-node 127.0.0.1:7001 節點7008的id

![Linux基礎命令[10]-cmp](http://pic.xiahunao.cn/Linux基礎命令[10]-cmp)






 題解 Kruscal重構樹 ST表)

(下))




)



