
文章鏈接:https://arxiv.org/abs/2402.17485
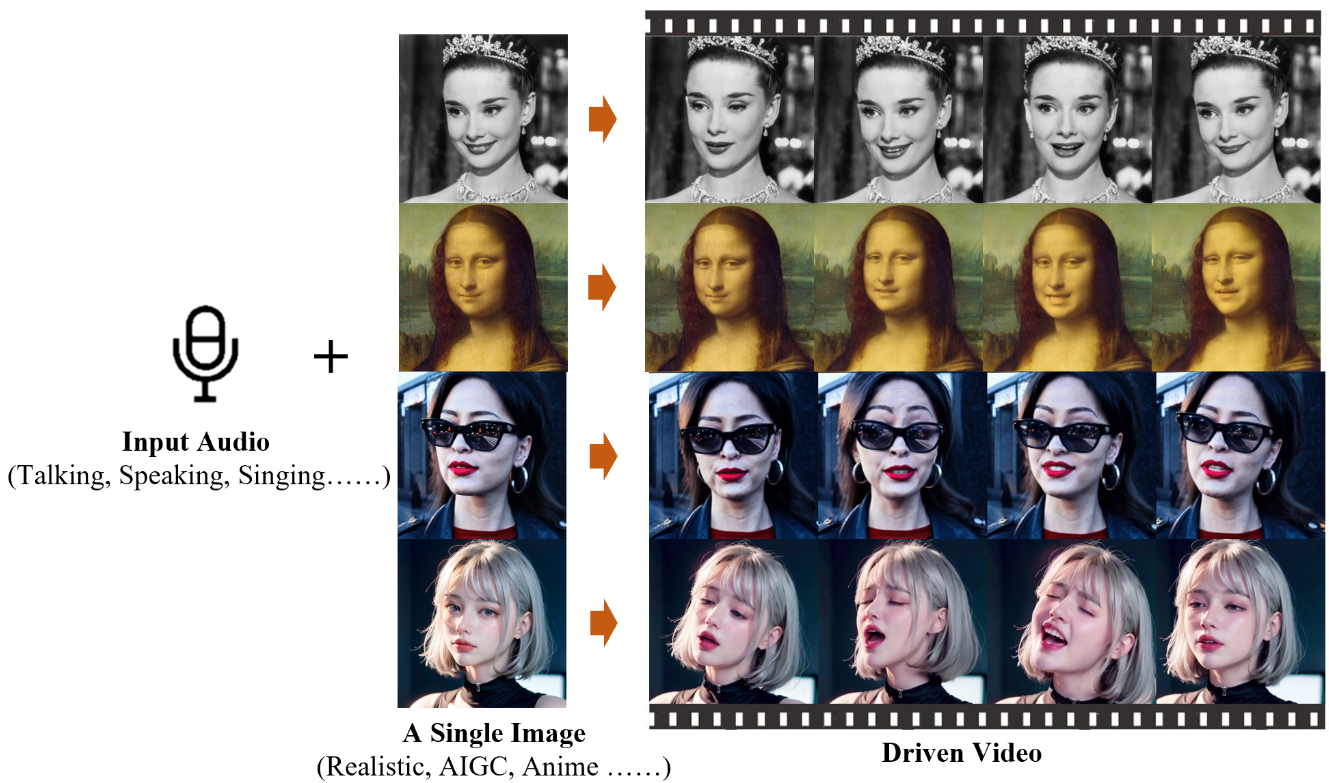
今天分享的工作是刷爆各大視頻平臺的EMO的背后的工作原理。提出的初衷是著手解決增強發言者的頭部特寫視頻生成中的現實感和表現力的挑戰,重點關注音頻提示與面部動作之間的動態和微妙關系。傳統技術具有局限性,這些技術通常無法捕捉到人類表情的全部范圍以及個體面部風格的獨特性。
EMO是一個新穎的框架,利用直接的音頻到視頻合成方法,繞過了中間的3D模型或面部關鍵點的需要。方法確保了無縫的幀轉換和一致的身份保留,從而產生高度表現力和逼真的動畫。實驗結果表明,EMO不僅能夠生成令人信服的說話視頻,還能以各種風格生成歌唱視頻,從表現力和逼真度方面顯著優于現有的最先進方法。
項目地址(截止3月4日還沒有放出代碼):
https://humanaigc.github.io/emote-portrait-alive/
介紹
近年來,圖像生成領域取得了顯著進展,這在很大程度上歸功于擴散模型的出現和成功。這些模型以它們生成高質量圖像的能力而受到贊譽,這要歸功于對大規模圖像數據集的廣泛訓練和漸進式生成方法。
這種創新方法使得創造具有無與倫比的細節和逼真度的圖像成為可能,為生成模型領域設立了新的標桿。擴散模型的應用不僅僅局限于靜態圖像。對視頻生成的興趣日益增長,導致了探索這些模型在塑造動態和引人入勝的視覺敘事方面的潛力。這些開創性的努力強調了擴散模型在視頻生成領域的巨大潛力。
除了一般的視頻合成之外,生成以人為中心的視頻一直是研究的焦點,比如發言者的頭部特寫。發言者的頭部特寫的目標是從用戶提供的音頻剪輯中生成面部表情。塑造這些表情涉及捕捉人的面部運動的微妙性和多樣性,在視頻合成中提出了重大挑戰。
傳統方法通常會對最終視頻輸出施加約束,以簡化這項任務。例如,一些方法使用3D模型來限制面部關鍵點,而其他方法從基礎視頻中提取頭部運動序列來引導整體運動。盡管這些約束減少了視頻生成的復雜性,但它們也往往限制了生成面部表情的豐富性和自然性。
本文的目標是建立一個創新的發言者的頭部特寫框架,旨在捕捉廣泛的逼真面部表情,包括微妙的微表情,并促進自然的頭部運動,從而賦予生成的頭像視頻無與倫比的表現力水平。
為了實現這一目標,本文提出了一種利用擴散模型的生成能力的方法,能夠直接從給定的圖像和音頻剪輯合成角色頭像視頻。這種方法消除了中間表示或復雜預處理的需要,簡化了生成具有高度視覺和情感保真度的發言者的頭部特寫視頻的過程,這些視頻與音頻輸入中存在的微妙差異密切相關。
音頻信號富含與面部表情相關的信息,理論上使得模型能夠生成多樣化的富有表現力的面部運動。然而,將音頻與擴散模型集成在一起并不是一項簡單的任務,因為音頻和面部表情之間的映射具有固有的模糊性。這個問題可能導致模型生成的視頻不穩定,表現為面部失真或視頻幀之間的抖動,嚴重的情況下,甚至可能導致視頻完全崩潰。
為了解決這一挑戰,這里在模型中引入了穩定的控制機制,即速度控制器和面部區域控制器,以增強在生成過程中的穩定性。這兩個控制器作為超參數發揮作用,充當微妙的控制信號,不會影響最終生成的視頻的多樣性和表現力。此外,為了確保生成視頻中的角色與輸入的參考圖像保持一致,采用并增強了ReferenceNet的方法,設計了一個類似的模塊,FrameEncoding,旨在跨視頻保留角色的身份。
最后,為了訓練模型,構建了一個龐大且多樣化的音頻視頻數據集,收集了超過250小時的錄影和超過1.5億張圖像。這個龐大的數據集涵蓋了廣泛的內容,包括演講、電影和電視片段以及歌唱表演,并涵蓋了多種語言,如中文和英文。豐富多樣的說話和歌唱視頻確保我們的訓練材料捕捉到了廣泛的人類表達和聲音風格,為EMO的發展提供了堅實的基礎。
在HDTF數據集上進行了大量的實驗和比較,其中我們的方法在多個指標(如FID、SyncNet、F-SIM和FVD)上超越了當前的最先進方法,包括DreamTalk、Wav2Lip和SadTalker。除了定量評估外,還進行了全面的用戶研究和定性評估,結果顯示我們的方法能夠生成高度自然和富有表現力的說話甚至歌唱視頻,達到了迄今為止最佳的結果。
相關工作
擴散模型
擴散模型在各個領域展示了顯著的能力,包括圖像合成、圖像編輯、視頻生成,甚至3D內容生成。其中,Stable Diffusion (SD)是一個代表性例子,采用UNet架構迭代生成具有顯著文本到圖像能力的圖像,經過對大型文本圖像數據集的廣泛訓練。這些預訓練模型在各種圖像和視頻生成任務中得到了廣泛應用。
一些最近的工作采用了DiT(Diffusion-in-Transformer),它改變了UNet架構,將Transformer與具有時間模塊和3D卷積的模塊相結合,使其支持更大規模的數據和模型參數。通過從頭開始訓練整個文本到視頻模型,它實現了卓越的視頻生成結果。此外,一些工作已經開始將擴散模型應用于發言者的頭部特寫生成,產生了令人期待的結果,突顯了這些模型在制作逼真的發言者的頭部特寫視頻方面的能力。
聲音驅動的發言者的頭部特寫生成
聲音驅動的發言者的頭部特寫生成可大致分為兩種方法:基于視頻的方法和單圖像方法。基于視頻的發言者的頭部特寫生成允許直接在輸入視頻片段上進行編輯。
例如,Wav2Lip根據音頻重新生成視頻中的唇部動作,使用鑒別器進行音頻唇部同步。它的局限性在于依賴基礎視頻,導致固定的頭部運動和僅生成嘴部動作,這可能限制了真實感。對于單圖像發言者的頭部特寫生成,使用參考照片生成與照片外觀相匹配的視頻。提出通過學習混合形狀和頭部姿勢來獨立生成頭部運動和面部表情。然后,使用這些信息創建3D面部網格,作為指導最終視頻幀生成的中間表示。
類似地,[33]使用3D可變模型(3DMM)作為生成發言者的頭部特寫視頻的中間表示。這些方法的一個常見問題是3D網格的表示能力有限,這限制了生成視頻的整體表現力和逼真度。此外,這兩種方法都基于非擴散模型,進一步限制了生成結果的性能。
[15]嘗試使用擴散模型進行發言者的頭部特寫生成,但不是直接應用于圖像幀,而是將它們用于生成3DMM的系數。與前兩種方法相比,Dreamtalk 在結果上有所改進,但仍然未能實現高度自然的面部視頻生成。
方法
給定一個角色肖像的單個參考圖像,EMO可以生成與輸入的語音音頻剪輯同步的視頻,保留與提供的聲音音頻的音調變化和諧的自然頭部運動和生動表情。通過創建一系列連續的級聯視頻,EMO促進了生成具有一致身份和連貫運動的長時持續說話肖像視頻,這對于現實應用至關重要。
準備
EMO采用 Stable Diffusion(SD)作為基礎框架。SD 是一種廣泛使用的文本到圖像(T2I)模型,起源于潛在擴散模型(LDM)。它利用變分自編碼器(VAE)將原始圖像特征分布 映射到潛在空間 ,將圖像編碼為 = 并將潛在特征重建為 。這種架構具有降低計算成本并保持高視覺保真度的優勢。基于去噪擴散概率模型(DDPM)或去噪擴散隱式模型(DDIM)方法,SD 引入高斯噪聲 ε 到潛在 中,產生特定時間步 t 的噪聲潛在 。在推理過程中,SD 旨在從潛在 中移除噪聲 ε,并通過整合文本特征來實現所需的結果。這個去噪過程的訓練目標表達為:
![]()
其中 c 代表文本特征,這些特征是通過 CLIPViT-L/14 文本編碼器從tokens 提示中獲取的。在 SD 中, 通過修改的 UNet模型實現,該模型采用交叉注意力機制將 c 與潛在特征融合。
網絡流程
我們方法的概述如下圖2所示。
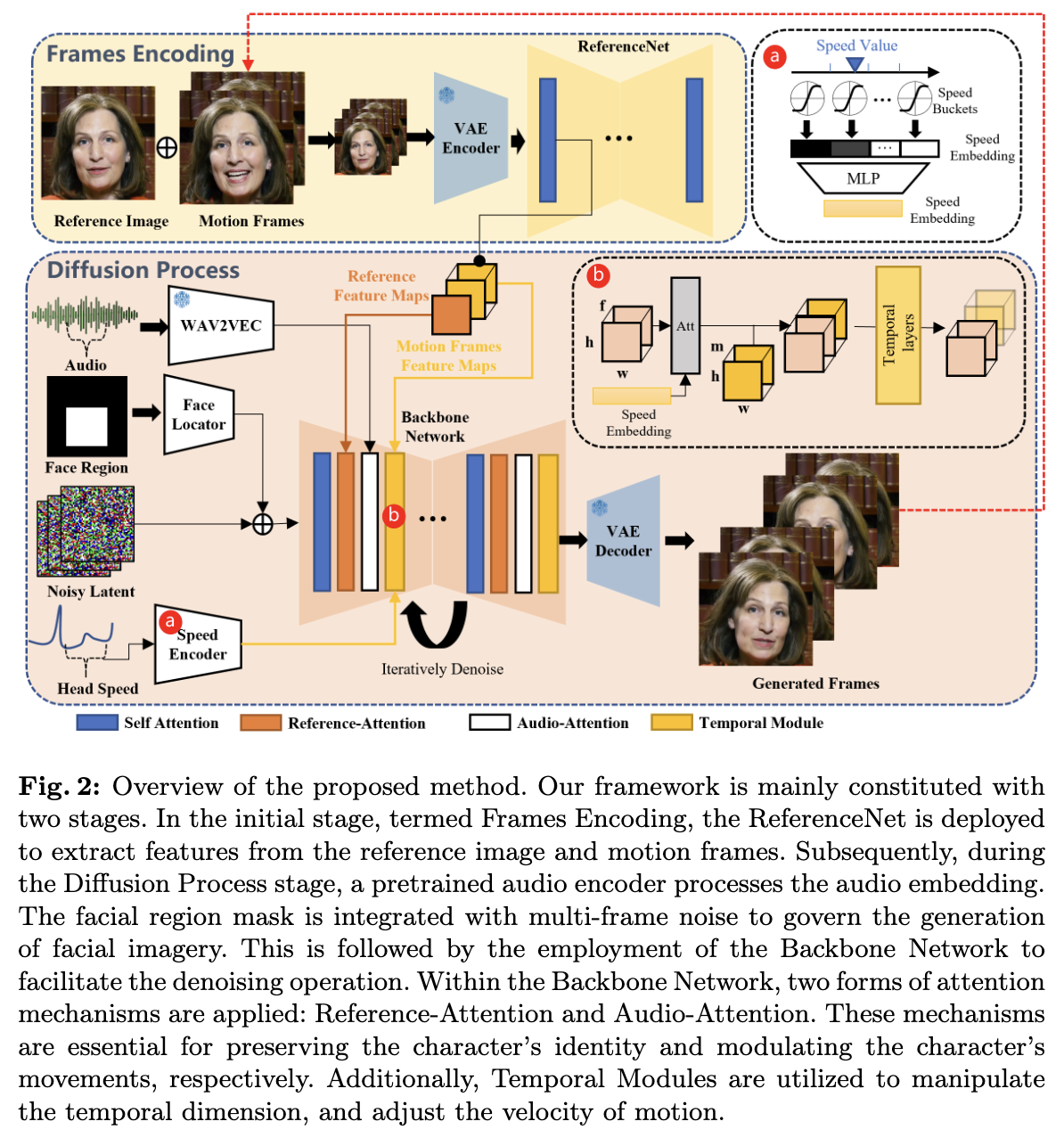
骨干網絡接收多幀噪聲潛在輸入,并在每個時間步嘗試將其去噪為連續的視頻幀,骨干網絡具有與原始 SD 1.5 類似的 UNet 結構配置。
-
與以前的工作類似,為了確保生成的幀之間的連續性,骨干網絡嵌入了時間模塊。
-
為了保持生成幀中人像的 ID 一致性,在骨干網絡旁部署了一個稱為 ReferenceNet 的 UNet 結構,它輸入參考圖像以獲取參考特征。
-
為了驅動角色的說話動作,使用音頻層來編碼語音特征。
-
為了使說話角色的運動可控且穩定,使用面部定位器和速度層提供弱約束條件。
骨干網絡
在本工作中,未使用提示embedding;因此,已經將 SD 1.5 UNet 結構中的交叉注意力層改為參考注意力層。這些修改后的層現在將 ReferenceNet 中的參考特征作為輸入,而不是文本embeddings。
音頻層
聲音中的發音和語調是生成角色運動的主要驅動信號。通過預訓練的 wav2vec的各個塊從輸入音頻序列中提取的特征被連接以產生音頻表示嵌入 ,對于第 f 幀。然而,運動可能受到未來/過去音頻段的影響,例如,在說話之前張嘴和吸氣。為了解決這個問題,我們通過將相鄰幀的特征連接起來定義了每個生成幀的語音特征:,其中 m 是每邊的附加特征數量。為了將語音特征注入到生成過程中,在骨干網絡中的每個參考注意力層后添加了音頻注意力層,執行潛在代碼與 Agen 之間的交叉注意力機制。
ReferenceNet
ReferenceNet 的結構與骨干網絡相同,并用于從輸入圖像中提取詳細特征。由于 ReferenceNet 和骨干網絡都源自相同的原始 SD 1.5 UNet 架構,因此這兩個結構在某些層次生成的特征圖很可能會表現出相似性。
因此,這有助于骨干網絡整合 ReferenceNet 提取的特征。先前的研究已經強調了利用類似結構在維持目標對象身份一致性方面的深遠影響。在本研究中,ReferenceNet 和骨干網絡都繼承了原始 SD UNet 的權重。將目標角色的圖像輸入到 ReferenceNet 中,以從自注意力層中提取參考特征圖輸出。在骨干網絡去噪過程中,相應層的特征經過與提取的特征圖的參考注意力層。由于 ReferenceNet 主要設計用于處理單個圖像,它缺乏在骨干網絡中發現的時間層。
時間模塊
大多數工作嘗試將時間混合層插入預訓練的文本到圖像架構中,以促進對連續視頻幀之間時間關系的理解和編碼。通過這樣做,增強的模型能夠在幀之間保持連續性和一致性,從而生成平滑一致的視頻流。
受AnimateDiff的架構概念啟發,將自注意力時間層應用于幀內的特征。具體而言,將輸入特征圖 x ∈ 重新配置為形狀 (b×h×w)×f×c。這里,b代表batch大小,h和w表示特征圖的空間維度,f是生成幀的數量,c是特征維度。
值得注意的是,將自注意力定向到時間維度 f,以有效捕捉視頻的動態內容。時間層被插入到骨干網絡的每個分辨率層中。大多數基于擴散的視頻生成模型在設計上受到限制,只能生成預先確定數量的幀,從而限制了生成擴展視頻序列的能力。
這種限制在發言者的頭部特寫視頻的應用中尤為顯著,因為足夠的持續時間對于表達有意義的講話至關重要。一些方法學采用前一剪輯末尾的幀作為后續生成的初始幀,旨在保持連接片段之間的無縫過渡。受此啟發,我們的方法將先前生成的剪輯中的最后n幀,稱為“運動幀”,并入以增強片段間的一致性。
具體而言,這些n個運動幀被輸入到ReferenceNet中以預提取多分辨率動作特征圖。在骨干網絡內的去噪過程中,將時間層輸入與匹配分辨率的預提取動作特征沿幀維度進行合并。這種簡單的方法有效地確保了各種片段之間的一致性。對于生成的第一個視頻剪輯,將運動幀初始化為零特征圖。
值得注意的是,雖然骨干網絡可能會多次迭代以去噪嘈雜的幀,但目標圖像和運動幀僅被串聯并輸入到ReferenceNet一次。因此,在整個過程中重復使用提取的特征,確保在推理過程中沒有計算時間的實質性增加。
面部定位器和速度層。時間模塊可以保證生成的幀之間的連續性和視頻片段之間的無縫過渡,然而,由于獨立生成過程,它們無法確保生成的角色動作在片段之間的一致性和穩定性。先前的工作使用某些信號來控制角色的動作,例如骨架、混合形狀或3DMM,然而,使用這些控制信號可能不利于創建生動的面部表情和動作,因為它們的自由度有限,而在訓練階段的不充分標注無法捕捉到完整的面部動態范圍。
此外,相同的控制信號可能導致不同角色之間的差異,無法考慮到個體細微差異。使生成控制信號可能是一個可行的方法,然而,產生逼真的運動仍然是一個挑戰。因此,我們選擇了一種“弱”控制信號方法。
具體地,在前面圖2中所示,使用一個mask M = 作為面部區域,該mask包含視頻剪輯的面部邊界框區域。我們使用面部定位器,它由輕量級卷積層組成,設計用于對邊界框mask進行編碼。然后,在將結果編碼的mask添加到嘈雜的潛在表示之前,將其饋送到骨干網絡。通過這種方式,可以使用mask來控制角色面部應該生成的位置。
然而,由于在不同的生成過程中頭部運動頻率的變化,使得在片段之間創建一致和平滑的運動是具有挑戰性的。
為了解決這個問題,將目標頭部運動速度納入到生成過程中。更具體地說,考慮幀f中的頭部旋轉速度,并將速度范圍劃分為d個離散速度桶,每個桶代表不同的速度水平。每個桶都有一個中心值和一個半徑。我們將重新定向到一個向量S = {}∈,其中。與音頻層中使用的方法類似,每個幀的頭部旋轉速度embedding由 = ⊕給出,并且 隨后由MLP處理以提取速度特征。
在時間層內,將重復到形狀 (b × h × w) × f × ,并實現一個跨速度特征和沿時間維度f重塑的特征圖之間進行操作的交叉注意力機制。通過這樣做,并指定目標速度,可以同步生成的角色頭部旋轉速度和頻率,跨不同的片段。結合面部定位器提供的面部位置控制,生成的輸出可以既穩定又可控。
還應該注意到,指定的面部區域和分配的速度并不構成強控制條件。在面部定位器的上下文中,由于M是整個視頻剪輯的聯合區域,表明了一個可允許面部運動的大區域,從而確保頭部不受限制于靜態姿勢。關于速度層,準確估計數據集標簽中的人類頭部旋轉速度的困難意味著預測的速度序列本質上是嘈雜的。因此,生成的頭部運動只能近似于指定的速度水平。這種限制促使我們設計了速度桶框架。
訓練策略
訓練過程分為三個階段。第一階段是圖像預訓練階段,在此階段中,骨干網絡、參考網絡和面部定位器都被納入訓練,骨干網絡以單幀作為輸入,而參考網絡處理同一視頻剪輯中不同的、隨機選擇的幀。骨干網絡和參考網絡都從原始的SD初始化權重。第二階段是引入視頻訓練,在此階段中加入了時間模塊和音頻層,從視頻剪輯中采樣n+f連續幀,其中開始的n幀是運動幀。
時間模塊的權重初始化來自于 AnimateDiff。在最后階段,速度層被整合進來,只在這個階段訓練時間模塊和速度層。這種策略性的決定有意地將音頻層從訓練過程中省略掉。因為說話角色的表情、嘴部動作和頭部運動的頻率,主要受到音頻的影響。因此,這些元素之間存在相關性,模型可能會根據速度信號而不是音頻來驅動角色的運動。實驗結果表明,同時訓練速度和音頻層會削弱音頻對角色動作的驅動能力。
實驗
實現
從互聯網上收集了約250小時的發言者特寫頭像視頻,并補充了HDTF和VFHQ數據集,用于訓練我們的模型。由于VFHQ數據集缺乏音頻,因此它僅用于第一個訓練階段。應用MediaPipe人臉檢測框架來獲取面部邊界框區域。頭部旋轉速度是通過提取每一幀的6自由度頭部姿態使用面部特征點進行標注,然后計算相鄰幀之間的旋轉角度來標注的。
從數據集中采樣的視頻剪輯被調整大小并裁剪為512 × 512。在第一個訓練階段,參考圖像和目標幀分別從視頻剪輯中采樣,以批大小48訓練骨干網絡和參考網絡。在第二和第三階段,將生成的視頻長度設置為f = 12,運動幀數設置為n = 4,采用批大小4進行訓練。額外特征數m設置為2,遵循Diffused Heads。所有階段的學習率均設置為1e-5。在推理過程中,使用DDIM的采樣算法為視頻剪輯生成40步,為每個幀生成分配一個恒定的速度值。我們的方法的時間消耗約為15秒一個批次(f = 12幀)。
實驗設置
為了進行方法比較,將HDTF數據集劃分,將10%分配為測試集,保留剩余90%用于訓練。采取了預防措施,確保這兩個子集之間沒有角色ID的重疊。將我們的方法與一些先前的工作進行比較,包括:Wav2Lip,SadTalker,DreamTalk。
另外,使用了來自Diffused Heads的發布代碼生成結果,然而,該模型是在僅包含綠色背景的CREMA數據集上訓練的,生成的結果不夠理想。此外,結果受到了在生成的幀之間的誤差累積的影響。因此只對Diffused Heads方法進行了定性比較。對于DreamTalk,使用了原始作者規定的說話風格參數。
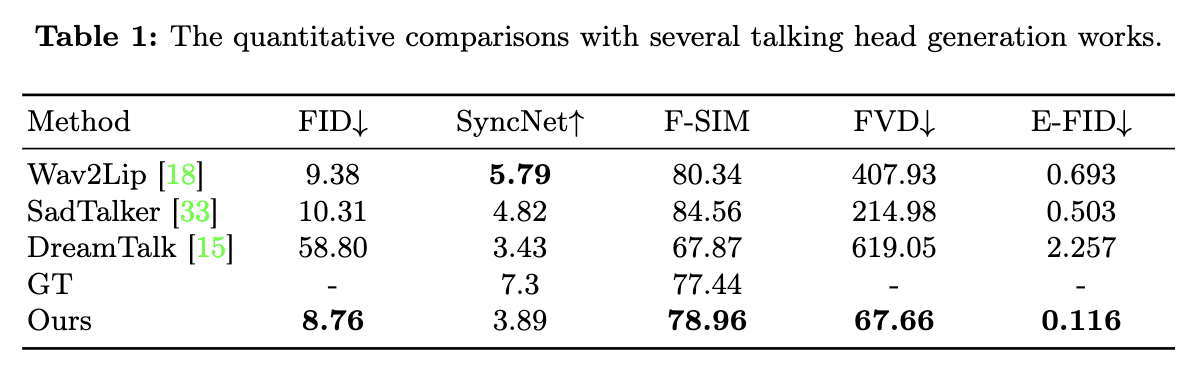
為了證明所提出方法的優越性,使用了幾個定量指標對模型進行評估。利用Fréchet Inception Distance(FID)來評估生成幀的質量。另外,為了衡量結果中的身份保持情況,通過提取和比較生成幀和參考圖像之間的面部特征來計算面部相似性(F-SIM)。值得注意的是,使用單一的、不變的參考圖像可能會導致欺騙性的完美F-SIM分數。某些方法[18]可能只會生成口部區域,而將其余幀保持與參考圖像相同,這可能會使結果產生偏差。
因此,將F-SIM視為opulation-reference indices,較接近相應的真值(GT)表示性能更好。進一步采用Fréchet Video Distance(FVD)進行視頻級評估。SyncNet分數用于評估唇部同步質量,這是說話頭應用的關鍵方面。
為了評估生成視頻中面部表情的表現力,引入了Expression-FID(E-FID)度量。這涉及通過面部重建技術提取表情參數,如[3]中所述。隨后,我們計算這些表情參數的FID,以定量衡量合成視頻中的表情與真值數據集中的表情之間的差異。
定性比較
下圖3展示了我們方法與之前方法的視覺結果。

可以觀察到,當提供單一參考圖像作為輸入時,Wav2Lip通常會合成模糊的嘴部區域,并生成頭部姿勢靜態、眼睛運動最小的視頻。對于DreamTalk,提供的樣式片段可能會扭曲原始面部,也會限制面部表情和頭部運動的動態性。與SadTalker和DreamTalk相比,我們提出的方法能夠生成更廣泛的頭部運動和更動態的面部表情。由于我們不使用直接信號,如混合形狀或3DMM,來控制角色的運動,這些運動是由音頻直接驅動的,這將在下面的示范中詳細討論。
進一步探索了在各種人像風格下生成發言者頭部特寫視頻的可能性。如下圖4所示,從Civitai獲取的參考圖像是由不同的文本到圖像(T2I)模型合成的,涵蓋了各種風格的人物,包括逼真的、動漫的和3D的。這些角色使用相同的語音音頻輸入進行動畫化,從而在不同風格之間實現了近乎統一的唇部同步。雖然我們的模型只是在逼真的視頻上進行了訓練,但它顯示出在為各種人像類型生成說話頭視頻方面的能力。

下圖5展示了當處理具有明顯音調特征的音頻時,我們的方法能夠生成更豐富的面部表情和動作。例如,第三行的示例顯示,高音調的語音音調能夠引發角色更強烈和更生動的表情。此外,利用動作幀能夠延長生成的視頻,可以根據輸入音頻的長度生成持續時間較長的視頻。正如下圖5和下圖6所示,我們的方法在長序列中保持了角色的身份,即使在存在大幅運動的情況下也是如此。

定量比較
如下表1所示,我們的結果表明在視頻質量評估方面具有明顯的優勢,這體現在較低的FVD得分上。此外,我們的方法在單幀質量方面表現出色,這表現在改善的FID得分上。盡管在SyncNet指標上未達到最高分,但我們的方法在生成生動的面部表情方面表現出色,正如E-FID所示。
局限性
EMO方法存在一些局限性。首先,與不依賴于擴散模型的方法相比,它更耗時。其次,由于不使用任何明確的控制信號來控制角色的動作,可能會導致意外生成其他身體部位,如手部,從而在視頻中產生瑕疵。解決這個問題的一個潛在方法是專門為身體部位使用控制信號。
參考文獻
[1]EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
?更多精彩內容,請關注公眾號:AI生成未來

歡迎加群交流AIGC技術




)




-快速入門)
)




—— Pod 不停重啟問題分析與解決)




