關于無人機相關的場景在我們之前的博文也有一些比較早期的實踐,感興趣的話可以自行移步閱讀即可:
《deepLabV3Plus實現無人機航拍目標分割識別系統》
《基于目標檢測的無人機航拍場景下小目標檢測實踐》
《助力環保河道水質監測,基于yolov5全系列模型【n/s/m/l/x】開發構建不同參數量級的無人機航拍河道污染漂浮物船只目標檢測識別系統,集成GradCAM對模型檢測識別能力進行分析》
《基于YOLO開發構建紅外場景下無人機航拍車輛實例分割檢測識別分析系統》
《基于輕量級YOLO模型開發構建大疆無人機檢測系統》
《基于輕量級YOLOv5n/s/m三款模型開發構建基于無人機視角的高空紅外目標檢測識別分析系統,對比測試分析性能》
《基于目標檢測實現遙感場景下的車輛檢測計數》
《共建共創共享》
《助力森林火情煙霧檢測預警,基于YOLOv5全系列模型[n/s/m/l/x]開發構建無人機航拍場景下的森林火情檢測識別系統》
《UAV 無人機檢測實踐分析》
《助力森林火情預警檢測,基于YOLOv7-tiny、YOLOv7和YOLOv7x開發構建無人機航拍場景下的森林火情檢測是別預警系統》
?《無人機助力電力設備螺母缺銷智能檢測識別,python基于YOLOv5開發構建電力設備螺母缺銷小目標檢測識別系統》
《無人機助力電力設備螺母缺銷智能檢測識別,python基于YOLOv7開發構建電力設備螺母缺銷小目標檢測識別系統》
前面因為時間、資源等因素的限制我們沒有辦法對YOLOv8全系列不同參數的模型進行全面的對比分析,僅僅開發了最為輕量級的n系列的模型,感興趣的話可以自行移步閱讀即可:?
《實踐航拍小目標檢測,基于輕量級YOLOv8n開發構建無人機航拍場景下的小目標檢測識別分析系統》
本文的內容則是圍繞開發YOLOv8全系列五款不同參數量級的模型來進行整體的對比分析。
首先看下實例效果:

簡單看下實例數據集:

如果對YOLOv8開發構建自己的目標檢測項目有疑問的可以看下面的文章,如下所示:
《基于YOLOv8開發構建目標檢測模型超詳細教程【以焊縫質量檢測數據場景為例》
非常詳細的開發實踐教程。本文這里就不再展開了,因為從YOLOv8開始變成了一個安裝包的形式,整體跟v5和v7的使用差異還是比較大的。
非常詳細的開發實踐教程。本文這里就不再展開了,因為從YOLOv8開始變成了一個安裝包的形式,整體跟v5和v7的使用差異還是比較大的。
YOLOv8核心特性和改動如下:
1、提供了一個全新的SOTA模型(state-of-the-art model),包括 P5 640 和 P6 1280 分辨率的目標檢測網絡和基于YOLACT的實例分割模型。和 YOLOv5 一樣,基于縮放系數也提供了 N/S/M/L/X 尺度的不同大小模型,用于滿足不同場景需求
2、骨干網絡和 Neck 部分可能參考了 YOLOv7 ELAN 設計思想,將 YOLOv5 的 C3 結構換成了梯度流更豐富的 C2f 結構,并對不同尺度模型調整了不同的通道數,屬于對模型結構精心微調,不再是一套參數應用所有模型,大幅提升了模型性能。
3、Head 部分相比 YOLOv5 改動較大,換成了目前主流的解耦頭結構,將分類和檢測頭分離,同時也從Anchor-Based 換成了 Anchor-Free
4、Loss 計算方面采用了TaskAlignedAssigner正樣本分配策略,并引入了Distribution Focal Loss
5、訓練的數據增強部分引入了 YOLOX 中的最后 10 epoch 關閉 Mosiac 增強的操作,可以有效地提升精度
YOLOv8官方項目地址在這里,如下所示:

目前已經收獲超過1.7w的star量了。官方提供的預訓練模型如下所示:
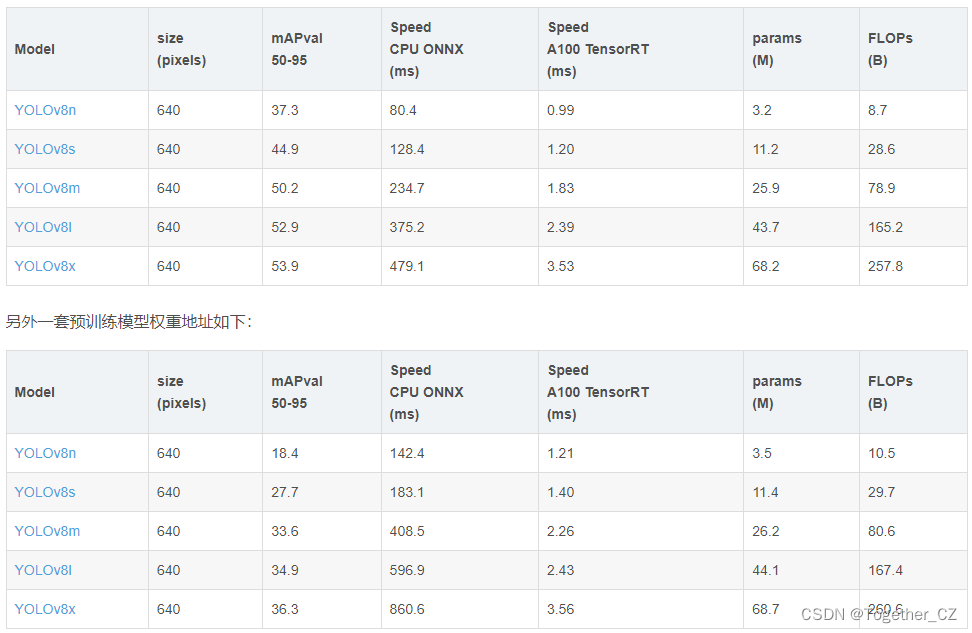
是基于Open Image V7數據集構建的,可以根據自己的需求進行選擇使用即可。
YOLOv8的定位不僅僅是目標檢測,而是性能強大全面的工具庫,故而在任務類型上同時支持:姿態估計、檢測、分類、分割、跟蹤多種類型,可以根據自己的需要進行選擇使用,這里就不再詳細展開了。
簡單的實例實現如下所示:
from ultralytics import YOLO# yolov8n
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8s
model = YOLO('yolov8s.yaml').load('yolov8s.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8m
model = YOLO('yolov8m.yaml').load('yolov8m.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8l
model = YOLO('yolov8l.yaml').load('yolov8l.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)# yolov8x
model = YOLO('yolov8x.yaml').load('yolov8x.pt') # build from YAML and transfer weights
model.train(data='data/self.yaml', epochs=100, imgsz=640)這里給出yolov8的模型文件如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 10 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
實驗階段保持著完全相同的參數設置,開發完成五款不同參數量級的模型來進行綜合全面的對比分析,等待訓練完成后我們來詳細看下結果。
【Precision曲線】
精確率曲線(Precision-Recall Curve)是一種用于評估二分類模型在不同閾值下的精確率性能的可視化工具。它通過繪制不同閾值下的精確率和召回率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率(Precision)是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率曲線。
根據精確率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察精確率曲線,我們可以根據需求確定最佳的閾值,以平衡精確率和召回率。較高的精確率意味著較少的誤報,而較高的召回率則表示較少的漏報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
精確率曲線通常與召回率曲線(Recall Curve)一起使用,以提供更全面的分類器性能分析,并幫助評估和比較不同模型的性能。

【Recall曲線】
召回率曲線(Recall Curve)是一種用于評估二分類模型在不同閾值下的召回率性能的可視化工具。它通過繪制不同閾值下的召回率和對應的精確率之間的關系圖來幫助我們了解模型在不同閾值下的表現。
召回率(Recall)是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。召回率也被稱為靈敏度(Sensitivity)或真正例率(True Positive Rate)。
繪制召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的召回率和對應的精確率。
將每個閾值下的召回率和精確率繪制在同一個圖表上,形成召回率曲線。
根據召回率曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
通過觀察召回率曲線,我們可以根據需求確定最佳的閾值,以平衡召回率和精確率。較高的召回率表示較少的漏報,而較高的精確率意味著較少的誤報。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。

【loss】

【F1值曲線】
F1值曲線是一種用于評估二分類模型在不同閾值下的性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)、召回率(Recall)和F1分數的關系圖來幫助我們理解模型的整體性能。
F1分數是精確率和召回率的調和平均值,它綜合考慮了兩者的性能指標。F1值曲線可以幫助我們確定在不同精確率和召回率之間找到一個平衡點,以選擇最佳的閾值。
繪制F1值曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率、召回率和F1分數。
將每個閾值下的精確率、召回率和F1分數繪制在同一個圖表上,形成F1值曲線。
根據F1值曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
F1值曲線通常與接收者操作特征曲線(ROC曲線)一起使用,以幫助評估和比較不同模型的性能。它們提供了更全面的分類器性能分析,可以根據具體應用場景來選擇合適的模型和閾值設置。

【mAP0.5】
mAP0.5,也被稱為mAP@0.5或AP50,指的是當Intersection over Union(IoU)閾值為0.5時的平均精度(mean Average Precision)。IoU是一個用于衡量預測邊界框與真實邊界框之間重疊程度的指標,其值范圍在0到1之間。當IoU值為0.5時,意味著預測框與真實框至少有50%的重疊部分。
在計算mAP0.5時,首先會為每個類別計算所有圖片的AP(Average Precision),然后將所有類別的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲線下面的面積,這個面積越大,說明AP的值越大,類別的檢測精度就越高。
mAP0.5主要關注模型在IoU閾值為0.5時的性能,當mAP0.5的值很高時,說明算法能夠準確檢測到物體的位置,并且將其與真實標注框的IoU值超過了閾值0.5。

【mAP0.5:0.95】
mAP0.5:0.95,也被稱為mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU閾值從0.5到0.95變化時,取各個閾值對應的mAP的平均值。具體來說,它會在IoU閾值從0.5開始,以0.05為步長,逐步增加到0.95,并在每個閾值下計算mAP,然后將這些mAP值求平均。
這個指標考慮了多個IoU閾值下的平均精度,從而更全面、更準確地評估模型性能。當mAP0.5:0.95的值很高時,說明算法在不同閾值下的檢測結果均非常準確,覆蓋面廣,可以適應不同的場景和應用需求。
對于一些需求比較高的場合,比如安全監控等領域,需要保證高的準確率和召回率,這時mAP0.5:0.95可能更適合作為模型的評價標準。
綜上所述,mAP0.5和mAP0.5:0.95都是用于評估目標檢測模型性能的重要指標,但它們的關注點有所不同。mAP0.5主要關注模型在IoU閾值為0.5時的性能,而mAP0.5:0.95則考慮了多個IoU閾值下的平均精度,從而更全面、更準確地評估模型性能。
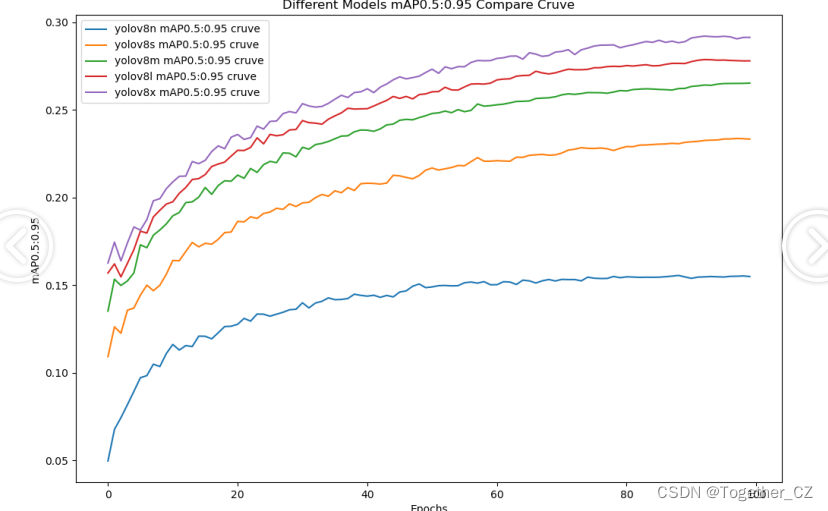
綜合實驗對比結果來看:五款不同參數量級的模型效果層次分明,不難看出n系列的模型效果最差,被其他幾款模型拉開了明顯的差距,s系列的模型性能次之,優于n系列的模型但是與其他3款模型依舊有明顯的差距,m系列模型效果居中不過依舊落后于l和x系列的模型,l系列的模型稍落后于x系列的模型,x系列的模型效果最優,結合參數量考慮最終線上考慮使用l系列的模型來作為最終的推理模型。
接下來看下l系列的模型詳情:
【離線推理實例】

【Batch實例】


【訓練可視化】

【PR曲線】
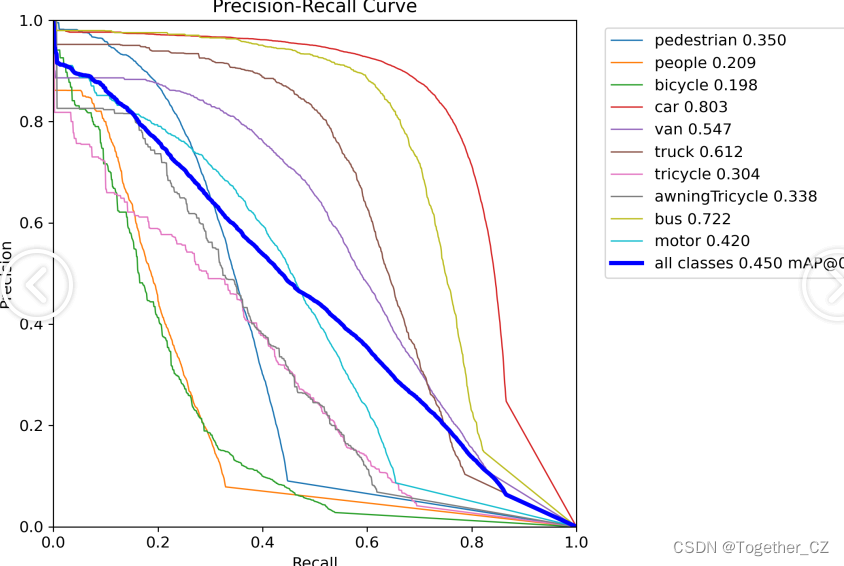
感興趣的話也都可以試試看!
如果自己不具備開發訓練的資源條件或者是沒有時間自己去訓練的話這里我提供出來對應的訓練結果可供自行按需索取。
單個模型的訓練結果默認YOLOv8s
全系列五個模型的訓練結果總集

)



)

)

)
)








