近日,我們開源了有道自研的RAG(Retrieval Augmented Generation) 引擎QAnything。該引擎允許用戶上傳PDF、圖片、Word、Excel、PowerPoint等多種格式的文檔,并實現類似于ChatGPT的互動問答功能,其中每個答案都能精確追溯到相應的文檔段落來源。QAnything 支持純本地部署,上傳文檔數量無上限,問答準確率高。
QAnything自開源以來,迅速吸引了開發者社區的廣泛關注,并很快登上了GitHub trending榜單。短短一個月內,下載次數已達數萬次,其中,我們的語義嵌入排序模型BCEmbedding更是達到了驚人的60萬次下載。根據社區的熱情反饋,我們決定分享QAnything背后的研發故事、技術路線選擇以及我們的經驗,希望能夠為社區帶來啟發。
QAnything的起源
與市場上的其他Retrieval Augmented Generation (RAG) 產品相比,QAnything引擎的研發軌跡略顯不同。它不是一開始就被設定為一個具體的項目目標,而是在項目進展中,通過不斷的探索和實踐,逐步成形的。這個過程雖然經歷了一些波折,但正是這些經歷,讓我們在RAG領域積累了豐富的實踐經驗。
從文檔翻譯到文檔問答
QAnything的研發團隊最初專注于文檔翻譯。2022年我們啟動了一個為期一年的文檔翻譯的升級的項目,到2023年3月份上線,效果提升顯著。正好那時候ChatGPT和類似技術正在興起,我們意識到這正是將我們現有技術擴展至文檔問答的絕佳時機。因此,我們毫不猶豫地為我們的文檔翻譯服務增添了問答功能,該功能能夠根據文檔內容自動推薦問題并提供答案,于5月份正式推出。

(視頻鏈接:https://www.bilibili.com/video/BV1fw4m1Z7QX/)
之所以能夠輕松地擴展到文檔問答,是因為有道在文檔翻譯領域的深厚積累。我們的文檔翻譯服務因其卓越的性能而聞名,這主要得益于兩大核心技術:先進的翻譯引擎和精準的文檔解析/OCR技術。多年來,在翻譯和OCR領域的持續探索和創新,為我們構建Retrieval Augmented Generation (RAG) 系統提供了堅實的基礎。
首先,核心技術方面,我們的翻譯模型基于Transformer架構,這與當前研究領域的大型語言模型(LLM)緊密相連,實質上并無顯著區別。所謂LLM,就是很大的Transformer模型,就是我們天天在研究的東西。ChatGPT出來后,我們之所以能迅速掌握并擴展我們的模型,例如開發了針對教育場景的“子曰”大模型,這一切都得益于我們對Transformer模型的深入理解和應用。
接著,關于RAG系統,它不僅僅是外部數據和LLM的簡單疊加。鑒于用戶文檔的多樣性,特別是PDF文件中復雜的圖文混排,僅僅提取文本往往會帶來信息的失真。例如,將具有邏輯連貫性的文本分割成多個片段,或者將圖表數據錯誤地融入文本,這些都會嚴重影響信息的準確性。正因如此,我們長期致力于文檔解析技術的研發,能夠精確地識別和分析文檔中的每一部分,無論是段落、圖表、公式還是其他元素,確保將用戶的查詢以最適合機器處理的方式進行組織和檢索。
借助有道翻譯龐大的用戶基礎,我們得以在實際應用中不斷完善和優化我們的系統。日均活躍用戶數達百萬級別的大數據反饋,為我們提供了寶貴的實踐經驗,使我們能夠持續提升系統性能,滿足用戶對高質量翻譯和問答服務的需求。
從文檔問答到速讀
有道速讀(https://read.youdao.com) 是我們算法研究員從自己的需求出發做的產品。有道翻譯桌面端雖然已經上線了文檔問答,但是它主要是面向大眾設計的,適合通用的文檔。我們經常讀論文,希望有一些論文相關的更個性一點的功能。而有道翻譯用戶量太大了,不方便隨意改動。
我們做有道速讀,一開始主要是面向論文閱讀做的。這也是我們新技術的試驗田,迭代快一點。我們看到了wordtune出了個段落摘要和對照的功能,用著特別爽,但是很貴,我們就把那個功能與RAG整合在一起,又能摘要讀段落,又能問答,方便溯源。論文一般都會講自己方法多好,我們就把其他人對這篇論文的評價信息也給整合起來了,做了論文口碑,把一篇論文的優勢和局限更客觀的展示出來。在內部做研發的過程中,有個研究人員希望能自動寫綜述,我們就在速讀上加上了自動綜述的功能,對每一篇論文,把前后引用的論文全部抓來,自動做問答,然后整理成報告。
有道速讀可以看作是RAG在某個垂直領域的應用。因為里面的口碑、綜述、文章解讀等功能,都可以認為是先設置一個模版,有一堆問題(或者自動生成的),然后通過自問自答的方式,生成關鍵信息,最后再總結潤色成文,這一切過程都是全自動的。
速讀給了我們一個訓練場,讓我們調試應用新技術,這個過程也學到了很多,團隊進步很大。當然,速讀現在也不只局限于論文閱讀了。
從速讀到Qanything
速讀主要是單篇問答(6月份剛上線時候只支持單篇,現在也支持多篇問答了,和QAnything主要區別是速讀更偏重閱讀的場景,QAnything偏重問答的場景,底層引擎是一樣的),且只支持pdf的格式。QAnything是支持多文檔問答的,不限文檔格式。
做Qanything有個契機。去年7月份的時候,網易的IT集團想升級他們的客服系統,找到我們,問能否基于他們的IT文檔做一個自動問答機器人,因為他們看到了我們的文檔問答效果,覺得做的不錯。于是我們就拿著他們的文檔和歷史的問答數據快速實驗了一下,發現經過我們的系統后,70%的轉人工的次數都可以被省下來,由AI來回答。
客服這個場景,用戶的文檔格式非常多樣,回答問題需要綜合各種文檔的內容。于是我們在這個場景需求的推動下,做了多文檔問答。我們給這個多文檔問答系統取了一個大氣的名字,叫Qanything,中文名字叫“萬物皆可問”。
QAnything,也是我們的愿景。QAnything的前兩個字母是Q和A,也是問答的意思,后面是anything,希望什么都可以放進去,什么東西都可以提問。
在去年8月份的時候,除了內部客戶要,有道智云的外部B端客戶也需要這樣的多文檔問答系統,還需要私有化。于是我們就做了大模型的小型化適配,做了私有化的版本,可以直接跑在游戲本上的。整個系統是完整的,可直接使用,也可以通過API調用。給了客戶,賣了點錢。

(視頻鏈接:https://www.bilibili.com/video/BV1FC411s7gQ/)
從QAanyhing到升學咨詢
我們一直將qanything的體驗頁掛在網上,主要是為了做 有道智云 toB生意的時候給外部用戶體驗的,也沒怎么宣傳。去年9月份的時候,突然有一天,我們的精品課事業部(有道領世)的人找上門來,說希望合作QAnything。原來,他們不知道通過哪里的渠道知道了我們的QAnything,去體驗了下,發現效果很好。比他們自己用langchain/lamma index+chatgpt 搭建了很久的系統,效果要好很多。
有道領世在高中升學領域深耕多年,積累了海量的升學數據資料,有幾萬份的文檔,還有大量的數據存儲在數據庫里。我們的任務是通過QAnything,結合這樣的積累的數據,打造出一個私人AI規劃師,針對每個家長和學生,提供個性化、更加全面、專業、及時的升學規劃服務。
一開始,我們把全部數據直接塞入我們QAnything系統,升學百科問答只有45%的準確率。經過一段時間的反復迭代優化,我們把確確率提升到了95%。目前系統可以解答用戶關于高考政策、升學路徑、學習生活以及職業規劃等各種問題。未來隨著不斷地數據補充和更新,準確率會一直上漲。
有道AI升學規劃師產品做出來后,我們都為它的體驗感到驚艷。

(視頻鏈接:https://www.bilibili.com/video/BV1Bt421b7am/)
Qanything 開源
今年1月份,我們整理了下我們的QAnything的代碼和模型,將適合開源的部分開放出來了。我們做這事,希望能和社區一起,共同推動RAG技術應用的發展。最近這個月,社區給了我們很對反饋,也讓我們受益良多。
QAnything架構解析
這次開源包括了模型和系統等所有必要的模塊。模型方面包括ocr解析、embedding/rerank,以及大模型。系統方面包括向量數據庫、mysql數據庫、前端、后端等必要的模塊。整個引擎的功能完整,用戶可以直接下載,不需要再搭配其他的模塊即可使用。系統可擴展性也非常好,只要硬盤內存足夠,就可以一直建庫,支持無上限的文檔。
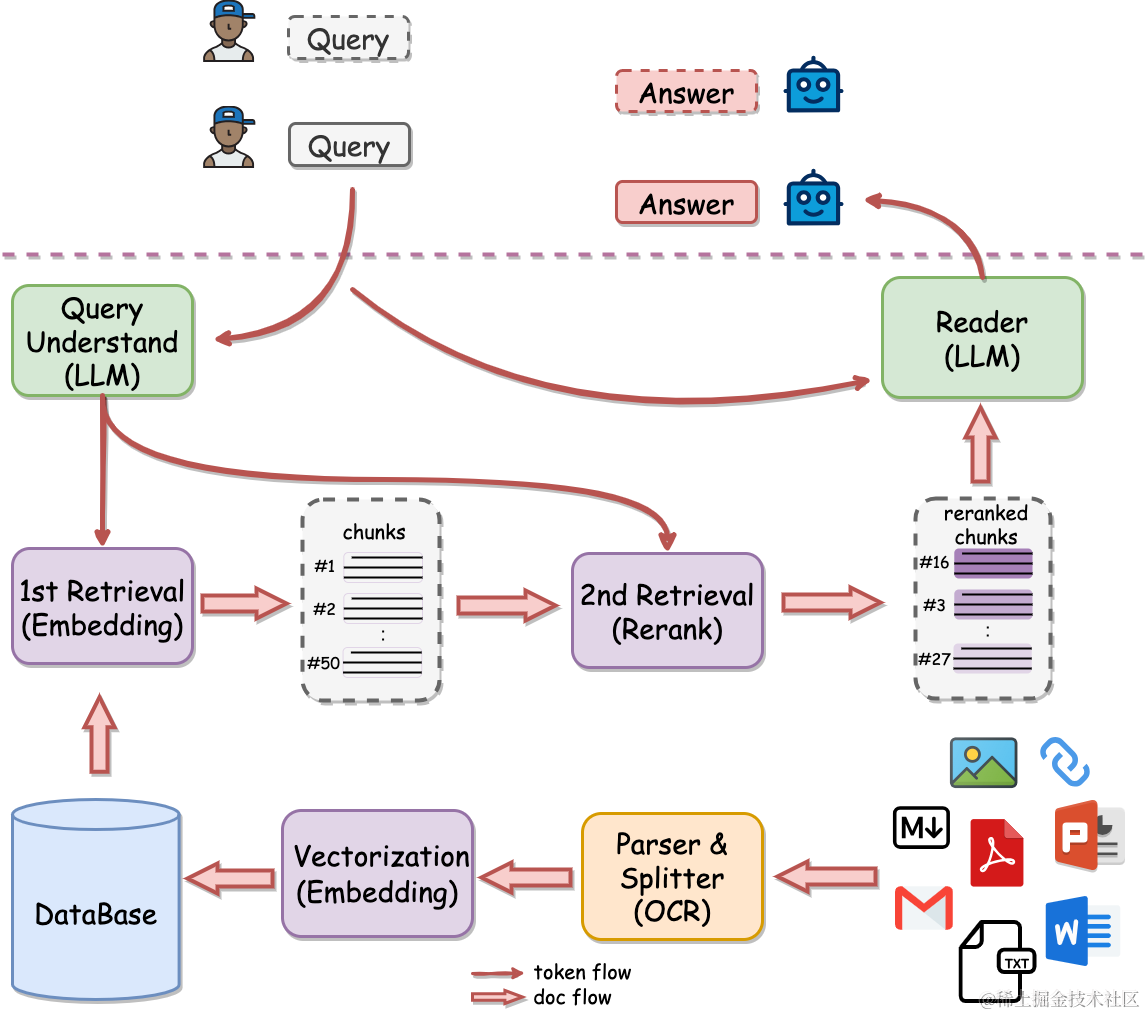
QAnything的整體架構圖
系統的工作流程主要包含三個環節:
- 索引(indexing):文本索引的構建包括以下步驟:文檔解析、文本分塊、Embedding向量化和創建索引。先將不同格式的原始文件解析轉換為純文本,再把文本切分成較小的文本塊。通過Embedding為每一個文本塊生成一個向量表示,用于計算文本向量和問題向量之間的相似度。創建索引將原始文本塊和Embedding向量以鍵值對的形式存儲,以便將來進行快速和頻繁的搜索。
- 檢索(Retrieval):使用Embedding模型將用戶輸入問題轉換為向量,計算問題的Embedding向量和語料庫中文本塊Embedding向量之間的相似度,選擇相似度最高的前K個文檔塊作為當前問題的增強上下文信息。
- 生成(Generation):將檢索得到的前K個文本塊和用戶問題一起送進大模型,讓大模型基于給定的文本塊來回答用戶的問題。
Bcembedding模型
Embedding是RAG系統里面最關鍵的模塊。為啥要自己訓練embedding模型?一開始我們也是直接去嘗試openai的ada embedding以及開源的embedding模型。但是我們很快發現,這樣做有很大弊端。首先,在我們的業務場景下,外部的embedding效果并不如宣傳的那么好。openai的embedding接口除了效果不好外,還很慢。我們后來自研了embedding,因為是放在自己服務器上,調用起來比openai接口快一百倍。其次,很多開源的embedding模型在mteb等地方刷傍刷的很高,但是那些刷榜的分值并不完全能反映真實的效果。第三,我們業務場景有很多混合語言的情況,比如庫里面放的是英文的文檔,用戶用中文去問答。這種跨語種的能力,現有模型支持不好。第四,單純的embedding在檢索排序上天花板比較低,所以我們在embedding的基礎上又做了rerank,共享同樣的底座,head不一樣。
為啥我們自己訓練的模型會比openai的效果好?我們認為可能是通才和專才的區別。openai是通才,但是它的效果遠未達到萬能的地步,大家不必迷信。在我們的場景下(客服問答以及一些toB客戶的場景),openai的ada2 embedding的檢索準確率只有60%,而經過訓練的bcembedding檢索準確率可以達到95%。
我們自研的BCEmbedding,總的來講有兩個特色:
- 中英雙語和跨語種能力
我們收集開源數據集(包括摘要、翻譯、語義改寫、問答等),來實現模型通用的基礎語義表征能力。為了實現一個模型就可以實現中英雙語、跨語種的檢索任務,我們依賴網易有道多年積累的強大的翻譯引擎,對數據進行處理,獲得中英雙語和跨語種數據集。實現一個模型就可以完成雙語和跨語種任務。
- 多領域覆蓋我們分析現有市面上常見或可能的應用場景,收集了包括:教育、醫療、法律、金融、百科、科研論文、客服(faq)、通用QA等場景的語料,使得模型可以覆蓋盡可能多的應用場景。同樣的依靠網易有道翻譯引擎,獲得多領域覆蓋的中英雙語和跨語種數據集。實現一個模型就可以支持多業務場景,用戶可以開箱即用。
我們在訓練的過程中,發現一個有意思的現象,數據標簽的構建對模型的效果影響非常大。相信大家一定聽過“難例挖掘”的概念,在機器學習中模型性能上不去時候,經常是因為一些例子比較難,模型訓練時候見的比較少,多挖掘一些難例給模型,就能夠提升模型的性能。但是在embedding訓練的時候,我們發現難例挖掘反而會降低模型的性能。我們猜測原因是embedding模型本身的能力有限,不應該給過難的任務。我們想要讓模型做多領域覆蓋,多語種、跨語種覆蓋(還要覆蓋代碼檢索和工具檢索),這已經給Embedding增加很多負擔了,應該想想怎么給Embedding“減負”。
因為Embedding模型是dual-encoder,query和passage在“離線”地語義向量提取時沒有信息交互,全靠模型將query和passages“硬”編碼到語義空間中,再去語義檢索。而rerank的階段,cross-encoder可以充分交互query和passage信息,潛力大的多。所以我們定了目標,embedding盡可能提高召回,rerank盡可能提高精度。
我們在Embedding模型訓練中,不使用難負樣例挖掘,只在Reranker中使用。以下是我們的幾點看法,供參考。
- 我們在訓練Embedding模型時發現,過難的負樣本對模型訓練有損害,訓練過程中會使模型“困惑”,影響模型最終性能[19]。Embedding模型算法本身性能上限有限,很多難負樣本只有細微差異,“相似”程度很高。就像讓一個小學生強行去學習微積分,這種數據對Embedding訓練是“有毒”的。
- 在大量的語料庫中,沒有人工校驗的自動化難負樣例挖掘,難免會“挖到正例”。語料庫很大,里面經常會混有正例,利用已有Embedding模型去挖掘正例,經常會挖到正例,毒害模型訓練。應該有不少調參工程師有這種慘痛經歷。
- 其實所謂的“正例”和“難負樣例”應該是根據你業務的定義來的。RAG場景下,之前人們認為的難負樣例可能就成為了正例。比如要回答“小明喜歡吃蘋果嗎?”,RAG場景下召回“小明喜歡吃蘋果”和“小明不喜歡吃蘋果”都是符合目標的,而學術定義的語義相似這兩句話又是難負樣例。
所以回歸我們業務目標和好檢索器的“評判標準”,Embedding模型應該能盡量召回相關片段,不要將精排Reranker要干的事強壓在Embedding身上,“越俎代庖”終究會害了它。
檢索排序效果評測方式LlamaIndex(https://github.com/run-llama/llama_index)是一個著名的大模型應用的開源框架,在RAG社區中很受歡迎。最近,LlamaIndex博客(https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)對市面上常用的embedding和reranker模型進行RAG流程的評測,吸引廣泛關注。
為了公平起見,我們復刻LlamaIndex博客評測流程,將bce-embedding-base_v1和bce-reranker-base_v1與其他Embedding和Reranker模型進行對比分析。在此,我們先明確一些情況,LlamaIndex博客(https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)的評測只使用了llama v2(https://arxiv.org/abs/2307.09288)這一篇英文論文來進行評測的,所以該評測是在純英文、限定語種(英文)、限定領域(人工智能)場景下進行的。
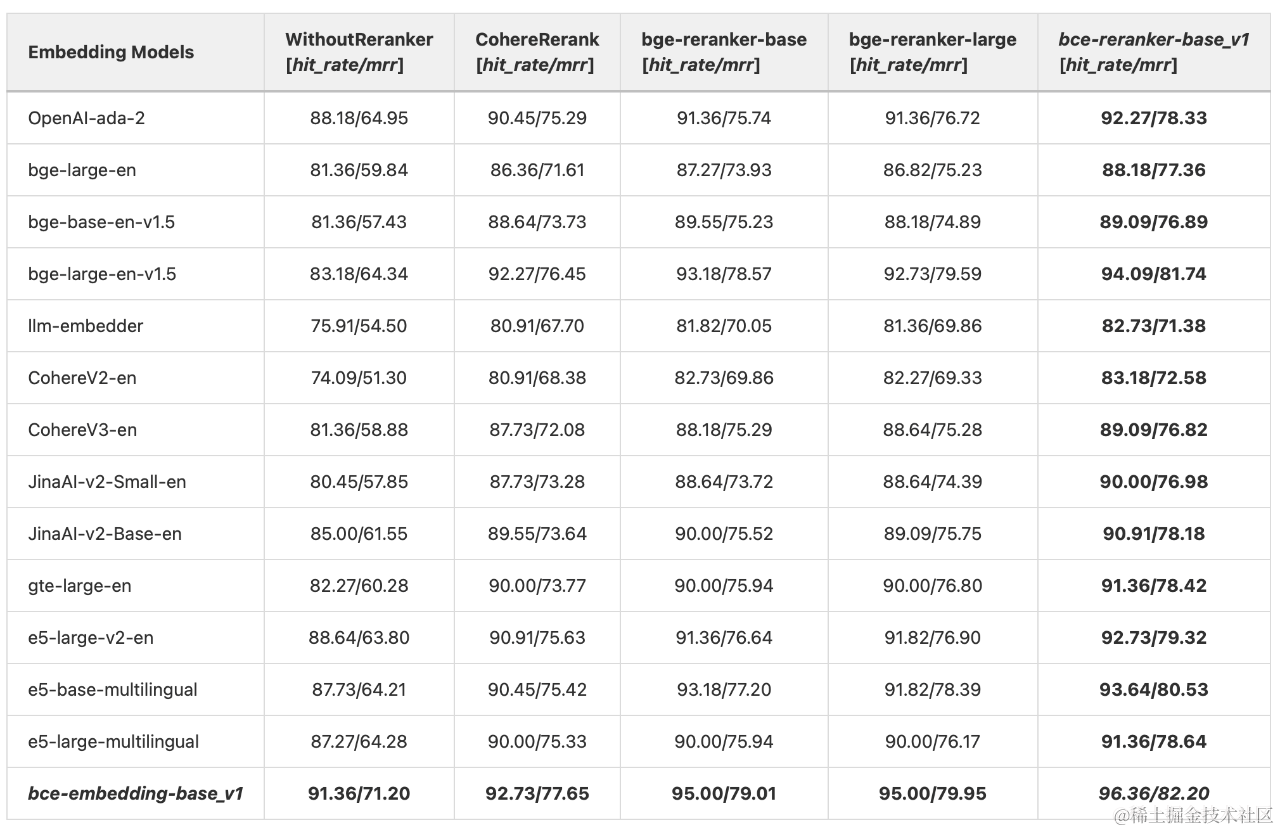
LlamaIndex博客評測復刻
如上表所示,
- 在沒有Reranker模塊的設置下,bce-embedding-base_v1顯著優于其他常見的開源和閉源英文embedding模型。
- 在相同reranker配置下(豎排對比),bce-embedding-base_v1也都是優于其他開源、閉源embedding模型。
- 在相同的embedding配置下(橫排對比),利用reranker模型可以顯著提升檢索效果,印證前面所述二階段檢索的優勢。bce-reranker-base_v1比其他常見的開源、閉源reranker模型具備更好的精排能力。
- 綜上,bce-embedding-base_v1和bce-reranker-base_v1的組合可以實現最好的效果。
多領域、多語種和跨語種RAG效果正如上所述的LlamaIndex博客(https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)評測有些局限,為了兼容更真實更廣的用戶使用場景,評測算法模型的 領域泛化性,雙語和跨語種能力,我們按照該博客的方法構建了一個多領域(計算機科學,物理學,生物學,經濟學,數學,量化金融等領域)的中英雙語種和中英跨語種評測數據,CrosslingualMultiDomainsDataset(https://huggingface.co/datasets/maidalun1020/CrosslingualMultiDomainsDataset)。
為了使我們這個數據集質量盡可能高,我們采用OpenAI的 gpt-4-1106-preview用于數據生成。為了防止數據泄漏,評測用的英文數據我們選擇了ArXiv上2023年12月30日最新的各領域英文文章;中文數據選擇Semantic Scholar相應領域高質量的盡可能新的中文文章。
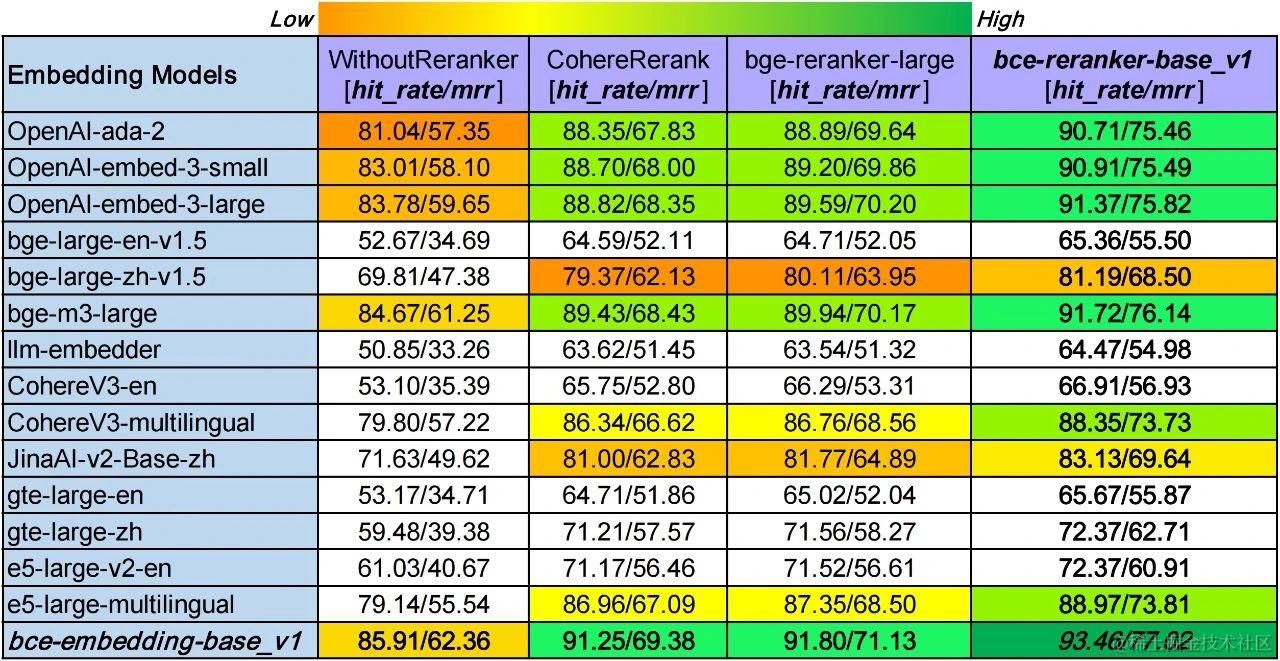 多領域、多語種和跨語種RAG評測
多領域、多語種和跨語種RAG評測
我們針對市面上最強的常用開源、閉源embedding和reranker模型,進行系統性評測分析,結果如上圖所示。
-
豎排對比,bce-embedding-base_v1的表現和之前一樣,具備很好的效果,語種支持和領域覆蓋都很不錯。最新的openai-embed-3和bge-m3表現出頑強的性能,具備良好的多語種和跨語種能力,具備良好的領域泛化性。Cohere和e5的多語種embedding模型同樣表現出不錯的效果。而其他單語種embedding模型表現卻不盡如人意(JinaAI-v2-Base-zh和bge-large-zh-v1.5稍好一些)。
-
橫排對比,reranker模塊可以顯著改善檢索效果。其中CohereRerank和bge-reranker-large效果相當,bce-reranker-base_v1具備比前二者更好的精排能力。
-
綜上,bce-embedding-base_v1和bce-reranker-base_v1的組合可以實現最好的檢索效果(93.46/77.02),比其他開源閉源最好組合(bge-m3-large+bge-reranker-large, 89.94/70.17),hit rate提升3.53%,mrr提升6.85%。
Rerank的必要性
為啥需要rerank,上面數字可能還不直觀。我們在開源的github上放了一張圖,意思是QAnything在知識庫的數據越多,準確率越高。而一般搭建的RAG,如果沒有rerank這一環節,在數據輸入多了以后,效果反而下降了。
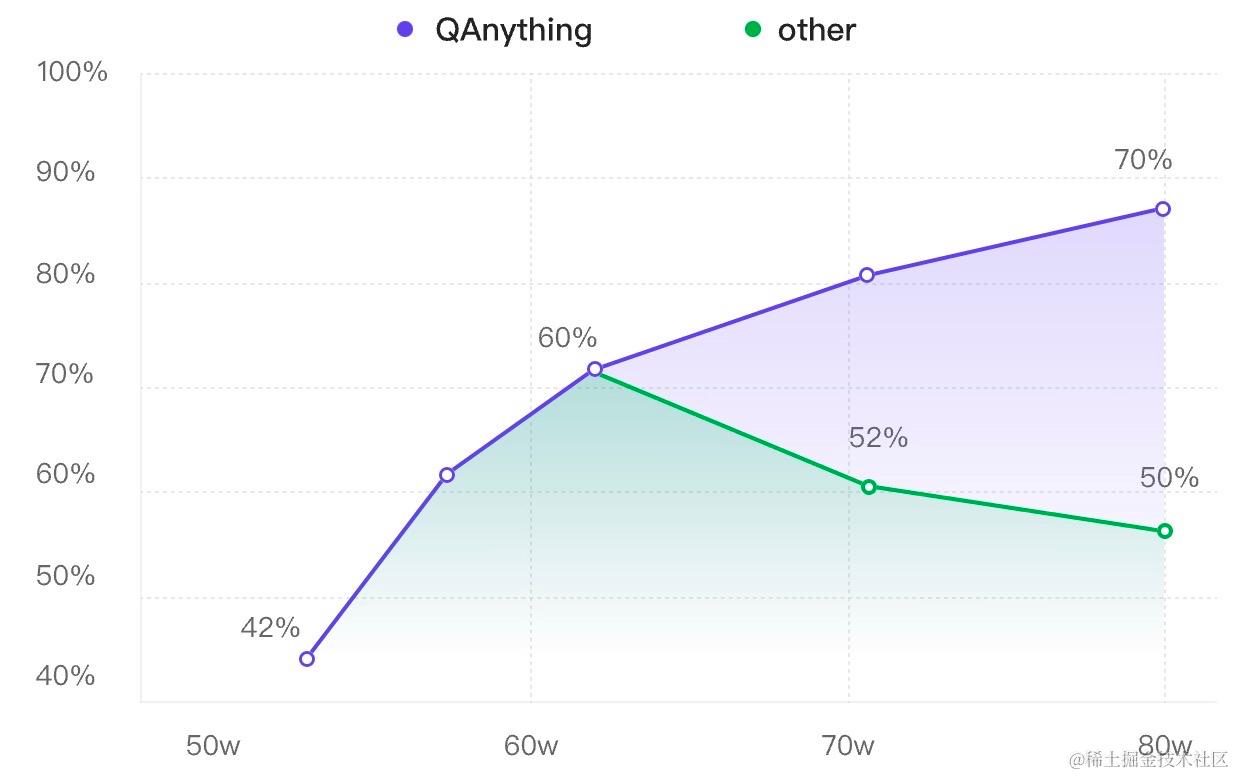
我們在做升學問答的時候,遇到一個有趣的現象:我們分批往RAG知識庫中灌入數據,每加一批數據都做一次評測,觀察隨著數據量變大,問答效果的變化情況:
- baseline:第一批數據加入后問答正確率有42.6%,此時有一些問題沒回答上來是因為確實缺少相關資料。我們繼續加數據…
- 迎來上漲:第二批加了更多數據,覆蓋知識范圍更廣。準確率提升到了60.2%,提升非常明顯,看來加數據確實還是挺有用的。
- 壞消息:當加入第三批數據的時候,我們最擔心的事情還是發生了。正確率急劇下降,跌了將近8個百分點。

不是所的RAG系統都能保證:數據越多,效果越好。隨著數據的增多,數據之間可能會有相互干擾,導致檢索退化的問題,影響問答的質量。
這個現象在最近的一篇論文:The Power of Noise: Redefining Retrieval for RAG Systems (arXiv:2401.14887v2)也有一些解釋,對于RAG系統,如果喂給大模型的輸入是相近容易混淆的話,對正確性的影響是最大的。
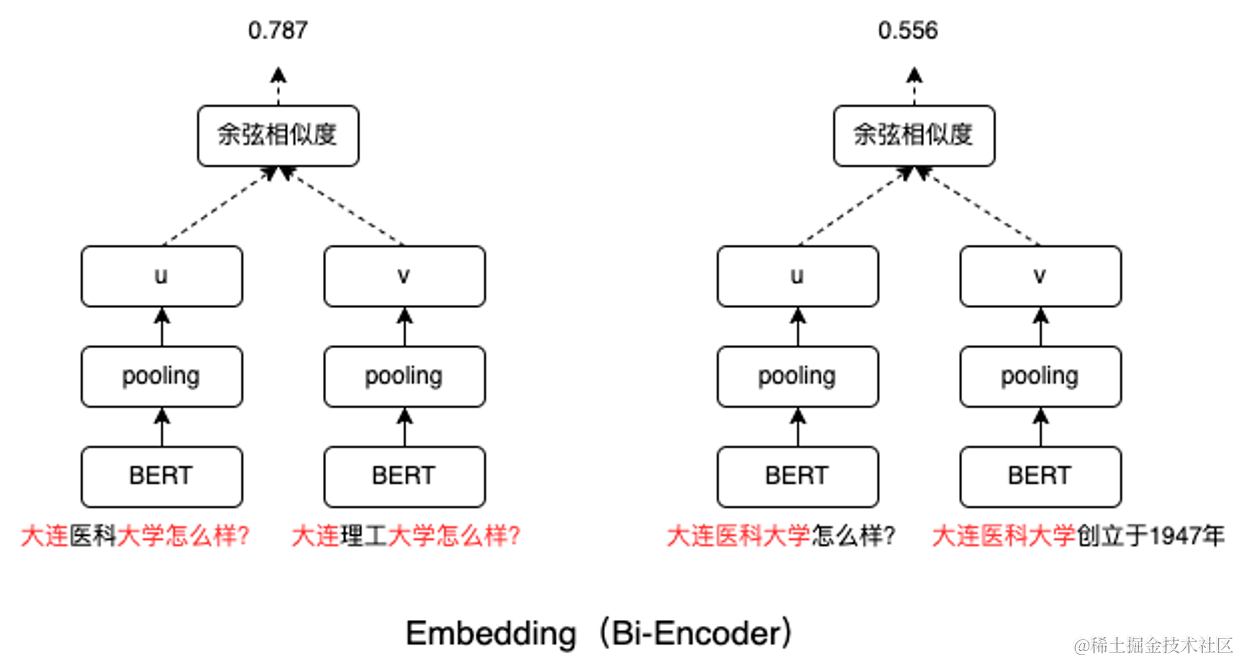
以我們遇到的一個case為例,大連醫科大學怎么樣?這個問題在v2版本(加入第三批數據前)是能回答對的,v3版本(加入第三批數據后)回答錯了。看了一下送到LLM的文本片段,居然全部都是大連理工大學相關的信息。

主要原因是第三批加入的某些文檔中恰好有 “大連理工大學xxx怎么樣?” 的句子,和query “大連醫科大學怎么樣?” 表面上看起來確實非常像,Embedding給它打了比較高的分。
而類似大連醫科大學師資介紹這樣的片段相關性就稍微低了些。LLM輸入token有限制,前面兩個最相關但是實際并不能回答query問題的片段就已經占滿了token的窗口,只能把他倆送進LLM里。結果可想而知,啥都不知道。
文本片段與query的相似性和文本片段是否包含query的答案(相關性)是兩回事。RAG中一個非常重要的矛盾點在于檢索召回的片段比較多,但是LLM輸入token是有限制,所以必須把能回答query問題的片段(和問題最相關)給LLM。 Embedding 可以給出一個得分,但是這個得分描述的更多的是相似性。Embedding本質上是一個雙編碼器,兩個文本在模型內部沒有任何信息交互。只在最后計算兩個向量的余弦相似度時才進行唯一一次交互。所以Embedding檢索只能把最相似的文本片段給你,沒有能力來判斷候選文本和query之間的相關性。但是相似又不等于相關。
如下圖所示,從某種程度上,Embedding其實就是在算兩個文本塊中相似字符的個數占比,它分不清query中的重點是大連醫科大學,在它看來每個字符的重要性都是一樣的。感興趣的話可以計算一下下圖中紅字部分的占比,和最后余弦相似度的得分基本是吻合的。
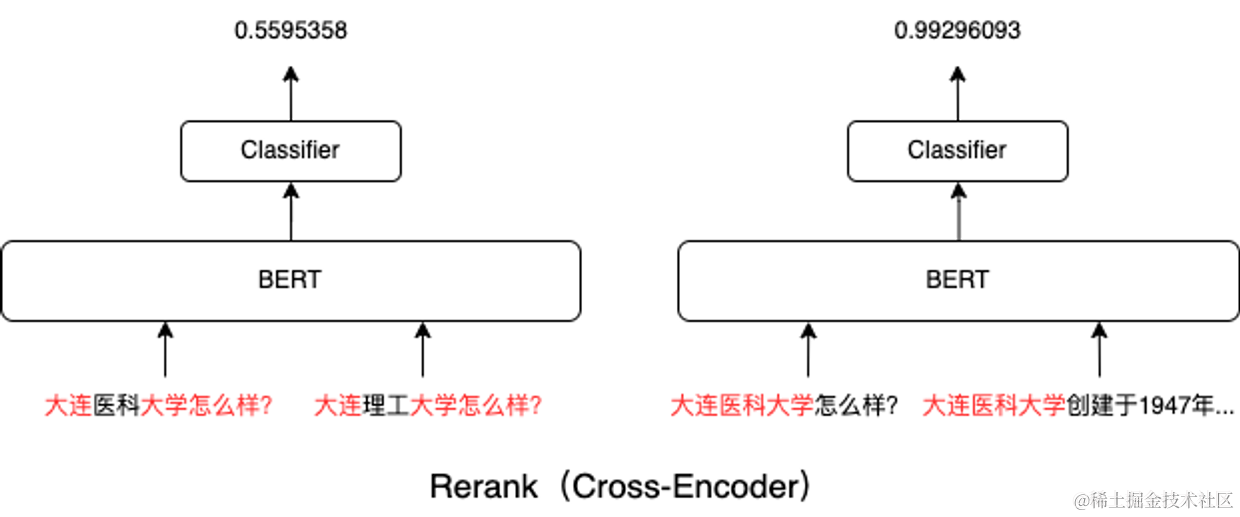
Rerank本質是一個Cross-Encoder的模型。Cross-Encoder能讓兩個文本片段一開始就在BERT模型各層中通過self-attention進行交互。它能夠用self-attention判斷出來這query中的重點在于大連醫科大學,而不是怎么樣?。所以,如下圖所示,大連醫科大學怎么樣?這個query和大連醫科大學創建于1947年…更相關。
加上兩階段檢索后,重新跑一下實驗:
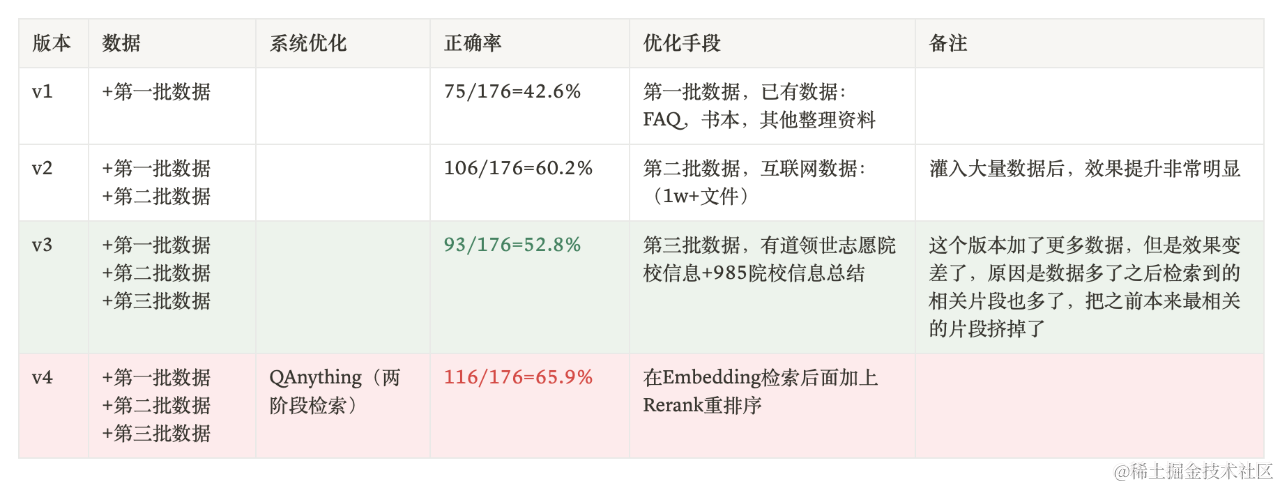
在數據不變的情況,兩階段檢索問答準確率從52.8%提升到65.9%,這個結果再次證明了一階段檢索中存在數據互相干擾的情況。兩階段檢索可以最大化的挖掘出數據的潛力,我們繼續加數據,效果能夠穩定提升。如下圖所示,兩階段檢索最大的意義不是在某一個實驗上面提升了10個點。它最大的意義在于讓“數據越多,效果越好”變成了現實。 在實際使用中,因為rerank比embedding慢得多,所以一般用兩階段檢索。速度慢不是cross-encoder的模型比bi-encoder的模型速度慢。關鍵在于,bi-encoder可以離線計算海量文本塊的向量化表示,把它們暫存在向量數據庫中,在問答檢索的時候只需要計算一個query的向量化表示就可以了。拿著query的向量表示去庫里找最相似的文本即可。但是cross-encoder需要實時計算兩個文本塊的相關度,如果候選文本有幾萬條,每一條都需要和query一起送進BERT模型中算一遍,需要實時算幾萬次。這個成本是非常巨大的。所以,我們可以把檢索過程分為兩個階段:召回(粗排)和重排:
- 第一個階段的目標是盡可能多的召回相似的文本片段,這個階段的文本得分排序不是特別靠譜,所以候選的topK可以設置大一些,比如topK=100;
- 第二個階段的目標是對100個粗排的候選文本片段進行重新排序,用cross-encoder計算100個候選文本和query的相關度得分;
兩階段檢索結合可以兼顧效果和效率。
LLM模型微調
我們的開源項目QAnything引入了一款7B參數規模的大型語言模型Qwen-7B-QAnything,該模型是在Qwen-7B基礎上,通過使用我們團隊精心構建的中英文高質量指令數據進行微調得到的。隨著開源大型語言模型(LLM)基座模型的能力不斷增強,我們通過在這些優秀的基座模型上進行后續訓練,包括繼續預訓練、指令微調(SFT)和偏好對齊等工作,以更有效地滿足RAG應用對大模型的特定需求,從而實現高性價比的模型優化。
為什么要微調?
RAG技術結合了知識檢索與生成模型,通過從外部知識源檢索信息,并將這些信息與用戶問題整合成完整的Prompt輸入到大模型中,以便根據這些參考信息回答問題。然而,當面對含有專業術語或通俗縮寫的開放性問題時,直接使用開源Chat模型可能會導致模型回答不準確。 此外,為了最大化利用大模型的上下文窗口,RAG應用傾向于保留盡可能多的檢索信息,這可能會使得模型的注意力分散,降低其遵循指令的能力,進而引發回答中的重復內容、關鍵信息丟失等問題。為了提高大模型在參考信息不足時的誠實度,加入與用戶問題關聯度低的負樣本進行微調訓練變得必要。
在選擇基座模型時,我們尋找能夠支持中英文、至少具備4K上下文窗口的模型,且能在單塊GPU上部署,優先考慮7B以下參數規模的模型以便于未來在消費級硬件上部署。Qwen-7B,一個阿里云研發的70億參數的通用大模型,以其在多個基準測試中的卓越表現成為我們的選擇。該模型通過在超過2.4萬億tokens的數據上預訓練,包含了豐富的中英文、多語言、編程、數學等領域數據,確保了廣泛的覆蓋面。考慮到7B參數規模的限制,我們在指令微調時采用了結構化指令模板,以增強模型在實際應用中的指令遵循能力。
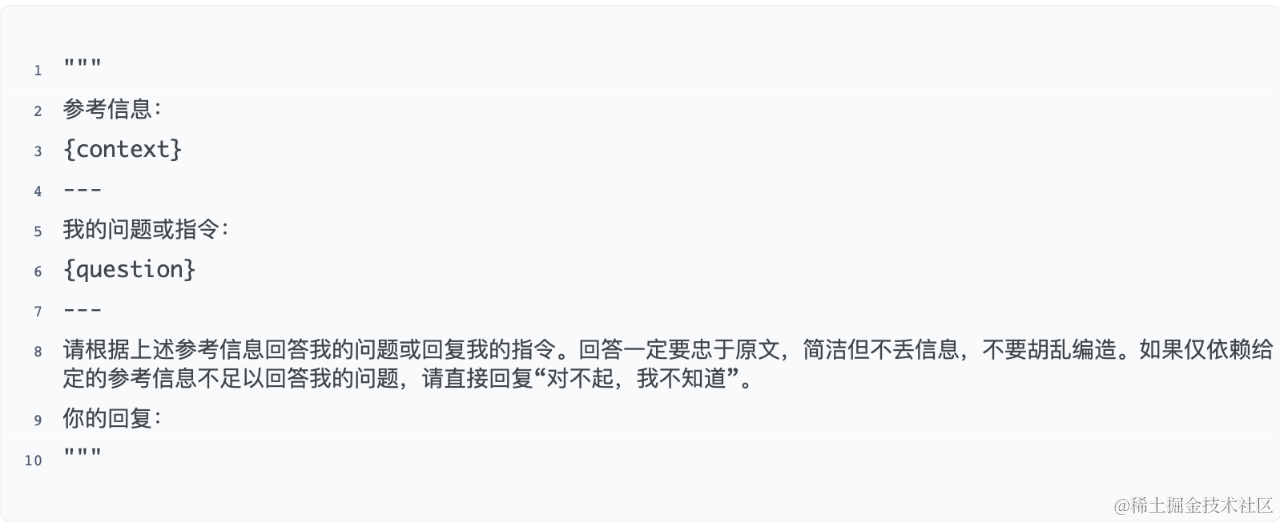
QAnything的prompt
如何微調?
-
指令微調數據構造我們為Qwen-7B-QAnything模型構造了豐富的指令微調數據集,涵蓋了多種類型的數據,包括基于參考信息的結構化問答數據(單文檔/多文檔的事實問答、多文檔的歸納總結/推理類問答、信息抽取)、多輪對話查詢重寫、段落摘要、開放域問答、中英文翻譯以及跨學科問答等。
-
指令微調模型訓練
盡管與大模型的預訓練相比,指令微調成本較低,但在微調數據不完整或比例不平衡的初期探索階段,采用全參數微調的代價依然較高。為了盡可能降低實驗成本并快速驗證微調效果,我們首先采用LoRA方法進行微調探索,待實驗條件穩定后,再轉向全參數微調。我們的LoRA微調配置如下:使用8張A40顯卡的單機環境,初始學習率設為3e-5,每張卡的批量大小為2,采用16步的梯度累積,同時利用bfloat16精度訓練以避免溢出并增強穩定性。此外,我們采用QLoRA + DeepSpeed Zero2 + FlashAttention配置以節約訓練所需的顯存。QLoRA通過4比特量化技術壓縮預訓練語言模型,使用NormalFloat4數據類型存儲基模型權重,凍結基模型參數,并以低秩適配器(LoRA參數)形式添加少量可訓練參數。在微調階段,QLoRA將權重從NormalFloat4數據類型反量化為bfloat16進行前向和后向傳播,僅更新bfloat16格式的LoRA參數權重梯度。與LoRA原論文不同,針對指令微調數據規模達到百萬級別的情況,我們在所有線性層添加低秩適配器,并發現增加lora_rank和lora_alpha參數能顯著提升微調效果。因此,我們為Qwen-7B模型微調采取了特定的LoRA參數配置,以實現最佳效果。

-
指令微調模型問答效果評估
我們參考了這篇文章:Benchmarking Large Language Models in Retrieval-Augmented Generation,使用開源 Benchmark 的事實型文檔問答測試集,對微調過后的LLM做質量評估。中、英文測試集分別包含300條,Context Noise Ratio (0~0.8)表示LLM 輸入Context中不相關噪聲片段的比例。回答準確率指標結果說明:Qwen-7B-Chat (QwenLM 2023)表示論文中的結果,Qwen-7B-Chat表示使用開源Chat模型和結構化指令模版的結果,Qwen-7B-QAnything 表示QAnything開源項目微調模型的結果。模型評估時使用了top_p采樣。結果表明 Qwen-7B-QAnything對檢索外部知識源包含不相關信息的魯棒性更好。
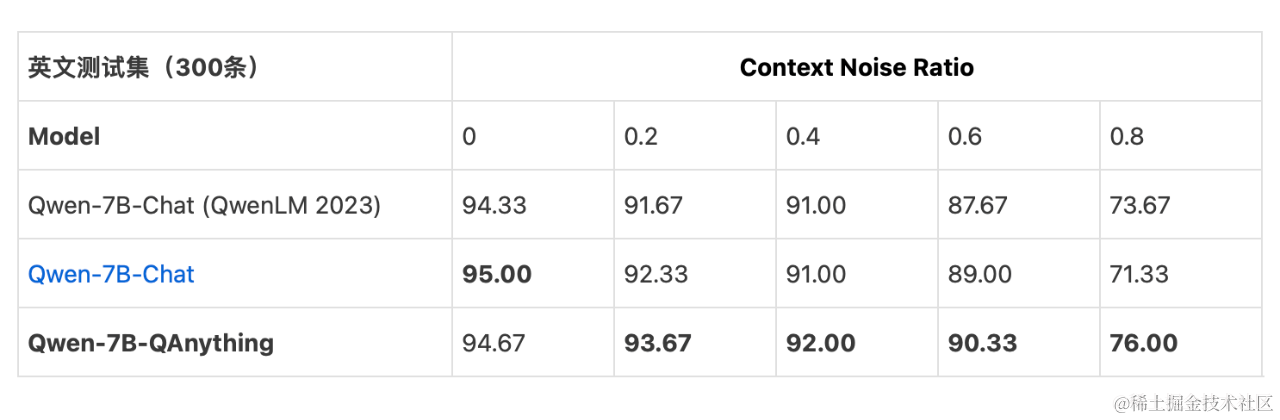
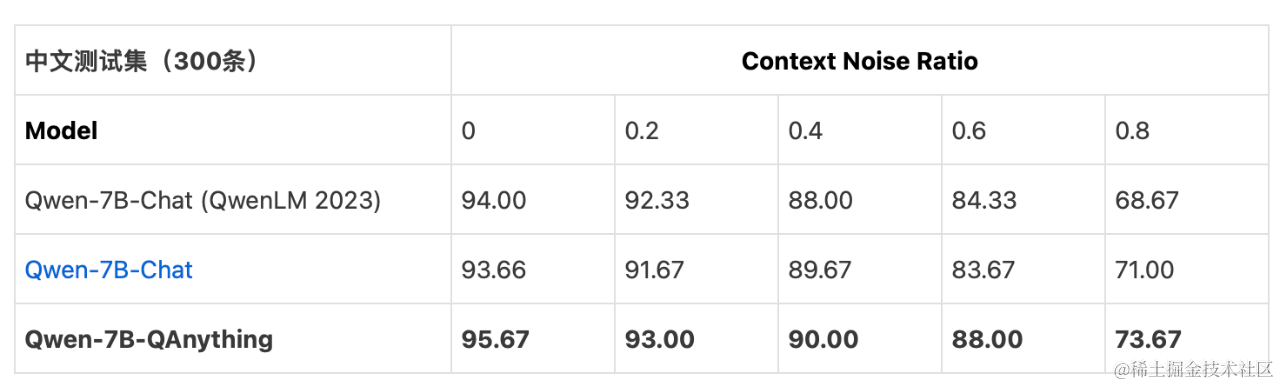
公開數據集的benchmark的評測結果
此外,團隊內部針對業務場景構造700條問答對作為評測集,覆蓋多種文檔類型和問題,其中相關參考信息由BCE Embedding和Rerank模型檢索重排序得到,參考答案由 GPT4 生成,結合人工修正得到。結合 Ragas 評測框架實現對 LLM 的自動化評測。評測指標采用 [answer_correctness],通過計算LLM回答內容 answer 和參考答案的 factual correctness 和 semantic similarity 加權和得到,其中 factual correctness(權重系數0.75)利用 GPT4 根據 answer 和參考答案生成TP/FN/FP表述計算得分,semantic similarity(權重系數0.25)利用 BCE Embedding 計算 answer 和參考答案的語義相似度。以下是評測結果及部分示例。

本地部署
QAnything開源項目為本地部署的大型語言模型(LLM)提供了三種推理框架后端選項:FasterTransformer、vLLM和Huggingface Transformers。這些選項滿足了不同用戶對于部署LLM的需求,實現了在高性能與通用性之間的平衡。
FasterTransformer (https://github.com/NVIDIA/FasterTransformer) 是由NVIDIA開源的一個高性能LLM推理框架,專為NVIDIA GPU優化。它的優點在于支持大型模型的INT8-Weight-Only推理,能在保持模型精度的同時減少推理延時和GPU顯存使用,提高了在相同GPU配置下的多并發吞吐性能。FasterTransformer的模型權重轉換與具體GPU型號無關,提供了一定的部署靈活性,但需要GPU具備一定的計算能力(FP16推理支持計算能力7.0及以上,INT8-Weight-Only支持7.5及以上)。此外,FasterTransformer作為Triton Inference Server的后端 (https://github.com/triton-inference-server/fastertransformer_backend) 實施LLM推理,支持Linux/Windows 11 WSL2部署。NVIDIA還基于FasterTransformer和TensorRT開發了新的推理框架TensorRT-LLM (https://github.com/NVIDIA/TensorRT-LLM),進一步提高了推理性能,但這也意味著與NVIDIA GPU的綁定更緊密,犧牲了一定的靈活性和通用性。
vLLM (https://github.com/vllm-project/vllm) 是由UC Berkeley LMSYS團隊開發的另一款高性能LLM推理框架,其利用PagedAttention技術優化KV Cache管理,并結合并行采樣和連續批處理請求調度管理,支持NVIDIA和AMD GPU,提高了系統吞吐性能。通過Huggingface Transformers訓練的模型可以輕松部署為Python服務,展現出良好的系統靈活性。vLLM通過AWQ和GPTQ等算法支持INT4-Weight-Only推理,節省顯存同時減少推理延時,但可能會輕微影響模型精度和生成質量。QAnything利用FastChat (https://github.com/lm-sys/FastChat)提供的接口使用vLLM后端,提供了兼容OpenAI API的調用接口,默認采用bfloat16推理,對GPU和算力有一定要求。
Huggingface Transformers (https://github.com/huggingface/transformers)是由Huggingface團隊開發的一個通用性強、靈活性高的Transformer模型庫,與PyTorch等深度學習框架配合,支持模型訓練和Python服務部署。雖然在多數情況下,其推理性能可能不及FasterTransformer和vLLM,但它兼容不同算力等級的GPU。QAnything通過復用FastChat(https://github.com/lm-sys/FastChat)提供的接口使用Huggingface Transformers后端,實現了兼容OpenAI API的調用,采用load_in_8bit配置加載模型以節省顯存,同時使用bfloat16進行推理。
關于開源
自從「QAnything」項目開放源代碼以來,受到了開發社區的熱烈歡迎和廣泛認可。截至2024年2月29日,項目在GitHub上已經積累近5000個星標,這反映出了其流行度和用戶對其價值的高度評價。
歡迎點擊下面的鏈接下載試用:
QAnything github: https://github.com/netease-youdao/QAnything
QAnything gitee: https://gitee.com/netease-youdao/QAnything
歡迎大家在GitHub上為「QAnything」加星助力,方便收到新版本更新的通知!




2020年06月真題C語言軟件編程等級考試四級(含詳細解析答案))



)









![[筆記] wsl 禁用配置 win系統環境變量+代理](http://pic.xiahunao.cn/[筆記] wsl 禁用配置 win系統環境變量+代理)
)