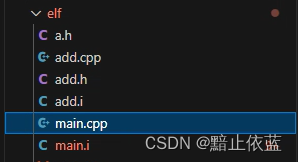
我們需要的文件結構如上
main.cpp

add.h

add.cpp

add.h

這里使用riscv的工具鏈編譯為.i文件,需要使用-E,就是只進行預處理,我們可以得到兩個.i文件即main.i和add.i
main.i

這里看到main.i里頭文件全部替換,然后多了三萬多行
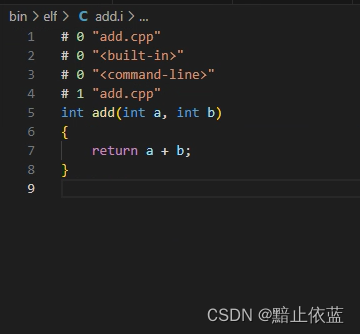
所以這部分純粹就是代碼插入,也就是說
對于C++編譯過程中預處理這一步來說,不區分頭文件來源。不論是標準庫的頭文件,還是我們自己寫的頭文件,預處理器處理它們的方式是相同的。預處理主要做以下幾件事:
-
宏定義展開:將所有的宏定義替換成相應的代碼。
-
文件包含處理:處理
#include指令,將包含的頭文件內容插入到包含指令的位置。這里不區分標準庫頭文件和自定義頭文件,預處理器根據指定的搜索路徑查找頭文件,并將頭文件內容插入到源文件中。 -
條件編譯指令處理:處理
#if、#ifdef、#ifndef、#else、#elif、#endif等條件編譯指令。 -
移除注釋:將代碼中的注釋移除。
-
添加行標識和文件標識:預處理器還會添加行號和文件名標識,這對于編譯時的錯誤定位是非常有用的。
對于引入的頭文件,預處理器的處理流程大致如下:
- 當遇到一個
#include指令時,預處理器會查找指定的文件。 - 如果是使用尖括號
< >包圍的文件名,如#include <iostream>,預處理器通常在系統的標準庫路徑中查找。 - 如果是使用雙引號
" "包圍的文件名,如#include "myheader.h",預處理器首先在源文件的相同目錄下查找,如果沒有找到,再按照編譯器配置的搜索路徑查找,這通常包括系統的標準庫路徑。 - 找到頭文件后,預處理器將頭文件的全部內容插入到
#include指令的位置,然后繼續處理插入的內容。
簡而言之,不論頭文件的來源如何,預處理器的處理方式是一致的,都是將頭文件內容插入到源文件中,然后繼續進行宏展開、條件編譯處理等操作。





DM8基于主備集群技術的兩地三中心集群部署及測試(全網最詳細))






)





)
