本筆記資料來源于 http://www.ai-start.com/ml2014/,該筆記來自于https://blog.csdn.net/dadapongi6/article/details/105668394,看了忘,忘了看,再看一遍。
時間統計:2024.2.29 5個番茄鐘,從week1開始,看完了week5反向傳播算法。
week1
特征縮放是什么?
week3
http://www.ai-start.com/ml2014/html/week3.html
線性回歸和邏輯回歸是同一個算法嗎?
線性回歸是回歸任務;
邏輯回歸是logistic regression是2分類,是一個分類任務。在線性回歸后又加了一個sigmoid函數,把線性回歸的值映射到0-1之間。
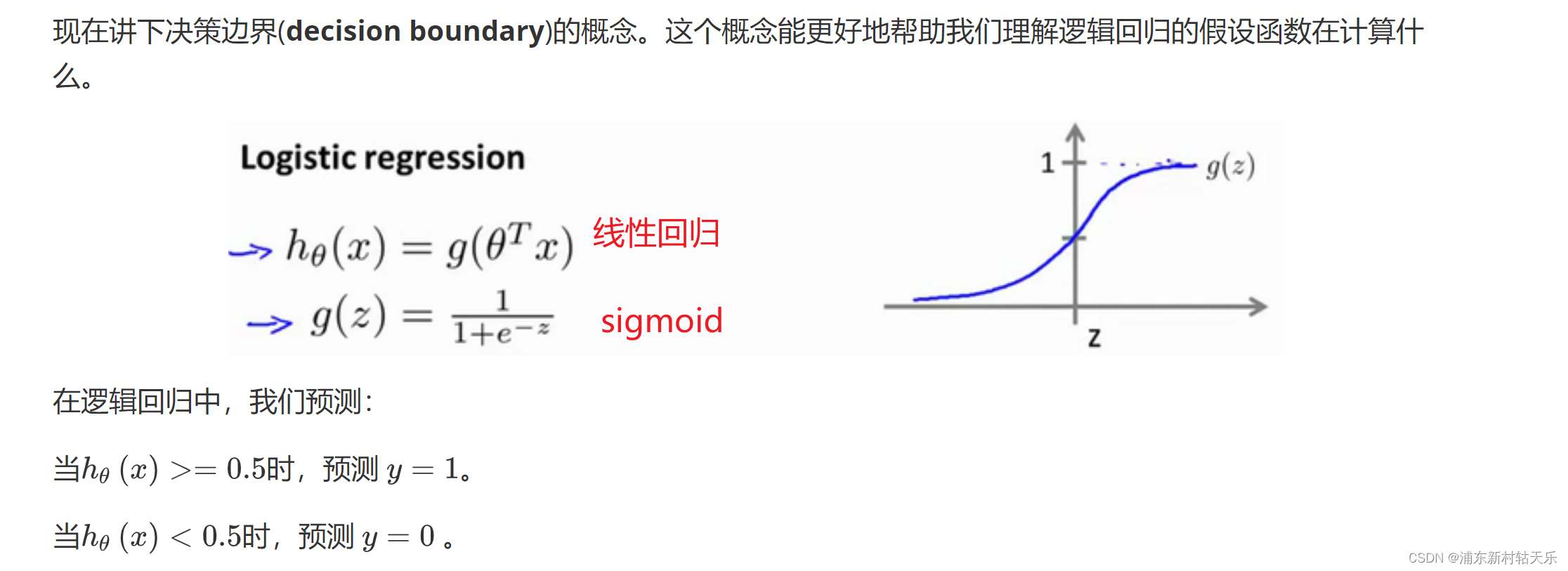
代價函數為什么不使用誤差的平方和,而是使用交叉熵?
這個圖太形象了,使用誤差的平方和會讓loss函數是非凸的,導致loss函數會有很多局部最小值!
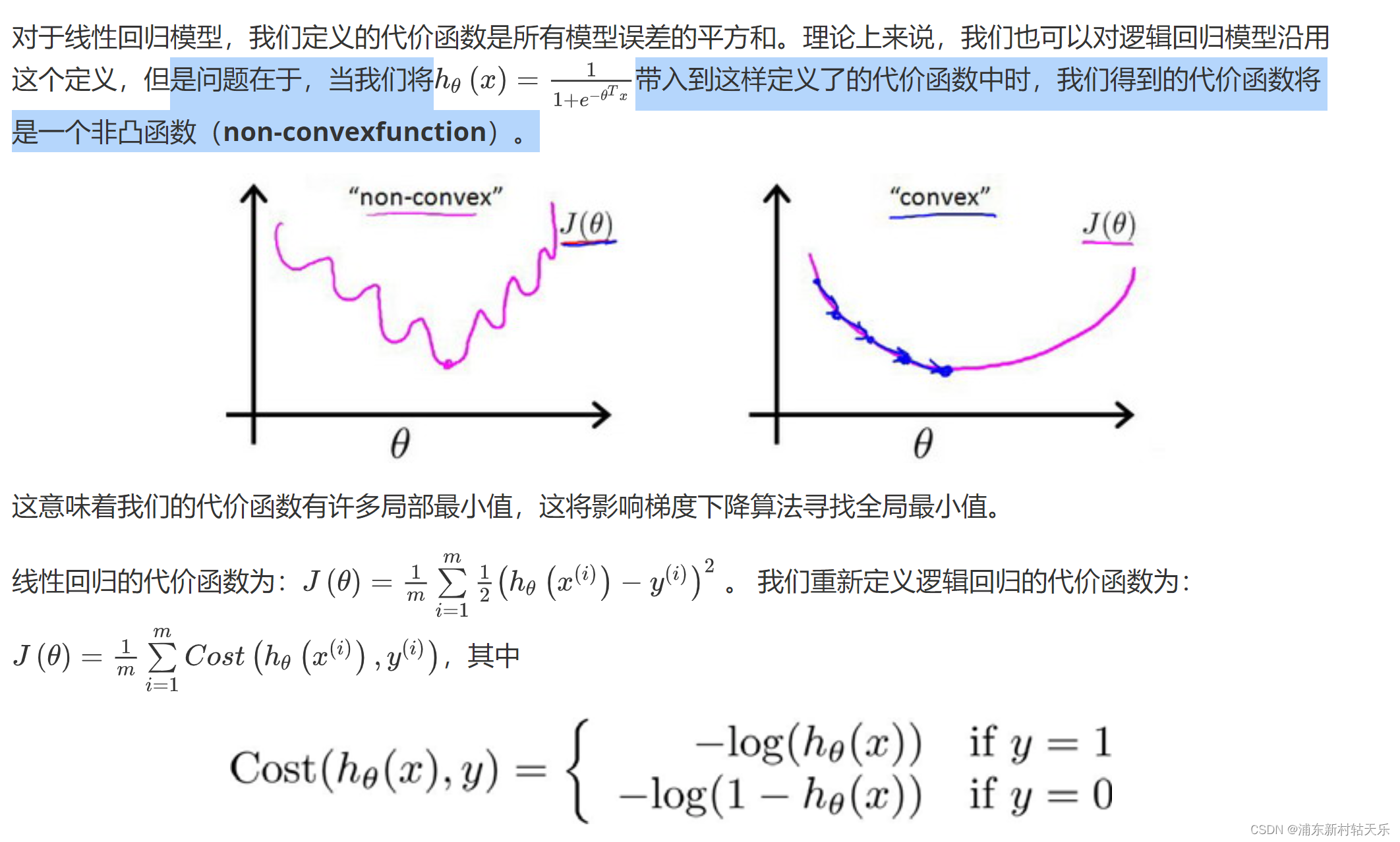
正則化為什么可以防止過擬合?
防止參數過大。

week4
神經網絡的矩陣參數含義
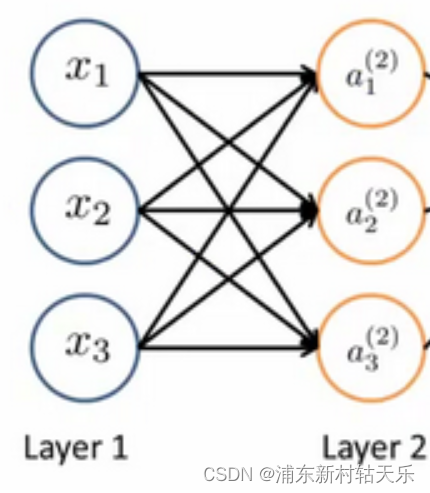
假設一個神經網絡輸入x是3維向量,輸出a是10維向量,則神經網絡的矩陣W就是(10x3),也就是神經網絡的參數量
a=Wx。如下圖所示,每個神經元跟輸入的所有神經元都建立了連接。
由此可見,單純的神經元線性層確實只是線性變換。
神經網絡相比線性回歸和邏輯回歸的優勢是什么?
隱藏層的輸出表示更高維度的feature,相對于輸入表達的更多。

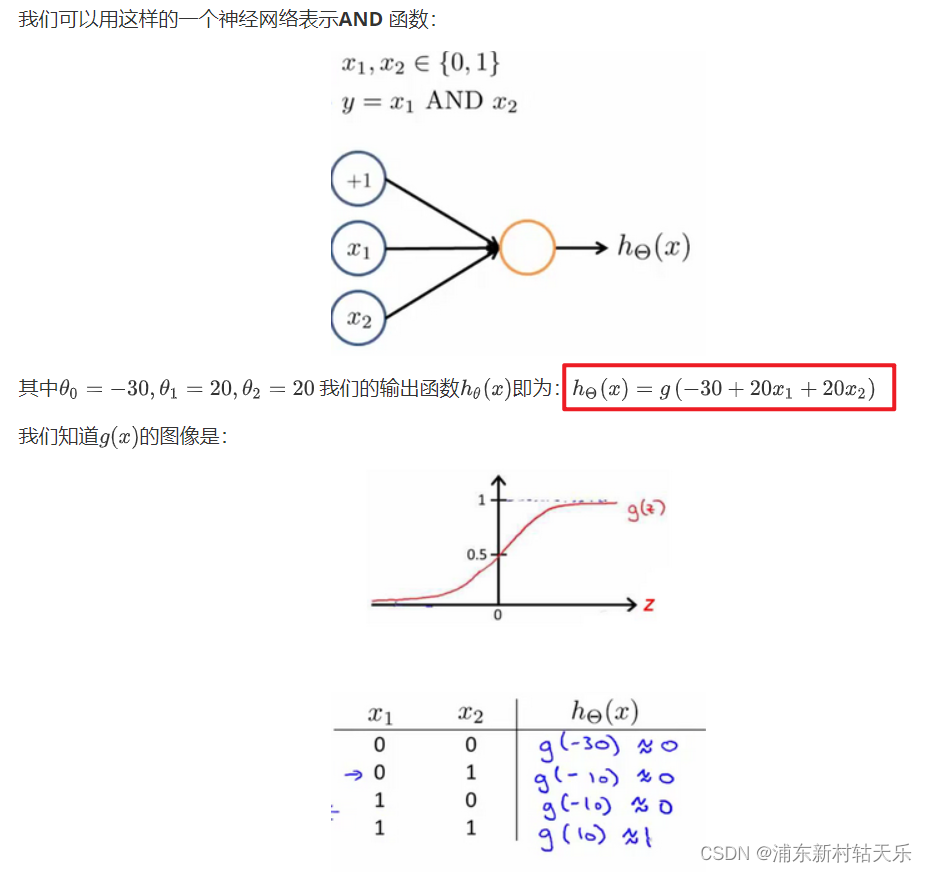
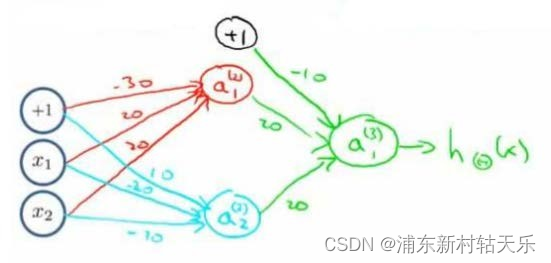
神經網絡表示and or 非 同或(XNOR)
這個是真牛逼,我就想不到。當你神經網絡是一個函數,對于一個and函數來說,它的輸入就是2維的x1,x2,所以這個線性網絡只需要三個參數。
同或XNOR表示
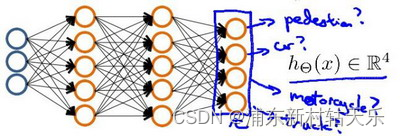
多分類輸出,有多少個類別,就輸出多少個神經元,最后神經元的真值是onehot向量。
week5
訓練神經網絡的流程
- 參數的隨機初始化
- 利用正向傳播方法計算所有的h(x)
- 編寫計算代價函數Loss的代碼
- 利用反向傳播方法計算所有偏導數
- 利用數值檢驗方法檢驗這些偏導數
- 使用優化算法來最小化代價函數
反向傳播算法(直觀理解,吳恩達視頻講解)比較清晰。
什么是反向傳播算法?誤差從最后一層,一層層往前傳播;而前向傳播指的是輸入的數據,從前往后一層層往后傳播,誤差的傳遞公式看下圖,其實就是梯度反傳?
sigmoid函數求導 f’(x) = f(x)*(1-f(x))
問題1 反向傳播公式怎么推導出來的?
吳恩達老師說自己了解也不是很深入,但是不影響他使用。大家也是一樣,不用太糾結。
從反向傳播公式中可以看出loss的反向傳播用到了上一層的梯度。
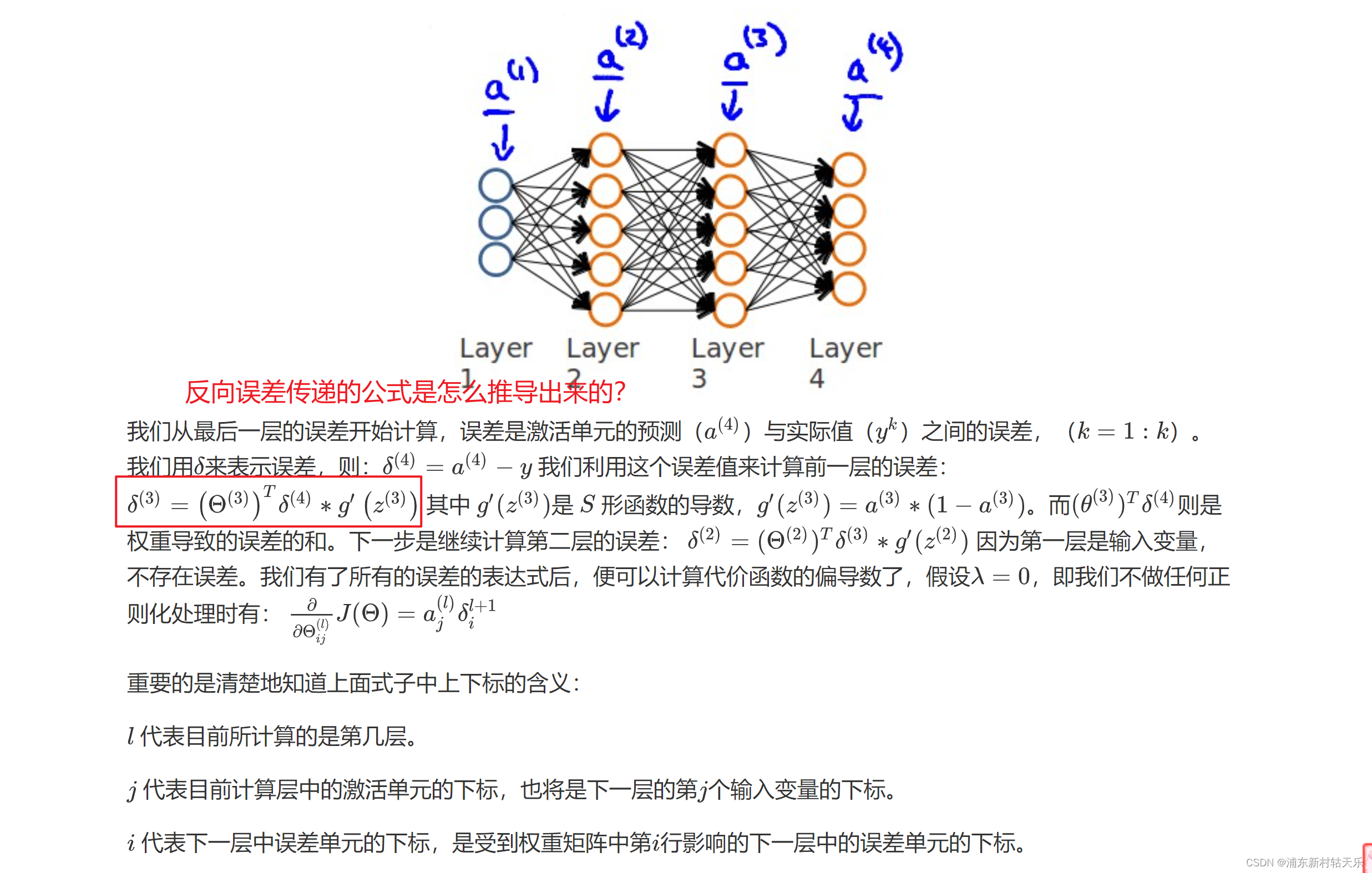
問題2 神經網絡參數初始化不能為0?
為0的話會導致第二層所有激活值都是零。
week6
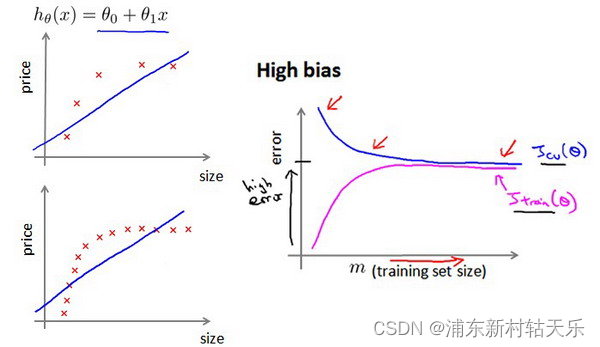
怎么判斷欠擬合和過擬合?
隨著訓練次數的增加,訓練集和驗證集的loss趨于相同,且都比較大 。
欠擬合的情況下,增加數據到訓練集不一定能有幫助。 比如用一個直線方程去擬合曲線方程,無論怎么增加數據都是沒用的。
過擬合加數據肯定有用。
如何選擇網絡
選擇比較大的神經網絡并采用正則化的方法,要比采用小的神經網絡更好。因為小的網絡容易欠擬合,而大的網絡可以通過正則化適應數據。
![【PyTorch][chapter 19][李宏毅深度學習]【無監督學習][ GAN]【理論】](http://pic.xiahunao.cn/【PyTorch][chapter 19][李宏毅深度學習]【無監督學習][ GAN]【理論】)





預處理)





DM8基于主備集群技術的兩地三中心集群部署及測試(全網最詳細))






)