1 大模型知識更新的困境
- 大模型的知識更新是很困難的,主要原因在于:
- 訓練數據集固定,一旦訓練完成就很難再通過繼續訓練來更新其知識
- 參數量巨大,隨時進行fine-tuning需要消耗大量的資源,并且需要相當長的時間
- LLM的知識是編碼在數百億個參數中的,無法直接查詢或編輯其中的知識圖譜
- ——>LLM的知識具有靜態、封閉和有限的特點。
- ——>為了賦予LLM持續學習和獲取新知識的能力,RAG應運而生
2 RAG介紹
- 將大規模語言模型(LLM)與來自外部知識源的檢索相結合,以改進大模型的問答能力
- 核心手段是利用外掛于LLM的知識數據庫(通常使用向量數據庫)存儲未在訓練數據集中出現的新數據、領域數據等
2.1 RAG 三階段
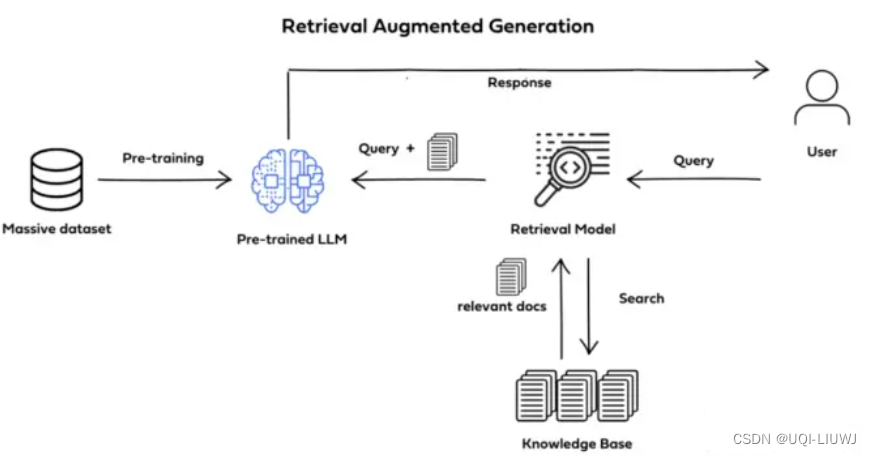
- RAG將知識問答分成三個階段:
- 索引
- 事先將文本數據進行處理,通過詞嵌入等向量化技術,將文本映射到低維向量空間,并將向量存儲到數據庫中,構建起可檢索的向量索引
- 知識檢索
- 當輸入一個問題時,RAG會對知識庫進行檢索,找到與問題最相關的一批文檔
- 生成答案
- RAG會把輸入問題及相應的檢索結果文檔一起提供給LLM,讓LLM充分把這些外部知識融入上下文,并生成相應的答案。
- RAG控制生成長度,避免生成無關內容
- 索引
3 RAG特點
3.1 優點
- 可以利用大規模外部知識改進LLM的推理能力和事實性
- 第一階段的知識索引可以隨時新增數據,延遲非常低,可以忽略不計。
- 因此RAG架構理論上能做到知識的實時更新
- 可解釋性強,RAG可以通過提示工程等技術,使得LLM生成的答案具有更強的可解釋性,從而提高了用戶對于答案的信任度和滿意度
3.2 缺點
- 知識檢索階段(第二階段)依賴相似度檢索技術,并不是精確檢索,因此有可能出現檢索到的文檔與問題不太相關
- 在第三階段生產答案時,由于LLM基于檢索出來的知識進行總結,從而導致無法應對用戶詢問知識庫之外的問題
- 外部知識庫的更新和同步,需要投入大量的人力、物力和時間
- 需要額外的檢索組件,增加了架構的復雜度和維護成本
4 RAG可以解決的問題
- 模型幻覺問題
- LLM文本生成的底層原理是基于概率進行生成的,在沒有已知事實作為支撐的情況下,不可避免的會出現一本正經的胡說八道的情況
- 時效性問題
- 具有一定時效性的數據就可能無法及時參與 訓練,造成模型無法直接回答與時效性相關的問題
- 數據安全問題
- 開源的LLM是沒有企業內部數據和用戶數據的,如果企業想在保證數據安全的前提下使用LLM,一種比較好的解決辦法就是把數據放在本地
- 企業數據的業務計算全部放在本地完成,在線的LLM只是完成一個歸納總結的作用
參考內容:RAG從入門到精通-RAG簡介 – Ace Consider
大模型LLM的主流應用RAG技術 - 知乎 (zhihu.com)


 GPIO(2)輸出)



)
)







:坤坤的籃球回避秀)


)
