3. 驗證方式
3.1什么是過擬合?產生過擬合原因?
定義:指模型在訓練集上的效果很好,在測試集上的預測效果很差
- 數據有噪聲
- 訓練數據不足,有限的訓練數據
- 訓練模型過度導致模型非常復雜
3.2 如何避免過擬合問題?
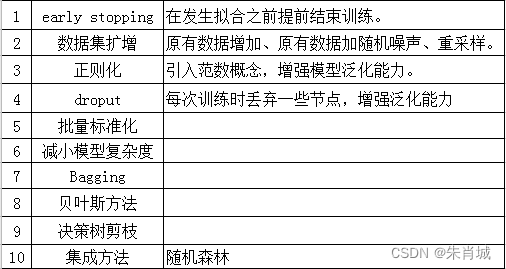
3.3 什么是機器學習的欠擬合?產生原因?解決辦法?
模型復雜度低或者數據集太小,對模型數據的擬合程度不高,因此模型在訓練集上的效果就不好。
- 模型復雜度不足:模型的復雜度不足以擬合數據的真實分布。例如,線性模型無法捕捉到非線性關系。
- 特征選擇不當:選擇的特征無法很好地描述數據的特性。例如,某些重要特征被忽略或特征提取不充分。
- 訓練數據量不足:訓練數據量過小,無法涵蓋數據的全貌,導致模型無法充分學習
3.4 如何避免欠擬合問題?
- 增加樣本的數量:增加訓練數據的數量,使模型能夠更充分地學習數據的規律。可以通過數據增強、采集更多的數據或合成數據等方法來增加訓練數據。
- 增加樣本特征的個數:選擇更多的特征,以更好地描述數據的特性。可以通過特征工程或特征選擇方法來獲取更多的特征。
- 增加模型復雜度:增加模型的復雜度,使其能夠更好地擬合數據的真實分布。例如,使用高階多項式模型或非線性模型。
- 可以進行特征維度擴展
- 減少正則化參數
- 使用集成學習方法,如Bagging








)






——基礎指令篇)



