文章目錄
- 0 前言
- 1 課題意義
- 課題難點:
- 2 實現方法
- 2.1 圖像預處理
- 2.2 字符分割
- 2.3 字符識別
- 部分實現代碼
- 3 實現效果
- 4 最后
0 前言
🔥 優質競賽項目系列,今天要分享的是
🚩 圖像識別 火車票識別系統
該項目較為新穎,適合作為競賽課題方向,學長非常推薦!
🥇學長這里給一個題目綜合評分(每項滿分5分)
- 難度系數:3分
- 工作量:3分
- 創新點:4分
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate
1 課題意義

目前火車乘務員在臥鋪旅客在上車前為其提供將火車票換成位置信息卡服務,在旅客上車前,由于上車人數多,而且大多數旅客都攜帶大量行李物品,而且乘車中老人和小孩也較多。在換卡這一過程中,人員擁擠十分厲害,而且上火車時,火車門窄階梯也較陡,危險系數十分高。乘務員維持秩序十分困難。換卡之后,在旅客下車之前乘務員又要將位置信息卡換成火車票。這一過程冗長且對于旅客基本沒有任何有用的意義。如果通過光學符識別軟件,乘務員利用ipad等電子產品掃描采集火車票圖像,讀取文本圖像,通過識別算法轉成文字,將文字信息提取出來,之后存儲起來,便于乘務員統計查看,在旅客到站是,系統自動提醒乘務員某站點下車的所有旅客位置信息。隨著鐵路交通的不斷優化,車次與旅客人數的增加,火車票免票系統將更加便捷,為人們帶來更好的服務。
課題難點:
由于火車票票面文字識別屬于多種字體混排,低品質的專用印刷漢子識別。火車票文字筆畫粘連,斷裂,識別復雜度高,難度大,采用目前較好的OCR技術都比較難以實現。
2 實現方法
2.1 圖像預處理
火車票經過掃描裝置火車照相機等裝置將圖像傳遞到計算機,經過灰度處理保存為一幅灰度圖。如果要對火車票進行后期的識別,那么就一定要對圖像做二值化,之后再對二值化的圖像進行版面分析,確定我們所需要的信息所在,之后才能進行單個字符的分割,才能對字符做提取特征點的工作,之后按照我們對比確定的規則來進行判決從而達到識別效果。
由于火車票容易被污損、彎折,而且字符的顏色也是有所不同,火車票票號是紅色,而其他信息顯示則為黑色,票面的背景包括紅色和藍色兩種彩色,這些特點都使得火車票的文字識別不同于一般的文字識別。在識前期,要對火車票圖像做出特定的處理才能很好的進行后續的識別。本次課題所研究的預處理有平常所處理的二值化,平滑去噪之外還需要針對不同字符顏色來進行彩色空間上的平滑過濾。
預處理流程如下所示
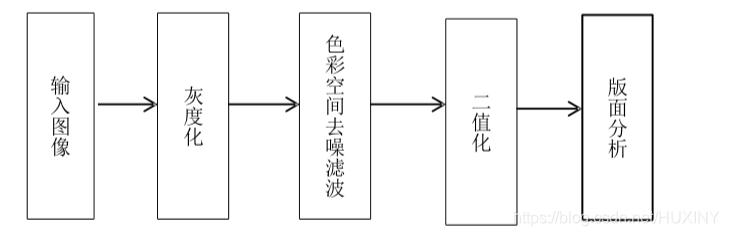
2.2 字符分割
字符分割就是在版面分析后得到的文本塊切分成為文字行,之后再將行分割成單個字符,來進行后續的字符識別。這是OCR系統里至關重要的一環,直接影響識別效果。字符分割的主流方式有三種,一種是居于圖像特種來尋找分割的準則,這是從結構角度進行分析切割。另一種方式是根據識別效果反饋來確認分割結果有無問題,這種方式是基于識別的切分。還有一種整體切分方式,把字符串當做整體,系統進行以詞為基礎的識別比并非字識別,一般這一方式要根據先驗知識來進行輔助判斷。
分割效果如下圖所示:


2.3 字符識別
中文/數字/英文 識別目前最高效的方法就是使用深度學習算法進行識別。
字符識別對于深度學習開發者來說是老生常談了,這里就不在復述了;
網絡可以視為編解碼器結構,編碼器由特征提取網絡ResneXt-50和雙向長短時記憶網絡(BiLSTM)構成,解碼器由加入注意力機制的長短時記憶網絡(LSTM)構成。網絡結構如下圖所示。

網絡訓練流程如下:

部分實現代碼
這里學長提供一個簡單網絡字符識別的訓練代碼:
(需要完整工程及代碼的同學聯系學長獲取)
?
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
#1、開始建立一個圖
sess = tf.InteractiveSession()#啟動一個交互會話
x = tf.placeholder(tf.float32, shape=[None, 784])#x和y_都用一個占位符表示
y_ = tf.placeholder(tf.float32, shape=[None, 10])W = tf.Variable(tf.zeros([784, 10]))#W和b因為需要改變,所以定義為初始化為0的變量
b = tf.Variable(tf.zeros(10))#2、建立預測部分的操作節點
y = tf.matmul(x,W) + b #計算wx+b
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)) #計算softmax交叉熵的均值#3、現在已經得到了損失函數,接下來要做的就是最小化這一損失函數,這里用最常用的梯度下降做
# 為了用到前幾節說過的內容,這里用學習率隨訓練下降的方法執行
global_step = tf.Variable(0, trainable = False)#建立一個可變數,而且這個變量在計算梯度時候不被影響,其實就是個全局變量
start_learning_rate = 0.5#這么寫是為了清楚
#得到所需的學習率,學習率每100個step進行一次變化,公式為decayed_learning_rate = learning_rate * decay_rate ^(global_step / decay_steps)
learning_rate = tf.train.exponential_decay(start_learning_rate, global_step, 10, 0.9, staircase=True)train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)#梯度下降最小化交叉熵
#這是因為在交互的Session下可以這樣寫Op.run(),還可以sess.run(tf.global_variables_initializer())
tf.global_variables_initializer().run()#初始化所有變量#iteration = 1000, Batch_Size = 100
for _ in range(1000):batch = mnist.train.next_batch(100)#每次選出100個數據train_step.run(feed_dict = {x:batch[0], y_: batch[1]})#給Placeholder填充數據就可以了correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) #首先比較兩個結果的差異
#這時的correct_prediction應該類似[True, False, True, True],然后只要轉為float的形式再求加和平均就知道準確率了
#這里的cast是用于形式轉化
accuracy = tf.reduce_mean(tf.cast(correct_prediction, dtype=tf.float32))
#打印出來就可以了,注意這個時候accuracy也只是一個tensor,而且也只是一個模型的代表,還需要輸入數據
print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}))sess.close()#首先把要重復用的定義好
def weight_variable(shape):initial = tf.truncated_normal(shape=shape, stddev=0.1)return tf.Variable(initial)
def bias_variable(shape):initial = tf.constant(0.1, shape=shape)#常量轉變量,return tf.Variable(initial)
def conv2d(x, f):return tf.nn.conv2d(x, f, strides=[1,1,1,1], padding='SAME')
def max_pool_22(x):return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')sess = tf.InteractiveSession()#啟動一個交互會話
x = tf.placeholder(tf.float32, shape=[None, 784])#x和y_都用一個占位符表示
y_ = tf.placeholder(tf.float32, shape=[None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
#第一層:
#1、設計卷積核1
fW1 = weight_variable([5,5,1,32])#[height, weight, in_channel, out_channel]
fb1 = bias_variable([32])#2、卷積加池化
h1 = tf.nn.relu(conv2d(x_image,fW1)+ fb1)
h1_pool = max_pool_22(h1)#第二層
fW2 = weight_variable([5,5,32,64])#[height, weight, in_channel, out_channel]
fb2 = bias_variable([64])h2 = tf.nn.relu(conv2d(h1_pool,fW2)+ fb2)
h2_pool = max_pool_22(h2)#全部變成一維全連接層,這里因為是按照官方走的,所以手動計算了經過第二層后的圖片尺寸為7*7
#來定義了一個wx+b所需的w和b的尺寸,注意這里的W和b不是卷積所用的了
h2_pool_flat = tf.reshape(h2_pool, [-1, 7*7*64])#首先把數據變成行表示
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_fc1 = tf.nn.relu(tf.matmul(h2_pool_flat, W_fc1) + b_fc1)#定義dropout,選擇性失活,首先指定一個失活的比例
prob = tf.placeholder(tf.float32)
h_dropout = tf.nn.dropout(h_fc1, prob)#最后一個全連接層,輸出10個值,用于softmax
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_dropout, W_fc2) + b_fc2#梯度更新,這里采用另一種優化方式AdamOptimizer
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))#初始化
sess.run(tf.global_variables_initializer())
for i in range(2000):batch = mnist.train.next_batch(50)if i%100 == 0:train_accuracy = accuracy.eval(feed_dict = {x:batch[0],y_:batch[1], prob:1.0}) #這里是計算accuracy用的eval,不是在run一個Operationprint("step %d, training accuracy %g"%(i, train_accuracy))train_step.run(feed_dict={x: batch[0], y_: batch[1], prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, prob: 1.0}) )
3 實現效果
車票圖

識別效果:

4 最后
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate









有中間件的各類鏈接和官網信息和漏洞庫以及配置問題和開源工具)

技術筆記)
![[云原生] k8s之pod容器](http://pic.xiahunao.cn/[云原生] k8s之pod容器)






