1. 前言
在SQL性能診斷上,OceanBase有一個非常實用的功能 —— SQL審計視圖(gv$sql_audit)。在OceanBase 4.0.0及更高版本中,該功能是 gv$ob_sql_audit。它可以使開發和運維人員更方便地排查在OceanBase上運行過的任意一條SQL,無論這些SQL是成功與否,都有詳細的運行信息記錄。這些信息包括客戶端和服務端的IP端口、SQL語句、執行時間、執行節點、執行計劃ID、會話ID、執行時間、等待時間、總時間、排隊時間、以及相關的塊讀取信息和執行報錯信息等。
| 查詢方式 | 說明 |
| (g)v$ob_sql_audit | OceanBase 4.0.0.0 及以上版本,gv$xx查詢該租戶所有機器v$xxx查詢該租戶本機器(不保證路由準確) |
| (g)v$sql_audit | OceanBase 4.0.0.0 以下版本gv$xx查詢該租戶所有機器v$xxx查詢該租戶本機器(不保證路由準確) |
sql_audit是基于虛擬表__all_virtual_sql_audit的視圖, 該虛擬表對應的數據存放在一個可配置的內存空間中,能夠記錄并顯示每一次SQL請求的來源、執行狀態及統計信息,由于存放這些記錄的內存是有限的,因此到達一定內存使用量,會觸發淘汰。
- sql_audit 每隔 1s 會檢測后臺任務并根據以下標準決定是否淘汰:
- sql_audit 內存最大可使用上限為?avail_mem_limit = min (OBServer 可使用內存 *10%,sql_audit_memory_limit)。
- 當?avail_mem_limit?在 [64M, 100M] 范圍內時, 內存使用達到?avail_mem_limit-20M?時觸發淘汰。
- 當?avail_mem_limit?在 [100M, 5G] 范圍內時, 內存使用達到?availmem_limit*0.8?時觸發淘汰。
- 當?avail_mem_limit?在 [5G, +∞)范圍內時, 內存使用達到?availmem_limit-1G?時觸發淘汰。
- 當 sql_audidt 記錄數超過 900 萬條時,觸發淘汰。
- sql_audit 根據以下標準決定是否停止淘汰:
- 如果是達到內存上限觸發淘汰則:
- 當?avail_mem_limit?在 [64M, 100M] 時, 內存使用淘汰到?avail_mem_limit-40M?時停止淘汰。
- 當?avail_mem_limit?在 [100M, 5G] 時, 內存使用淘汰到?availmem_limit*0.6?時停止淘汰。
- 當?avail_mem_limit?在 [5G, +∞] 時, 內存使用淘汰到?availmem_limit-2G?時停止淘汰。
- 如果是達到記錄數上限觸發的淘汰則淘汰到 800 萬行記錄時停止淘汰。
2. sql_audit視圖字段介紹
| 字段名稱 | 類型 | 描述 |
| SVR_IP | varchar(32) | ip地址 |
| SVR_PORT | bigint(20) | 端口號 |
| REQUEST_ID | bigint(20) | 請求的id號 |
| TRACE_ID | varchar(128) | 這條語句的trace_id |
| CLIENT_IP | varchar(32) | 發送請求的client ip |
| CLIENT_PORT | bigint(20) | 發送請求的client port |
| TENANT_ID | bigint(20) | 發送請求的租戶id |
| TENANT_NAME | varchar(64) | 發送請求的租戶 名稱 |
| USER_ID | bigint(20) | 發送請求的用戶id |
| USER_NAME | varchar(64) | 發送請求的用戶名稱 |
| SQL_ID | varchar(32) | 這條SQL的id |
| QUERY_SQL | varchar(32768) | 實際的SQL語句 |
| PLAN_ID | bigint(20) | 執行計劃id |
| AFFECTED_ROWS | bigint(20) | 影響行數 |
| RETURN_ROWS | bigint(20) | 返回行數 |
| PARTITION_CNT | bigint(20) | 該請求涉及的分區數 |
| RET_CODE | bigint(20) | 執行結果返回碼 |
| EVENT | varchar(64) | 最長等待事件名稱 |
| P1TEXT | varchar(64) | 等待事件參數1 |
| P1 | bigint(20) unsigned | 等待事件參數1的值 |
| P2TEXT | varchar(64) | 等待事件參數2 |
| P2 | bigint(20) unsigned | 等待事件參數2的值 |
| P3TEXT | varchar(64) | 等待事件參數3 |
| P3 | bigint(20) unsigned | 等待事件參數3的值 |
| LEVEL | bigint(20) | 等待事件的level級別 |
| WAIT_CLASS_ID | bigint(20) | 等待事件所屬的class id |
| WAIT_CLASS# | bigint(20) | 等待事件所屬的class 的下標 |
| WAIT_CLASS | varchar(64) | 等待事件所屬的class 名稱 |
| STATE | varchar(19) | 等待事件的狀態 |
| WAIT_TIME_MICRO | bigint(20) | 該等待事件所等待的時間 |
| TOTAL_WAIT_TIME_MICRO | bigint(20) | 執行過程所有等待的總時間 |
| TOTAL_WAITS | bigint(20) | 執行過程總等待的次數 |
| RPC_COUNT | bigint(20) | 發送rpc個數 |
| PLAN_TYPE | bigint(20) | 執行計劃類型 |
| IS_INNER_SQL | tinyint(4) | 是否內部sql請求 |
| IS_EXECUTOR_RPC | tinyint(4) | 當前請求是否rpc請求 |
| IS_HIT_PLAN | tinyint(4) | 是否命中plan_cache |
| REQUEST_TIME | bigint(20) | 開始執行時間點 |
| ELAPSED_TIME | bigint(20) | 接收到請求到執行結束消耗 總時間 |
| NET_TIME | bigint(20) | 發送rpc到接收到請求時間 |
| NET_WAIT_TIME | bigint(20) | 接收到請求到進入隊列時間 |
| QUEUE_TIME | bigint(20) | 請求在隊列等待事件 |
| DECODE_TIME | bigint(20) | 出隊列后decode時間 |
| GET_PLAN_TIME | bigint(20) | 開始process到獲得plan時間 |
| EXECUTE_TIME | bigint(20) | plan執行消耗時間 |
| APPLICATION_WAIT_TIME | bigint(20) unsigned | 所有application類事件的總時間 |
| CONCURRENCY_WAIT_TIME | bigint(20) unsigned | 所有concurrency類事件的總時間 |
| USER_IO_WAIT_TIME | bigint(20) unsigned | 所有user_io類事件的總時間 |
| SCHEDULE_TIME | bigint(20) unsigned | 所有schedule類事件的時間 |
| ROW_CACHE_HIT | bigint(20) | 行緩存命中次數 |
| BLOOM_FILTER_CACHE_HIT | bigint(20) | bloom filter緩存命中次數 |
| BLOCK_CACHE_HIT | bigint(20) | 塊緩存命中次數 |
| BLOCK_INDEX_CACHE_HIT | bigint(20) | 塊索引緩存命中次數 |
| DISK_READS | bigint(20) | 物理讀次數 |
| EXECUTION_ID | bigint(20) | 執行ID |
| SESSION_ID | bigint(20) | session id |
| RETRY_CNT | bigint(20) | 重試次數 |
| TABLE_SCAN | tinyint(4) | 判斷該請求是否含全表掃描 |
| CONSISTENCY_LEVEL | bigint(20) | 一致性級別 |
| MEMSTORE_READ_ROW_COUNT | bigint(20) | MEMSTORE中的讀行數 |
| SSSTORE_READ_ROW_COUNT | bigint(20) | SSSTORE中讀的行數 |
| REQUEST_MEMORY_USED | bigint(20) | 該請求消耗的內存 |
- 一些重要的事件間隔
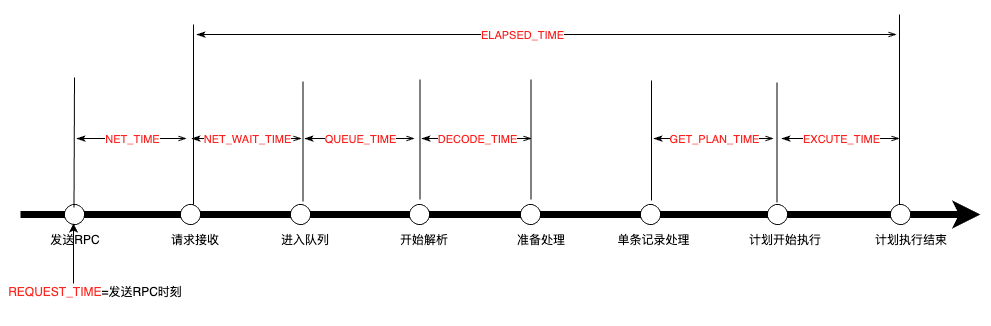
3. 基于sql_audit的診斷case
3.1. 最近100s某個租戶的TOP SQL耗時監控
- 檢查語句:
-- OceanBase 4.0.0.0及以上版本,請替換tenant_name的值為實際的租戶名
select /*+read_consistency(weak),query_timeout(100000000)*/ SQL_ID,count(1),avg(ELAPSED_TIME),avg(EXECUTE_TIME),avg(QUEUE_TIME),avg(AFFECTED_ROWS),avg(GET_PLAN_TIME)
from gv$ob_sql_audit
where time_to_usec(now(6))-request_time <1000000000
and tenant_name='test_tenant'
group by SQL_ID order by avg(ELAPSED_TIME)*count(1) desc limit 20;-- OceanBase 4.0.0.0以下版本,請替換tenant_name的值為實際的租戶名
select /*+read_consistency(weak),query_timeout(100000000)*/ SQL_ID,count(1),avg(ELAPSED_TIME),avg(EXECUTE_TIME),avg(QUEUE_TIME),avg(AFFECTED_ROWS),avg(GET_PLAN_TIME)
from gv$sql_audit
where time_to_usec(now(6))-request_time <1000000000
and tenant_name='test_tenant'
group by SQL_ID order by avg(ELAPSED_TIME)*count(1) desc limit 20 ;- 期望值: 觀察SQL 整體耗時,cpu_time, 物理讀及邏輯消耗是否合理,一般單行insert 和 主鍵查詢 500us以內
- 對應建議:通過SQL語義與表結構比對,確認執行計劃是否合理,耗時是否正常
3.2.?查看集群中 SQL 請求流量是否均勻
- 思路:我們首先可以查出某個時間段內數據庫中所有 SQL 并按照 server 級別進行聚合,再統計該時間段內每臺機器上的 QPS。
- 語句:
-- OceanBase 4.0.0.0及以上版本,請替換t1.tenant_id的值為實際租戶的值
select t2.zone, t1.svr_ip, count(*) as QPS
from oceanbase.gv$ob_sql_audit t1, oceanbase.__all_server t2
where t1.svr_ip = t2.svr_ip and t1.tenant_id = 1001
and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 1000000)
and request_time < time_to_usec(now())
group by t1.svr_ip order by QPS;-- OceanBase 4.0.0.0以下版本,請替換t1.tenant_id的值為實際租戶的值
select t2.zone, t1.svr_ip, count(*) as QPS
from oceanbase.gv$ob_sql_audit t1, oceanbase.__all_server t2
where t1.svr_ip = t2.svr_ip and t1.tenant_id = 1001
and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 1000000)
and request_time < time_to_usec(now())
group by t1.svr_ip order by QPS;
3.3.?某個時間段請求次數排在 TOP-N 的 SQL
- 思路:我們首先可以查出某個時間段內數據庫中所有 SQL 并按照 sql_id 級別進行聚合,再統計該時間段內每個SQL_ID的 QPS,取出top值。
- 語句:
-- OceanBase 4.0.0.0及以上版本,請替換tenant_id的值為實際租戶的值
select SQL_ID, count(*) as QPS, avg(t1.elapsed_time) RT
from oceanbase.gv$ob_sql_audit t1
where tenant_id = 1001 and IS_EXECUTOR_RPC = 0
and request_time > (time_to_usec(now()) - 10000000)
and request_time < time_to_usec(now())
group by t1.sql_id order by QPS desc limit 10;-- OceanBase 4.0.0.0以下版本,請替換tenant_id的值為實際租戶的值
select SQL_ID, count(*) as QPS, avg(t1.elapsed_time) RT
from oceanbase.gv$sql_audit t1
where tenant_id = 1001 and IS_EXECUTOR_RPC = 0
and request_time > (time_to_usec(now()) - 10000000)
and request_time < time_to_usec(now())
group by t1.sql_id order by QPS desc limit 10;3.4.?定位所有SQL中消耗CPU最多的sql
思路:消耗CPU的時間是elapsed_time - queue_time,因為queue_time的過程中是在排隊,并不消耗cpu. 排查消耗CPU最多的sql在cpu飆高的場景非常有用
語句:
-- OceanBase 4.0.0.0及以上版本,請替換tenant_id的值為實際租戶的值
select sql_id, substr(query_sql, 1, 20) as query_sql, sum(elapsed_time - queue_time) sum_t, count(*) cnt, avg(get_plan_time), avg(execute_time)
from oceanbase.gv$ob_sql_audit
where tenant_id = 1001 and request_time > (time_to_usec(now()) - 10000000) and request_time < time_to_usec(now())
group by sql_id order by sum_t desc limit 10;-- OceanBase 4.0.0.0以下版本,請替換tenant_id的值為實際租戶的值
select sql_id, substr(query_sql, 1, 20) as query_sql, sum(elapsed_time - queue_time) sum_t, count(*) cnt, avg(get_plan_time), avg(execute_time)
from oceanbase.gv$sql_audit
where tenant_id = 1001 and request_time > (time_to_usec(now()) - 10000000) and request_time < time_to_usec(now())
group by sql_id order by sum_t desc limit 10;3.5.?查看SQL的執行是否出現大量請求不合理的使用了遠程執行
思路:sql_audit的PLAN_TYPE字段可以看到該SQL的執行計劃類型,
- plan_type=1?:本地執行計劃。性能最好。
- plan_type=2?: 遠程執行計劃。
- plan_type=3?: 分布式執行計劃。包含本地執行計劃和遠程執行計劃。
一般情況下,如果出現遠程執行比較多時可能時出現切主或proxy客戶端路由不準的情況。
語句:
-- OceanBase 4.0.0.0及以上版本,請替換tenant_id的值為實際租戶的值
select count(*), plan_type
from oceanbase.gv$ob_sql_audit
where tenant_id = 1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 10000000) and request_time < time_to_usec(now())
group by plan_type ;-- OceanBase 4.0.0.0以下版本,請替換tenant_id的值為實際租戶的值
select count(*), plan_type
from oceanbase.gv$sql_audit
where tenant_id = 1001 and IS_EXECUTOR_RPC = 0 and request_time > (time_to_usec(now()) - 10000000) and request_time < time_to_usec(now())
group by plan_type ;3.6. 查詢全表掃描的SQL
思路:sql_audit的TABLE_SCAN字段是標識語句是否走了全表掃描,=1 表示全表掃描了。可以進一步分析一下SQL是否可以添加索引來防止全表掃描:
語句:
-- OceanBase 4.0.0.0及以上版本,請替換tenant_id的值為實際租戶的值
select query_sql
from oceanbase.gv$ob_sql_audit
where table_scan = 1 and tenant_id = 1001
group by sql_id;-- OceanBase 4.0.0.0以下版本,請替換tenant_id的值為實際租戶的值
select query_sql
from oceanbase.gv$sql_audit
where table_scan = 1 and tenant_id = 1001
group by sql_id;3.7 如何分析RT突然抖動的SQL?
? ? 在線上如果出現RT抖動,但RT并不是持續很高的情況,可以考慮在抖動出現后,立刻將sql audit關閉(alter system set ob_enable_sql_audit = 0),從而確保該抖動的SQL請求在sql audit中存在;然后通過3.3章節的【某個時間段請求次數排在 TOP-N 的 SQL】,分析有異常的SQL。
? ?如果在sql_audit中找到了對應的RT異常請求,則可以分析該請求在sql audit中記錄:
- 查看retry次數是否很多(RETRY_CNT, 如果次數很多,則是否考慮是否有鎖沖突或切主等情況)
- 查看queue time是不是很大(QUEUE_TIME字段)
- 查看獲取執行計劃時間(GET_PLAN_TIME), 如果時間很長,一般會伴隨IS_HIT_PLAN = 0, 表示沒有命中plan cache)
- 查看EXECUTE_TIME是否很長,如果很長,則
? ? ?a. 查看是否有很長等待事件耗時
? ? ?b. 查看訪問的行數是否很多, 看SSSTORE_READ_ROW_COUNT, MEMSTORE_READ_ROW_COUNT兩個字段, 比如大小賬號場景可能導致rt抖動。
| 第一篇 | “神醫”的修煉秘籍——《OceanBase診斷系列》之一 |
| 第二篇 | 一起走進sql_audit性能視圖——《OceanBase診斷系列》之二 |




)
![[Java 探索者之路] 一個大廠都在用的分布式任務調度平臺](http://pic.xiahunao.cn/[Java 探索者之路] 一個大廠都在用的分布式任務調度平臺)





)



)

)

)