大數據技術概述
大數據技術層面及其功能
數據采集與預處理
- 利用ETL(extract-transform-load)工具將分布的、異構數據源中的數據,如關系數據、平面數據文件等,抽取到臨時中間層后進行清洗、轉換、集成,最后加載到數據倉庫或數據集市中,成為聯機分析處理、數據挖掘的基礎;
- 利用日志采集工具把實時采集的數據作為流計算系統的輸入,進行實時處理分析;
- 利用網頁爬蟲程序到互聯網網站中爬取數據。
數據存儲和管理
利用文件系統、關系數據庫、數據倉庫、并行數據庫,分布式文件系統、NoSQL數據庫、NewSQL數據庫等,實現對結構化、半結構化、非結構化數據的存儲和管理。
數據處理與分析
利用分布式并行編程模型和計算框架,結合機器學習和數據挖掘等算法,實現對海量數據的處理和分析。
數據可視化
對分析結果進行可視化呈現,幫助人們更好地理解數據、分析數據。
數據安全和隱私保護
在從大數據中挖掘潛在的巨大商業價值和學術價值的同時,構建隱私數據保護體系和數據安全體系,有效保護個人隱私和數據安全。
數據采集與預處理
數據采集
定義:數據采集,又稱數據獲取,是利用一種裝置,從系統外部采集數據并輸入到系統內部的一個接口。
過程:它通過各種技術手段把外部各種數據源產生的數據進行實時或非實時地采集,獲得各種類型的結構化、半結構化以及非結構化的海量數據并加以利用。
數據分類
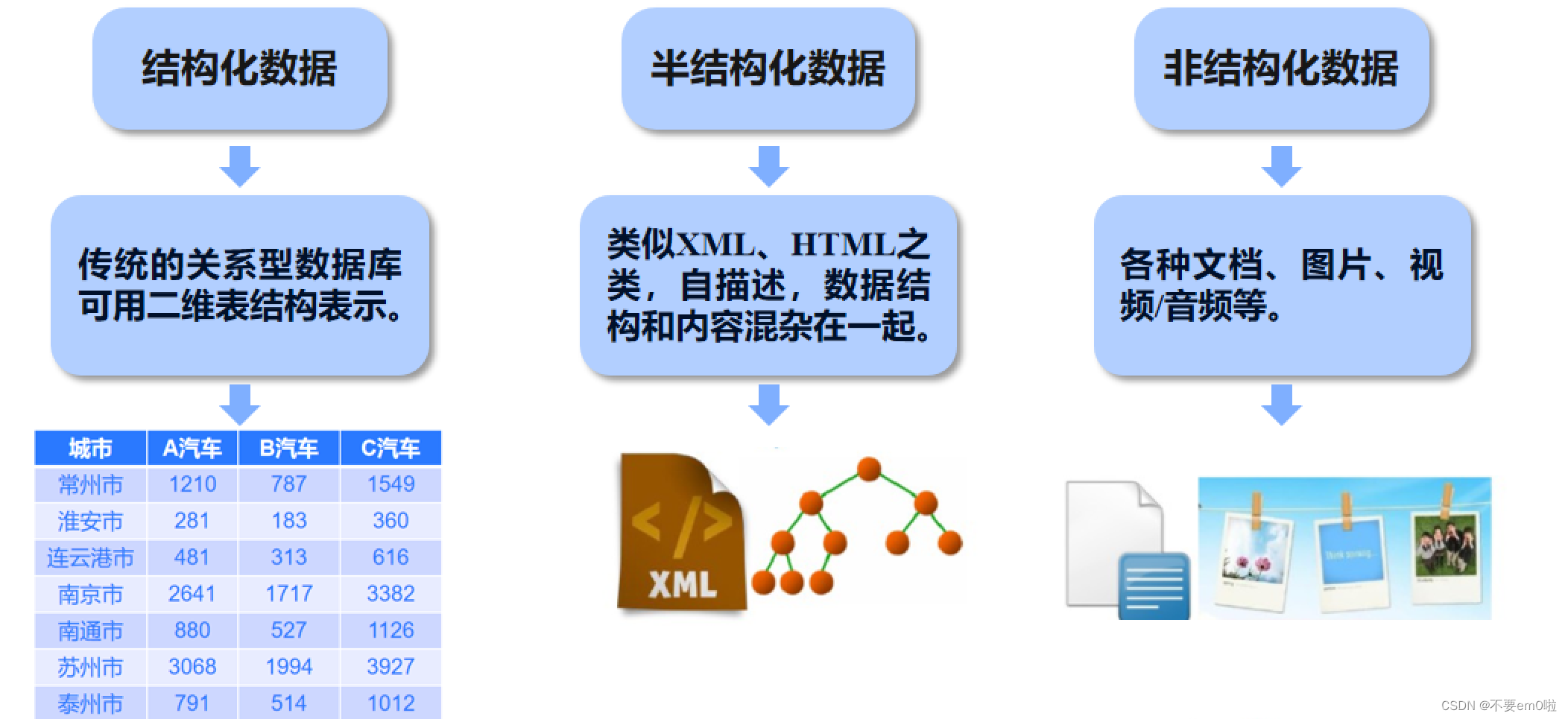
?數據采集方式
大數據的采集通常采用多個數據庫來接收終端數據,包括智能硬件端、多種傳感器端、網頁端、移動APP應用端等,并且可以使用數據庫進行簡單的處理工作。
數據采集數據源
- 數據源: 企業業務系統數據:企業產生的業務數據,以數據庫一行記錄的形式,被直接寫入到數據庫中。企業使用傳統的關系數據庫MySQL和Oracle,或Redis和MongoDB這樣的NoSQL數據庫來存儲業務系統數據。
- 傳感器:是一種檢測裝置,能感受到被測量的信息,并轉化為其他形式的信息輸出,以滿足信息的傳輸、處理、存儲、顯示、記錄和控制等要求。
- 日志文件:日志文件系統一般由數據源系統產生,用于記錄數據源的執行的各種操作活動。比如網絡監控的流量管理,金融應用的股票記賬和Web服務器記錄的用戶訪問行為。
- 互聯網數據:互聯網數據采集是借助網絡爬蟲來實現的,通過對網頁數據的定向抓取。數據存儲與管理
數據采集要點
- 全面性:數據量大具有分析價值;數據面全,支撐分析需求。比如對于“查看商品詳情”這一行為,需要采集用戶觸發時的環境信息、會話、以及背后的用戶id,最后需要統計這一行為在某一時段觸發的人數、次數、人均次數、活躍比等。
- 多維性:靈活、快速自定義數據的多重屬性和不同類型,滿足不同的分析目標。比如“查看商品詳情”這一行為,通過埋點,我們才能知道用戶查看的商品是什么、價格、類型、商品id等多個屬性。從而知道用戶看過哪些商品、什么類型的商品被查看的多、某一個商品被查看了多少次。而不僅僅是知道用戶進入了商品詳情頁。
- 高效性:高效性包含技術執行的高效性、團隊內部成員協同的高效性、數據分析需求和目標實現的高效性。還要考慮數據的及時性。
數據清洗
數據清洗是指將大量原始數據中的錯誤信息“洗掉”,它是發現并糾正數據文件中可識別的錯誤的最后一道程序,包括:一致性檢查、無效值和缺失值處理等。
需要清洗的數據的主要類型: 殘缺數據、錯誤數據、重復數據。
數據清洗的內容
- 一致性檢查:根據每個變量的合理取值范圍和相互關系,檢查數據是否合乎要求,發現超出正常范圍、邏輯上不合理或者相互矛盾的數據。
- 無效值和缺失值的處理:由于調查、編碼和錄入誤差,數據中可能存在一些無效值和缺失值,需要給予適當的處理。
無效值和缺失值的處理方法
- 整例刪除:適合關鍵變量缺失,或者含有無效值或缺失值的樣本比重很小的情況。
- 變量刪除:如果某一變量的無效值和缺失值很多,且對研究內容的不是很重要,該變量可以刪除。
- 成對刪除:用一個特殊碼代表無效值和缺失值,同時保留數據集中的全部變量和樣本。
- 估算: 統計法:對于數值型的數據(連續值),使用均值、加權均值、中位數等方法補足;對于分類型數據(離散值),使用類別眾數最多的值補足。
- 模型法:基于已有的字段,將缺失字段作為目標變量進行預測,從而得到最為可能的補全值。如果帶有缺失值的列是數值變量(連續值),采用回歸模型補全;如果是分類變量(離散值),則采用分類模型補全。
- 專家補全:對于少量且具有重要意義的數據記錄,專家補足也是非常重要的一種途徑。
- 其他方法:例如隨機法、特殊值法、多重填補等。

)
:右側屬性欄(字體、字號、行間距))











和with是干嘛的)




