主從架構
主從架構有什么用?
通過搭建MySQL主從集群,可以緩解MySQL的數據存儲以及訪問的壓力。
- 數據安全(主備):給主服務增加一個數據備份。基于這個目的,可以搭建主從架構,或者也可以基于主從架構搭建互主的架構。
- 讀寫分離(主從):對于大部分的Java業務系統來說,都是讀多寫少的,讀請求遠遠高于寫請求。這時,當主服務的訪問壓力過大時,可以將數據讀請求轉為由從服務來分擔,主服務只負責數據寫入的請求,這樣大大緩解數據庫的訪問壓力。
注意:我們不能對備份的的節點進行寫操作只能進行讀,我們寫入一定是寫入主節點 - 故障轉移-高可用:當MySQL主服務宕機后,可以由一臺從服務切換成為主服務,繼續提供數據讀
寫功能。
對于高可用架構,主從數據的同步也只是實現故障轉移的一個前提條件,要實現MySQL主從切換,
還需要依靠一些其他的中間件來實現。比如MMM、MHA、MGR。
主從架構原理
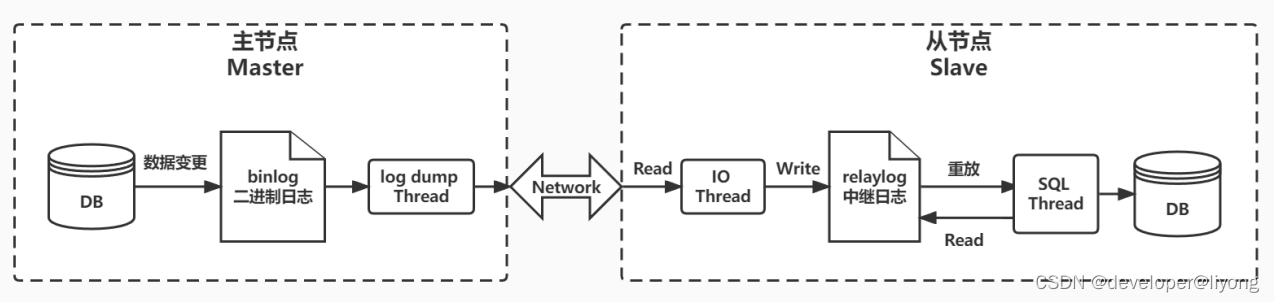
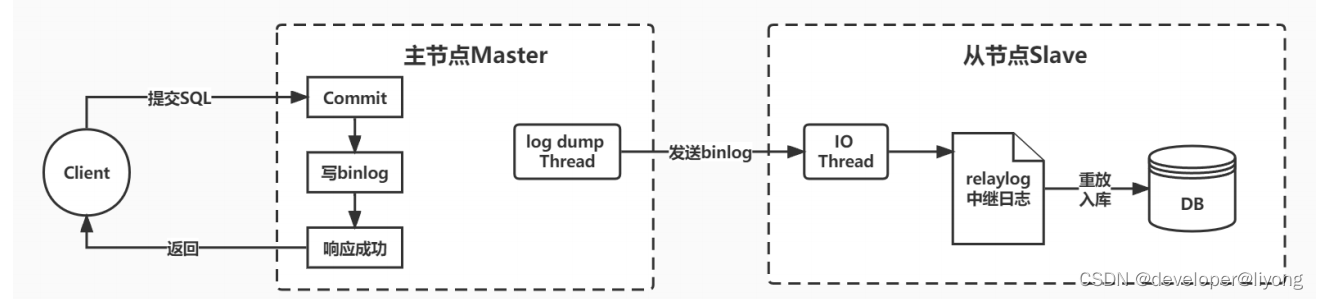
具體流程如下:
- 在主服務上打開binlog記錄每一步的數據庫操作
- 然后,從服務上會有一個IO線程,負責跟主服務建立一個TCP連接,請求主服務將binlog傳輸過來
- 這時,主庫上會有一個IO dump線程,負責通過這個TCP連接把binlog日志傳輸給從庫的IO線程
- 主服務器MySQL服務將所有的寫操作記錄在 binlog 日志中,并生成 log dump 線程,將 binlog 日志傳給從服務器MySQL服務的 I/O 線程。
- 接著從服務的IO線程會把讀取到的binlog日志數據寫入自己的relay日志文件中。
- 然后從服務上另外一個SQL線程會讀取relay日志里的內容,進行操作重演,達到還原數據的目的。
注意:
- 主從復制是異步的邏輯的 SQL 語句級的復制
- 復制時,主庫有一個 I/O 線程,從庫有兩個線程,即 I/O 和 SQL 線程
- 實現主從復制的必要條件是主庫要開啟記錄 binlog 的功能
- 作為復制的所有 MySQL 節點的 server-id 都不能相同
- binlog 文件只記錄對數據內容有更改的 SQL 語句,不記錄任何查詢語句
- 雙方MySQL必須版本一致,至少需要主服務的版本低于從服務
- 兩節點間的時間需要同步
主從復制形式
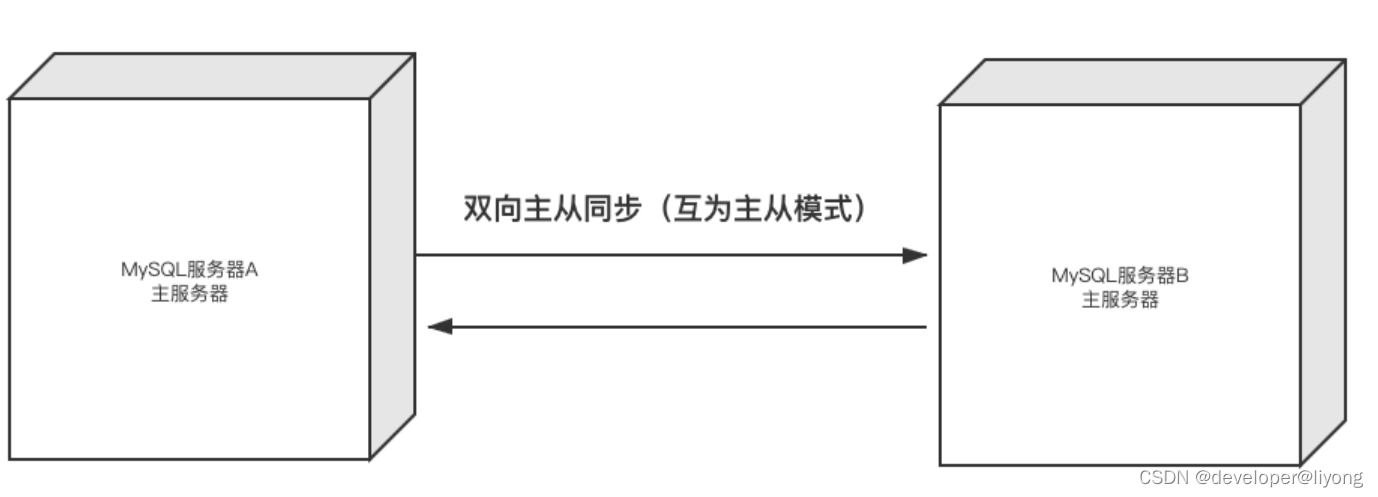
1 一主一從
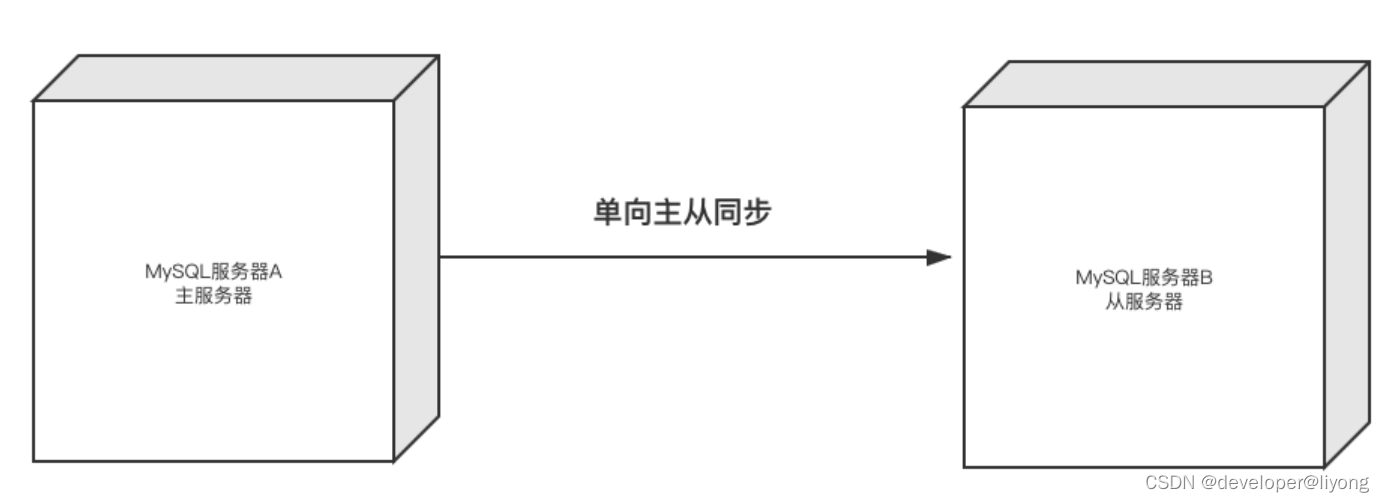
2 主主復制
存在數據一致性問題,可以提高讀寫能力。
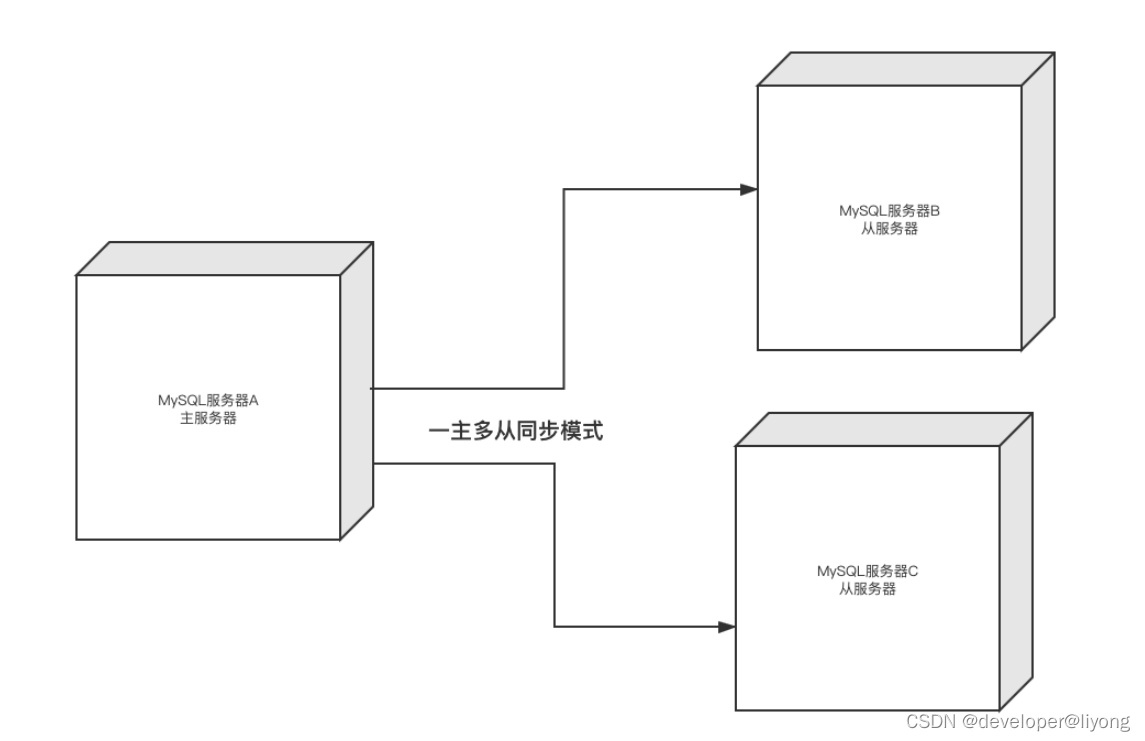
3 一主多從
4 多主一從(mysql5.7以后)
主一從的MySQL主從同步集群,具有了數據同步的基礎功能。而在生產環境中,通常會以此為基礎,根據業務情況以及負載情況,搭建更大更復雜的集群,掌握了一主一從的搭建方式,其它的方式就好弄了。
互主集群:我們也可以擴展出互為主從的互主集群甚至是環形的主從集群,實現多活部署。
5 聯級復制
降低主從同步的延遲,降低主服務器的壓力,因為同步也是要消耗資源的。

案例實戰
一主一從
首先配置主服務器
[mysqld]
# binlog刷盤策略
sync_binlog=1
# 需要備份的數據庫
binlog-do-db=hello
# 不需要備份的數據庫
binlog-ignore-db=mysql
# 啟動二進制文件
log-bin=mysql-bin
# 服務器ID
server-id=132
#設置錯誤日志輸出路徑
log-error=/var/lib/logs/log-err.log
log_warnings=1
#慢查詢相關日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#記錄沒有使用到索引的sql語句
log_queries_not_using_indexes=ON
創建用于同步的用戶
#需要保證mysql-slave 主機名能夠被解析
CREATE USER 'slave' @'mysql-slave' IDENTIFIED BY '654321';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave' @'mysql-slave';
docker run -d -p 3306:3306 -v $(pwd)/logs:/var/lib/logs -v $(pwd)/conf:/etc/mysql/conf.d -v $(pwd)/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=654321 --name mysql-master mysql:5.7
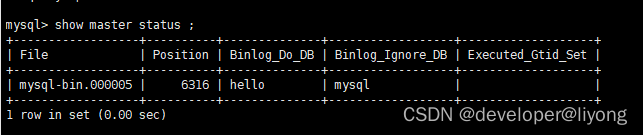
show master status;
創建從數據庫
[mysqld]
server-id=133
#設置錯誤日志輸出路徑
log-error=/var/lib/logs/log-err.log
log_warnings=1
#慢查詢相關日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#記錄沒有使用到索引的sql語句
log_queries_not_using_indexes=ON
#--link 這樣從數據庫可以直接和主數據庫通信 原理就是在從數據庫hosts文件里加了容器的端口映射并且和容器進行綁定
docker run -d -p 13306:13306 --link=mysql:msql-master -v $(pwd)/logs:/var/lib/logs -v $(pwd)/conf:/etc/mysql/conf.d -v $(pwd)/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=654321 --name mysql-slave mysql:5.7
change master to
master_host='myql-master',
master_port=3306,
master_user='slave',
master_password='654321',
master_log_file='mysql-bin.000004',
#這個值一定要填我上面 show master status 中的偏移值
master_log_pos=6316,
MASTER_AUTO_POSITION=0;
start slave;
show slave status \G;
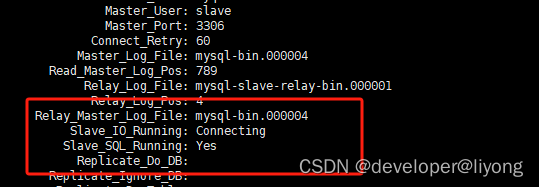
驗證這個時候我們去主庫間插入數據,就會被同步到從庫。
基于主從復制有這樣幾個問題:
1 如果我們部署的是一主多從,這個時候如果主節點掛掉了,需要從節點變為主節點是一件麻煩的事情,并且丟失了很多數據。
2 同步有延遲或者同步丟失。
基于GTID的主從復制
什么是GTID?
從 MySQL 5.6.5 開始新增了一種基于 GTID 的復制方式。GTID即全局事務ID (Global TransactionIdentifier),其保證每個主節點上提交的事務,在從節點可以一致性的復制。
這種方式強化了數據庫的主備一致性,故障恢復以及容錯能力。GTID在一主一從情況下沒有優勢,對于兩主以上的結構優勢異常明顯,可以在數據不丟失的情況下切換新主
GTID實際上是由UUID+TID (即transactionId)組成的,其中UUID(即server_uuid) 產生于auto.conf文件,是一個MySQL實例的唯一標識。TID代表了該實例上已經提交的事務數量,并且隨著事務提交單調遞增,所以GTID能夠保證每個MySQL實例事務的執行。GTID在一組復制中,全局唯一。 通過GTID的UUID可以知道這個事務在哪個實例上提交的。
GTID的優勢
- GTID相對于binlog+pos 復制數據安全性更高、failover更簡單、搭建主從復制更簡單
- 實現 failover不用像binlog+pos 復制那樣需要找 log_file 和 log_pos
- 一個 GTID 在一個node上只執行一次,避免重復執行導致數據混亂或者主從不一致
- 根據 GTID 可以快速的確定事務最初是在哪個實例上提交
- 使得 DBA 在運維中做集群變遷時更加方便
注意事項 - 在一個復制組中必須要求統一開啟GTID或是關閉GTID
- 主從庫的表存儲引擎必須是一致,不允許一個SQL同時更新一個事務引擎和非事務引擎的表
- MySQL在主從復制時如果要跳過報錯,可以采取以下方式跳過SQL(event)組成的事務,但GTID不支持以下方式(也就是說GTID不支持跳過報錯)
set global SQL_SLAVE_SKIP_COUNTER=1;
start slave sql_thread;
- 不支持下面語句的復制(主庫直接報錯)
create table….select
create temporary table
drop temporary table
GTID 主從復制原理
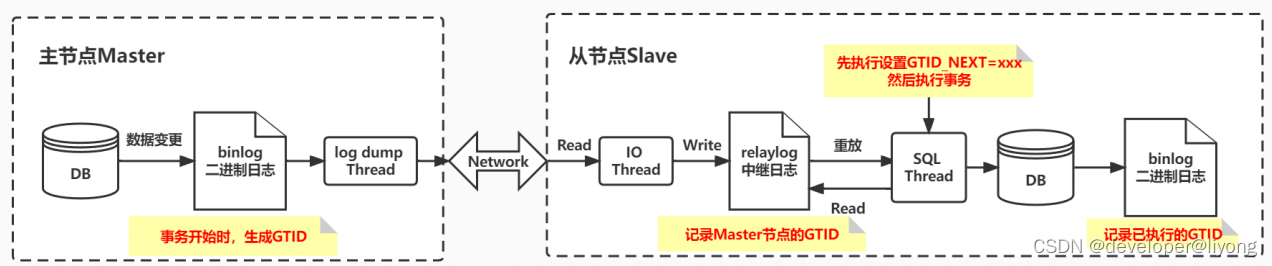
- Master更新數據時,會在事務前產生GTID一同記錄到binlog日志中
- Slave的IO Thread將變更后的binlog寫入到本地的relaylog中,這其中含有Master的GTID
- SQL Thread讀取這個 GTID 的值并設置 GTID_NEXT變量,告訴 Slave下一個要執行的 GTID 值,然后對比 Slave 端的 binlog 是否有該 GTID
- 如果有,說明該 GTID 的事務已經執行 Slave 會忽略
- 如果沒有,Slave 就會執行該 GTID 事務,并記錄該 GTID 到自身的 binlog
- 在解析過程中會判斷是否有主鍵,如果沒有就用二級索引,如果沒有二級索引就用全表掃描
在使用GTID的時候如果這個時候一主多從,切換從節點為主節點非常的方便,我們可以找到數據較為完整的Server。由于MASTER_AUTO_POSITION功能的出現,我們都不需要知道GTID的具體值,直接使用
CHANGE MASTER TO MASTER_HOST=‘xxx’,MASTER_AUTO_POSITION命令就可以直接完成failover的工作。
注意:在我們切換完Master以后不要在這個數據庫上進行一些操作,例如更新和刪除數據,因為這部分事務到時候會同步到從節點,萬一操作錯了,從節點的數據也被刷新了,容易導致數據出問題。
下面我們基于上面的一主一從來搭建GTID主從(直接搭建一主多從,需要重啟):
主節點的配置
[mysqld]
server-id=133
#設置錯誤日志輸出路徑
log-error=/var/lib/logs/log-err.log
log_warnings=1
#開啟gtid
gtid_mode=on
enforce_gtid_consistency=on
# 做級聯復制的時候,再開啟。允許下端接入slave
log_slave_updates=1
#慢查詢相關日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#記錄沒有使用到索引的sql語句
log_queries_not_using_indexes=ON#查看服務器的UUID
cat /var/lib/mysql/auto.cnf
#可以才看到GTID 是UUID + 事務ID
show master status;

從服務器
由于我們之前已經有數據了所以我們要,先把數據遷移過來。
#備份
mysqldump -u root -p --all-databases > backup.sql
#導入
mysql -uroot -p < backup.sql
[mysqld]
# binlog刷盤策略
sync_binlog=1
# 需要備份的數據庫
binlog-do-db=hello
# 不需要備份的數據庫
binlog-ignore-db=mysql
# 啟動二進制文件
log-bin=mysql-bin
# 服務器ID
server-id=132
#設置錯誤日志輸出路徑
log-error=/var/lib/logs/log-err.log
log_warnings=1
#慢查詢相關日志
log_output=FILE
slow_query_log=1
long_query_time=10
slow_query_log_file=/var/lib/logs/slow_query_log.log
#記錄沒有使用到索引的sql語句
log_queries_not_using_indexes=ON
gtid_mode=on
enforce_gtid_consistency=on
# 強烈建議,其他格式可能造成數據不一致
binlog_format=row
change master to
master_host='mysql-master',
master_port=3306,
master_user='slave',
master_password='654321',
MASTER_AUTO_POSITION=1;
另一個服務器一樣的操作,記得一定要修改server-id。接著去驗證是否同步即可。

半同步復制機制
1)異步復制
MySQL主從集群默認采用的是一種異步復制的機制。
主服務在執行用戶提交的事務后,寫入binlog日志,然后就給客戶端返回一個成功的響應了。而binlog
會由一個dump線程異步發送給Slave從服務。由于這個發送binlog的過程是異步的。主服務在向客戶端
反饋執行結果時,是不知道binlog是否同步成功了的。這時候如果主服務宕機了,而從服務還沒有備份
到新執行的binlog,那就有可能會丟數據。
2)半同步復制
半同步復制機制是一種介于異步復制和全同步復制之前的機制。
主庫在執行完客戶端提交的事務后,并不是立即返回客戶端響應,而是等待至少一個從庫接收并寫到relaylog中,才會返回給客戶端。
MySQL在等待確認時,默認會等 10 秒,如果超過10秒沒有收到ack,就會降級成為 異步復制 。
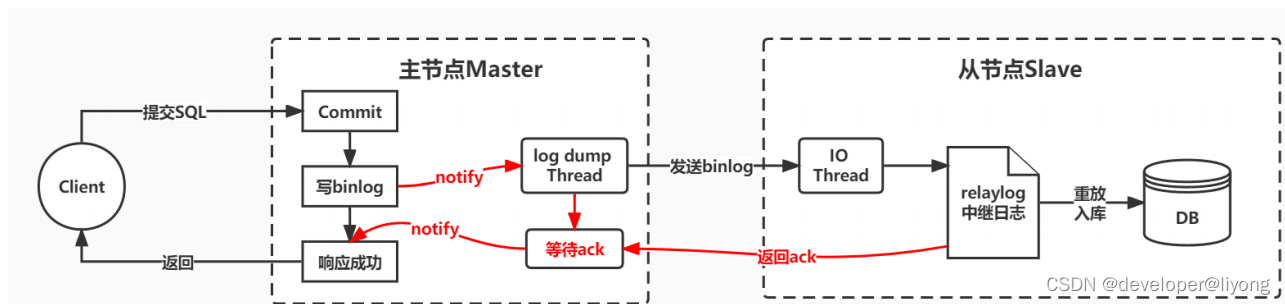
這種半同步復制相比異步復制,能夠有效的提高數據的安全性。但是這種安全性也不是絕對的,他只保證事務提交后的binlog至少傳輸到了一個從庫,且并不保證從庫應用這個事務的binlog是成功的。另一方面,半同步復制機制也會造成一定程度的延遲,這個延遲時間最少是一個TCP/IP請求往返的時間。整個服務的性能是會有所下降的。而當從服務出現問題時,主服務需要等待的時間就會更長,要等到從服務的服務恢復或者請求超時才能給用戶響應。
案例搭建
我們基于上面的GTID一主兩從來搭建,只需要在這個基礎上加上半同步機制就行。
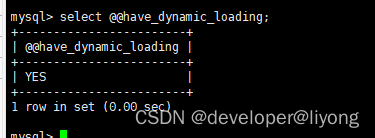
#查看當前數據庫是否支持 版同步機制
select @@have_dynamic_loading;
#查看插件的位置
show variables like 'plugin_dir';
安裝插件
主機節點
install plugin rpl_semi_sync_master soname 'semisync_master.so';
#查看半同步機制的參數
show global variables like 'rpl_semi%';
#開半同步機制
set global rpl_semi_sync_master_enabled=ON;
# 單位是毫秒,可動態調整,表示主庫事務等待從庫返回commit成功信息超過30秒就降為異步模式,
set global rpl_semi_sync_master_timeout=30000;
#查看插件是否搭建成功了
select * from mysql.plugin;
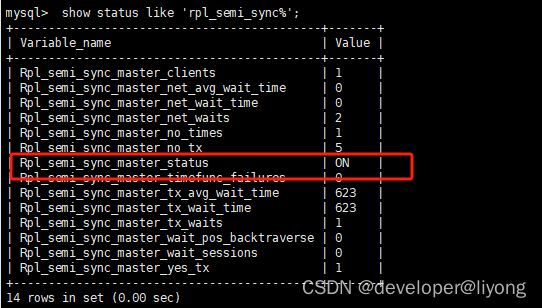
#監控狀態
show status like 'rpl_semi_sync%';

半同步復制有兩種方式,rpl_semi_sync_master_wait_point通過這個參數指定:
- AFTER_SYNC 方式:默認,主庫把日志寫入binlog并且復制給從庫,然后開始等待從庫的響應。從庫返回成功后,主庫再提交事務,接著給客戶端返回一個成功響應性能更差,安全性更好。
- AFTER_COMMIT 方式:主庫把日志寫入binlog并且復制給從庫,主庫就提交自己的本地事務,再等待從庫返回給自己一個成功響應,等到響應后主庫再給客戶端返回響應。性能更好,安全性較差區別:提交事務的時機不同。
安裝從節點的插件
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
#開啟半同步
set global rpl_semi_sync_slave_enabled = on;
#監控狀態
show status like 'rpl_semi_sync%';
驗證停止其中的一個節點
stop slave io_thread;
#下面插入一條數據然后看半同步狀態
#恢復
start slave;
(九))
)

)


和 Temporal Join)

狀態模式)







![[嵌入式系統-36]:龍芯1B 開發學習套件 -5- PMON常見命令](http://pic.xiahunao.cn/[嵌入式系統-36]:龍芯1B 開發學習套件 -5- PMON常見命令)
內存文件)

)