近期,Stability AI發布了首個開放視頻模型——"Stable Video",該創新工具能夠將文本和圖像輸入轉化為生動的場景,將概念轉換成動態影像,生成出電影級別的作品,旨在滿足廣泛的視頻應用需求,包括媒體、娛樂、教育和營銷等領域。"Stable Video"提供了兩種圖像到視頻的模型,能夠生成14幀和25幀的視頻,用戶還可以自行設置幀率,范圍在3到30幀每秒之間。該模型適用于多種視頻應用任務,包括從單一圖像進行多視角合成,以及在多視角數據集上進行微調。
Stable Video Diffusion模型是一種先進的文本到視頻和圖像到視頻生成模型,專為高分辨率視頻設計。研究者通過三個階段的訓練過程,強調了預訓練數據集的重要性,并提出了一種系統化的數據策劃方法來培養一個強大的基礎模型。該模型不僅為多視圖合成提供了強有力的運動和多視角先驗,還能夠微調成多視圖擴散模型,以高效的方式生成對象的多個視角。
此外,通過特定的運動提示和LoRA模塊的訓練,模型能夠實現顯式運動控制。研究者們通過策劃工作流程,將大型視頻集合轉化為高質量的數據集,并訓練出了超越先前所有模型的尖端文生視頻和圖生視頻模型。他們的方法在減少數據集大小、提高分辨率和視頻幀數方面表現出色,并在與其他頂尖模型的比較中證明了其有效性。總而言之,這一方法有效地分離了運動和內容,在多視圖合成方面取得了顯著成果。其主要步驟如下:
-
數據處理與標注:首先提出了一個大型視頻數據集(LVD),包含580M個標注過的視頻剪輯對,使用三種不同的合成字幕方法對每個片段進行注釋,而通過進一步研究發現,現有數據集中含有可能降低最終視頻模型性能的樣本,如運動量少、文本過多或審美價值低的視頻。因此,作者以2FPS進行計算,并通過刪除任何平均光流幅度低于某一閾值的視頻來過濾掉靜態場景。
-
圖像預訓練:討論了圖像預訓練作為視頻模型訓練流程中的第一個階段。作者將圖像預訓練(image pretraining)作為視頻模型訓練流程的第一個階段。他們在初始模型上使用了一個預訓練的圖像擴散模型——即Stable Diffusion 2.1——以為模型提供強大的視覺表現力
-
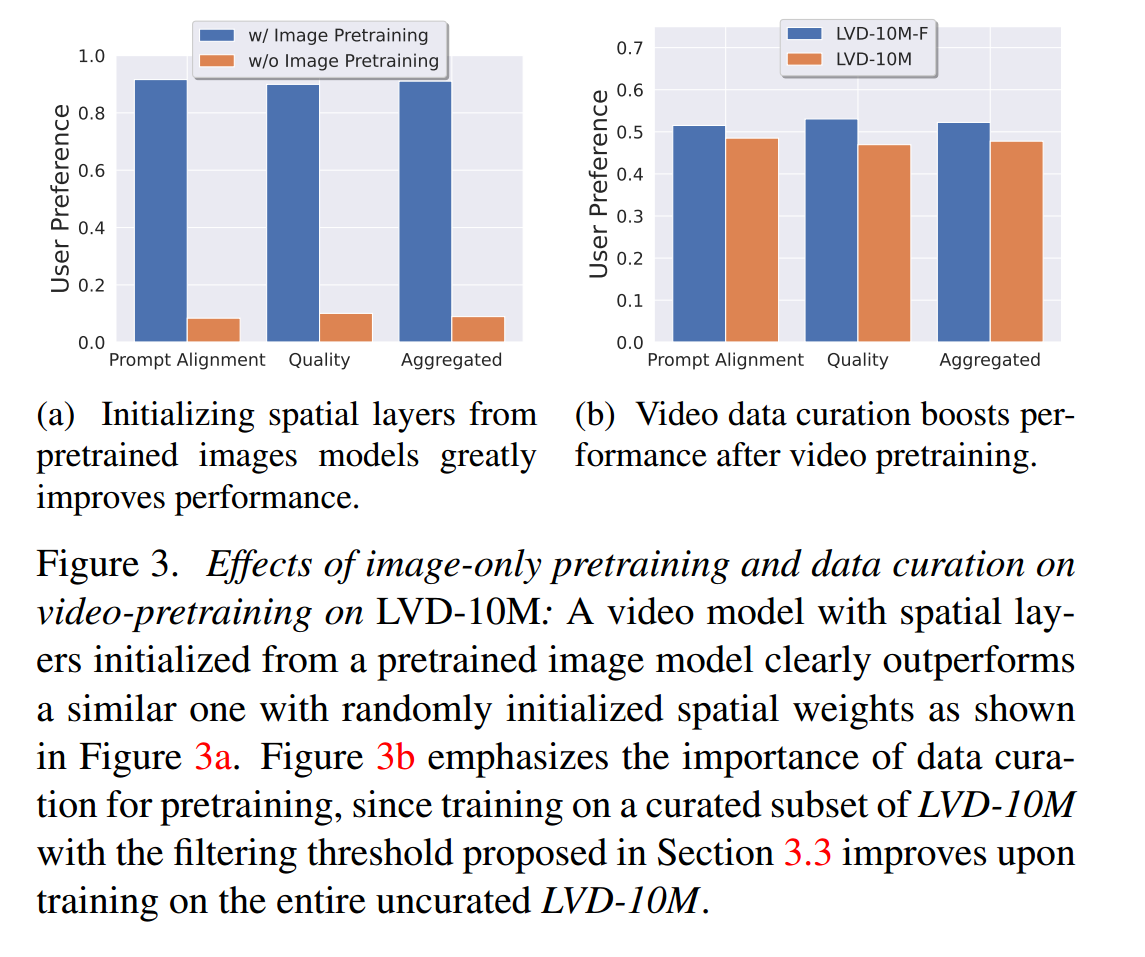
策劃視頻預訓練數據集:作者提出了一個兩階段的視頻預訓練數據集策劃流程。第一階段涉及圖像預訓練,其中利用了空間布局初始化自預訓練圖像模型的視頻模型,并展示了在預訓練大型且多樣化的數據集,然后在較小但質量更高的數據集上進行微調的效果提升。第二階段關注于策劃適合預訓練的視頻數據集。作者通過計算光流(optical flow)來過濾掉不需要的樣本以創建一個更適宜的預訓練數據集
-
高質量視頻微調:這一階段的目的是在一個高質量、高分辨率的視頻子集上對模型進行精細化調整。在前兩個階段(圖像預訓練和視頻預訓練)的基礎上,通過進一步的高質量微調來提升最終模型的性能。在第三階段期間,插入時間卷積和注意力層,這些是在每個空間卷積和注意力層之后添加的,與僅訓練時間層的工作或完全基于LLM(大型語言模型)的方法形成對比。
Stability AI還發布了"Stable Video Diffusion"的代碼,其github倉庫地址為:https://github.com/nateraw/stable-diffusion-videos,可以進入倉庫使用colab一鍵體驗。另外Stable Video Diffusion官網已經全面開放使用,可以直接進入官網https://www.stablevideo.com/,點擊start with text。
輸入對應的prompt如:A tranquil, realistic depiction of a sunset over calm ocean waters, with the sky ablaze in vibrant oranges and reds, reflecting softly on the water's surface,然后選擇比例和風格,點擊Generate即可開始生成視頻。
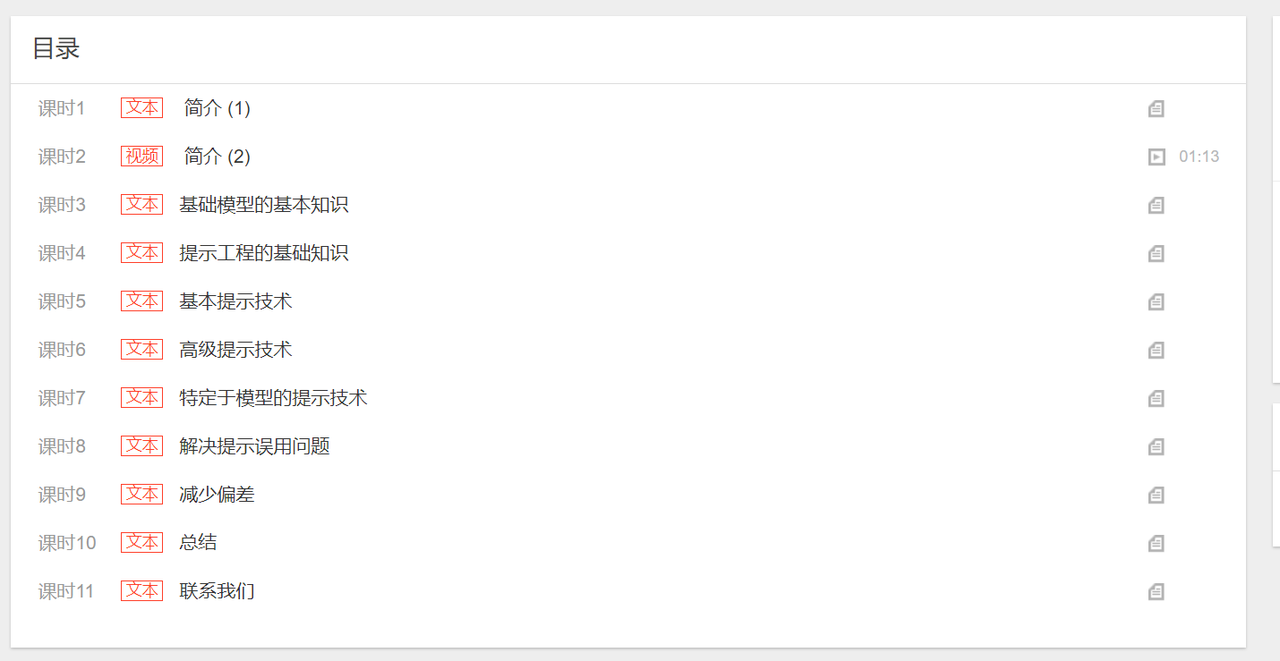
圖像和視頻的生成已成為目前人工智能最火熱的應用,而掌握良好的提示工程基礎已經成為提高工作效率、優化系統設計和提供良好用戶體驗的重要前提之一。無論是對于從事信息技術相關工作的專業人士,還是對于對提示技術感興趣的初學者,我推薦學習一下《提示工程基礎》這門課程、課程將介紹提示工程的基本知識,然后逐步過渡到高級提示技術。您還將學習如何防止提示誤用,以及如何在與基礎模型 (FM, Foundation Model) 互動時減少偏差。
課程鏈接:https://study.163.com/course/introduction.htm?from=AWS-social-FY24-KOC-HJS






gcc ASAN、MSAN檢測內存越界、泄露、使用未初始化內存等內存相關錯誤)
)


)




)


)
)