?
專欄介紹:YOLOv9改進系列 | 包含深度學習最新創新,主力高效漲點!!!
一、本文介紹
?本文只有代碼及注意力模塊簡介,YOLOv9中的添加教程:可以看這篇文章。
YOLOv9有效提點|加入SE、CBAM、ECA、SimAM等幾十種注意力機制(一)
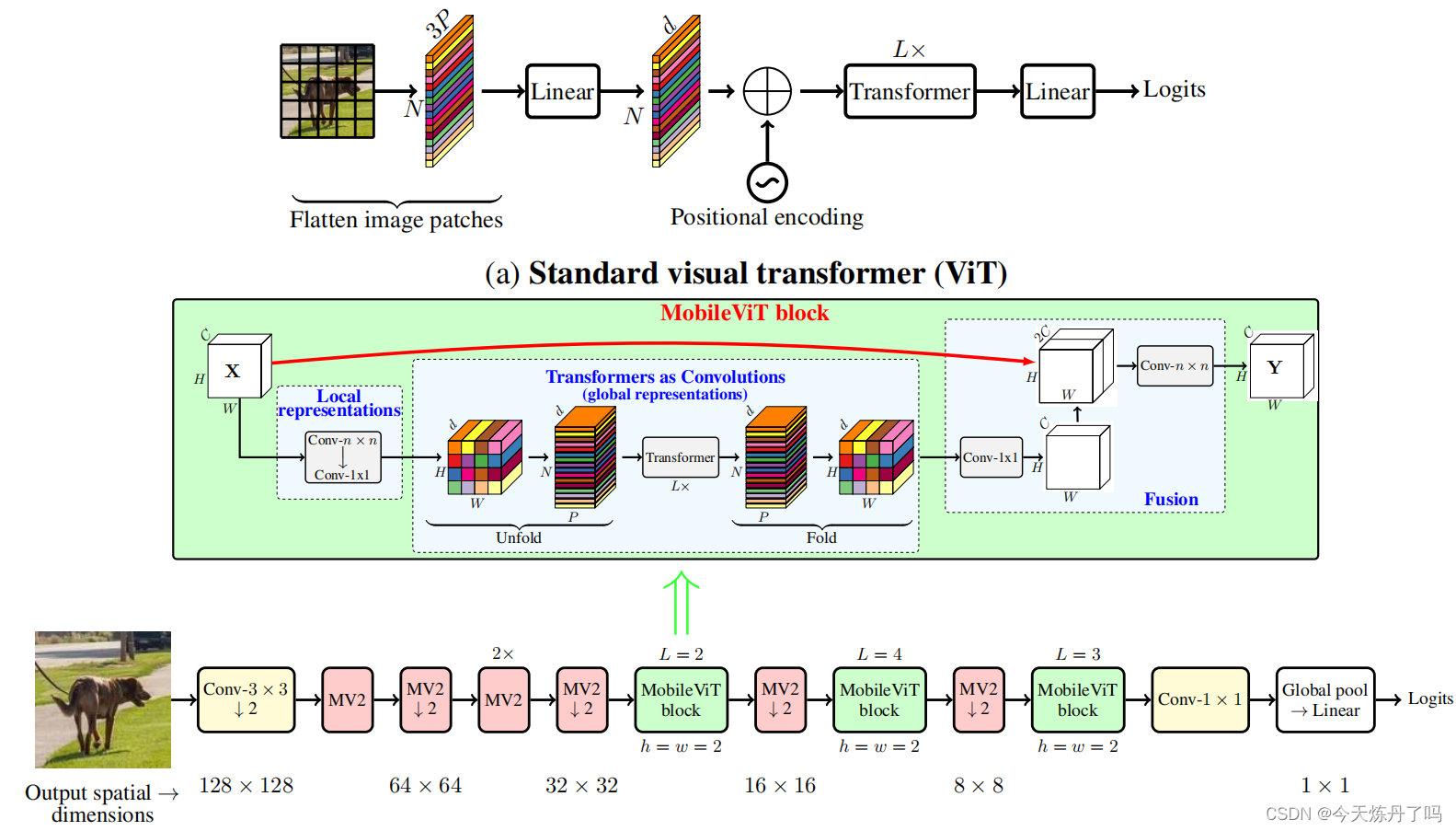
MobileViT:《MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER》
????????MobileViT是一種輕量級和通用視覺轉換器,用于移動設備上的視覺任務。MobileViT結合了CNN和ViT的優點,提供了一個不同的視角來進行全局信息處理。
from torch import nn
import torch
from einops import rearrangeclass PreNorm(nn.Module):def __init__(self, dim, fn):super().__init__()self.ln = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.ln(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, mlp_dim, dropout):super().__init__()self.net = nn.Sequential(nn.Linear(dim, mlp_dim),nn.SiLU(),nn.Dropout(dropout),nn.Linear(mlp_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads, head_dim, dropout):super().__init__()inner_dim = heads * head_dimproject_out = not (heads == 1 and head_dim == dim)self.heads = headsself.scale = head_dim ** -0.5self.attend = nn.Softmax(dim=-1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):qkv = self.to_qkv(x).chunk(3, dim=-1)q, k, v = map(lambda t: rearrange(t, 'b p n (h d) -> b p h n d', h=self.heads), qkv)dots = torch.matmul(q, k.transpose(-1, -2)) * self.scaleattn = self.attend(dots)out = torch.matmul(attn, v)out = rearrange(out, 'b p h n d -> b p n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, head_dim, mlp_dim, dropout=0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads, head_dim, dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout))]))def forward(self, x):out = xfor att, ffn in self.layers:out = out + att(out)out = out + ffn(out)return outclass MobileViTAttention(nn.Module):def __init__(self, in_channel=3, dim=512, kernel_size=3, patch_size=7):super().__init__()self.ph, self.pw = patch_size, patch_sizeself.conv1 = nn.Conv2d(in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2)self.conv2 = nn.Conv2d(in_channel, dim, kernel_size=1)self.trans = Transformer(dim=dim, depth=3, heads=8, head_dim=64, mlp_dim=1024)self.conv3 = nn.Conv2d(dim, in_channel, kernel_size=1)self.conv4 = nn.Conv2d(2 * in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2)def forward(self, x):y = x.clone() # bs,c,h,w## Local Representationy = self.conv2(self.conv1(x)) # bs,dim,h,w## Global Representation_, _, h, w = y.shapey = rearrange(y, 'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim', ph=self.ph, pw=self.pw) # bs,h,w,dimy = self.trans(y)y = rearrange(y, 'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)', ph=self.ph, pw=self.pw, nh=h // self.ph,nw=w // self.pw) # bs,dim,h,w## Fusiony = self.conv3(y) # bs,dim,h,wy = torch.cat([x, y], 1) # bs,2*dim,h,wy = self.conv4(y) # bs,c,h,wreturn y
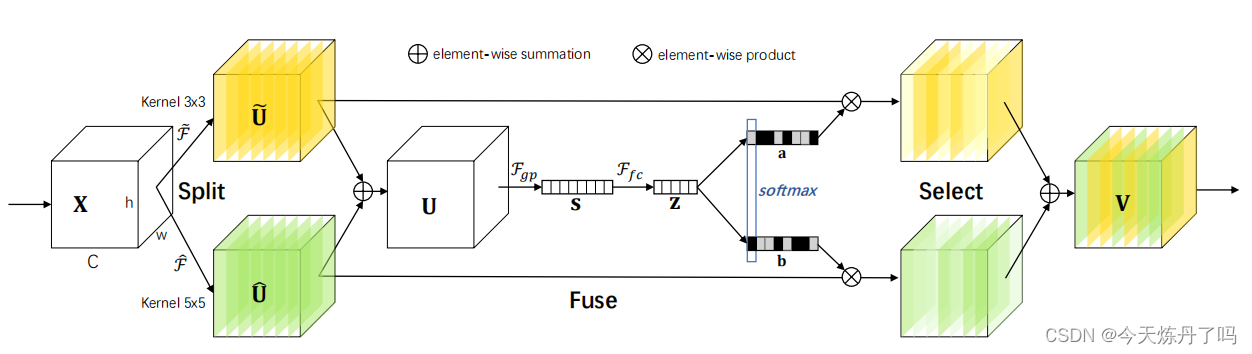
《Selective Kernel Networks》
? ? ? ? SK是一個動態選擇機制,允許每個神經元根據輸入信息動態調整其感受野大小。設計了選擇性核(SK)單元作為構建塊,其中不同核大小的多個分支通過由這些分支中的信息引導的softmax注意力進行融合。這些分支上的不同注意力會產生融合層中神經元的不同大小的有效的感受野。多個SK單元堆疊成一個稱為選擇性核網絡(SKNet)的深層網絡。?
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDictclass SKAttention(nn.Module):def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):super().__init__()self.d = max(L, channel // reduction)self.convs = nn.ModuleList([])for k in kernels:self.convs.append(nn.Sequential(OrderedDict([('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),('bn', nn.BatchNorm2d(channel)),('relu', nn.ReLU())])))self.fc = nn.Linear(channel, self.d)self.fcs = nn.ModuleList([])for i in range(len(kernels)):self.fcs.append(nn.Linear(self.d, channel))self.softmax = nn.Softmax(dim=0)def forward(self, x):bs, c, _, _ = x.size()conv_outs = []### splitfor conv in self.convs:conv_outs.append(conv(x))feats = torch.stack(conv_outs, 0) # k,bs,channel,h,w### fuseU = sum(conv_outs) # bs,c,h,w### reduction channelS = U.mean(-1).mean(-1) # bs,cZ = self.fc(S) # bs,d### calculate attention weightweights = []for fc in self.fcs:weight = fc(Z)weights.append(weight.view(bs, c, 1, 1)) # bs,channelattention_weughts = torch.stack(weights, 0) # k,bs,channel,1,1attention_weughts = self.softmax(attention_weughts) # k,bs,channel,1,1### fuseV = (attention_weughts * feats).sum(0)return V《A2 -Nets: Double Attention Networks》
????????A2Nets是一種新的神經網絡組件,名為“雙注意力塊”,它能夠從整個輸入圖像/視頻中提取重要的全局特征,并使神經網絡更有效地訪問整個空間的特征,從而提高識別任務的性能。實驗表明,配備雙注意力塊的神經網絡在圖像和動作識別任務上均優于現有的更大規模神經網絡,同時參數和計算量也減少。

import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as Fclass DoubleAttention(nn.Module):def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):super().__init__()self.in_channels=in_channelsself.reconstruct = reconstructself.c_m=c_mself.c_n=c_nself.convA=nn.Conv2d(in_channels,c_m,1)self.convB=nn.Conv2d(in_channels,c_n,1)self.convV=nn.Conv2d(in_channels,c_n,1)if self.reconstruct:self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)self.init_weights()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, h,w=x.shapeassert c==self.in_channelsA=self.convA(x) #b,c_m,h,wB=self.convB(x) #b,c_n,h,wV=self.convV(x) #b,c_n,h,wtmpA=A.view(b,self.c_m,-1)attention_maps=F.softmax(B.view(b,self.c_n,-1))attention_vectors=F.softmax(V.view(b,self.c_n,-1))# step 1: feature gatingglobal_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n# step 2: feature distributiontmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*wtmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,wif self.reconstruct:tmpZ=self.conv_reconstruct(tmpZ)return tmpZ
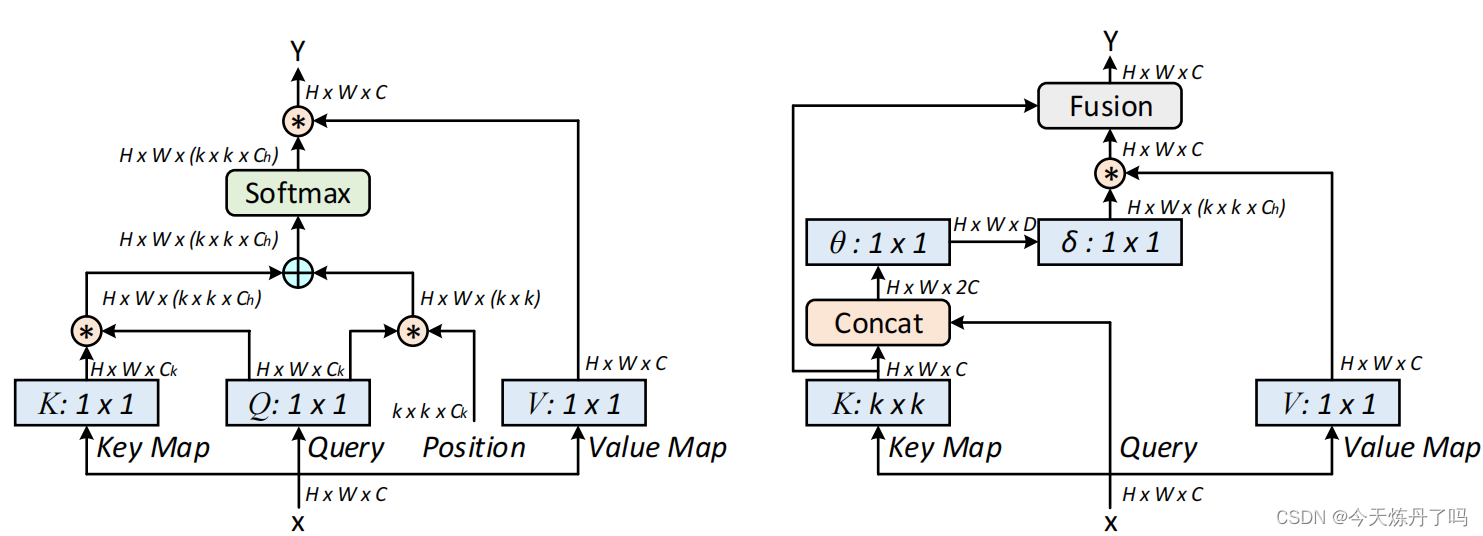
《Large Selective Kernel Network for Remote Sensing Object Detection》
?????????CoTAttention網絡是一種用于多模態場景下的視覺問答(Visual Question Answering,VQA)任務的神經網絡模型。它是在經典的注意力機制(Attention Mechanism)上進行了改進,能夠自適應地對不同的視覺和語言輸入進行注意力分配,從而更好地完成VQA任務。CoTAttention網絡中的“CoT”代表“Cross-modal Transformer”,即跨模態Transformer。在該網絡中,視覺和語言輸入分別被編碼為一組特征向量,然后通過一個跨模態的Transformer模塊進行交互和整合。在這個跨模態的Transformer模塊中,Co-Attention機制被用來計算視覺和語言特征之間的交互注意力,從而實現更好的信息交換和整合。在計算機視覺和自然語言處理緊密結合的VQA任務中,CoTAttention取得了很好的效果。
此代碼暫沒調試,代碼地址:https://github.com/JDAI-CV/CoTNet/tree/master/cot_experiments





)
:Redis實現分布式ID生成)
)








——使用MRTK在Unity中設置混合現實場景并進行程序模擬)


