背景
當今的數字化世界離不開無處不在的網絡連接。無論是日常生活中的社交媒體、電子商務,還是企業級應用程序和云服務,我們對網絡的依賴程度越來越高。然而,網絡的可靠性和性能往往是一個復雜的問題,尤其是在具有大規模分布式架構的系統中。
在過去,網絡監控主要依賴于傳統的點對點(point-to-point)方式,通過單獨的監控工具對網絡路徑進行測試。然而,這種方法往往只能提供有限的信息,并且無法全面評估整個網絡的健康狀況。為了更好地了解網絡的運行情況以及及時發現潛在的問題,Pingmesh 技術應運而生。
Pingmesh 的提出最初是來自微軟,在微軟內部 Pingmesh 每天會記錄 24TB 數據,進行 2000 億次 ping 探測,通過這些數據,微軟可以很好的進行網絡故障判定和及時的修復。
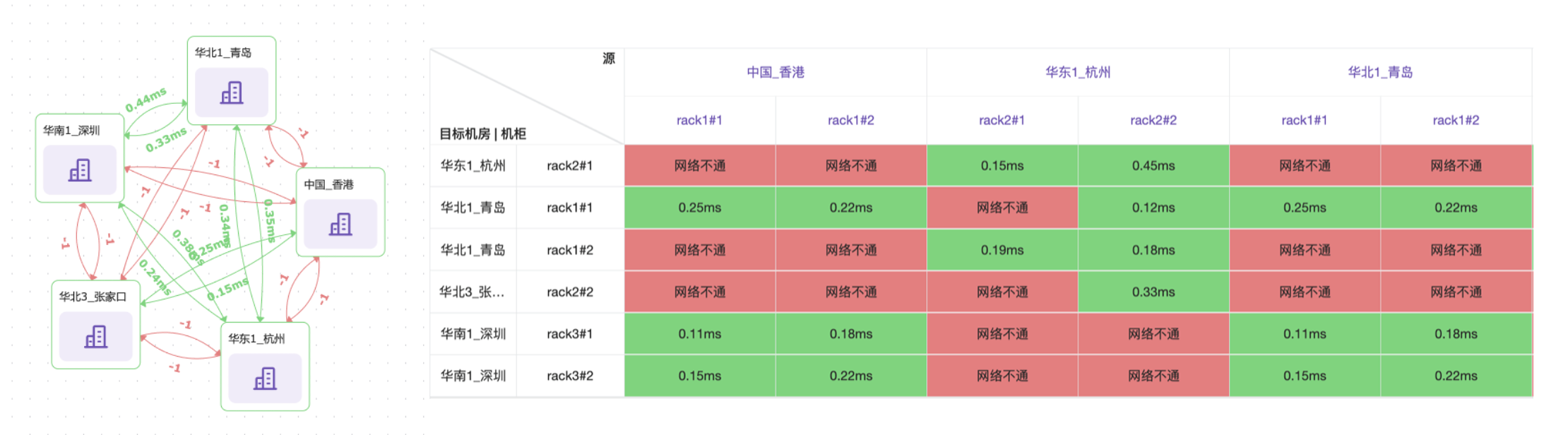
下面是 Flashcat Pingmesh 的頁面樣例,可以清晰地看到各個機房之間的網絡情況,也可以看到各個機柜或交換機之間的情況:
業界方案
業界對Pingmesh的實現大都基于微軟的一則論文為基礎,做出了一些改造和升級。原微軟Pingmesh論文地址: 《Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis》。
常見的數據中心網絡拓撲:
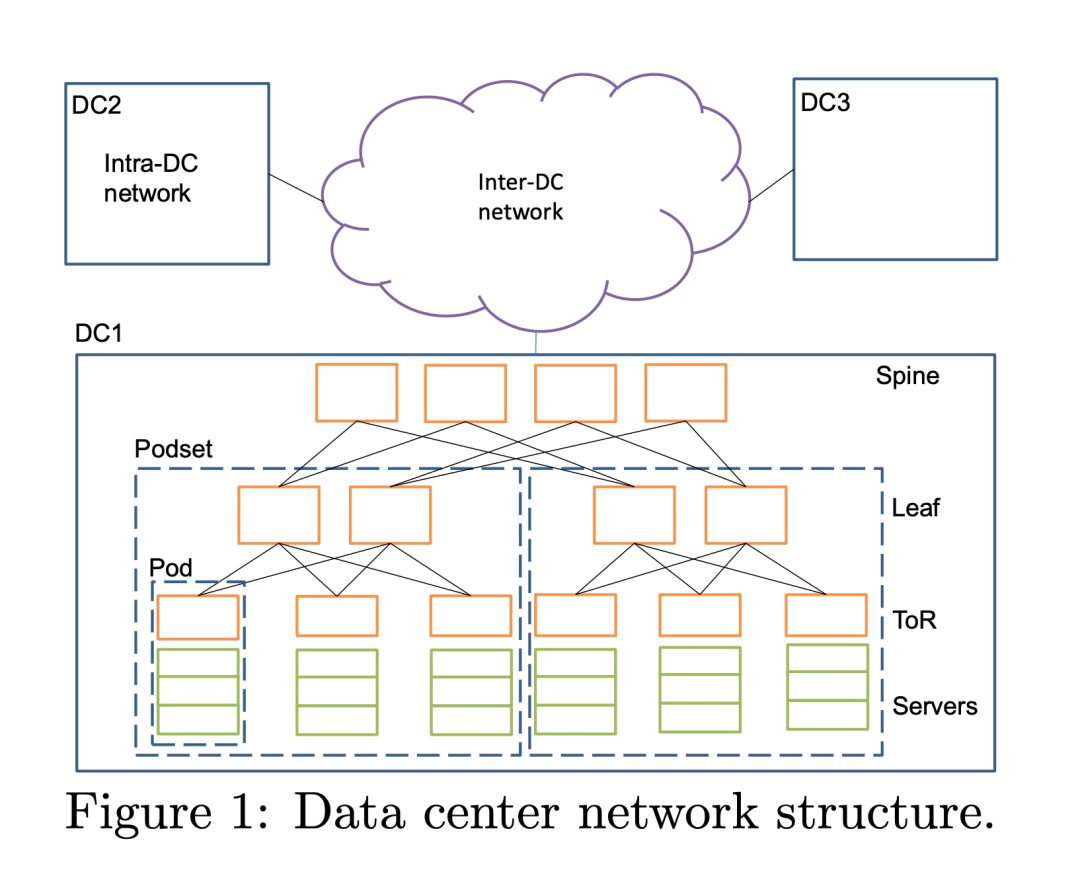
在這樣的架構中,有多個數據中心,數據中心之間有專線連通,在數據中心內部有多個Spine、Leaf、ToR交換機,在一些架構中,leaf交換機也會直接充當ToR作為服務器接入交換機,在 ToR 交換機下有大量服務器連接; 因此,pingmesh 能力就分為3 個級別:
- 在機架內部,讓所有的 server 互相 ping,每個 server ping 機架內其他 N-1 個 server
- 在機架之間,則每個機架選幾個 server ping 其他機架的 server,保證 server 所屬的 ToR 不同
- 在數據中心之間,則選擇不同的數據中心的幾個不同機架的 server 來ping
Pingmesh 架構設計

Controller
Controller 主要負責生成 pinglist 文件,這個文件是 XML 格式的,pinglist 的生成是很重要的,需要根據實際的數據中心網絡拓撲進行及時更新。 在生成 pinglist 時, Controller 為了避免開銷,分為3 個級別:
- 在機架內部,讓所有的 server 互相 ping,每個 server ping (N-1) 個 server
- 在機架之間,則每個機架選幾個 server ping 其他機架的 server,保證 server 所屬的 ToR 不同
- 在數據中心之間,則選擇不同的數據中心的幾個不同機架的 server 來ping
Controller 在生成 pinglist 文件后,通過 HTTP 提供出去,Agent 會定期獲取 pinglist 來更新 agent 自己的配置,也就是我們說的“拉”模式。Controller 需要保證高可用,因此需要在 VIP 后面配置多個實例,每個實例的算法一致,pinglist 文件內容也一致,保證可用性。
Agent
微軟數據中心的每個 server 都會運行 Agent,用來真正做 ping 動作的服務。為了保證獲取結果與真實的服務一致,Pingmesh 沒有采用 ICMP ping,而是采用的 TCP/HTTP ping。所以每個 Agent 既是 Server 也是 Client。每個 ping 動作都開啟一個新的連接,主要為了減少 Pingmesh 造成的 TCP 并發。 Agent 要保證自己是可靠的,不會造成一些嚴重的后果,其次要保證自己使用的資源要足夠的少,畢竟要運行在每個 server 上。兩個server ping 的周期最小是 10s,Packet 大小最大 64kb。針對靈活配置的需求,Agent 會定期去 Controller 上拉取 pinglist,如果 3 次拉取不到,那么就會刪除本地已有 pinglist,停止 ping 動作。 在進行 ping 動作后,會將結果保存在內存中,當保存結果超過一定閾值或者到達了超時時間,就將結果上傳到 Cosmos 中用于分析,如果上傳失敗,會有重試,超過重試次數則將數據丟棄,保證 Agent 的內存使用。
網絡狀況
根據論文中提到的,不同負載的數據中心的數據是有很大差異的,在 P99.9 時延時大概在 10-20ms,在 P99.99 延時大概在100+ms 。關于丟包率的計算,因為沒有用 ICMP ping 的方式,所以這里是一種新的計算方式,(一次失敗 + 二次失敗)次數/(成功次數)= 丟包率。這里是每次 ping 的 timeout 是 3s,windows 重傳機制等待時間是 3s,下一次 ping 的 timeout 時間是 3s,加一起也就是 9s。所以這里跟 Agent 最小探測周期 10s 是有關聯的。二次失敗的時間就是 (2 * RTT)+ RTO 時間。 Pingmesh 的判斷依據有兩個,如果超過就報警:
- 延時超過 5ms
- 丟包率超過?
10^(-3)
在論文中還提到了其他的網絡故障場景,交換機的靜默丟包。有可能是 A 可以連通 B,但是不能連通 C。還有可能是 A 的 i 端口可以連通 B 的 j 端口,但是 A 的 m 端口不能連通 B 的 j 端口,這些都屬于交換機的靜默丟包的范疇。Pingmesh 通過統計這種數據,然后給交換機進行打分,當超過一定閾值時就會通過 Autopilot 來自動重啟交換機,恢復交換機的能力。
Flashcat-Pingmesh 方案
業界方案大都實現了各自的ping-agent的能力,但對于controller生成pinglist的能力并未有好的開源方案。同時我們和一些客戶交流,了解到目前數據中心架構與傳統的leaf-tor-server架構不太一樣,傳統一個機頂交換機下server都在一個機柜下,現在數據中心一個交換機下機器可能在不同機柜,這種情況如果還是按交換機維度進行探測,當server機器探測故障后,無法快速定位到機器位置。因此,我們在開發之前就針對Tor以及機柜維度進行了設計。
Pimgesh應具備哪些能力?
- 具備最基礎的Ping探測能力,即ICMP協議支持,同時也應支持TCP、UDP等協議的端口探測;
- 簡化頁面用戶配置,用戶只需配置數據中心名字、交換機CIDR值,數據中心支持的探測協議和端口等關鍵信息;
- 數據中心會有很多機柜、交換機和機器,如何避免ping風暴,因此需支持配置選取部分機柜、交換和機器進行探測,及探測比例配置,用戶可靈活配置數據中心參與探測的交換機或機柜比例數,以及每個交換機或機柜下參與探測的Server比例數;
- 每個數據中心內部、默認所有機柜或交換機之間進行探測(Server比例數依舊生效)
- 每個數據中心之間,用戶可配置默認規則,即兩兩數據中心之間,按照配置的協議進行探測。當然,用戶也可自定義哪些數據中心之間按照所選協議進行探測,此時機柜或交換機以及Server比例數依舊生效;
- 探測結果進行有效聚合展示,多個數據中心有很多機柜或交換機以及機器,分三層結構展示探測結果,第一層展示所有數據中心之間的探測鏈路拓撲以及探測值、第二層展示數據中心內部每個機柜或交換機之間的探測拓撲和結果、第三層展示機柜或交換機下面所選Server之間的探測拓撲和結果;
- Ping故障一鍵停止探測的止損能力;
- 探測機器故障后,自動重新選替補機器能力;
- 數據中心配置變更后,能及時自動以新配置重新生成pinglist;
- 支持簡便地配置報警規則;
- 探測結果寫入支持prometheus協議的時序庫中;
交換機和機柜模式配置差異
- 交換機模式,頁面用戶只需配置交換CIDR值即可,無需手動注冊Server IP,我們會借助 Categraf 的心跳功能,自動判斷出server ip應歸屬哪個交換機。
- 機柜模式,這種方式一般適用于客戶環境中有自己的CMDB系統,可將其CMDB系統中的數據中心、機柜和機器關系通過OpenApi注冊到Pingmesh系統中。
Pingmesh 架構設計:
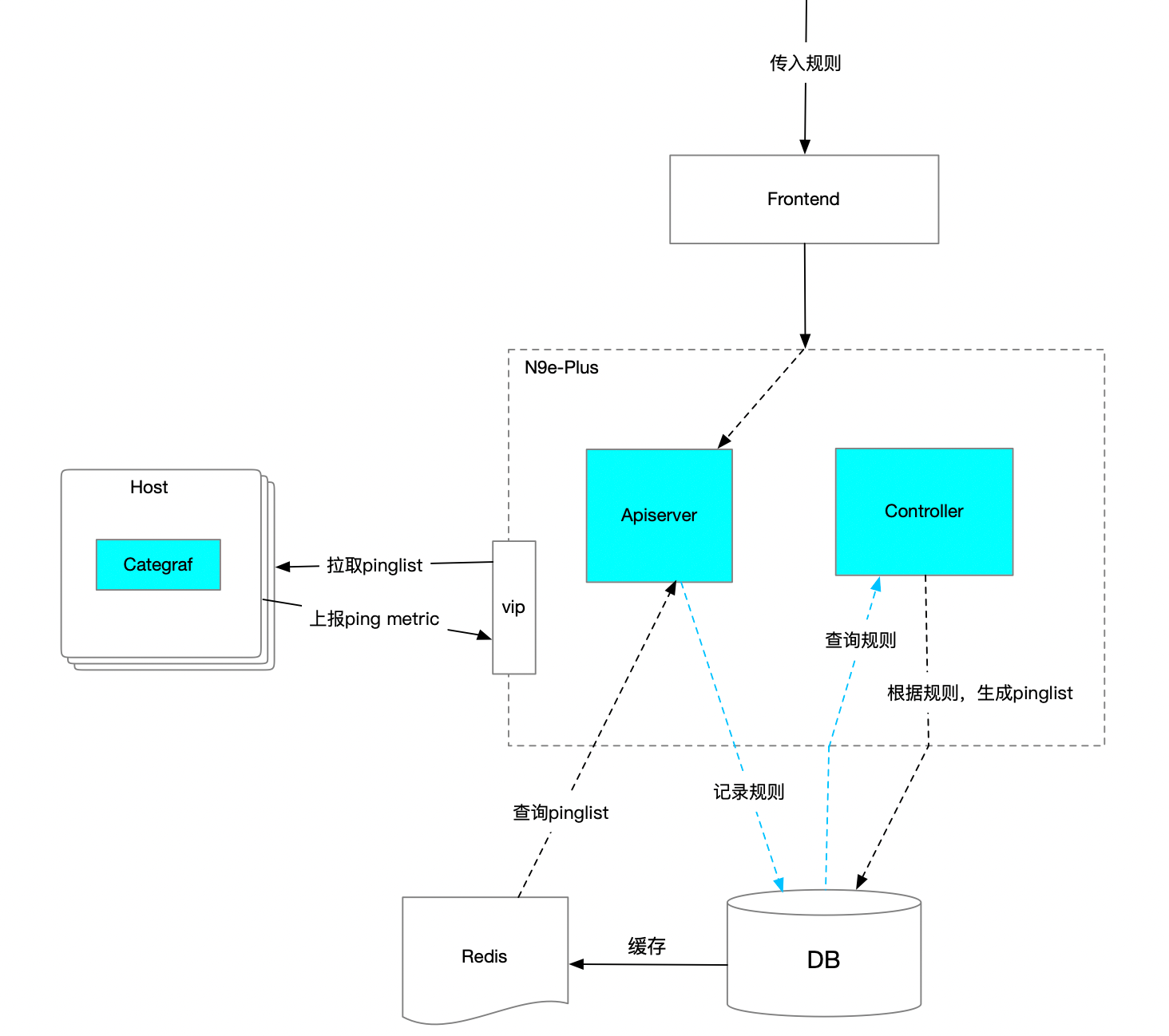
Apiserver
提供OpenApi:
- 用于注冊、變更、查詢數據中心原信息、探測規則(如:數據中心、探測協議、Tor交換機CIDR/機柜名、機器IP和機器名(機柜方式)、 探測百分比設置、數據中心之間探測規則設置 )。
- 數據中心三層結構拓撲圖展示,以及歷史探測曲線圖、報警規則配置、一鍵降級等API。
- 提供給Categraf使用的查詢pinglist接口。
Controller
生成pinglist的核心控制器邏輯,它需要定時從DB中查詢最新的配置和規則,判斷是否有發生變更,如果發生變更則重新執行pinglist生成邏輯。 從DB中查到配置后,判斷是機柜模式還是交換機模式,因為這兩種方式,其篩查Server IP的邏輯會有差異,之后需計算出每個數據中心,待探測的機柜或交換機是哪些,以及其下的Server Ip分別是多少,做好數據準備工作。接下來查看探測規則(數據中心內、數據中心之間),根據這些規則我們對每一臺發起探測的Server 生成探測配置,并記錄到DB中(因為我們底層真正執行探測任務的是Categraf Agent,需根據不同協議所使用的插件,生成不同的配置文件)。
此外,我們需新起一個協程,定時去對比新用戶配置和已生成的pinglist是否一致,因為可能在我們生成新的pinglist后的一段時間內,用戶變更或新增、刪除了數據中心配置和規則,那需要將已生成的pinglist進行對比清理,避免用戶配置變更后,依舊使用老的配置去探測,導致數據不準問題。
實現過程中還需要考慮另一個問題,數據中心有很多機器,但不是所有機器都裝有categraf,或裝有categraf但進程退出了等情況,如果我們只是單純地按所有的機器數量去篩選一堆Server IP,那很有可能選出的機器都沒有裝agent,那也就無法進行探測和發現問題了,因此我們需要結合categraf自身的心跳上報的能力,來過濾出可用的Server IP。到了這里,我們可能會想到另一個問題,因為我們是按比例篩選機器的,而當某臺機器down掉后,原本選了10臺,現在只有9臺可用機器了,這就會和用戶配置的參與探測的服務器比例出現diff。出現這種情況,那我們就需要重新選一臺可用機器補上去。當選擇出來這批機器后,后面都需要一直用這些機器,除非遇到重新選的情況,這樣可以保障我們指標量是固定的,同時也能滿足探測的比例需求。
探測Agent
Pingmesh底層真正執行探測邏輯的是我們的Categraf,它是一個開源的項目,插件豐富、配置簡單,這里就不做過多介紹了,大家可在github上搜索下即可。Categraf 會定時來中心端拉取本機的采集插件配置,當然,可能部署categraf的集群很多,這里中心端會將配置文件緩存到Redis中,降低對DB的查詢壓力,并提升接口查詢效率。最終categraf會拿到最新的插件配置并進行探測,之后將探測結果上報給中心端,用于數據展示和報警配置使用。
額外說一點,如果存在邊緣機房,那categraf可以將探測結果上報給邊緣機房的 n9e-edge 模塊,之后報警就可在這邊緣機房內部閉環了,而且edge 會自動將指標轉發給時序庫,用于頁面展示使用。
小結
Pingmesh 在復雜網絡問題的排查中發揮了巨大的作用,本文分享了 Pingmesh 的實現思路,歡迎大家?聯系我們試用。




)
SpringBoot整合WebMvc(二)DispatcherServlet的工作全流程)






)






