文章目錄
- 計算機網絡的層次結構
- 應用層
- DNS
- HTTP協議
- HTTP請求響應過程
- 運輸層
- TCP協議
- TCP協議面向連接實現
- TCP的三次握手連接
- TCP的四次揮手斷開連接
- TCP協議可靠性實現
- TCP的流量控制
- TCP的擁塞控制
- TCP的重傳機制
- UDP協議
- 網際層
- IP協議(主機與主機)
- IP地址的分類
- IP地址和路由控制
- 公有IP地址
- 私有IP地址
- 路由控制
- IP分片與重組
- DHCP協議
- NAT協議
- 數據鏈路層
- MAC地址
- ARP協議
- 物理層
- 計算機網絡綜合
計算機網絡的層次結構

我們用一個很簡單的例子總體宏觀的講述一下計算機網絡的體系:
應用層(Application Layer):
- 類比: 你的出行目的和服務需求。
- 作用: 應用層就像是你的出行目的和需要的服務,例如選擇旅游目的地、規劃行程、訂票、導航等。它關注的是最終用戶的需求和應用服務。
運輸層(Transport Layer):
- 類比: 貨物運輸和物流服務。
- 作用: 運輸層就像是確保貨物在運輸過程中安全、有序地到達目的地,管理貨物的流量、錯誤處理和重新發送。它負責端到端的通信服務。
網際層(Network Layer):
- 類比: 導航系統和路由選擇。
- 作用: 網際層就像是車輛選擇正確的道路和路徑,通過交匯處和路口,到達目的地。它關注的是整體的路線規劃和節點之間的通信。
數據鏈路層(Data Link Layer):
- 類比: 交通規則和道路標志。
- 作用: 數據鏈路層就像是確保車輛在道路上按照規則行駛,遵守交通標志和信號,防止碰撞和混亂。這一層負責直接相鄰車輛(節點)之間的通信。
物理層(Physical Layer):
- 類比: 公路的基礎設施和道路條件。
- 作用: 物理層就像是確保高速公路的質量良好、平整,沒有坑洼或障礙物的部分。它關注的是實際的道路和交通的物理特性。
應用層
DNS
DNS解析過程如下圖所示:
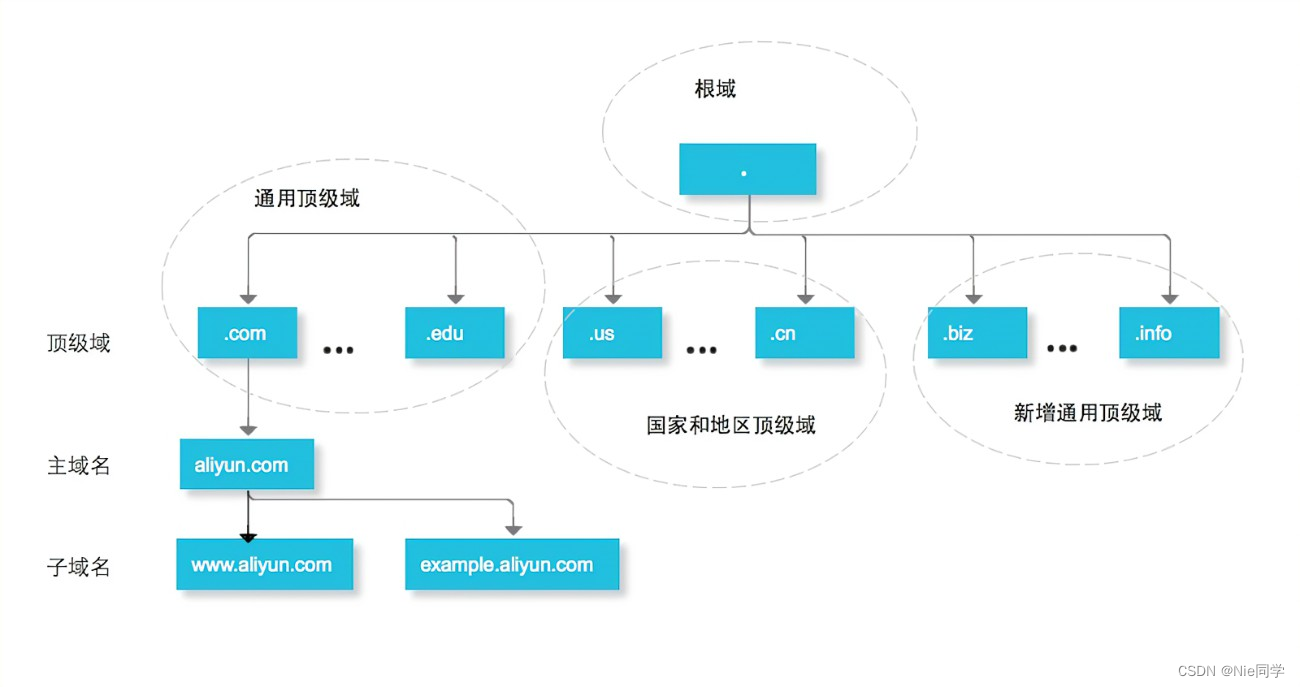
我們可以舉一個形象的例子來說明DNS域名解析的過程:
想象一下你正在圖書館尋找一本特定的書籍,而圖書館的書架上沒有詳細的書名和作者信息。在這個場景中,你需要問圖書管理員找到你需要的書。
-
你的需求(用戶輸入域名): 你想要一本特定的書,但是你不知道它在哪個書架上。
-
圖書管理員(本地域名解析器): 你向圖書管理員詢問,她知道圖書館內部的布局,并告訴你去哪個區域找書。
- 對應DNS:本地域名解析器向本地域名服務器發起查詢。
-
分層查詢(圖書管理員詢問其他領域專員): 如果圖書管理員也不知道具體位置,她可能會向館內的專門領域人員咨詢。這個過程可能需要幾輪的詢問,每次都在更高層次的領域中尋找答案。
- 對應DNS:本地域名服務器向根域名服務器發起查詢,再迭代向下詢問TLD服務器和 authoritative name server。
-
最終定位(找到書籍位置): 最終,通過遞歸和迭代的過程,你找到了這本書的具體位置。
- 對應DNS:最終 authoritative name server 返回域名對應的IP地址給本地域名服務器。
-
記憶(下次更容易找到): 下次你再需要同一本書時,你可能記得它的具體位置,不再需要問圖書管理員。
- 對應DNS:本地域名解析器將解析結果返回給用戶,同時將結果存儲在本地緩存中,以便下次查詢時直接使用。
這個圖書館的例子類比了DNS的遞歸查詢和迭代查詢過程,以及分布式的信息咨詢。就像在DNS中,如果某個層次的服務器不知道答案,它會向更高層次的服務器詢問,直到找到最終答案。這個過程同時也突顯了DNS中緩存的作用,就像你在圖書館里找到書的位置后,可以記住它以便將來更容易找到。
HTTP協議
HTTP是應用層協議,用于在客戶端和服務器之間傳輸超文本數據。它是Web應用中最常用的協議之一,負責在Web瀏覽器和Web服務器之間傳遞信息。
HTTP報文格式如下圖所示:
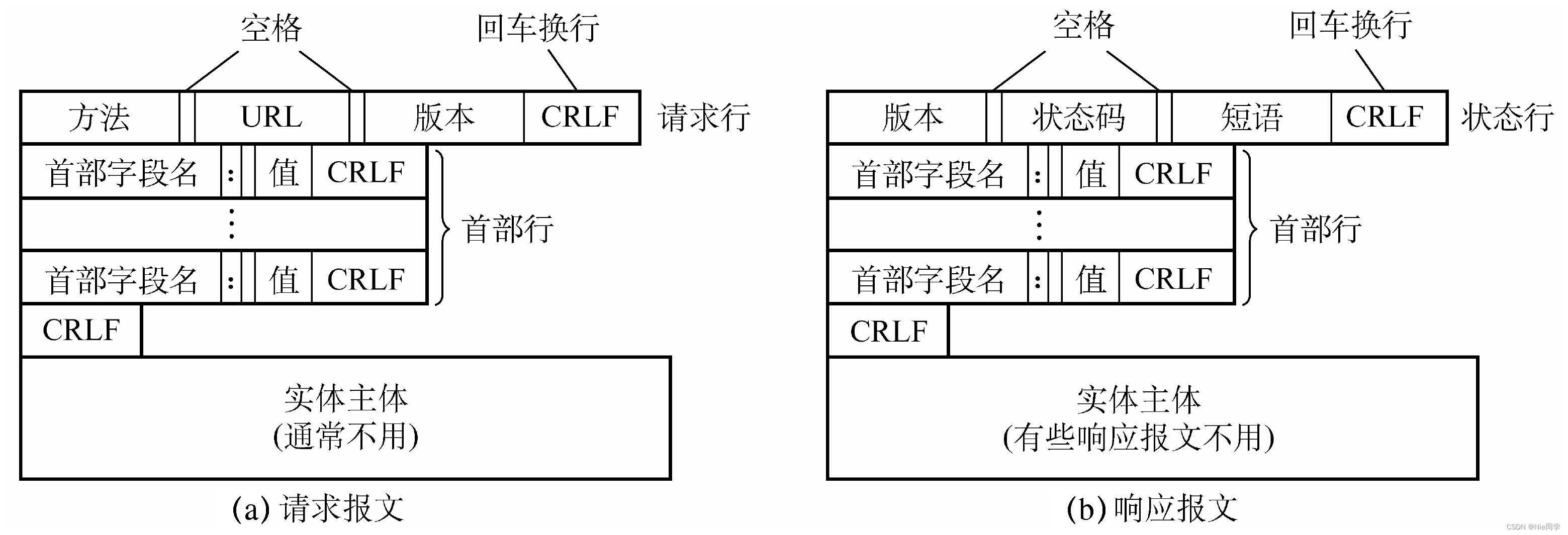
HTTP請求響應過程
HTTP請求響應過程如下所示:
-
DNS解析:在發起HTTP請求之前,如果請求的域名不在本地緩存中,需要進行DNS解析。本地域名解析器向DNS服務器發起查詢,獲取域名對應的IP地址。
-
建立TCP連接:使用獲取到的目標服務器的IP地址,客戶端與服務器建立TCP連接。這通常涉及到三次握手,確保連接的可靠性。
-
發送HTTP請求:客戶端通過建立的TCP連接向服務器發送HTTP請求。請求的內容包括請求行、請求頭部、空行(CRLF),以及可選的請求體(對于POST等有請求體的請求)。
-
服務器處理請求:服務器收到HTTP請求后,根據請求行中的方法和URI等信息,進行相應的處理。這可能涉及到查詢數據庫、執行應用程序邏輯等操作。
-
服務器發送HTTP響應:服務器生成HTTP響應報文,包括響應狀態行、響應頭部、空行(CRLF),以及可選的響應體。響應狀態行包含了HTTP協議版本和狀態碼,響應頭部包含了服務器信息、響應的內容類型等信息。
-
傳輸響應數據:服務器通過已建立的TCP連接向客戶端發送HTTP響應。響應的內容根據響應體的內容類型(Content-Type)而異,可能是HTML頁面、JSON數據、圖片等。
-
客戶端接收響應:客戶端接收到服務器的HTTP響應后,根據響應狀態碼判斷請求的成功或失敗。同時,客戶端解析響應頭部,獲取服務器傳遞的信息。
-
關閉連接:根據需要,連接可以保持開放以便進行其他請求,或者在一定時間后關閉。HTTP/1.1默認使用持久連接,允許在同一連接上發送多個請求和接收多個響應。
-
瀏覽器渲染(對于Web頁面請求):如果是Web頁面請求,瀏覽器將解析HTML內容,并加載其中的資源(如CSS、JavaScript、圖片等),最終渲染出用戶可見的頁面。
讓我們以訂購咖啡的過程來形象地說明HTTP請求和響應的流程。
- 客戶需求(訂購咖啡):客戶想要訂購一杯咖啡,但不知道具體的咖啡店位置。
- 導航(DNS解析):客戶首先需要導航到咖啡店,這就好比進行DNS解析,將咖啡店域名轉換為實際IP地址。
- 到達咖啡店(建立TCP連接):客戶到達咖啡店后,與店員建立聯系。這個過程相當于通過TCP連接與服務器建立通信。
- 點咖啡(發送HTTP請求):客戶告訴店員他要什么咖啡,這就像發送HTTP請求,其中包括了請求行和頭部信息。
- 處理訂單(服務器處理請求):店員接到客戶的訂單后,制作咖啡。這類似于服務器處理HTTP請求,執行相應的操作。
- 告知取貨位置(發送HTTP響應):店員告訴客戶咖啡已經準備好,取貨的位置在哪。這就像服務器發送HTTP響應,包含了響應行和頭部信息。
- 取咖啡(接收HTTP響應):客戶按照店員的指示去取咖啡,這類似于瀏覽器接收到HTTP響應后,根據響應的內容來進行相應的操作。
- 完成訂購,離開咖啡店(關閉連接):
客戶選擇離開咖啡店。這類似于在HTTP中,連接可以保持開放以便進行其他請求,或者在一定時間后關閉。HTTP/1.1默認使用持久連接,但在特定情況下可能會關閉連接。 - 品嘗咖啡(瀏覽器渲染):客戶喝上一口咖啡,享受美好的味道。這就好比瀏覽器解析HTML內容,并加載其中的資源,最終渲染出用戶可見的頁面。
運輸層
TCP協議
TCP是一種面向連接的(一對一)、可靠的、基于字節流的傳輸層協議。它在計算機網絡中負責提供可靠的、有序的數據傳輸。
TCP報文格式如下所示:
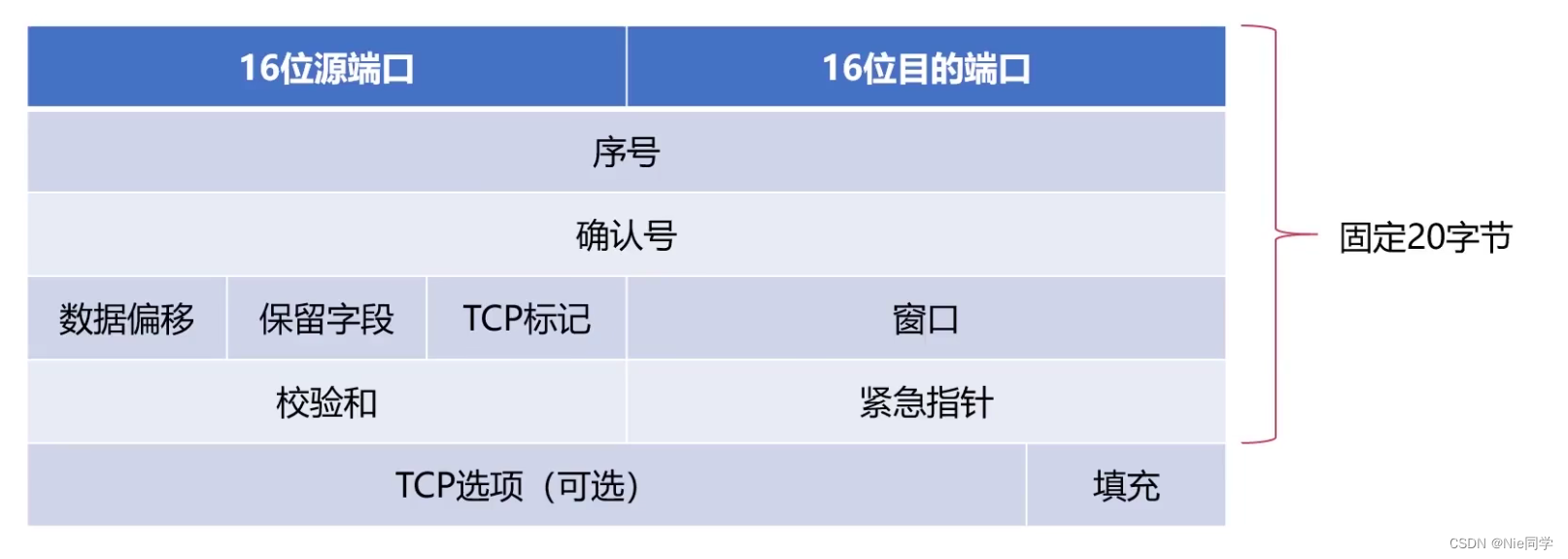
TCP標記字段如下所示:
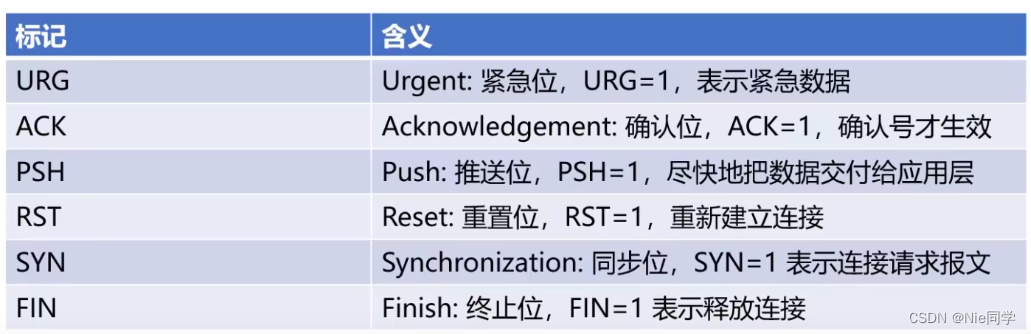
TCP協議面向連接實現
TCP的三次握手連接
TCP三次握手連接示意圖如下所示:
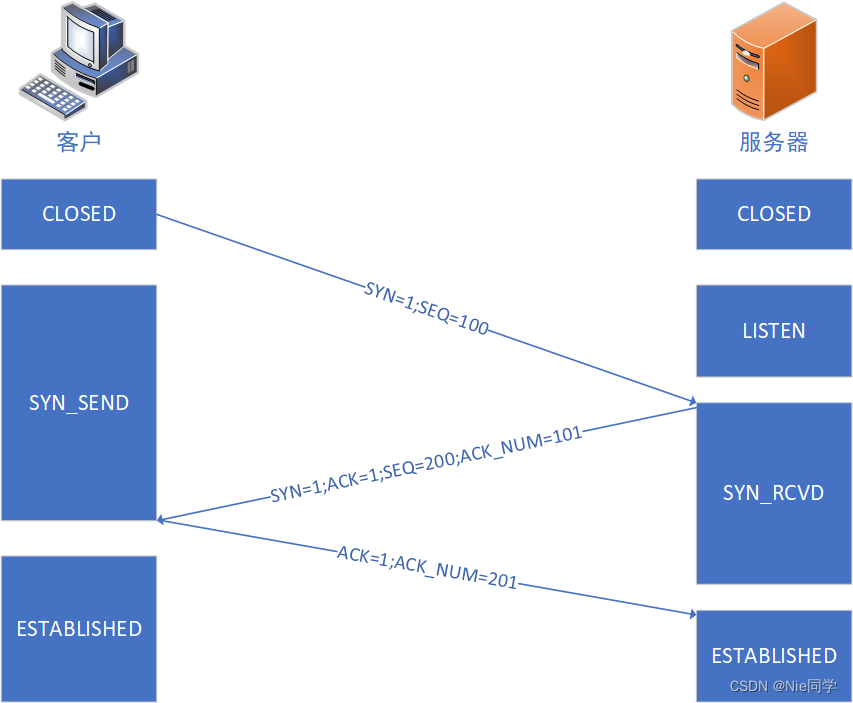
讓我們用郵寄信件的場景來解釋兩次、三次和四次握手的區別以及可能出現的問題:
兩次握手的場景:
-
寄信(第一次握手): 你寫好信件并將信封寄出,表達了寄信的愿望。
-
送信員確認(第二次握手): 送信員收到信并回信說:“我已收到你的信件。”表示確認寄信的請求。
問題: 在這個場景中,你寄信后就得到了確認,看似連接已經建立。然而,問題在于你并不知道信是否已經被正確投遞,因為送信員可能還沒來得及將信遞交給收信人。
三次握手的場景:
-
寄信(第一次握手): 你寫好信件并將信封寄出,表達了寄信的愿望。
-
送信員確認(第二次握手): 送信員收到信并回信說:“我已收到你的信件,并準備將其遞交給收信人。”表示確認寄信的請求。
-
信成功遞交(第三次握手): 送信員將信成功遞交給收信人,并回信給你說:“我已將信成功遞交給收信人。”表示確認信已成功投遞。
優勢: 通過第三次握手,你知道信已經被成功遞交,建立了更為可靠的連接。
四次握手的場景:
-
寄信(第一次握手): 你寫好信件并將信封寄出,表達了寄信的愿望。
-
送信員確認(第二次握手): 送信員收到信并回信說:“我已收到你的信件,并準備將其遞交給收信人。”表示確認寄信的請求。
-
信成功遞交(第三次握手): 送信員將信成功遞交給收信人,并回信給你說:“我已將信成功遞交給收信人。”表示確認信已成功投遞。
-
信被接收(第四次握手): 收信人接收到信并回信給你說:“我已成功收到你的信。”表示確認信已被接收。
問題: 通過第四次握手,雖然確保了對方成功接收并閱讀了信,但在一些情況下,這可能導致了資源的浪費。每一次握手或揮手都需要經過一定的網絡傳輸和處理時間,因此四次揮手相比三次握手在關閉連接時會增加一定的時延,占用更多系統資源,并增加了復雜性。
總結:
- 兩次握手可能存在的問題在于確認建立連接后,雙方并不一定了解對方的真實狀態。
- 三次握手通過增加一次確認,提高了連接的可靠性,確保信息的雙向確認。
- 四次揮手相較于三次握手,在關閉連接時可能導致資源的浪費,包括時延增加、占用更多系統資源以及增加了復雜性。
TCP的四次揮手斷開連接
TCP四次揮手斷開連接示意圖如下所示:
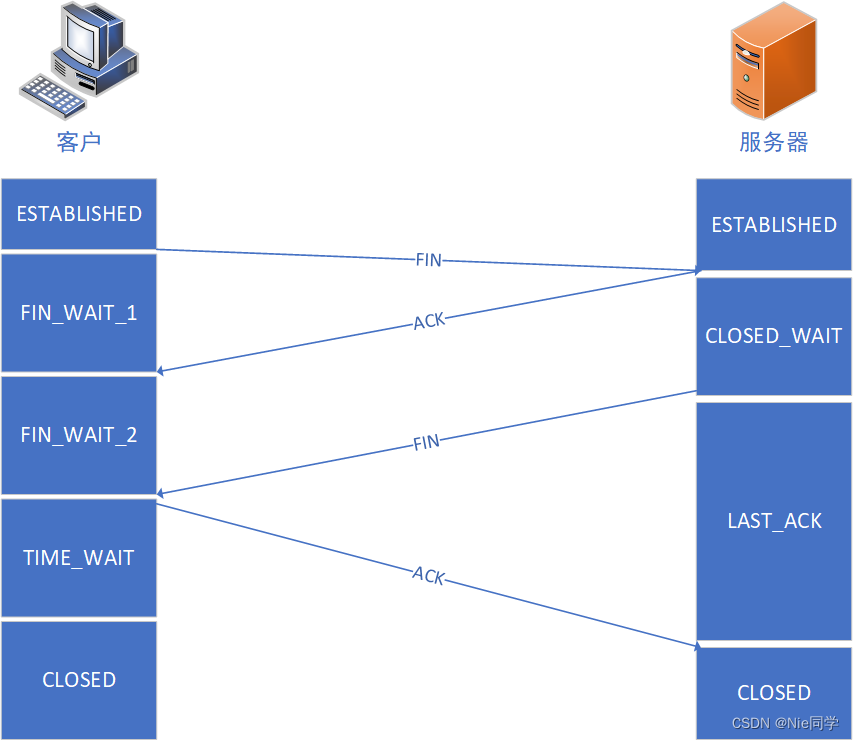
當我們使用關燈睡覺的場景來解釋TCP四次揮手時,可以更加形象地理解:
-
關燈前的準備(第一次揮手): 你決定要睡覺了,于是關掉了房間的燈,表示你希望結束一天的活動。
-
房間感知燈光消失(第二次揮手): 房間內的感應器檢測到燈光的消失,開始準備關機,表示它已經接收到了結束的請求。
-
關機完成(第三次揮手): 房間內的設備完成了關機的準備工作,發送一個信號給你,表示已經做好了關閉的準備,可以完全進入休眠狀態。
-
休眠確認(第四次揮手): 你感覺到房間已經完全安靜,確認燈光已經熄滅,表示房間已經完全進入休眠狀態,雙方都確認關閉完成。
這個例子中,第四次揮手是你對房間關閉請求的最終確認。在TCP連接中,四次揮手確保雙方都明確了終止連接的意愿,并最終確認連接的完全關閉。這可以防止在連接關閉后可能出現的數據傳輸中的滯留或錯誤。
如果我們在關燈睡覺的場景中省略一次揮手,即使用三次揮手,可能會導致一些問題:
-
關燈前的準備(第一次揮手): 你決定要睡覺了,于是關掉了房間的燈,表示你希望結束一天的活動。
-
房間感知燈光消失(第二次揮手): 房間內的感應器檢測到燈光的消失,開始準備關機,表示它已經接收到了結束的請求。
-
關機完成(第三次揮手): 房間內的設備直接完成了關機的準備工作,并沒有發送額外的信號給你,因為省略了一次揮手。
在這種情況下,可能會出現以下問題:
-
狀態不確定: 你關掉燈后,并沒有得到房間已經完全進入休眠狀態的確認。因為省略了一次揮手,你無法確保房間內的設備已經完全準備好關閉。
-
潛在滯留: 由于沒有最終的確認,可能會導致房間內的設備在關閉過程中出現滯留,例如未完成的任務或數據未保存。
在TCP連接中,省略揮手可能導致類似的問題。為了確保連接的可靠關閉,TCP使用四次揮手來進行最終的確認,避免可能出現的狀態不確定和數據滯留。
TCP協議可靠性實現
TCP的流量控制
TCP協議中的流量控制是一種機制,用于管理數據的傳輸速率,確保發送方和接收方之間的通信保持穩定,防止因為接收方處理不及時而導致的數據丟失或擁塞。
流量控制的核心目標是協調發送方和接收方之間的數據傳輸速率,以避免網絡擁塞、數據丟失或過度等待。主要通過以下兩個機制來實現:
-
滑動窗口(Sliding Window): 滑動窗口是TCP流量控制的關鍵概念之一。發送方和接收方都有一個窗口大小的緩沖區,通過滑動窗口的方式來動態調整可發送的數據量。接收方通過通告窗口大小告知發送方,發送方根據窗口大小調整發送的數據量,以確保不會超過接收方的處理能力。
-
TCP窗口大小的動態調整: 接收方可以通過TCP報文中的窗口字段來通告其當前的可接收窗口大小。發送方根據這個信息來動態調整發送的數據量。如果接收方處理能力較強,窗口大小可能會增大,允許發送方發送更多的數據。如果接收方處理能力較弱,窗口大小可能減小,限制發送方發送的數據量。
流量控制的工作流程如下:
-
建立連接: 在TCP連接建立階段,雙方會協商初始的窗口大小。
-
數據傳輸: 發送方根據接收方通告的窗口大小來動態調整發送的數據量。發送的數據不能超過接收方的窗口大小。
-
動態調整: 窗口大小可以根據網絡和接收方的狀況進行動態調整。如果接收方處理能力較強,窗口可能增大;反之,窗口可能減小。
-
連接終止: 在TCP連接終止階段,雙方仍然可以進行流量控制,確保最后的數據傳輸完整。
通過流量控制,TCP協議能夠適應不同網絡和主機之間的傳輸速率差異,保證可靠的數據傳輸,同時避免了擁塞和數據丟失的問題。
讓我們通過指揮交通的例子來更詳細地解釋TCP流量控制的工作流程:
場景: 想象你是一名交警(發送方),負責指揮交叉路口的車輛流動。交叉路口上的車輛就是要傳輸的數據,而你的指揮動作就是發送的數據。
-
車輛通過的速度(發送方的發送速率): 你向交叉路口中的車輛發出指揮信號的速度是你的發送速率。這表示你有多快能夠指揮車輛通過。
-
路口的通行能力(接收方的處理速率): 交叉路口有一個固定的通行能力,即每分鐘能夠容納多少車輛通過。這代表了接收方的處理速率。
-
指揮手勢的數量(發送方的窗口大小): 你一次發出的指揮手勢數量就像是窗口大小,表示你能夠一次性發送的指揮動作數量。如果你一次揮動手臂能夠指揮3輛車通過,那么你的窗口大小就是3。
-
路口通行能力的通告(接收方的通告窗口大小): 你向交叉路口的管理中心通告每分鐘可以指揮多少車輛通過。這就是接收方通告窗口大小的概念。
-
動態調整指揮手勢的數量(動態調整窗口大小): 如果交叉路口的通行能力提高,你可以逐漸增大一次性發出的指揮手勢數量,以便更多車輛可以同時通過。
-
通告新的通行能力: 如果交叉路口的通行能力發生變化,你會向管理中心通告新的每分鐘通行車輛數量,以便及時調整你的指揮手勢數量。
這個指揮交通的例子中,你通過動態調整指揮手勢的數量(窗口大小),根據路口的通行能力(通告窗口大小)來協調車輛的流動,以確保交通順暢而不會因為車輛過多而堵塞。這種動態的流量控制機制使得指揮者和路口之間能夠更好地協作,避免了交通混亂。
TCP的擁塞控制
TCP協議中的擁塞控制是一種機制,用于在網絡中有效地管理擁塞,防止網絡過載,以確保數據傳輸的可靠性和效率。擁塞控制的目標是避免網絡擁塞,即網絡中的流量過大,導致丟包、延遲增加和網絡性能下降。
擁塞控制的主要機制包括:
-
擁塞窗口(Congestion Window): 發送方維護一個擁塞窗口的大小,該窗口限制了在任何時刻可以發送到網絡中的數據量。擁塞窗口的大小是動態調整的,根據網絡的擁塞狀況進行調整。
-
慢啟動(Slow Start): 在連接剛開始時,發送方先以一個較小的擁塞窗口開始發送數據,然后隨著時間的推移逐漸增大窗口的大小,直到達到一個閾值。這有助于避免在網絡開始時發送大量數據導致擁塞。
-
擁塞避免(Congestion Avoidance): 一旦擁塞窗口達到了閾值,發送方進入擁塞避免階段。在這個階段,擁塞窗口的增長變得更為緩慢,以避免快速增大窗口導致擁塞。
-
快速重傳和快速恢復: 如果發送方檢測到網絡中有數據包丟失,它會采取快速重傳和快速恢復的機制,盡快重傳丟失的數據并降低擁塞窗口的大小。
-
超時重傳: 如果發送方在一定時間內沒有收到確認,它會認為數據包可能丟失,并觸發超時重傳,同時減小擁塞窗口的大小。
讓我們繼續使用指揮交通的例子,來解釋TCP擁塞控制的主要機制:
-
擁塞窗口(Congestion Window):
- 類比為: 你手中的指揮棒和手勢。
- 解釋: 你手中的指揮棒和手勢代表了你一次性能夠指揮通過的車輛數量,即擁塞窗口的大小。這個窗口限制了在任何時刻可以通過路口的車輛數量。
-
慢啟動(Slow Start):
- 類比為: 剛開始時逐漸增加指揮棒的幅度。
- 解釋: 在慢啟動階段,你開始時只允許少量車輛通過,就像逐漸增加指揮棒的幅度。這有助于避免在路口剛開始時就引發擁塞。
-
擁塞避免(Congestion Avoidance):
- 類比為: 控制指揮棒的幅度,確保逐漸增加。
- 解釋: 一旦路口的流量逐漸增多,你不再采用慢啟動,而是控制指揮棒的幅度,確保逐漸增加車輛通過的數量,以避免引發擁塞。
-
快速重傳:
- 類比為: 交通警察在發現車輛違規或發生事故時,立即通過手勢示意進行糾正。
- 解釋: 在TCP中,當發送方檢測到數據包丟失時,通過快速重傳機制,立即重發丟失的數據包,避免等待超時,從而及時糾正錯誤,提高傳輸效率。
-
快速恢復:
- 類比為: 交通警察在解決交通阻塞后,逐步放行車輛,恢復正常的交通流。
- 解釋: TCP的快速恢復機制允許在發生快速重傳后,通過逐步增加擁塞窗口來恢復數據傳輸速率,類似于逐步恢復正常交通流,以避免再次引發擁塞。
-
超時重傳:
- 類比為: 如果車輛長時間沒有動靜,采取超時措施。
- 解釋: 如果一些車輛在路口停滯時間過長,你可能采取超時措施,例如通過手勢提示司機等待更長時間或尋找其他路徑,就像TCP中的超時重傳機制。
-
動態調整擁塞窗口:
- 類比為: 根據路口狀況動態調整指揮手勢的幅度。
- 解釋: 你不斷觀察路口狀況,根據需要調整手勢的幅度,以確保路口不會再次擁塞。這類似于TCP動態調整擁塞窗口大小以適應網絡狀況。
通過這個指揮交通的例子,可以更具體地理解TCP擁塞控制的主要機制,以及這些機制是如何通過模擬交通流量來確保網絡順暢、避免擁塞的。
擁塞控制的工作流程如下:
-
初始階段: 在連接剛建立時,擁塞窗口設置為一個較小的值,例如1或2。
-
慢啟動: 發送方以指數級增長擁塞窗口,快速向網絡發送數據。
-
擁塞避免: 一旦擁塞窗口達到了一個閾值,發送方切換到擁塞避免階段,擁塞窗口以線性增長。
-
數據丟失檢測: 發送方通過接收到的確認和超時檢測是否有數據包丟失。
-
快速重傳和快速恢復: 如果檢測到數據包丟失,采取快速重傳和快速恢復機制,盡快重傳數據。
-
動態調整擁塞窗口: 根據網絡狀況,動態調整擁塞窗口的大小,確保在網絡容量允許的范圍內進行數據傳輸。
擁塞控制通過這些機制有效地管理網絡流量,避免了擁塞的發生,從而提高了TCP協議在不同網絡環境下的性能和可靠性。
讓我們通過指揮交通的例子來形象地解釋TCP擁塞控制的工作流程:
假設場景: 你是一個交通警察(發送方),負責在一個繁忙的十字路口指揮交通。車輛流量大致代表了網絡中的數據流量。
-
初始階段(擁塞窗口小): 當你開始指揮交通時,初始階段你只允許幾輛車通過,這相當于剛開始連接時的擁塞窗口設置為一個小值。
-
慢啟動(擁塞窗口指數增長): 隨著交通的逐漸流暢,你決定逐漸增加過路車輛的數量,就像慢啟動階段擁塞窗口指數增長一樣。
-
擁塞避免(擁塞窗口線性增長): 一旦路口流量逐漸增多,你意識到不能一直按照指數增長的方式增加車輛通過,于是你改變策略,以較為線性的方式增加過路車輛,就像擁塞避免階段的擁塞窗口線性增長。
-
檢測交通堵塞: 在某一時刻,你可能會觀察到路口有些擁堵,車輛排隊較長,就像TCP檢測到網絡擁塞一樣。
-
采取措施(快速重傳和快速恢復): 你決定立即采取措施,例如,讓部分車輛優先通過,以解決擁堵問題,就像TCP中的快速重傳和快速恢復機制,盡快恢復正常流程。
-
動態調整交通流量(動態調整擁塞窗口): 為了更好地管理交通,你決定根據交通狀況動態調整每次放行的車輛數,確保路口不會再次擁堵,就像TCP動態調整擁塞窗口大小以適應網絡狀況。
-
保持交通流暢: 在整個過程中,你不斷觀察路口的狀況,采取適當的措施,以確保交通持續流暢。這類似于TCP通過擁塞控制機制不斷調整擁塞窗口,以保持網絡的穩定和高效。
通過這個指揮交通的例子,你可以形象地理解TCP擁塞控制的工作流程,通過動態調整發送速率,避免網絡擁塞,確保數據傳輸的順暢和可靠性。
TCP的重傳機制
TCP協議的重傳機制是為了確保可靠的數據傳輸,即當發送方發送的數據包未能在合理的時間內收到確認時,會觸發重傳。這樣可以應對網絡中可能發生的丟包、延遲或亂序等問題。
TCP的重傳機制主要包括以下步驟:
-
發送數據包: 發送方通過TCP協議發送數據包給接收方。
-
等待確認: 發送方等待接收方發送確認(ACK)信號。在這個等待期間,如果發送方沒有及時收到確認,就會認為數據包可能丟失了。
-
超時檢測: 如果在一定的時間內(超時時間內)沒有收到確認,發送方會認為數據包丟失,觸發超時檢測。
-
觸發重傳: 一旦觸發了超時檢測,發送方會重新發送未收到確認的數據包。這是TCP的基本的超時重傳機制。
-
快速重傳: 為了更快地應對丟失的情況,TCP還引入了快速重傳機制。如果發送方在一次收到三個重復的確認(接收方多次確認相同的數據)時,就會立即重傳對應的丟失的數據包,而不必等待超時。
這樣的重傳機制確保了數據的可靠性。通過在適當的時候重傳數據包,TCP可以應對網絡中的不確定性,提高了數據傳輸的成功率。然而,過度的重傳可能會導致網絡資源浪費,因此TCP的實現通常會采用一些策略來優化重傳機制,例如指數退避等。
讓我們通過寄信的比喻來解釋TCP的重傳機制:
-
寄信過程: 假設你寄了一封重要的信給你的朋友,但郵遞員在送信的過程中可能會遇到一些問題,比如郵件可能會丟失、被延遲送達,或者順序混亂。
-
等待回執: 你寄信后等待朋友的回執,表示他已經收到了信。在網絡通信中,這類似于TCP發送數據包后等待接收方的確認。
-
未收到回執: 如果一段時間內沒有收到朋友的回執,你會懷疑郵件可能遺失了。在TCP中,如果發送方未能在合理的時間內收到確認,就會懷疑數據包可能丟失。
-
超時重傳: 為了確保信件的可靠送達,你會決定重新寄一封相同的信。在TCP中,這相當于超時重傳機制,即發送方在等待確認的過程中,如果超過了設定的時間,就會重新發送相同的數據包。
-
確認收到: 如果朋友最終收到了兩封相同的信,他會回執一份確認,表明他已經收到了信。在TCP中,接收方收到數據后發送確認,告知發送方數據已成功接收。
-
快速重傳: 如果你的朋友連續三次回執同一封信,你可能會懷疑郵遞員只是在一段路程上反復走動。在TCP中,如果發送方在短時間內接收到相同的確認三次,就會立即重傳未確認的數據包,這就是快速重傳機制。
通過這個寄信的例子,可以更形象地理解TCP的重傳機制,它通過重新發送未得到確認的數據包,以確保數據在網絡中的可靠傳輸。
UDP協議
UDP是一種面向無連接的傳輸層協議,與TCP相比,UDP更加輕量,不提供可靠性和有序性。它被設計用于那些對實時性要求較高、能夠容忍一些數據丟失的應用場景。
以下是UDP協議的主要特點和用途:
-
無連接性: UDP是無連接的,不需要在發送數據之前建立連接。每個UDP數據包都是相互獨立的,不受之前或之后數據包的影響。
-
不可靠性: UDP不提供數據可靠性的保證,因此無法確保數據包的到達或按順序到達。如果某個數據包在傳輸過程中丟失,UDP不會進行重傳。
-
輕量和高效: 由于不需要建立連接、不提供可靠性,UDP協議的頭部開銷相對較小,使其成為一種輕量、高效的協議。
-
實時性要求高: UDP適用于對實時性要求較高的應用,如音頻和視頻流傳輸,實時游戲等。在這些場景下,輕微的數據丟失可以被接受,但重要的是能夠及時地傳輸數據。
-
廣播和多播支持: UDP支持廣播和多播,允許將數據一次性發送給多個接收方。這對于一些實時通信或流媒體應用非常有用。
-
應用場景: UDP適用于一些簡單的通信場景,如DNS查詢、SNMP、DHCP等。它還常用于語音通話、視頻會議等實時應用,以及在線游戲等需要快速響應的場景。
UDP的簡單性和高效性使其在特定的應用場景中得到廣泛應用。然而,由于它的不可靠性,對于那些要求數據完整性和有序性的應用,通常會選擇使用TCP。UDP和TCP是兩種互補的協議,根據應用的需求選擇合適的協議是很重要的。
UDP協議報文格式如下圖所示:
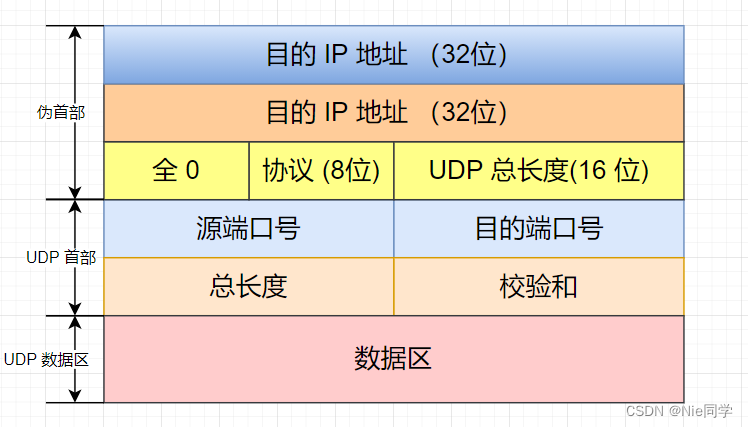
網際層
IP協議(主機與主機)
IP協議是一種主要用于互聯網的網絡層協議,它定義了在網絡上進行數據通信的規則。IP協議的主要功能是為數據包提供尋址和路由,使其能夠在網絡中正確地傳遞。
IP協議報文格式如下圖所示:
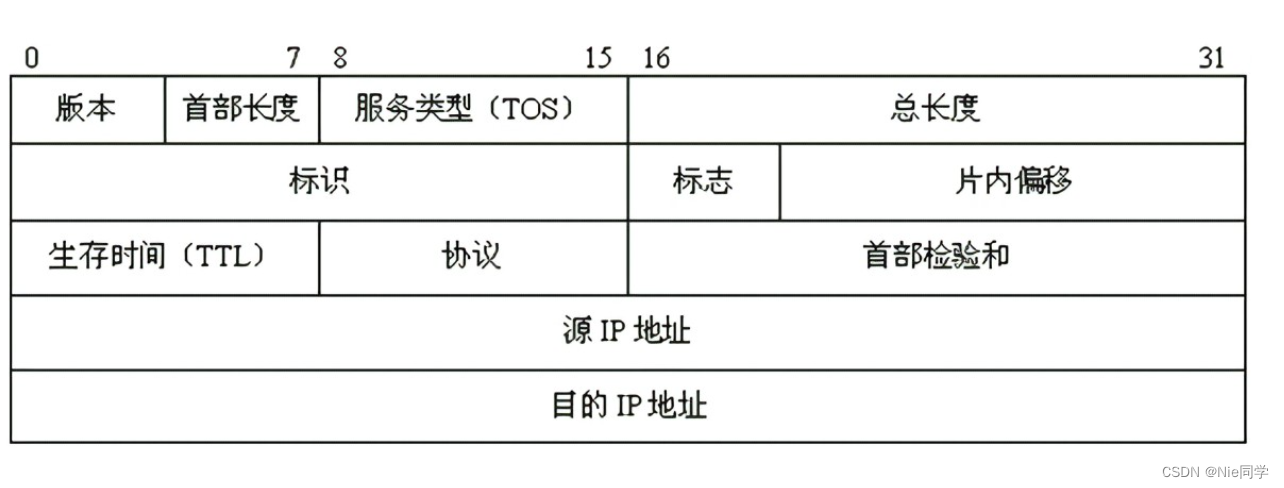
IP地址的分類
IP地址根據其分配和管理方式,可以分為不同的類別。在過去,IP地址分為五個主要的類別:A、B、C、D、E。每個類別都有不同的地址范圍,用于滿足不同規模的網絡需求。然而,隨著互聯網的發展,CIDR的引入使得IP地址的分配更加靈活,不再嚴格按照類別進行。
以下是過去的IP地址分類:
-
類A地址:
- 范圍:1.0.0.0 到 126.255.255.255
- 特點:第一位是0,剩余31位可用。適用于大型網絡,可容納最多的主機數。
-
類B地址:
- 范圍:128.0.0.0 到 191.255.255.255
- 特點:前兩位是10,剩余30位可用。適用于中等規模的網絡,可以容納中等數量的主機。
-
類C地址:
- 范圍:192.0.0.0 到 223.255.255.255
- 特點:前三位是110,剩余29位可用。適用于小型網絡,容納較少數量的主機。
-
類D地址:
- 范圍:224.0.0.0 到 239.255.255.255
- 特點:前四位是1110,用于多播(Multicast)通信。
-
類E地址:
- 范圍:240.0.0.0 到 255.255.255.255
- 特點:前四位是1111,保留用途,用于實驗和研究。
在CIDR引入后,IP地址的分配更加靈活,不再受到固定的類別劃分。CIDR使用前綴長度表示地址的網絡前綴,例如,192.168.1.0/24,其中“/24”表示前綴有24位。這種方式允許更精細地控制地址的分配和路由。
我們如何劃分主機號和網絡號?
劃分主機號和網絡號的過程使用子網掩碼,按照以下步驟進行:
-
選擇IP地址: 選擇一個IP地址作為劃分子網的起點。
-
確定子網掩碼: 根據網絡規模和需要劃分的子網數量,確定子網掩碼的位數。這些位用于表示網絡號,剩余的是主機號。
-
應用子網掩碼: 將子網掩碼與選定的IP地址進行邏輯與運算,得到網絡號和主機號。
-
確定每個子網的可用范圍: 每個子網都有一個網絡號和廣播地址,確定每個子網的可用IP范圍。
-
重復: 如果需要進一步劃分子網,可以重復上述步驟。
例子:
11000000.10101000.00000001.00001010 (192.168.1.10)
11111111.11111111.11111111.00000000 (255.255.255.0)
-----------------------------------
11000000.10101000.00000001.00000000 (192.168.1.0,網絡號)
IP地址和路由控制
公有IP地址
公有IP地址是指在全球范圍內唯一分配給互聯網上的設備的IP地址。這些IP地址是由互聯網尋址與分配機構(如亞太網絡信息中心、美國互聯網數字地址分配機構等)進行分配和管理的,確保在全球范圍內不發生沖突。
以下是公有IP地址的特點:
-
全球唯一性: 公有IP地址在全球范圍內是唯一的,每個公有IP地址只能分配給一個設備。這確保了在互聯網上的設備能夠被唯一標識,避免了沖突。
-
直接可路由: 公有IP地址是可以直接被互聯網路由器識別和傳遞的。互聯網上的設備使用公有IP地址可以直接進行端到端的通信,無需經過網絡地址轉換(NAT)等中間步驟。
-
用于服務器和對外服務: 公有IP地址通常被分配給服務器、網絡設備和需要直接與互聯網通信的設備。這些設備需要在互聯網上提供服務,如網站、郵件服務器等。
-
限制和稀缺性: 公有IP地址的數量是有限的,尤其是在IPv4協議下。由于互聯網的快速發展,公有IPv4地址的供應變得緊張,IPv6的推廣正在逐漸解決這一問題。
-
可追蹤性: 公有IP地址的唯一性和全球性可追蹤設備在互聯網上的活動。這在一些安全和監管方面具有重要作用,但也引發了隱私和安全方面的一些關切。
-
成本較高: 獲取公有IP地址通常需要額外的費用,特別是在IPv4地址稀缺的情況下。一些企業和服務提供商可能需要支付較高的費用以獲得足夠的公有IP地址來支持其業務需求。
私有IP地址
私有IP地址是指在局域網(LAN)內部使用的、不直接暴露在互聯網上的IP地址。這些地址被保留在特定的地址范圍內,用于內部網絡通信,而不用于全球互聯網路由。私有IP地址的使用有助于提高網絡安全性和地址分配的靈活性。
以下是私有IP地址的主要特點:
-
非全球唯一性:
- 私有IP地址在全球范圍內不唯一,可以在不同的局域網中重復使用。這是因為私有IP地址是為了內部網絡通信而保留的,不直接參與全球互聯網的路由。
-
局限于特定范圍: 私有IP地址的范圍是在IPv4中的三個區域:
- 類A: 10.0.0.0 到 10.255.255.255
- 類B: 172.16.0.0 到 172.31.255.255
- 類C: 192.168.0.0 到 192.168.255.255
這些地址范圍被專門保留,不會出現在全球互聯網路由表中。
-
用于內部網絡通信: 私有IP地址主要用于內部網絡中,如家庭網絡、企業內部網絡或組織內的局域網。設備在這些網絡中使用私有IP地址進行局域網通信。
-
NAT技術使用: 為了使私有IP地址的設備能夠訪問互聯網,通常會使用網絡地址轉換(NAT)技術。NAT允許多個內部設備共享單一的公有IP地址,通過修改IP地址信息來實現局域網和互聯網之間的通信。
-
安全性增強: 使用私有IP地址有助于增強網絡的安全性,因為內部設備不直接在互聯網上可見。只有通過NAT的設備才能與互聯網進行通信,提高了網絡的隱蔽性。
-
IP地址沖突的防止: 不同的內部網絡可以使用相同的私有IP地址,而不會發生全球互聯網上的IP地址沖突。這為局域網提供了一定的靈活性,而不必考慮全球唯一性。
路由控制
計算機網絡進行路由控制的過程涉及多個步驟和組件,以下是詳細說明:
-
數據包生成: 通信的起點是應用程序生成數據,形成數據包。數據包包含源和目標設備的IP地址、端口信息以及要傳輸的數據。
-
傳輸到網絡層: 數據包從應用層經過傳輸層,進入網絡層。在這一層,數據包被封裝為IP數據包,添加了源和目標IP地址等信息。
-
源主機路由表查找: 源主機查找自己的路由表,以確定數據包的下一跳路徑。路由表中的信息可能是通過動態路由協議學習到的,也可能是手動配置的靜態路由。
-
查找下一跳路由器: 如果目標設備不在同一子網內,源主機需要查找下一跳路由器的IP地址,通常是源主機所在子網的網關。這個過程可能涉及ARP請求,以獲取下一跳路由器的MAC地址。
-
封裝數據包: 源主機將數據包封裝成數據幀,添加目標MAC地址、源MAC地址等信息。數據幀是鏈路層的表示形式。
-
數據包通過鏈路層: 封裝后的數據包通過鏈路層傳輸到下一跳路由器。鏈路層負責將數據包從一個設備傳輸到另一個設備。
-
下一跳路由器的路由控制: 下一跳路由器收到數據包后,進行類似的路由控制過程。它查找自己的路由表,決定如何將數據包傳遞到下一個路由器或目標設備。
-
數據包傳輸到目標主機: 經過一系列路由器的傳遞,數據包最終到達目標主機。目標主機根據自己的路由表,確定如何將數據包交付給目標應用程序。
-
目標主機解封裝: 目標主機解封裝數據包,提取應用層的信息,并將數據交給目標應用程序。
整個過程是復雜而協調的,需要路由器之間的密切合作,確保數據包能夠按照正確的路徑傳遞。路由表的更新、路由器的決策以及鏈路層的傳輸是實現路由控制的關鍵步驟。
路由控制如下圖所示:
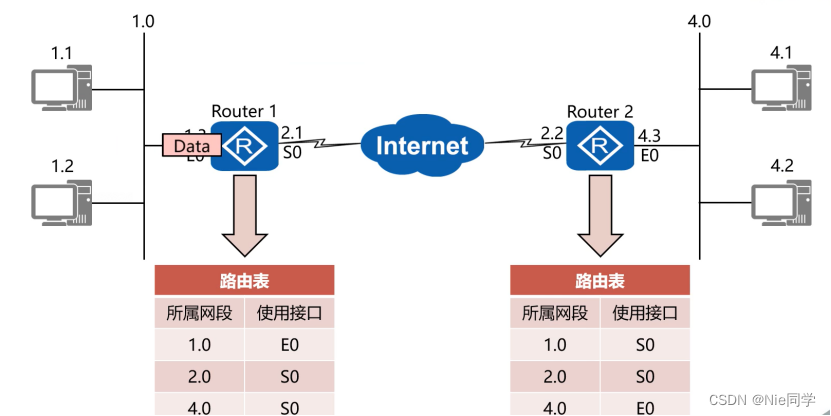
我們用一個例子來解釋路由控制,假設你的計算機網絡就像一座城市,每個計算機就像城市中的一個建筑物,而路由器就像城市中的交叉路口和導航系統。現在,我們使用一個城市交通的例子來生動形象地解釋計算機網絡是如何進行路由控制的:
-
建筑物和地址: 想象一座大城市,每座建筑物都有一個唯一的地址,就像計算機在網絡中有唯一的IP地址。
-
交叉路口和道路: 假設城市中有許多交叉路口,這些交叉路口就像網絡中的路由器。這些路由器通過一條條道路(網絡鏈路)相互連接。
-
導航系統和路由表: 每輛車都有一個導航系統,就像每個計算機都有一個路由表。導航系統知道如何從一座建筑物到另一座建筑物,路由表知道如何從一個IP地址到達另一個IP地址。
-
車輛和數據包: 想象城市中的車輛就像網絡中的數據包。車輛需要從一個地方到達另一個地方,就像數據包需要從源計算機到達目標計算機。
-
交叉路口的決策: 當車輛到達一個交叉路口時,它需要根據導航系統的指示選擇正確的方向。同樣,當數據包到達一個路由器時,路由器會根據路由表的信息選擇下一個跳的路徑。
-
道路上的拓撲變化: 如果城市中的一條道路發生了封閉或施工,車輛需要根據導航系統的提示選擇另一條路徑。在計算機網絡中,如果某個鏈路發生故障,路由器會選擇備用路徑。
-
導航系統的更新: 導航系統會定期更新地圖,以確保它了解最新的道路和交叉路口信息。在計算機網絡中,路由表也會根據動態路由協議的更新而改變,以適應網絡拓撲的變化。
通過這個城市交通的例子,可以形象地理解計算機網絡是如何進行路由控制的。每個路由器就像一個交叉路口,而數據包就像城市中的車輛,通過選擇正確的路徑,確保數據在網絡中快速、可靠地傳遞。
IP分片與重組
IP分片和重組是IPv4協議中的兩個重要概念,用于處理網絡中傳輸的大數據包。當一個數據包在網絡中傳輸時,如果經過的鏈路不支持這個數據包的大小,就會進行IP分片。接收端在接收到這些分片后,通過IP重組將它們還原為原始的數據包。
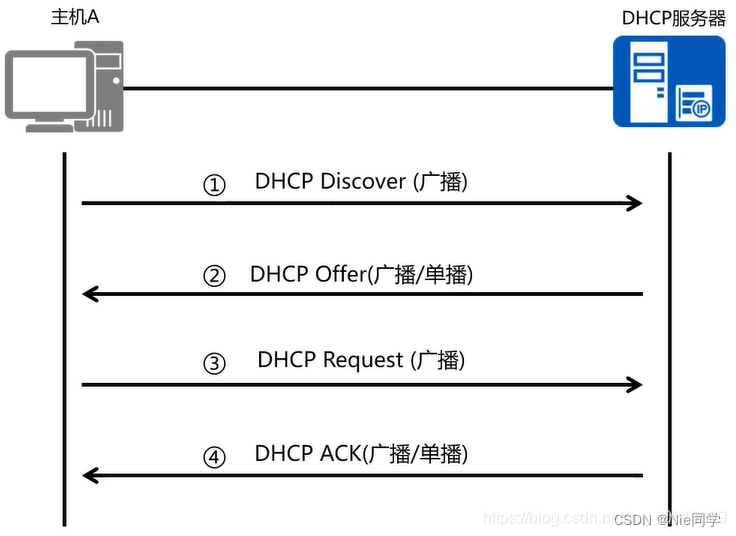
DHCP協議
動態主機配置協議(DHCP)是一種網絡協議,用于自動分配和管理IP地址、子網掩碼、默認網關、DNS等網絡配置信息,以簡化網絡管理員對網絡設備的配置工作。
下圖是DHCP協議動態獲取IP的過程:
NAT協議
網絡地址轉換(NAT)是一種用于在私有網絡和公共網絡之間映射IP地址的協議。NAT主要用于解決IPv4地址短缺的問題,并提供了一種將多個設備共享單個公共IP地址的方法。
下圖是NAT協議如何從私有IP地址網絡轉化到公有IP地址網絡:
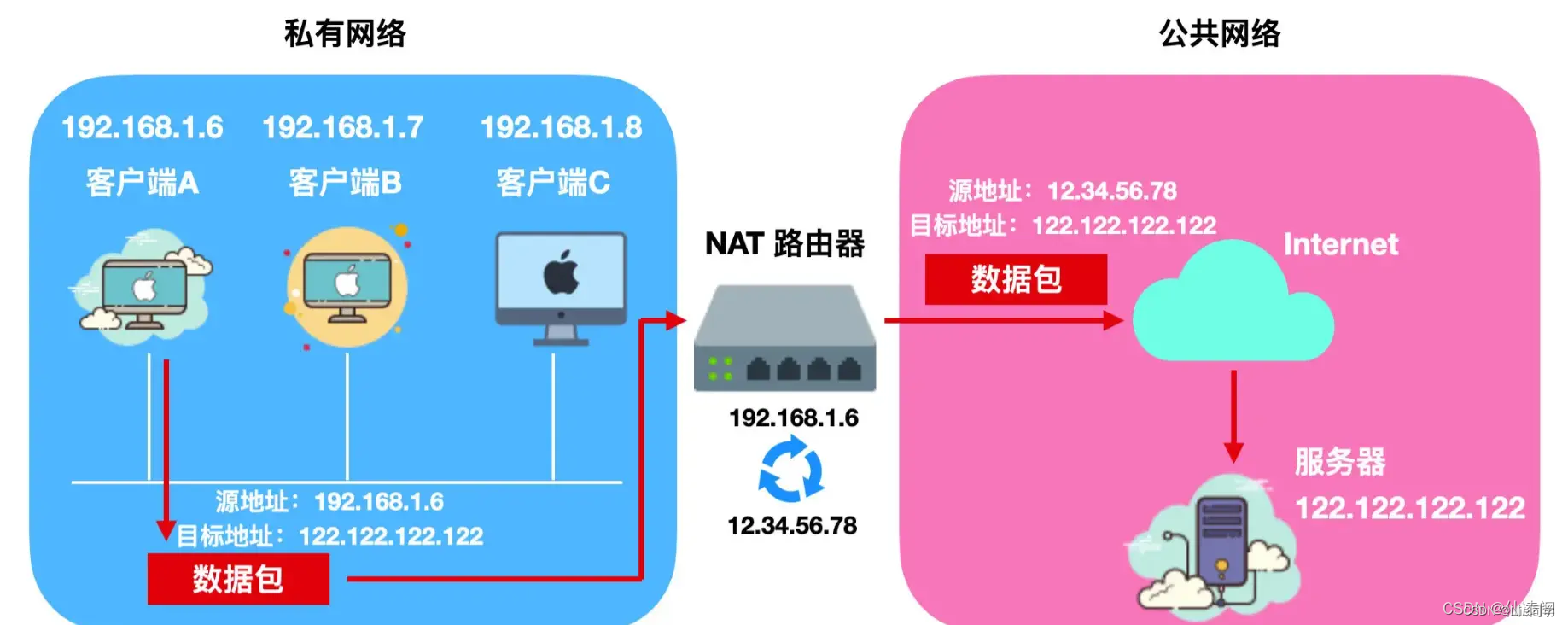
下面通過一個生動形象的例子解釋NAT如何將私有IP地址網絡轉化到公有IP地址網絡:
假設你身處一個度假村,每個度假屋都有一個內部電話,但度假村只有一個公共電話總機(公有IP地址)。這里的度假屋可以看作是私有網絡中的設備,而公共電話總機是公有IP地址。
-
度假屋撥號(設備請求): 當度假屋的居民想要撥號(訪問互聯網)時,他們撥打的是度假村內部的號碼(私有IP地址)。每個度假屋有一個唯一的號碼,但這些號碼只在度假村內部有效。
-
總機接通(NAT設備): 公共電話總機接聽了撥號請求,這里的總機可以看作是NAT設備。NAT設備負責處理度假屋的撥號請求。
-
度假屋號碼翻譯(私有IP地址轉換): 當度假屋的撥號請求到達總機時,總機會將撥號請求中的度假屋號碼(私有IP地址)翻譯為總機的公共號碼(公有IP地址)。這樣,外部網絡(互聯網)就能夠識別和回應這個請求。
-
請求發送到目標(請求轉發): 總機將翻譯后的請求發送到外部網絡(互聯網),就好比公共電話總機代表度假屋撥打了外部號碼。
-
外部網絡回應(響應返回): 當外部網絡(互聯網)收到請求后,它會將響應返回到總機的公共號碼。這時,總機會根據之前的翻譯記錄,將響應翻譯為度假屋的內部號碼,然后傳遞給請求的度假屋。
其中NAT充當了度假屋和外部網絡之間的橋梁,實現了私有IP地址到公有IP地址的轉換,讓私有網絡中的多個設備能夠通過共享一個公有IP地址訪問互聯網。這種轉換過程保護了內部設備的隱私,并有效利用了有限的公有IP地址資源。
數據鏈路層
主要負責在直連的兩個節點之間提供可靠的數據傳輸。數據鏈路層通常涉及的是相鄰節點之間的通信,而不是全局網絡通信。它將網絡層提供的數據報轉換為適合物理層傳輸的幀,同時處理差錯檢測和糾正。
下圖是數據鏈路層封裝成幀的格式:
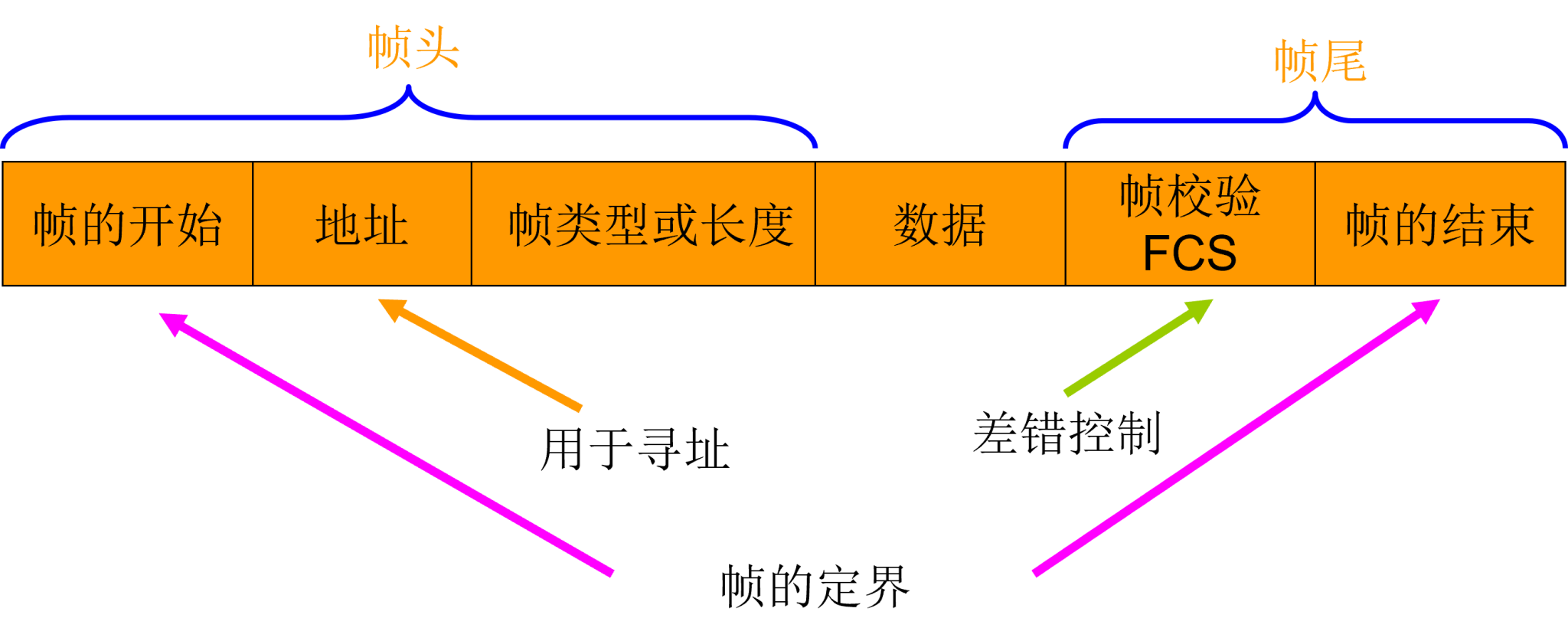
MAC地址
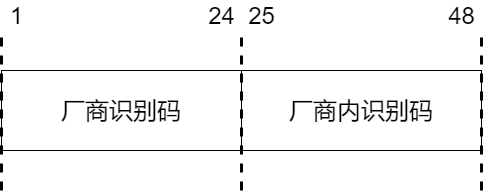
MAC地址,又稱物理地址,是數據鏈路層(Data Link Layer)中用于識別網絡設備的唯一硬件地址。每個網絡設備(如網卡、交換機)都被分配一個獨特的MAC地址,通常由設備的制造商在生產過程中固定編碼到設備的網絡接口卡中。
以下是MAC地址的特點:
-
唯一性: 每個網絡設備的MAC地址是唯一的,確保了全球范圍內的設備標識的唯一性。這是通過設備制造商的標識碼和設備的唯一序列號組合而成的。
-
48位地址: MAC地址通常是一個由48位二進制數字組成的地址。這些位被分為兩個部分:前24位是由IEEE分配給設備制造商的唯一標識碼,后24位是設備的唯一序列號。
-
十六進制表示: 為了方便人類閱讀和書寫,MAC地址通常以十六進制表示。例如,一個MAC地址可能是類似于
00:1A:2B:3C:4D:5E的形式。 -
固定在網絡接口卡上: MAC地址是固定在設備的網絡接口卡上的,通常不會被修改。這使得MAC地址成為設備在網絡中唯一標識的一種可靠方式。
以下是MAC地址的作用:
-
唯一標識設備: MAC地址用于唯一標識網絡中的設備。在局域網(LAN)中,設備使用MAC地址進行通信。
-
地址解析協議(ARP): 在IPv4網絡中,ARP協議用于將IP地址映射到MAC地址。每個設備通過ARP協議來查詢網絡中其他設備的MAC地址,以便進行通信。
-
網絡交換: 在交換機等網絡設備中,MAC地址用于構建交換表,從而決定將數據幀從哪個端口發送到目的設備。
-
防止沖突: MAC地址的唯一性確保了在同一網絡中沒有兩個設備具有相同的MAC地址,從而防止網絡中的沖突和混淆。
總的來說,MAC地址在數據鏈路層扮演著重要的角色,是設備在局域網中唯一標識的關鍵。由于其獨特性和固定性,MAC地址成為網絡通信中重要的硬件地址。
以下是MAC地址的結構:
ARP協議
ARP是一種網絡協議,用于將網絡層的IP地址映射到數據鏈路層的MAC地址。ARP協議允許設備在同一局域網中查找目標設備的MAC地址,以便建立通信。下面是ARP協議的詳細說明:
ARP的工作原理:
-
設備發送ARP請求: 當一個設備想要與局域網上的另一個設備通信,但只知道目標設備的IP地址時,它會發送一個ARP請求廣播到局域網上。該請求包含了目標設備的IP地址。
-
局域網上的設備響應: 局域網上的所有設備都會接收到這個ARP請求,但只有目標設備會響應。目標設備會將自己的MAC地址封裝在ARP響應中,并發送給請求設備。
-
ARP響應包含MAC地址: ARP響應包含了目標設備的MAC地址,這樣請求設備就知道了目標設備的IP地址與MAC地址的映射關系。
-
緩存ARP表: 請求設備會將收到的ARP響應中的IP地址與MAC地址的映射關系存儲在本地的ARP緩存表中。這樣,在以后的通信中,就不需要再發送ARP請求,而是直接使用ARP緩存表中的映射關系。
ARP消息格式:
-
ARP請求消息:
- 硬件類型: 表示使用的硬件地址類型,通常為Ethernet。
- 協議類型: 表示網絡層協議類型,通常為IPv4。
- 硬件地址長度: 表示硬件地址的長度,對于Ethernet是6字節。
- 協議地址長度: 表示協議地址的長度,對于IPv4是4字節。
- 操作碼: 表示ARP請求(1)或ARP響應(2)。
- 發送方硬件地址: 發送ARP請求的設備的MAC地址。
- 發送方協議地址: 發送ARP請求的設備的IP地址。
- 目標硬件地址: 在ARP請求中通常為0,因為此時目標MAC地址未知。
- 目標協議地址: 目標設備的IP地址。
-
ARP響應消息: 與ARP請求消息相似,不同之處在于操作碼是ARP響應(2),目標硬件地址是目標設備的MAC地址。
ARP的應用:
-
解析IP地址到MAC地址: ARP主要用于解析目標設備的IP地址到其對應的MAC地址,以便直接通信。
-
ARP緩存: 設備在收到ARP響應后,會將IP地址與MAC地址的映射關系緩存起來,以便后續通信時直接使用,提高效率。
-
局域網通信: ARP主要用于局域網中,當設備需要與同一局域網上的其他設備通信時使用。
ARP協議是IPv4網絡中的一個重要組成部分,它幫助設備在局域網中解析目標設備的MAC地址,從而實現直接的通信。
物理層
物理層是OSI模型中的第一層,它主要負責在網絡設備之間傳輸原始比特流,通過物理媒體將數據從一個點傳輸到另一個點。物理層的主要功能和用處包括:
-
比特編碼和調制: 物理層負責將數字數據轉換為比特流,并進行調制,以適應特定的物理傳輸介質。這可能涉及到將數字信號轉換為模擬信號,或者采用不同的編碼方式。
-
傳輸介質的選擇: 物理層決定了數據的傳輸媒體,可以是銅線、光纖、無線電波等。選擇合適的傳輸介質取決于通信需求、距離和成本等因素。
-
數據傳輸速率: 確定數據傳輸速率,即比特率。物理層定義了在單位時間內傳輸的比特數,例如以每秒比特數(bps)為單位。
-
物理拓撲: 確定網絡的物理拓撲結構,即設備之間的連接方式。常見的物理拓撲包括星型、總線型、環型等。
-
信道復用: 控制在物理媒體上傳輸的數據流,以確保多個設備能夠共享同一物理通道。信道復用技術包括時分復用(TDM)、頻分復用(FDM)等。
-
時鐘同步: 提供時鐘同步,確保發送和接收設備在傳輸過程中保持相同的時鐘頻率,以便正確解釋比特的時序。
-
物理層設備: 包括傳輸介質和物理層設備,如中繼器、集線器等。這些設備用于放大信號、衰減和整形信號,以確保它們能夠在物理媒體上傳輸。
-
媒體訪問控制(MAC): 在一些網絡中,物理層也可能涉及到媒體訪問控制,即控制在共享媒體上訪問的方式,如以太網中的CSMA/CD(Carrier Sense Multiple Access with Collision Detection)。
物理層在網絡通信中扮演著將數字數據轉換為物理信號,并通過物理媒體進行傳輸的重要角色。物理層的設計和實施直接影響到網絡的性能和可靠性。
計算機網絡綜合
讓我們使用OSI模型的各層來解釋從輸入網址到瀏覽器顯示的過程:
-
應用層: 用戶在瀏覽器中輸入網址,觸發了應用層。瀏覽器會使用HTTP或HTTPS協議創建一個HTTP請求。
-
運輸層: HTTP請求被傳遞到運輸層,通常使用TCP協議。在這一層,建立了一個TCP連接,確保數據的可靠傳輸。
-
網際層: 在運輸層之上,數據包被封裝并添加了源和目標的IP地址。這是通過DNS解析得到的目標服務器的IP地址。
-
數據鏈路層: 數據包在網際層上傳輸時,會被封裝成幀,并添加源和目標的MAC地址。這一層確保了數據在局域網中的傳輸。
-
物理層: 最底層是物理層,負責實際的比特傳輸,將幀轉換為電信號或光信號,并通過物理介質(例如電纜、光纖)傳輸。
在服務器端,相反的過程也會發生:
-
物理層: 接收到比特流后,物理層將其轉換為幀。
-
數據鏈路層: 幀被解封裝,提取出數據包。
-
網際層: 從數據包中提取出目標IP地址,路由決定如何將數據包傳遞到目標服務器。
-
運輸層: 數據包傳遞到運輸層,TCP協議解封裝數據包,將其傳遞到應用層。
-
應用層: 在應用層,服務器的Web服務器軟件處理HTTP請求,生成HTTP響應。
最終,HTTP響應沿著相反的路徑通過物理、數據鏈路、網際、運輸和應用層,到達用戶的瀏覽器。瀏覽器將HTTP響應解析并渲染成用戶可以瀏覽的網頁。整個過程遵循OSI模型,每一層負責不同的功能,確保了網絡通信的順利進行。
我們用一個例子來更形象的表示此過程,想象一下你是一位旅行者,正在規劃一次前往一個新城市的旅程。這個城市的名字就是你在瀏覽器中輸入的網址。現在,我們將這個旅程與計算機網絡的通信過程進行對比:
-
應用層 - 旅行計劃: 你開始規劃旅行,類似于在瀏覽器中輸入網址。這相當于應用層,你的旅行計劃就像HTTP請求。
-
運輸層 - 交通規劃: 為了到達目的地,你需要選擇適當的交通工具,例如汽車或火車。在網絡中,運輸層就像是交通規劃,選擇TCP協議作為主要交通工具,確保安全可靠的到達。
-
網際層 - 導航系統: 使用導航系統(相當于DNS解析),你輸入目的地的城市名稱,導航系統將其轉換為具體的地理坐標,幫助你找到正確的路線。
-
數據鏈路層 - 行車路徑: 你沿著道路行駛,道路上有標識和指示牌,確保你沿著正確的路徑前進。在計算機網絡中,數據鏈路層就像是行車路徑,通過MAC地址確保數據在局域網中正確傳輸。
-
物理層 - 實際道路: 最終,你駕駛著汽車或坐著火車,通過實際的道路或鐵路網絡到達目的地。在網絡中,物理層就是實際的電纜、光纖等物理介質,確保比特數據能夠物理傳輸。
在目的地城市,整個過程相反地發生,就像服務器響應你的旅行請求一樣。這個生動的旅行比喻幫助理解了計算機網絡中不同層次的功能及其相互協作。



![【web | CTF】BUUCTF [HCTF 2018]WarmUp](http://pic.xiahunao.cn/【web | CTF】BUUCTF [HCTF 2018]WarmUp)








用法詳解)


、進程間的通信方式)



