💕"Echo"💕
作者:Mylvzi
文章主要內容:JVM內部世界(內存劃分,類加載,垃圾回收)

關于JVM的學習主要掌握三方面:
- JVM內存區的劃分
- 類加載
- 垃圾回收
一.JVM內存區的劃分
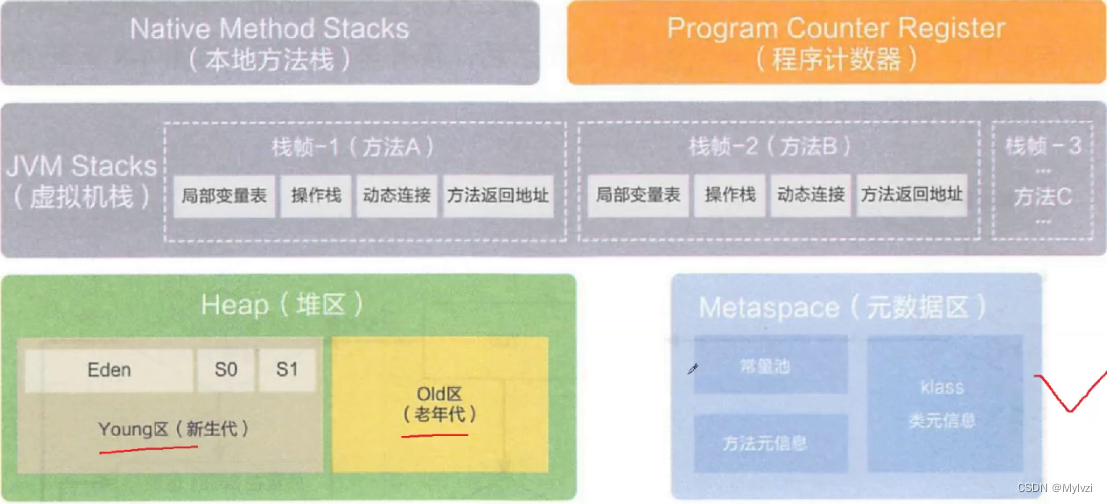
當一個Java進程開始執行時,JVM會首先向操作系統申請一塊較大的內存來提供進程在執行過程中所需的空間,而JVM為了更加高效,規范化的管理數據,將這塊內存劃分為5個區域
- 方法區/元數據區
- 棧區
- 堆區
- 程序計數器
- 本地方法區
1.方法區/元數據區
主要存放與
類相關的信息,如靜態變量,方法等
Java中的一個(.class)文件在運行時就會被加載為一個類對象,類對象中包含與類相關的數據和方法,這些信息都被存儲到元數據區(方法區)中
2.堆區
存放實例化的對象(new)
存儲實例化出的對象,包括對象中包含的實例變量(成員變量)
注:實例方法是存儲在方法區之中的,屬于類對象的信息
3.程序計數器
存放進程在執行過程中的
字節碼指令在方法區的地址或者當前正在執行的方法的地址
程序計數器是JVM內存中占用內存比較小的一部分區域,當一個Java進程運行時,文件中包含的代碼就都被轉化為字節碼指令,字節碼指令是JVM可以識別和執行的最小單位,通過字節碼指令來完成代碼中的邏輯
程序計數器的一個很大的用途是用在多線程之中,一個進程包含多個線程,每一個線程都有自己的私有的程序計數器,用于存儲當前線程的執行指令,當由一個線程跳轉到另一個線程時,需要保存當前線程的執行的指令的位置,以便跳轉回該線程時能夠繼續執行代碼,程序計數器就起到了這樣的作用,由此也可以看出,程序計數器也是線程安全的
4.棧區
用于存放局部變量和方法的調用關系,每調用一次方法,就會在棧區中創建出棧幀,來表示一個方法調用,隨著方法的執行完畢,棧幀又會從棧區之中脫離(出棧)
5.本地方法區
存儲本地方法
在Java中,有很多方法的底層是通過C++進行編寫的,在源碼中我們無法看到背后的具體執行邏輯,但是在開發中也會使用,所以就劃分出本地方法區專門存儲這些方法
一個經典面試題:
分別說出一下三個變量在內存中的位置
class Test {public int a;public static int b;
}Test t = new Test();
- a:通過new Test()創建,和new出來的對象一樣位于堆區之中(成員變量)
- b:靜態變量,位于方法區
- t:引用變量,位于棧區之中
注意:
Test t = new Test();
t并不是我們實例化出的對象,而是一個引用,真正的對象是在堆區中存儲的,t就類似于C語言中的指針,用于指向實例化的對象,但t本身并不是對象,僅僅是一個引用類型的變量
總結:
每個線程都有自己私有的棧空間和程序計數器,同一個進程里的所有線程共用方法區和堆區
找到垃圾的方式有兩種:
- 引用計數
- 可達性分析
可達性分析的核心是通過一組線程周期性的掃描所有的對象,在一次掃描過程中,如果掃描到了對應的對象,就標記為可達,表示該對象仍然存在,如果沒有掃描到,JVM就會執行回收
內部是通過一個N叉樹的方式來組織各種對象的,通過掃描這棵樹的方式來進行可達性的分析
二.類加載
類加載部分主要掌握兩部分:
- 類加載的過程
- 雙親委派模型
1.類加載過程
類加載就是
.class文件被JVM轉換為類對象的過程
在完成源代碼的編寫之后,源代碼會被轉換為字節碼文件,這些文件通常以.class作為后綴,JVM需要讀取到這個.class文件并將其轉換為類對象,并保存到方法區中才能運行程序
所謂程序運行,執行代碼本質上就是要執行方法,要執行方法首先要知道這些方法的指令(字節碼),而這些指令是和創建的類緊密相連的
類加載的過程分為5步:
1.加載
分為三步:
- 找到.class文件
- 打開.class文件
- 讀取.class文件
2.驗證
對于生成的.class文件,JVM是有著嚴格的格式規范的,JVM在讀取.class文件之后,首先會對格式進行驗證,具體的格式在Java的標準文檔上有介紹

3.準備
為類對象分配內存,注意這里僅僅只是分配內存,并沒有進行初始化
4.解析
符號引用 --> 直接引用
文件偏移量 --> 內存地址
Java源代碼中的字符串引用也會被保存到.class文件之中:
類似:
String s = "hello";
引用s在代碼中實際上是存儲的字符串的地址,引用s被加載到.class文件之中,在文件里面是沒有地址這個概念的,但是初始化s就必須要指明其所指向的對象的地址,在文件系統里,我們通過引用和指向對象之間的距離文件偏移量來替代地址這個概念
比如當引用s被保存到.class文件之中,和其指向的字符串"hello"在文件中的存儲位置相差1000,則文件偏移量就是1000
5.初始化
類對象初始化 把各個屬性初始化好 還需要初始化static成員,靜態代碼塊,加載父類
2.雙親委派模型
在上面類加載的第一步中,第一步找到.class文件是一個比較繁瑣的過程,在Java中,通過類加載器來完成尋找.class文件的過程,類加載器是JVM的一個模塊,內置了三個類加載器幫助我們完成找.class文件的過程,分別是:

注:上面的三個類加載器并不是繼承關系,之所以叫爺父子是因為每個類加載器中都有一個屬性parent,這個屬性指向上一級的加載器
完整過程:
- 給一個
全限定類名,作為尋找的依據(比如java.lang.String) - 以Application ClassLoader為入口,但是先不從自己的庫中尋找(負責當前項目的庫和第三方庫),而是先交給Extension ClassLoader加載器
- Extension ClassLoader加載器也不會直接在自己的庫中尋找(負責JDK的擴展庫),而是先交給BootStrap ClassLoader類加載器
- 同樣的BootStrap ClassLoader也不會直接在自己的庫中尋找,而是交給自己的父加載器,但是并沒有父加載器,就只能在自己的庫中尋找,如果找到了,就執行加載操作的剩余步驟,如果沒找到就交給子加載器(Extension ClassLoader)
- Extension ClassLoader此時就會從自己的庫中尋找對應的.class文件,如果找到了,執行加載操作的剩余步驟,沒找到,交給子加載器(Application ClassLoader)
- Application ClassLoader從自己的庫中尋找,如果找到了,執行加載操作的剩余步驟,沒找到,就會拋出
ClassNotFound異常
以上就是查找.class文件的完整過程,上述尋找的過程就被稱為雙親委派模型,這里的雙親其實是翻譯問題,英文是parent,而不是parents,應該翻譯為雙親之一,實際上在上述類加載器中,也只有父子這種關系
雙親委派模型實際上就是一個優先級問題,是為了保證標準庫中的類先被加載,其次是擴展庫,最后才是當前項目和第三方庫
比如你自己寫了一個形如java.lang.String的類,在加載時會首先從標準庫中尋找,而不是你自己的項目庫
實際上,雙親委派模型也不是不能打破的,比如tomcat服務器,在進行類加載時只會在webapp目錄中尋找,如果沒找到,也不會從其他地方尋找
3.垃圾回收機制(GC)
在C語言中我們學習過動態內存管理這一章節,通過malloc/realloc函數申請動態的內存,通過free來釋放申請的動態內存,對于動態內存來說,最需要注意的一點是要及時通過free來釋放申請的內存,如果不及時釋放,就有可能造成內存泄露問題
在C++里面也是,都是需要通過手動的釋放申請的內存(C++中是delete方法),這種手動釋放內存的方式對于程序員來說是一個致命殺手,會常常突然出現,而且難以發現(往往是因為長時間的大量不釋放內存所導致的),為了解決這種問題,最好的方法就是把釋放內存這個操作交給計算機去執行
在Java中就引入了**垃圾回收機制(Garbage Collection)**來自動的完成內存的釋放,可有這樣的一個比喻說明C++和Java的垃圾回收機制的不同–“C++是手動擋,Java是自動擋”
GC的工作過程主要有以下兩步:
- 找到垃圾
- 釋放垃圾
1.找到垃圾
釋放垃圾的第一步首先需要找到"垃圾",這里的垃圾就是不再使用的內存.具體找的方式大體上相同,都是需要有一組線程去不斷的掃描的當前所有的對象,判斷對象是否仍被引用,如果沒有引用就認為是"垃圾"
不同的語言實現的方式有所差異,大概分為以下兩種:
- 引用計數
- 可達性分析
1.引用計數
為new出來的出現單獨創建一塊內存空間,當做計數器,描述這個對象有多少引用指向
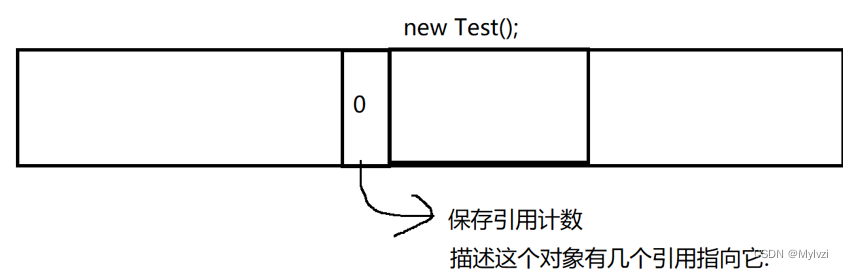
如果引用計數為0,就代表沒有引用指向,也就代表此對象成為"垃圾",可以被釋放
引用計數的問題
1.需要額外占用內存空間
引用計數需要額外的內存當做計數器,計數器少說也得2個字節,如果對象本身很小,那么計數器的內存占總體的內存的比例就會很大,而且隨著對象數目的增多,這種額外的內存開銷就不容忽視
2.存在循環引用問題
如果兩個對象分別引用,就會形成環形引用,就有可能出現永遠無法釋放的問題
class Test {public Test t;
}Test a = new Test();
Test b = new Test();// 在內部分別引用
a.t = b;
b.t = a;// 置空
a = null;
b = null;
在上述代碼中,每置空之前,創建出的兩個對象的引用計數都是2,分別給a,b置空,但是內部t對象仍在引用,所以創建的兩個Test對象的引用變為1
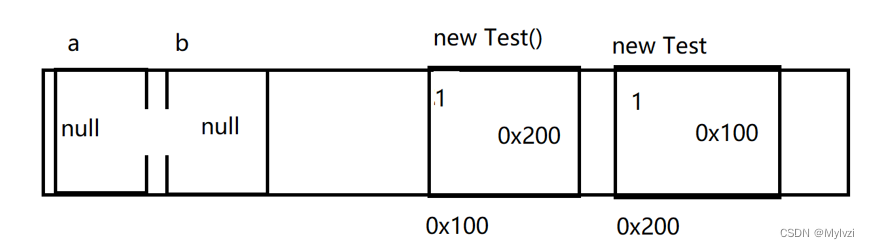
此時a和b被銷毀了,在代碼中不可能再訪問到這兩個對象,但是此時這兩個對象的引用計數不為0,要想釋放對象1,需要先釋放對象2,要想釋放對象2,需要先釋放對象1,構成了邏輯上的死環,這兩個對象就永遠無法進行釋放了
2.可達性分析
Java的GC機制采用的是可達性分析,通過掃描的方式,從特定對象出發(GC Root),對掃描到的對象標記為可達,沒有掃描到的對象就認為是不可達的,需要當做垃圾進行釋放
可達性分析本質上是一種使用時間換空間的方式,通過一組掃描線程,不斷的對所有的對象進行掃描,且這種掃描是周期性的,遍歷方式類似于樹的遍歷(底層很可能是N叉樹)
GC Root是掃描過程的起點,通常包括以下幾種類型:
- 活動線程的本地變量和輸入參數
- 靜態對象的引用
- 活動線程的所有類對象
2.釋放垃圾
釋放垃圾的方法主要有三種:
- 標記清楚
- 復制算法
- 標記整理
1.標記清除
對于標記的對象,直接釋放
標記清除是一種簡單粗暴的方式,垃圾在哪里,就直接釋放
演示:
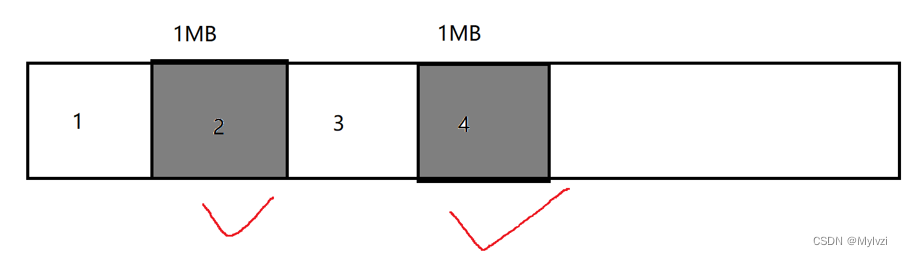
缺陷:
- 會導致大量內存碎片的出現.申請內存是直接申請一個連續的空間,內存碎片的出現會導致可申請的連續空間變小,比如如果上述區域2的內存空間較小,新的對象所需的內存空間大于2,那么2區域的內存就永遠無法使用了,隨著內存碎片的增多,這種情況會更加明顯
2.復制算法
將內存
一分為2,一半用于對象的存儲,一般用于復制
上述標記清楚的方式最大的缺陷就在于連續空間的減少,通過復制算法就能解決上述問題
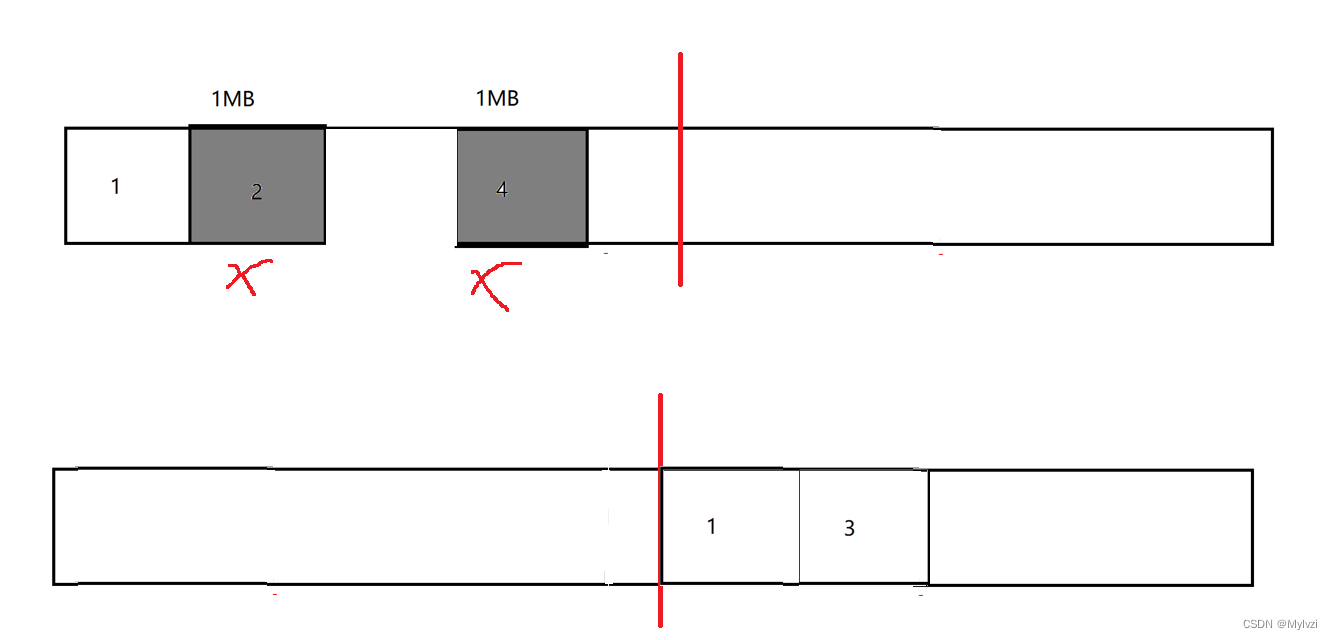
將區域2和4刪除之后,剩余的區域1和3一起復制到內存的另一半,這樣當有新的對象嘗試申請內存時,就可以利用到左側的連續的內存空間
但是復制算法的方式的缺點也很明顯:
- 內存利用率不高,整個內存一分為2
- 如果有效的數據很多,挪動一次需要移動的數據很多,開銷不容忽視
3.標記整理
上述兩種方法都有著各自的缺陷,通過標記整理的方式能夠進一步的提高效率和內存利用率
標記整理處理垃圾的方式類似于順序表刪除任意位置元素的實現,在刪除之后,需要從后往前挪動數據,來保證順序表的連續性
標記整理也是這樣,當有垃圾被回收之后,就把有效數據從后往前挪動,保證內存利用的連續性
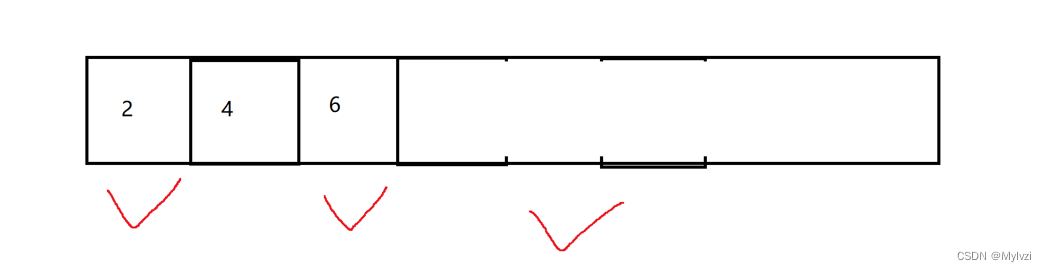
但其實這種方式的開銷也很大,也需要大量的挪動數據
JVM采用的實際上是一種更加高效的方式,利用一些經驗規律,達到內存利用和垃圾回收效率的最大化,JVM內部采用的方式叫做分代回收
JVM把內存分為幾個部分
- 伊甸區
- 幸存區
- 老年區
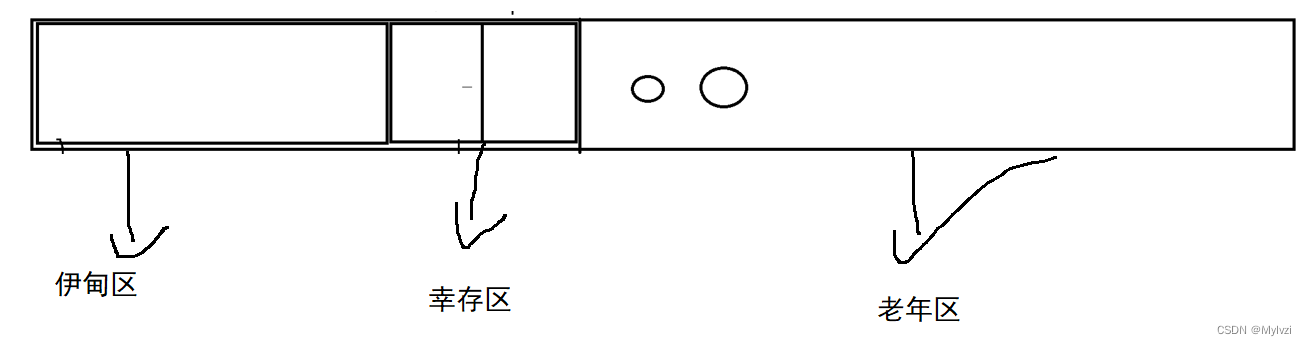
新new出來的對象會首先被存儲到伊甸區(新生代)之中,經驗表明,new出來的對象的生命周期是很短的,往往短時間內就會隨著方法的結束而銷毀,在一次掃描過程中就能被釋放,沒有被釋放的對象就存儲到幸存區之中
由于對象的銷毀很快,大部分的對象在伊甸區中就被銷毀了,所以在幸存去之中存儲的對象很少,就比較適合使用復制算法,幸存區 的內存被一分為二.
幸存區也會被掃描線程掃描,不過掃描的頻率比伊甸區之中要低很多,每掃描一次就利用復制算法對垃圾進行回收,往往在幸存區之中要進行多輪掃描
經過多輪掃描之后,如果仍有對象存儲到幸存區之中,這些對象就會被轉移到老年區之中,老年區的掃描頻率更低
為什么掃描的頻率越來越低呢?這其實也是一種經驗規律,如果對象在第一次(伊甸區)之中沒有被釋放,那么其生存時間就比較長,證明該對象在短時間內不會被清除,如果在幸存區之中經過多輪掃描還是存活,就更加證明該對象在短時間之內不會被清除,不需要頻繁的去掃描該對象
分代回收的這種機制就像是找工作,新生代就是筆試,對象多,淘汰率高,通過筆試就是進入了面試(幸存區),還要經過多輪的面試(在幸存去反復的被掃描),都通過了就進入老年代(拿到offer了,此時檢查的頻率就降低了,但是如果被標記為垃圾,就會被淘汰
以上就是JVM




![【web | CTF】BUUCTF [HCTF 2018]WarmUp](http://pic.xiahunao.cn/【web | CTF】BUUCTF [HCTF 2018]WarmUp)








用法詳解)


、進程間的通信方式)


