
一、引言
在當今競爭激烈的汽車行業中,售后服務的質量已成為品牌成功的關鍵因素之一。作為一位經驗豐富的項目經理,我曾參與構建一個全面的汽車售后服務網絡,旨在為客戶提供無縫的維修、保養和配件更換服務。這個項目的核心目標是通過高效的服務流程和客戶關懷,提升客戶滿意度并增強品牌忠誠度。信息抽取技術的應用,使得我們能夠從大量數據中提取有價值的客戶洞察,從而優化服務流程和響應策略。通過這種方式,我們不僅維護了品牌形象,而且建立了一個強大的客戶關系網絡,為汽車制造商在市場中的長期成功奠定了基礎。
二、用戶案例
在項目初期,我們面臨了一個重大挑戰:如何高效地處理和分析客戶的反饋信息,以便快速響應他們的需求和解決問題。客戶反饋通常包含大量的非結構化數據,如電子郵件、社交媒體帖子和客服記錄。這些數據中蘊含著豐富的信息,但需要先進的技術來進行有效的提取和分析。信息抽取技術正好滿足了這一需求,它使我們能夠自動從文本中識別出關鍵參數、屬性、實體和事件,從而加快了我們對客戶反饋的處理速度。
例如,在分析客戶對某款新車的反饋時,我們使用參數抽取技術識別出了客戶的里程數、車輛使用時間和維修頻率等數據。這些數據幫助我們發現了一個潛在的質量問題:車輛在特定里程數后出現故障的概率顯著增加。通過進一步的屬性抽取,我們發現這一問題與車輛的特定部件材質有關。有了這些詳細信息,我們能夠及時通知生產線進行調整,并為客戶提供免費的維修或更換服務。 在項目進行中,我們還面臨著如何快速識別并處理客戶的緊急維修請求的問題。信息抽取技術再次發揮了關鍵作用。
通過實體抽取,我們能夠迅速識別出客戶提到的車輛型號、故障描述和地理位置。這使得我們的服務團隊能夠立即響應,并且根據客戶的具體情況,為他們安排最近的服務中心或派遣移動維修團隊。此外,關系抽取技術幫助我們理解了客戶與服務流程之間的相互作用,使我們能夠優化服務流程,減少客戶等待時間。 項目后期,我們利用事件抽取技術來分析客戶在維修過程中的體驗。我們從中識別出了客戶在維修過程中的關鍵時間點,如預約時間、到店時間和維修完成時間。通過這些信息,我們能夠評估服務流程的效率,并發現可能導致客戶不滿的瓶頸。例如,我們發現某些服務中心在周末的預約過于集中,導致客戶等待時間過長。
基于這些發現,我們調整了預約系統,平衡了各個服務中心的預約分布,從而顯著提升了客戶的整體滿意度。 通過這些具體的應用實例,我們可以看到信息抽取技術在汽車制造和售后服務領域的巨大潛力。它不僅提高了我們的工作效率,還幫助我們更好地理解和滿足客戶的需求,最終實現了項目的長期目標。
三、技術原理
在汽車制造領域,信息抽取技術的應用正成為提升生產效率和質量控制的關鍵。深度學習技術,特別是自然語言處理(NLP)的進步,使得從復雜的生產數據中自動提取信息成為可能。通過預訓練語言模型,如BERT、GPT和XLNet,我們可以捕獲語言的深層結構和語義,為后續的信息處理打下堅實基礎。這些模型在大規模文本數據上經過訓練,能夠理解復雜的語言模式,為汽車制造過程中的信息處理提供了強大的支持。 針對特定的制造任務,預訓練模型需要進行微調,以適應特定的信息抽取需求。例如,在生產線上,實體識別(NER)可以幫助識別關鍵的組件和設備信息;關系抽取(RE)可以揭示組件之間的相互關系及其與生產流程的關聯;事件抽取(EE)則能夠從日志和報告中提取生產事件,如故障、維護和質量檢查。這些任務的微調通常涉及在特定領域的標注數據上進行訓練,使得模型能夠更準確地識別和理解與汽車制造相關的特定術語和概念。 序列標注技術在實體識別等任務中發揮著重要作用。

通過條件隨機場(CRF)或雙向長短時記憶網絡(BiLSTM),模型能夠對文本序列進行精確標注,識別出諸如部件編號、生產批次和質量標準等關鍵信息。這些技術能夠捕捉文本中的長距離依賴關系,確保即使在復雜的句子結構中也能準確識別出相關信息。 對于更復雜的任務,如生產流程的優化和故障診斷,序列到序列(Seq2Seq)模型,尤其是基于注意力機制的Transformer模型,被用來處理輸入序列并生成輸出序列。這些模型能夠理解生產數據的上下文信息,并生成有助于決策的輸出,如優化建議或故障原因分析。 整個信息抽取過程通常通過端到端訓練進行,這意味著從輸入到輸出的整個過程都在一個統一的訓練框架下進行優化。這樣的訓練方式有助于提高模型的整體性能,確保在實際應用中能夠快速準確地提取所需信息。
在模型訓練過程中,通過準確率、召回率、F1分數等指標對模型性能進行評估,并根據評估結果進行調整。這可能包括調整學習率、優化網絡結構或增加訓練數據,以提高信息抽取的準確性和可靠性。 在汽車制造項目中,信息抽取技術的應用不僅提高了生產效率,還有助于質量控制和故障預防。通過自動分析生產數據,我們能夠及時發現潛在的質量問題,優化生產流程,減少浪費,確保每一臺出廠的汽車都符合最高標準。此外,這些技術還能夠幫助項目經理更好地理解生產過程中的各種動態,從而做出更明智的決策,推動項目順利進行。
四、技術實現
在處理項目的技術原理部分時,由于涉及到的自然語言處理(NLP)技術較為復雜,為了確保項目的順利進行,我選擇使用了一個現成的NLP平臺。這個平臺提供了一整套的NLP工具和服務,幫助我在不需要深入了解底層技術細節的情況下,快速實現數據的標注、模型訓練和預測。 首先,我進行了數據收集,收集了與項目相關的數據樣本,這些樣本覆蓋了各種可能的情況。接著,我對這些數據進行了清洗,確保數據質量。在數據清洗的基礎上,我使用平臺提供的在線標注工具對數據進行了標注,這個過程包括了實體、關系等的標記,確保了標注的一致性和質量。 在樣本標注完成后,我根據標注的數據提取了文本特征,如詞性標注、命名實體識別(NER)和依存句法分析等,并使用這些數據訓練了模型。在模型訓練過程中,我通過調整模型參數來優化性能,并進行了多次迭代。 為了確保模型的性能,我選擇了合適的評估指標,如精確度、召回率和F1分數等,對模型進行了評估。通過交叉驗證等方法,我確保了模型具有良好的泛化能力,并根據評估結果對模型進行了調整。 最后,我將訓練好的模型部署到了生產環境中,以便對新的文本數據進行信息抽取。模型能夠自動執行信息抽取任務,并輸出結構化的結果。所有這些步驟都可以通過平臺的Web界面完成,我無需編寫任何代碼。 此外,我還可以通過Python代碼調用接口,實現訓練和預測的結果。這為我在項目中提供了極大的便利,讓我能夠專注于項目管理和業務邏輯,而不是深入研究技術細節。通過這種方式,我有效地利用了NLP技術,提升了項目的效率和效果。
信息抽取代碼實現
在構建汽車售后服務網絡的過程中,我利用了平臺的信息抽取功能來優化服務流程和提升客戶滿意度。以下是我使用該功能的偽代碼示例:
# 設置請求參數headers = {'secret-id': '你的密鑰','secret-key': '你的密鑰'}data = {'text': '提供汽車維修、保養、配件更換等售后服務的相關文本內容。','sch': '汽車維修,保養,配件更換','modelID': '選擇或創建的模型ID'}# 發送POST請求response = post('https://nlp.stonedt.com/api/extract', headers=headers, json=data)# 解析返回的JSON數據if response.status_code == 200:result = response.json()# 輸出抽取結果print("抽取的保養信息:")for movie in result['result'][0]['實體']:print(f"名稱:{movie['text']}, 起始位置:{movie['start']}, 結束位置:{movie['end']}, 準確率:{movie['probability']}")print("\n抽取的維修信息:")for director in result['result'][0]['關系']:print(f"名稱:{director['text']}, 起始位置:{director['start']}, 結束位置:{director['end']}, 準確率:{director['probability']}")# ... 其他抽取結果的輸出else:print("請求失敗,狀態碼:", response.status_code)在這個偽代碼中,我們通過設置請求頭和請求參數,向平臺的API發送了一個POST請求。請求的目的是抽取文本中關于汽車維修、保養、配件更換的相關信息。平臺返回的JSON數據包含了抽取結果的詳細信息,包括文本內容、起始和結束位置以及準確率。我們通過解析這些數據,可以將非結構化的文本信息轉換為結構化的輸出,進而用于優化我們的服務流程和響應策略。
通過這種方式,信息抽取技術幫助我們在處理大量客戶反饋和維修記錄時,快速定位到關鍵信息,提高了服務效率,并確保了客戶問題能夠得到及時和準確的解決。這不僅提升了客戶滿意度,也為品牌忠誠度的建立提供了堅實的基礎。
數據庫表設計
-- 創建維修記錄表
CREATE TABLE MaintenanceRecords (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '維修記錄唯一標識',vehicle_id INT NOT NULL COMMENT '車輛唯一標識',customer_id INT NOT NULL COMMENT '客戶唯一標識',service_center_id INT NOT NULL COMMENT '服務中心唯一標識',maintenance_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '維修日期',mileage INT COMMENT '維修時里程數',issue_description TEXT COMMENT '問題描述',maintenance_type ENUM('Repair', 'Checkup', 'PartsReplacement') COMMENT '維修類型',status ENUM('Pending', 'InProgress', 'Completed', 'Cancelled') COMMENT '維修狀態',estimated_cost DECIMAL(10, 2) COMMENT '預計成本',actual_cost DECIMAL(10, 2) COMMENT '實際成本',technician_id INT COMMENT '維修技師唯一標識',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '記錄創建時間',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '記錄更新時間') COMMENT '維修記錄表';-- 創建客戶表
CREATE TABLE Customers (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '客戶唯一標識',name VARCHAR(255) NOT NULL COMMENT '客戶姓名',email VARCHAR(255) COMMENT '客戶郵箱',phone_number VARCHAR(20) COMMENT '客戶電話號碼',address TEXT COMMENT '客戶地址',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '記錄創建時間',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '記錄更新時間') COMMENT '客戶表';-- 創建服務中心表
CREATE TABLE ServiceCenters (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '服務中心唯一標識',name VARCHAR(255) NOT NULL COMMENT '服務中心名稱',address TEXT COMMENT '服務中心地址',phone_number VARCHAR(20) COMMENT '服務中心電話號碼',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '記錄創建時間',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '記錄更新時間') COMMENT '服務中心表';-- 創建維修技師表
CREATE TABLE Technicians (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '維修技師唯一標識',name VARCHAR(255) NOT NULL COMMENT '技師姓名',phone_number VARCHAR(20) COMMENT '技師電話號碼',service_center_id INT COMMENT '所屬服務中心唯一標識',created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '記錄創建時間',updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '記錄更新時間',FOREIGN KEY (service_center_id) REFERENCES ServiceCenters(id) ON DELETE SET NULL ON UPDATE CASCADE COMMENT '技師所屬服務中心外鍵') COMMENT '維修技師表';五、項目總結
在本項目中,我們成功構建了一個高效的汽車售后服務網絡,通過信息抽取技術的應用,我們實現了以下具體效益和效果:
- 顯著提升了客戶反饋處理的效率。通過自動化的文本分析,我們能夠在短時間內從大量非結構化數據中提取關鍵信息,從而快速響應客戶需求,減少了客戶等待時間。例如,質量問題的及時發現和處理,避免了潛在的大規模召回,節約了成本并維護了品牌形象。
- 優化了服務流程,提高了服務質量。信息抽取技術幫助我們理解客戶與服務流程的相互作用,我們據此調整了預約系統,平衡了服務中心的預約分布,顯著提升了客戶滿意度。此外,通過對維修過程中關鍵時間點的分析,我們發現了服務流程中的瓶頸,并采取了相應措施進行優化。
- 強化了客戶關系管理。通過分析客戶反饋和維修記錄,我們能夠更好地理解客戶需求,為他們提供個性化的服務,增強了客戶的忠誠度。同時,這些數據為市場分析提供了寶貴信息,幫助我們更好地定位市場策略,提升品牌競爭力。
- 提升了生產效率和質量控制。在生產過程中,信息抽取技術的應用使我們能夠自動分析生產數據,及時發現潛在的質量問題,優化生產流程,減少浪費。這不僅確保了出廠汽車的質量,也為項目經理提供了實時的生產監控,使得項目決策更為高效。
- 技術實現的便捷性。我們采用了現成的NLP平臺,使得整個信息抽取過程無需深入了解底層技術細節,就可以快速實現。這大大減輕了技術團隊的負擔,使得團隊能夠專注于項目管理和業務邏輯,加速了項目的推進。
- 綜上所述,信息抽取技術在本項目中的應用不僅提高了工作效率,優化了服務和生產流程,還加強了客戶關系管理,為公司的長期發展奠定了堅實基礎。
六、開源項目(本地部署,永久免費)
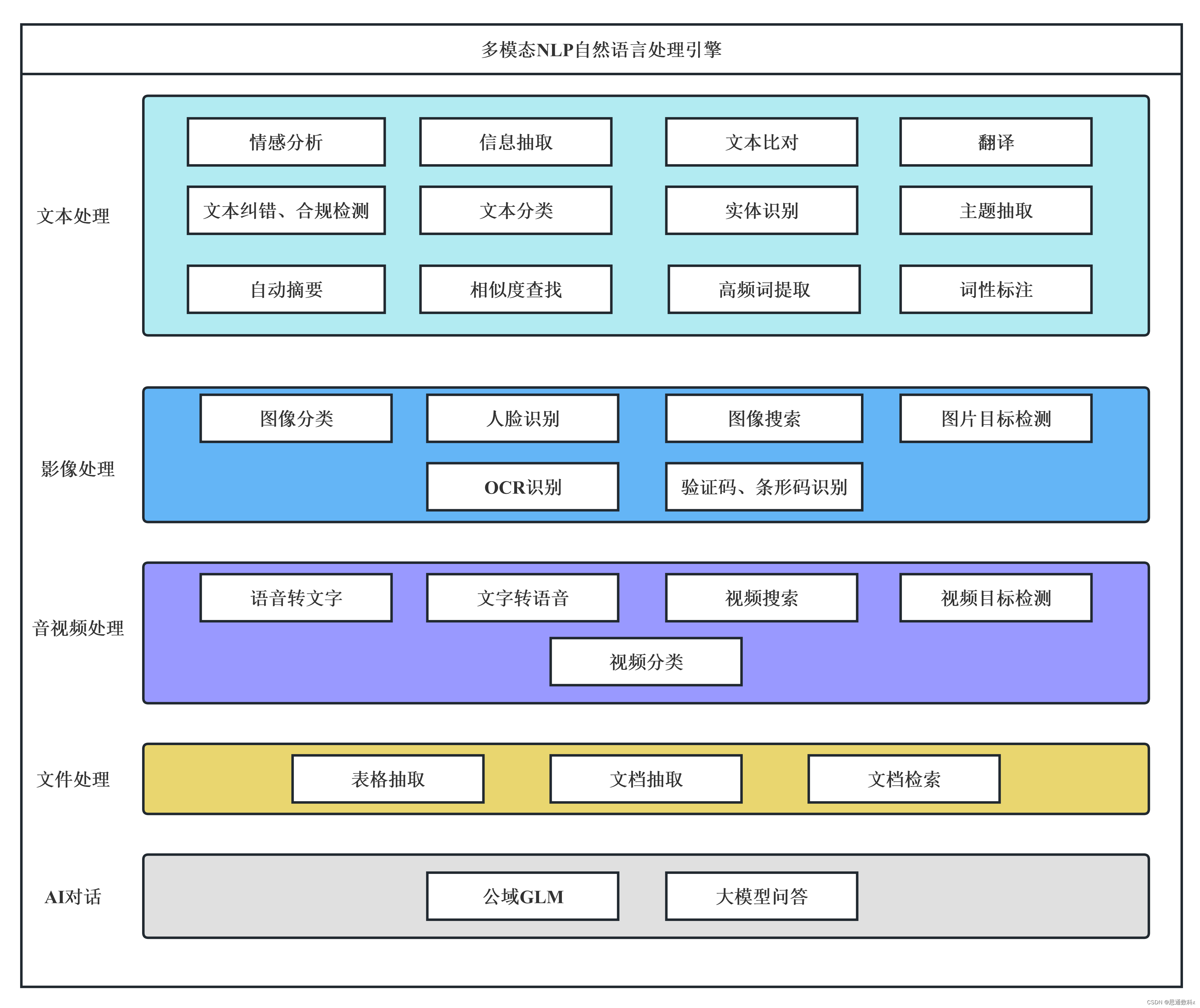
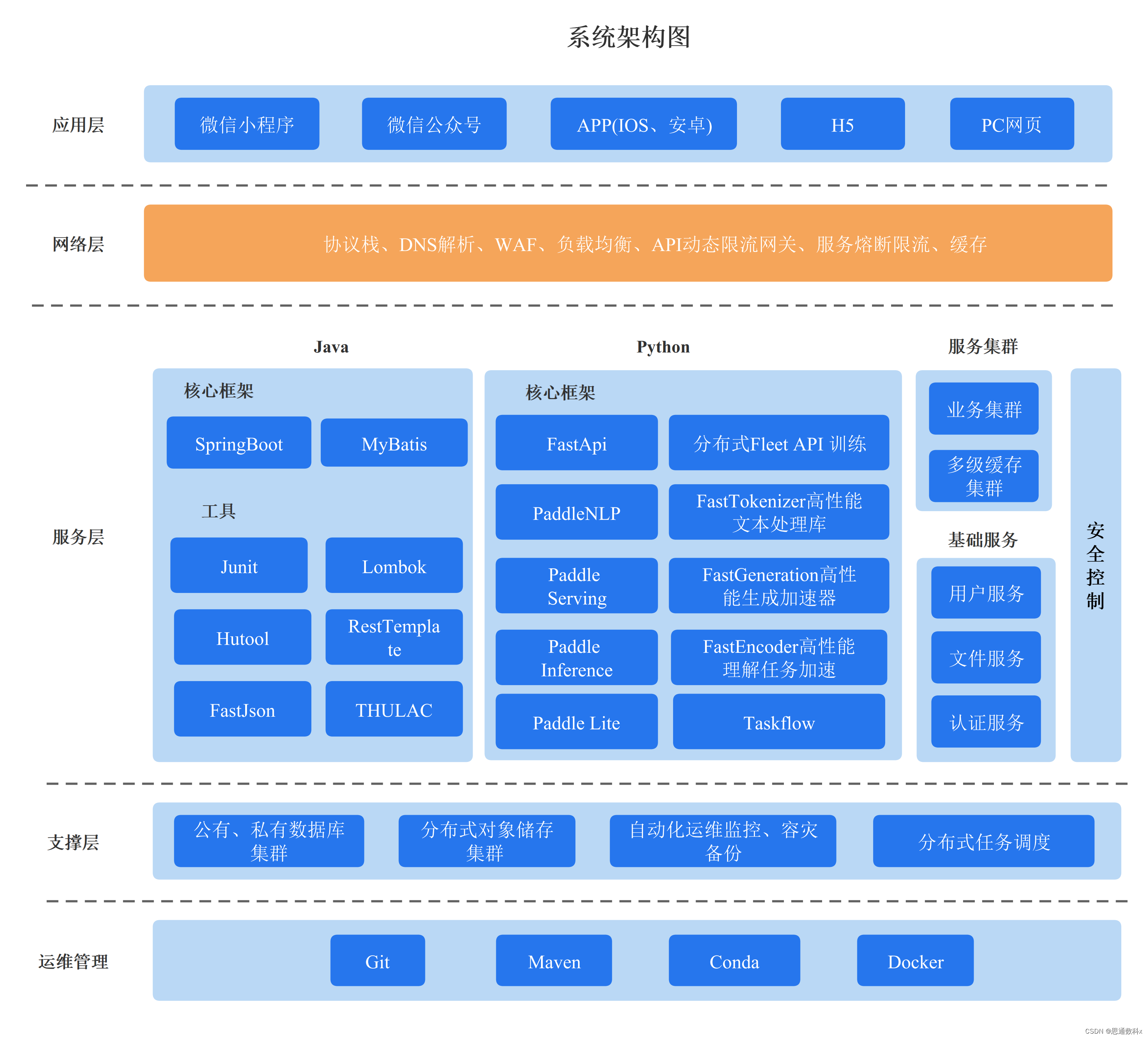
思通數科的多模態AI能力引擎平臺是一個企業級解決方案,它結合了自然語言處理、圖像識別和語音識別技術,幫助客戶自動化處理和分析文本、音視頻和圖像數據。該平臺支持本地化部署,提供自動結構化數據、文檔比對、內容審核等功能,旨在提高效率、降低成本,并支持企業構建詳細的內容畫像。用戶可以通過在線接口體驗產品,或通過提供的教程視頻和文檔進行本地部署。
思通數科多模態AI能力引擎平臺![]() https://nlp.stonedt.com多模態AI能力引擎平臺: 免費的自然語言處理、情感分析、實體識別、圖像識別與分類、OCR識別、語音識別接口,功能強大,歡迎體驗。
https://nlp.stonedt.com多模態AI能力引擎平臺: 免費的自然語言處理、情感分析、實體識別、圖像識別與分類、OCR識別、語音識別接口,功能強大,歡迎體驗。![]() https://gitee.com/stonedtx/free-nlp-api
https://gitee.com/stonedtx/free-nlp-api



)
(九))
)

)


和 Temporal Join)

狀態模式)






